Equal Cost Multipath Load Sharing
Cumulus Linux enables ECMP by default. Load sharing occurs automatically for IPv4 and IPv6 routes with multiple installed next hops. The hardware or the routing protocol configuration determines the maximum number of routes for which load sharing occurs.
How Does ECMP Work?
ECMP operates only on equal cost routes in the RIB. In the following example, the 10.10.10.3/32 route has four possible next hops installed in the RIB:
cumulus@leaf01:mgmt:~$ net show route 10.10.10.3/32
RIB entry for 10.10.10.3/32
===========================
Routing entry for 10.10.10.3/32
Known via "bgp", distance 20, metric 0, best
Last update 10:04:41 ago
* fe80::4ab0:2dff:fe60:910e, via swp54, weight 1
* fe80::4ab0:2dff:fea7:7852, via swp53, weight 1
* fe80::4ab0:2dff:fec8:8fb9, via swp52, weight 1
* fe80::4ab0:2dff:feff:e147, via swp51, weight 1
FIB entry for 10.10.10.3/32
===========================
10.10.10.3 nhid 108 proto bgp metric 20
For Cumulus Linux to consider routes equal, the routes must:
- Originate from the same routing protocol. Routes from different sources are not considered equal. For example, a static route and an OSPF route are not considered for ECMP load sharing.
- Have equal cost. If two routes from the same protocol are unequal, only the best route installs in the routing table.
When multiple routes are in the routing table, a hash determines through which path a packet follows. To prevent out of order packets, ECMP hashes on a per-flow basis; all packets with the same source and destination IP addresses and the same source and destination ports always hash to the same next hop. ECMP hashing does not keep a record of packets that hash to each next hop and does not guarantee that traffic to each next hop is equal.
Cumulus Linux enables the BGP maximum-paths setting by default and installs multiple routes. Refer to BGP and ECMP.
Next Hop Groups
ECMP routes resolve to next hop groups, which identify one or more next hops. To view next hop information, run the NVUE nv show router nexthop rib or nv show router nexthop rib <id> commands, or the ip nexthop show or ip nexthop show <id> kernel commands.
cumulus@leaf01:mgmt:~$ nv show router nexthop rib
Installed - Install state
ID Installed UpTime Vrf Valid Via ViaIntf ViaVrf Depends
--- --------- -------- ------- ----- ------------------------- ------------- ------- -------
7 on 00:10:43 default on lo default
8 on 00:13:36 default on eth0 mgmt
9 on 00:13:36 default on eth0 mgmt
10 00:10:43 default on
11 on 00:10:43 default on 192.168.200.1 eth0 mgmt
12 on 00:10:43 default on
15 on 00:10:43 default on
30 on 00:10:43 default on
32 on 00:13:33 default on swp53 default
34 00:13:33 default on swp51 default
36 00:13:33 default on swp52 default
38 00:13:33 default on swp54 default
68 00:10:50 default on peerlink.4094 default
76 on 00:10:48 default on fe80::4ab0:2dff:fe59:eedc peerlink.4094 default
88 00:10:46 default on br_default default
89 00:10:46 default on vlan10v0 RED
90 on 00:10:46 default on vlan10 RED
91 00:10:46 default on vlan10v0 RED
92 00:10:46 default on vlan4024_l3 RED
93 00:10:46 default on vlan20 RED
94 on 00:10:46 default on vlan10 RED
95 on 00:10:46 default on vlan20 RED
96 on 00:10:46 default on vlan30 BLUE
97 00:10:46 default on vlan4036_l3 BLUE
98 on 00:10:46 default on vlan30 BLUE
...
The following example shows information for next hop group 108:
cumulus@leaf01:mgmt:~$ nv show router nexthop rib 93
operational
--------------- -----------
type zebra
ref-count 2
vrf default
valid on
interface-index 67
uptime 00:12:58
Via
======
Nexthop type vrf weight Summary
------- --------- --- ------ -------
vlan20 interface RED
Via BackupNexthops
=====================
No Data
Depends
==========
No Data
ECMP Hashing
You can configure custom hashing to specify what to include in the hash calculation during load balancing between:
- Multiple next hops of a layer 3 route (ECMP hashing).
- Multiple interfaces that are members of the same bond (bond or LAG hashing). For bond hashing, see Bonding - Link Aggregation.
For ECMP load balancing between multiple next hops of a layer 3 route, you can hash on these fields:
Field |
Default Setting | NVUE Command | traffic.conf |
|---|---|---|---|
| IP protocol | on | nv set system forwarding ecmp-hash ip-protocol onnv set system forwarding ecmp-hash ip-protocol off |
hash_config.ip_prot |
| Source IP address | on | nv set system forwarding ecmp-hash source-ip onnv set system forwarding ecmp-hash source-ip off |
hash_config.sip |
| Destination IP address | on | nv set system forwarding ecmp-hash destination-ip onnv set system forwarding ecmp-hash destination-ip off |
hash_config.dip |
| Source port | on | nv set system forwarding ecmp-hash source-port onnv set system forwarding ecmp-hash source-port off |
hash_config.sport |
| Destination port | on | nv set system forwarding ecmp-hash destination-port onnv set system forwarding ecmp-hash destination-port off |
hash_config.dport |
| IPv6 flow label | on | nv set system forwarding ecmp-hash ipv6-label onnv set system forwarding ecmp-hash ipv6-label off |
hash_config.ip6_label |
| Ingress interface | off | nv set system forwarding ecmp-hash ingress-interface onnv set system forwarding ecmp-hash ingress-interface off |
hash_config.ing_intf |
| TEID (see GTP Hashing) | off | nv set system forwarding ecmp-hash gtp-teid onnv set system forwarding ecmp-hash gtp-teid off |
hash_config.gtp_teid |
| Inner IP protocol | off | nv set system forwarding ecmp-hash inner-ip-protocol onnv set system forwarding ecmp-hash inner-ip-protocol off |
hash_config.inner_ip_prot |
| Inner source IP address | off | nv set system forwarding ecmp-hash inner-source-ip onnv set system forwarding ecmp-hash inner-source-ip off |
hash_config.inner_sip |
| Inner destination IP address | off | nv set system forwarding ecmp-hash inner-destination-ip onnv set system forwarding ecmp-hash inner-destination-ip off |
hash_config.inner_dip |
| Inner source port | off | nv set system forwarding ecmp-hash inner-source-port onnv set system forwarding ecmp-hash inner-source-port off |
hash_config.inner-sport |
| Inner destination port | off | nv set system forwarding ecmp-hash inner-destination-port onnv set system forwarding ecmp-hash inner-destination-port off |
hash_config.inner_dport |
| Inner IPv6 flow label | off | nv set system forwarding ecmp-hash inner-ipv6-label onnv set system forwarding ecmp-hash inner-ipv6-label off |
hash_config.inner_ip6_label |
The following example commands omit the source port and destination port from the hash calculation:
cumulus@switch:~$ nv set system forwarding ecmp-hash source-port off
cumulus@switch:~$ nv set system forwarding ecmp-hash destination-port off
cumulus@switch:~$ nv config apply
Use the instructions below when NVUE is not enabled. If you are using NVUE to configure your switch, the NVUE commands change the settings in /etc/cumulus/datapath/nvue_traffic.conf which takes precedence over the settings in /etc/cumulus/datapath/traffic.conf.
- Edit the
/etc/cumulus/datapath/traffic.conffile:- Uncomment the
hash_config.enable = trueoption. - Set the
hash_config.sportandhash_config.dportoptions tofalse.
- Uncomment the
cumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf
...
# HASH config for ECMP to enable custom fields
# Fields will be applicable for ECMP hash
# calculation
#Note : Currently supported only for MLX platform
# Uncomment to enable custom fields configured below
hash_config.enable = true
#hash Fields available ( assign true to enable)
#ip protocol
hash_config.ip_prot = true
#source ip
hash_config.sip = true
#destination ip
hash_config.dip = true
#source port
hash_config.sport = false
#destination port
hash_config.dport = false
...
-
Run the
echo 1 > /cumulus/switchd/ctrl/hash_config_reloadcommand. This command does not cause any traffic interruptions.cumulus@switch:~$ echo 1 > /cumulus/switchd/ctrl/hash_config_reload
Cumulus Linux enables symmetric hashing by default. Make sure that the settings for the source IP and destination IP fields match, and that the settings for the source port and destination port fields match; otherwise Cumulus Linux disables symmetric hashing automatically. If necessary, you can disable symmetric hashing manually in the /etc/cumulus/datapath/traffic.conf file by setting symmetric_hash_enable = FALSE.
GTP Hashing
GTP carries mobile data within the core of the mobile operator’s network. Traffic in the 5G Mobility core cluster, from cell sites to compute nodes, have the same source and destination IP address. The only way to identify individual flows is with the GTP TEID. Enabling GTP hashing adds the TEID as a hash parameter and helps the Cumulus Linux switches in the network to distribute mobile data traffic evenly across ECMP routes.
Cumulus Linux supports TEID-based ECMP hashing for:
- GTP-U packets ingressing physical ports.
- VXLAN encapsulated GTP-U packets terminating on egress VTEPs.
For TEID-based load balancing for traffic on a bond, see Bonding - Link Aggregation.
GTP TEID-based ECMP hashing is only applicable if the outer header egressing the port is GTP encapsulated and if the ingress packet is either a GTP-U packet or a VXLAN encapsulated GTP-U packet.
- Cumulus Linux supports GTP Hashing on NVIDIA Spectrum-2 and later.
- GTP-C packets are not part of GTP hashing.
To enable TEID-based ECMP hashing:
cumulus@switch:~$ nv set system forwarding ecmp-hash gtp-teid on
cumulus@switch:~$ nv config apply
To disable TEID-based ECMP hashing, run the nv set system forwarding ecmp-hash gtp-teid off command.
Use the instructions below when NVUE is not enabled. If you are using NVUE to configure your switch, the NVUE commands change the settings in /etc/cumulus/datapath/nvue_traffic.conf which takes precedence over the settings in /etc/cumulus/datapath/traffic.conf.
-
Edit the
/etc/cumulus/datapath/traffic.conffile and change thelag_hash_config.gtp_teidparameter totrue:cumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf ... #GTP-U teid hash_config.gtp_teid = true -
Run the
echo 1 > /cumulus/switchd/ctrl/hash_config_reloadcommand. This command does not cause any traffic interruptions.cumulus@switch:~$ echo 1 > /cumulus/switchd/ctrl/hash_config_reload
To disable TEID-based ECMP hashing, set the hash_config.gtp_teid parameter to false, then reload the configuration.
To show that TEID-based ECMP hashing is on, run the command:
cumulus@switch:~$ nv show system forwarding ecmp-hash
applied description
----------------- ------- -----------------------------------
destination-ip on Destination IPv4/IPv6 Address
destination-port on TCP/UDP destination port
gtp-teid on GTP-U TEID
...
ECMP Hash Buckets
When there are multiple routes in the routing table, Cumulus Linux assigns each route to an ECMP bucket. When the ECMP hash executes, the result of the hash determines which bucket to use.
In the following example, four next hops exist. Three different flows hash to different hash buckets. Each next hop goes to a unique hash bucket.
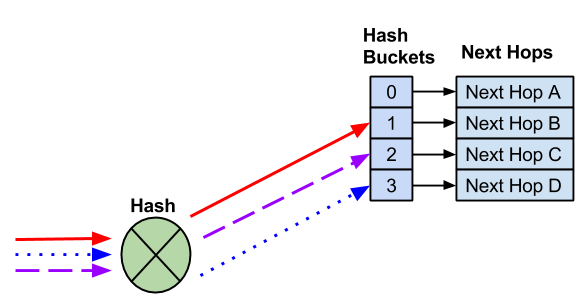
The addition of a next hop creates a new hash bucket. The assignment of next hops to hash buckets, as well as the hash result, sometimes changes with the addition of next hops.
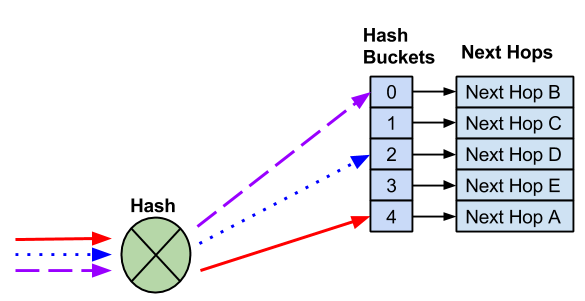
With the addition of a new next hop, there is a new hash bucket. As a result, the hash and hash bucket assignment changes, so the existing flows go to different next hops.
When you remove a next hop, the remaining hash bucket assignments can change, which can also change the next hop selected for an existing flow.
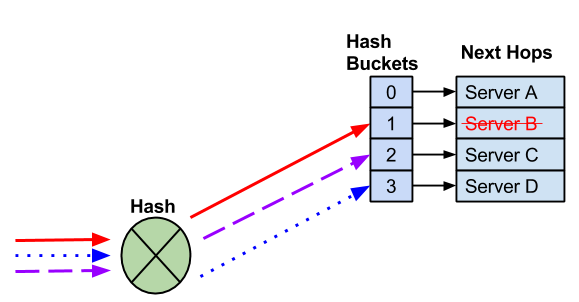
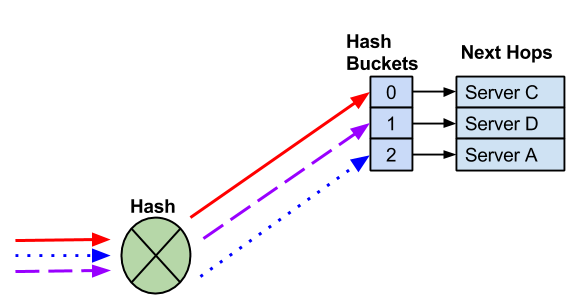
A next hop fails, which removes the next hop and hash bucket. It is possible that Cumulus Linux reassigns the remaining next hops.
In most cases, modifying hash buckets has no impact on traffic flows as the switch forwards traffic to a single end host. In deployments where multiple end hosts use the same IP address (anycast), you must use resilient hashing.
Unique Hash Seed
You can configure a unique hash seed for each switch to prevent hash polarization, a type of network congestion that occurs when multiple data flows try to reach a switch using the same switch ports.
You can set a hash seed value between 0 and 4294967295. If you do not specify a value, switchd creates a randomly generated seed.
To configure the hash seed:
cumulus@switch:~$ nv set system forwarding hash-seed 50
cumulus@switch:~$ nv config apply
If you do not enable NVUE, use the instructions below. If you are using NVUE to configure your switch, the NVUE commands change the settings in /etc/cumulus/datapath/nvue_traffic.conf which takes precedence over the settings in /etc/cumulus/datapath/traffic.conf.
Edit /etc/cumulus/datapath/traffic.conf file to change the ecmp_hash_seed parameter, then restart switchd.
cumulus@switch:~$ sudo nano /etc/cumulus/datapath/traffic.conf
...
#Specify the hash seed for Equal cost multipath entries
# and for custom ecmp and lag hash
# Default value: random
# Value Range: {0..4294967295}
ecmp_hash_seed = 50
...
cumulus@switch:~$ sudo systemctl restart switchd.service
Restarting the switchd service causes all network ports to reset, interrupting network services, in addition to resetting the switch hardware configuration.
cl-ecmpcalc
Run the cl-ecmpcalc command to determine a hardware hash result. For example, you can see which path a flow takes through a network. You must provide all fields in the hash, including the ingress interface, layer 3 source IP, layer 3 destination IP, layer 4 source port, and layer 4 destination port.
cl-ecmpcalc only supports input interfaces that convert to a single physical port in the port tab file, such as the physical switch ports (swp). You can not specify virtual interfaces like bridges, bonds, or subinterfaces.
cumulus@switch:~$ sudo cl-ecmpcalc -i swp1 -s 10.0.0.1 -d 10.0.0.1 -p tcp --sport 20000 --dport 80
ecmpcalc: will query hardware
swp3
If you omit a field, cl-ecmpcalc fails.
cumulus@switch:~$ sudo cl-ecmpcalc -i swp1 -s 10.0.0.1 -d 10.0.0.1 -p tcp
ecmpcalc: will query hardware
usage: cl-ecmpcalc [-h] [-v] [-p PROTOCOL] [-s SRC] [--sport SPORT] [-d DST]
[--dport DPORT] [--vid VID] [-i IN_INTERFACE]
[--sportid SPORTID] [--smodid SMODID] [-o OUT_INTERFACE]
[--dportid DPORTID] [--dmodid DMODID] [--hardware]
[--nohardware] [-hs HASHSEED]
[-hf HASHFIELDS [HASHFIELDS ...]]
[--hashfunction {crc16-ccitt,crc16-bisync}] [-e EGRESS]
[-c MCOUNT]
cl-ecmpcalc: error: --sport and --dport required for TCP and UDP frames
Resilient Hashing
In Cumulus Linux, when a next hop fails or you remove the next hop from an ECMP pool, the hashing or hash bucket assignment can change. Resilient hashing is an alternate way to manage ECMP groups. Cumulus Linux assigns next hops to buckets using their hashing header fields and uses the resulting hash to index into the table of 2^n hash buckets. Because all packets in a given flow have the same header hash value, they all use the same flow bucket.
- Resilient hashing supports both IPv4 and IPv6 routes.
- Resilient hashing prevents disruption when you remove next hops but does not prevent disruption when you add next hops.
The NVIDIA Spectrum ASIC assigns packets to hash buckets and assigns hash buckets to next hops. The ASIC also runs a background thread that monitors buckets and can migrate buckets between next hops to rebalance the load.
- When you remove a next hop, Cumulus Linux distributes the assigned buckets to the remaining next hops.
- When you add a next hop, Cumulus Linux assigns no buckets to the new next hop until the background thread rebalances the load.
- The load rebalances when the active flow timer expires only if there are inactive hash buckets available; the new next hop can remain unpopulated until the period set in active flow timer expires.
- When the unbalanced timer expires and the load is not balanced, the thread migrates buckets to different next hops to rebalance the load.
Any flow can migrate to any next hop, depending on flow activity and load balance conditions. Over time, the flow can get pinned, which is the default setting and behavior.
When you enable resilient hashing, Cumulus Linux assigns next hops in round robin fashion to a fixed number of buckets. In this example, there are 12 buckets and four next hops.
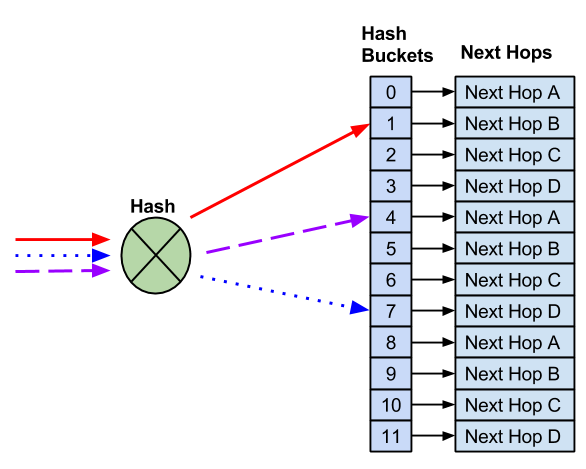
Unlike default ECMP hashing, when you need to remove a next hop, the number of hash buckets does not change.
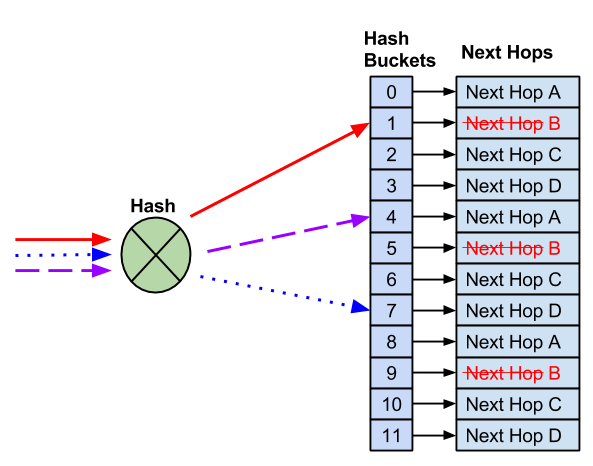
With 12 buckets and four next hops, instead of reducing the number of buckets, which impacts flows to known good hosts, the remaining next hops replace the failed next hop.
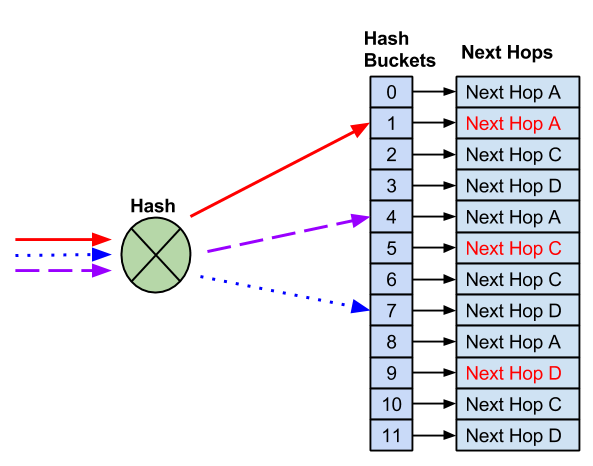
After you remove the failed next hop, the remaining next hops replace it. This prevents impact to any flows that hash to working next hops.
Resilient hashing does not prevent possible impact to existing flows when you add new next hops. Because there are a fixed number of buckets, a new next hop requires reassigning next hops to buckets.
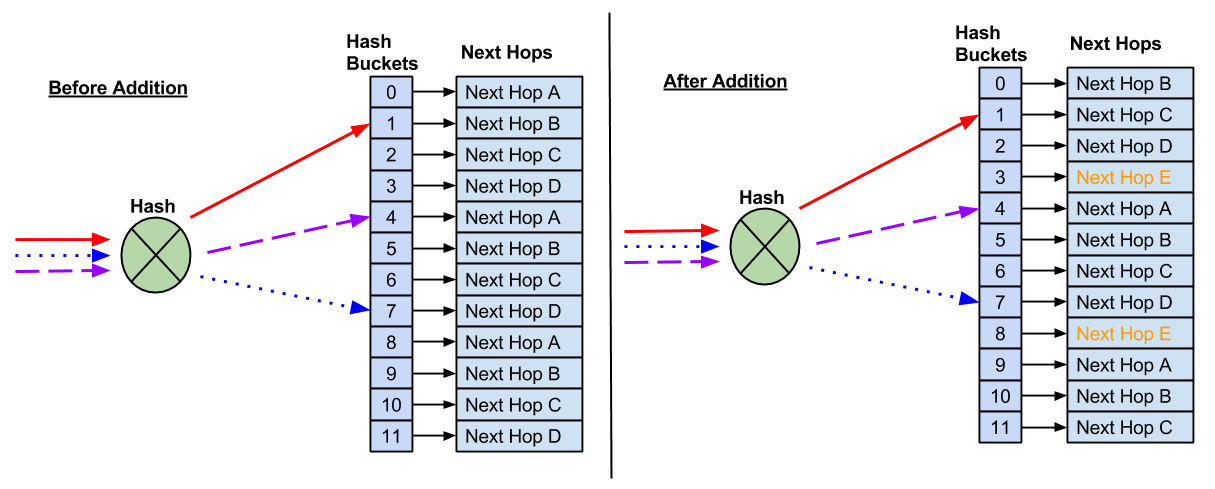
As a result, some flows hash to new next hops, which can impact anycast deployments.
Cumulus Linux does not enable resilient hashing by default. When you enable resilient hashing, all ECMP groups share 65,536 buckets. An ECMP group is a list of unique next hops that multiple ECMP routes reference.
An ECMP route counts as a single route with multiple next hops.
All ECMP routes must use the same number of buckets (you cannot configure the number of buckets per ECMP route).
A larger number of ECMP buckets reduces the impact on adding new next hops to an ECMP route. However, the system supports fewer ECMP routes. If you install the maximum number of ECMP routes, new ECMP routes log an error and do not install.
You can configure route and MAC address hardware resources depending on ECMP bucket size changes. See NVIDIA Spectrum routing resources.
To enable resilient hashing:
-
Edit the
/etc/cumulus/datapath/traffic.conffile to uncomment and set theresilient_hash_enableparameter toTRUE.You can also set the
resilient_hash_entries_ecmpparameter to the number of hash buckets to use for all ECMP routes. On Spectrum switches, you can set the number of buckets to 64, 512, 1024, 2048, or 4096. On NVIDIA Spectrum-2 and later, you can set the number of buckets to 64, 128, 256, 512, 1024, 2048, or 4096. The default value is 64.# Enable resilient hashing resilient_hash_enable = TRUE # Resilient hashing flowset entries per ECMP group # # Mellanox Spectrum platforms: # Valid values - 64, 512, 1024, 2048, 4096 # # Mellanox Spectrum2/3 platforms # Valid values - 64, 128, 256, 512, 1024, 2048, 4096 # # resilient_hash_entries_ecmp = 64 -
Restart the
switchdservice:
cumulus@switch:~$ sudo systemctl restart switchd.service
Restarting the switchd service causes all network ports to reset, interrupting network services, in addition to resetting the switch hardware configuration.
- Resilient hashing in hardware does not work with next hop groups; the switch remaps flows to new next hops when the set of nexthops changes. To work around this issue, configure zebra not to install next hop IDs in the kernel with the following vtysh command:
cumulus@switch:~$ sudo vtysh
switch# configure terminal
switch(config)# zebra nexthop proto only
switch(config)# exit
switch# write memory
switch# exit
cumulus@switch:~$
Considerations
When the router adds or removes ECMP paths, or when the next hop IP address, interface, or tunnel changes, the next hop information for an IPv6 prefix can change. FRR deletes the existing route to that prefix from the kernel, then adds a new route with all the relevant new information. In certain situations, Cumulus Linux does not maintain resilient hashing for IPv6 flows.
To work around this issue, you can enable IPv6 route replacement.
For certain configurations, IPv6 route replacement can lead to incorrect forwarding decisions and lost traffic. For example, it is possible for a destination to have next hops with a gateway value with the outbound interface or just the outbound interface itself, without a gateway address. If both types of next hops for the same destination exist, route replacement does not operate correctly; Cumulus Linux adds an additional route entry and next hop but does not delete the previous route entry and next hop.
To enable the IPv6 route replacement option:
-
In the
/etc/frr/daemonsfile, add the configuration option--v6-rr-semanticsto the zebra daemon definition. For example:cumulus@switch:~$ sudo nano /etc/frr/daemons ... vtysh_enable=yes zebra_options=" -M cumulus_mlag -M snmp -A 127.0.0.1 --v6-rr-semantics -s 90000000" bgpd_options=" -M snmp -A 127.0.0.1" ospfd_options=" -M snmp -A 127.0.0.1" ...
Restart FRR with this command:
cumulus@switch:~$ sudo systemctl restart frr.service
Restarting FRR restarts all the routing protocol daemons that are enabled and running.
To verify that IPv6 route replacement, run the systemctl status frr command:
cumulus@switch:~$ systemctl status frr
● frr.service - FRRouting
Loaded: loaded (/lib/systemd/system/frr.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-02-03 20:02:33 UTC; 3min 8s ago
Docs: https://frrouting.readthedocs.io/en/latest/setup.html
Process: 4675 ExecStart=/usr/lib/frr/frrinit.sh start (code=exited, status=0/SUCCESS)
Memory: 14.4M
CGroup: /system.slice/frr.service
├─4685 /usr/lib/frr/watchfrr -d zebra bgpd staticd
├─4701 /usr/lib/frr/zebra -d -M snmp -A 127.0.0.1 --v6-rr-semantics -s 90000000
├─4705 /usr/lib/frr/bgpd -d -M snmp -A 127.0.0.1
└─4711 /usr/lib/frr/staticd -d -A 127.0.0.1
Adaptive Routing
Adaptive routing is a load balancing feature that improves network utilization for eligible IP packets by selecting forwarding paths dynamically based on the state of the switch, such as queue occupancy and port utilization.
The benefits of using adaptive routing include:
- The switch can forward adaptive routing eligible IP packets over all the available ECMP member ports to maximize the total traffic throughput, while removing potential ECMP flow collisions.
- The switch distributes incoming traffic equally (or according to their weights) between the available IP next hops, which helps to minimize latency and network congestion.
- If the cumulative rate of one or more flows exceeds the link bandwidth of the individual uplink port, adaptive routing can distribute the traffic dynamically between multiple uplink ports; the available bandwidth for these flows is not limited to the link bandwidth of an individual uplink port.
With adaptive routing, the switch forwards packets to the less loaded path on a per packet basis to best utilize the fabric resources and avoid congestion. The change decision for port selection is set to one microsecond; you cannot change it.
Cumulus Linux supports adaptive routing with:
- Switches with the Spectrum-4 ASIC at 400G and 200G speeds.
- RoCE2 unicast traffic.
- VXLAN-encapsulated RoCE traffic.
- Layer 3 interfaces.
- Next hop router interfaces in the default VRF.
- Adaptive routing does not make use of resilient hashing.
- Cumulus Linux does not support adaptive routing on layer 3 subinterfaces, SVIs, bonds or bond members.
- The Spectrum-4 switch does not support adaptive routing on 800G links.
Cumulus Linux also supports BGP W-ECMP with adaptive routing; see BGP Weighted Equal Cost Multipath.
Enable Adaptive Routing
To enable adaptive routing:
Run the nv set interface <interface> router adaptive-routing enable on command on all the ports that are part of the same ECMP route. NVUE sets adaptive routing on the ports and enables the adaptive routing feature.
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv config apply
To disable adaptive routing, run the nv set router adaptive-routing enable off command. To disable adaptive routing on a specific port, run the nv set interface <interface> router adaptive-routing enable off command.
Enabling or disabling adaptive routing restarts the switchd service, which causes all network ports to reset, interrupts network services, and resets the switch hardware configuration.
Edit the /etc/cumulus/switchd.d/adaptive_routing.conf file:
- Set the
adaptive_routing.enableparameter toTRUEto enable the adaptive routing feature. - Set the
interface.<port>.adaptive_routing.enableparameter toTRUEin thePer-port configurationsection to enable adaptive routing on all the ports that are part of the same ECMP route.
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
...
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 70
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 70
...
Restart switchd with the sudo systemctl restart switchd.service command.
- To disable adaptive routing, set the
adaptive_routing.enableparameter toFALSEin the/etc/cumulus/switchd.d/adaptive_routing.conffile. - To disable adaptive routing on a specific port, set the
interface.<port>.adaptive_routing.enableparameter toFALSEin the/etc/cumulus/switchd.d/adaptive_routing.conffile.
When you enable adaptive routing, Cumulus Linux uses the default profile settings for your switch ASIC type. You cannot change the default profile settings. If you need to make adjustments to the settings, contact NVIDIA Customer Support.
Link Utilization
Link utilization, when crossing a threshold, is one of the parameters in the adaptive routing decision. The default link utilization threshold percentage on an interface is 70. You can change the percentage to a value between 1 and 100.
Link utilization is off by default; you must enable the global link utilization setting to use the link utilization thresholds set on adaptive routing interfaces. You cannot enable or disable link utilization per interface.
In Cumulus Linux 5.5 and earlier, link utilization is on by default. If you configured link utilization in a previous release, be sure to enable link utilization after you upgrade.
The following example enables link utilization and uses the default link utilization threshold percentage of 70:
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
The following example changes the link utilization threshold percentage to 100 on swp51 and enables link utilization:
cumulus@switch:~$ nv set interface swp51 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
Enabling or disabling link utilization restarts the switchd service, which causes all network ports to reset, interrupts network services, and resets the switch hardware configuration.
Edit the /etc/cumulus/switchd.d/adaptive_routing.conf file to set:
interface.<interface>.adaptive_routing.link_util_threshto a value between 1 and 100.adaptive_routing.link_util_threshold_disabledto TRUE.
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = TRUE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 100
Restart switchd with the sudo systemctl restart switchd.service command.
Example Configuration
The following example enables adaptive routing on swp1 and swp2. Global link utilization is off (the default setting).
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv config apply
The following example enables adaptive routing on swp51 and swp52, sets the link utilization threshold percentage to 100 on both swp51 and swp52, and enables global link utilization:
cumulus@switch:~$ nv set interface swp51 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp52 router adaptive-routing enable on
cumulus@switch:~$ nv set interface swp51 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set interface swp52 router adaptive-routing link-utilization-threshold 100
cumulus@switch:~$ nv set router adaptive-routing link-utilization-threshold on
cumulus@switch:~$ nv config apply
The following example enables adaptive routing on swp51 and swp52. Global link utilization is off (the default setting).
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/ad.aptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = FALSE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 0
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 0
...
Reload switchd with the sudo systemctl reload switchd.service command.
The following example enables adaptive routing on swp51 and swp52, sets the link utilization threshold percentage to 100 on both swp51 and swp52, and enables global link utilization.
cumulus@switch:~$ sudo nano /etc/cumulus/switchd.d/adaptive_routing.conf
## Global adaptive-routing enable/disable setting
adaptive_routing.enable = TRUE
## Global Link-utilization-threshold on/off
adaptive_routing.link_utilization_threshold_disabled = TRUE
## Per-port configuration
interface.swp51.adaptive_routing.enable = TRUE
interface.swp51.adaptive_routing.link_util_thresh = 100
interface.swp52.adaptive_routing.enable = TRUE
interface.swp52.adaptive_routing.link_util_thresh = 100
Reload switchd with the sudo systemctl reload switchd.service command.
Show Adaptive Routing Settings
To show adaptive routing settings, run the nv show router adaptive-routing command:
cumulus@leaf01:mgmt:~$ nv show router adaptive-routing
operational applied
-------------------------- ------------ -------
enable on off
To show adaptive routing configuration for an interface, run the nv show interface <interface> router adaptive-routing.
Considerations
IPv6 Next Hop Preference
Cumulus Linux uses IPv6 link-local addresses as BGP next hops when receiving a route with both link-local and global next hops. To configure a BGP peering to prefer global next hop addresses, configure the ipv6-nexthop-prefer-global option in an inbound route map applied to the peer. This is required when there are multiple BGP peerings to the same router with adaptive routing enabled, or multiple peerings to the same router on interfaces that share the same MAC address or physical interface. Refer to Set IPv6 Prefer Global.