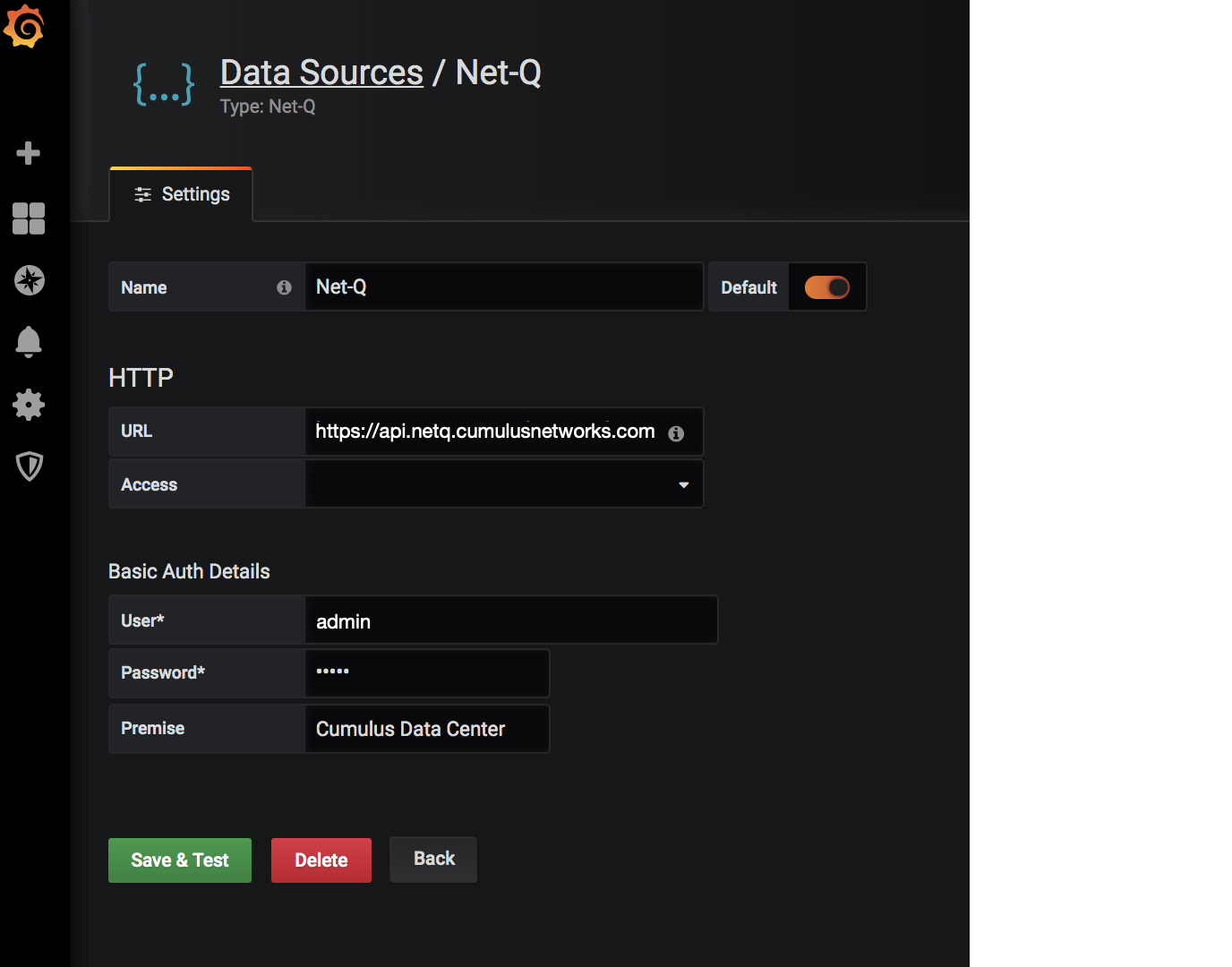
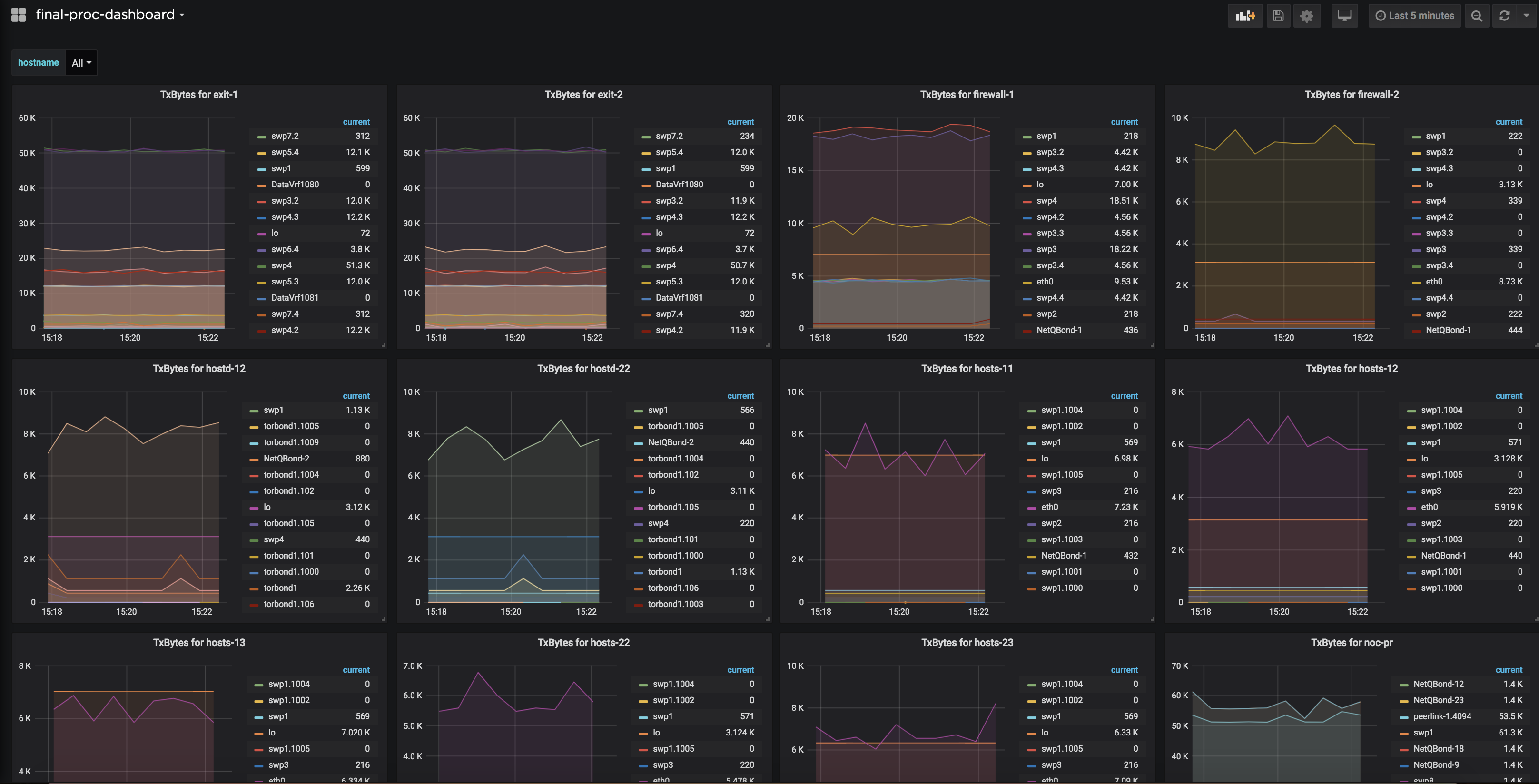
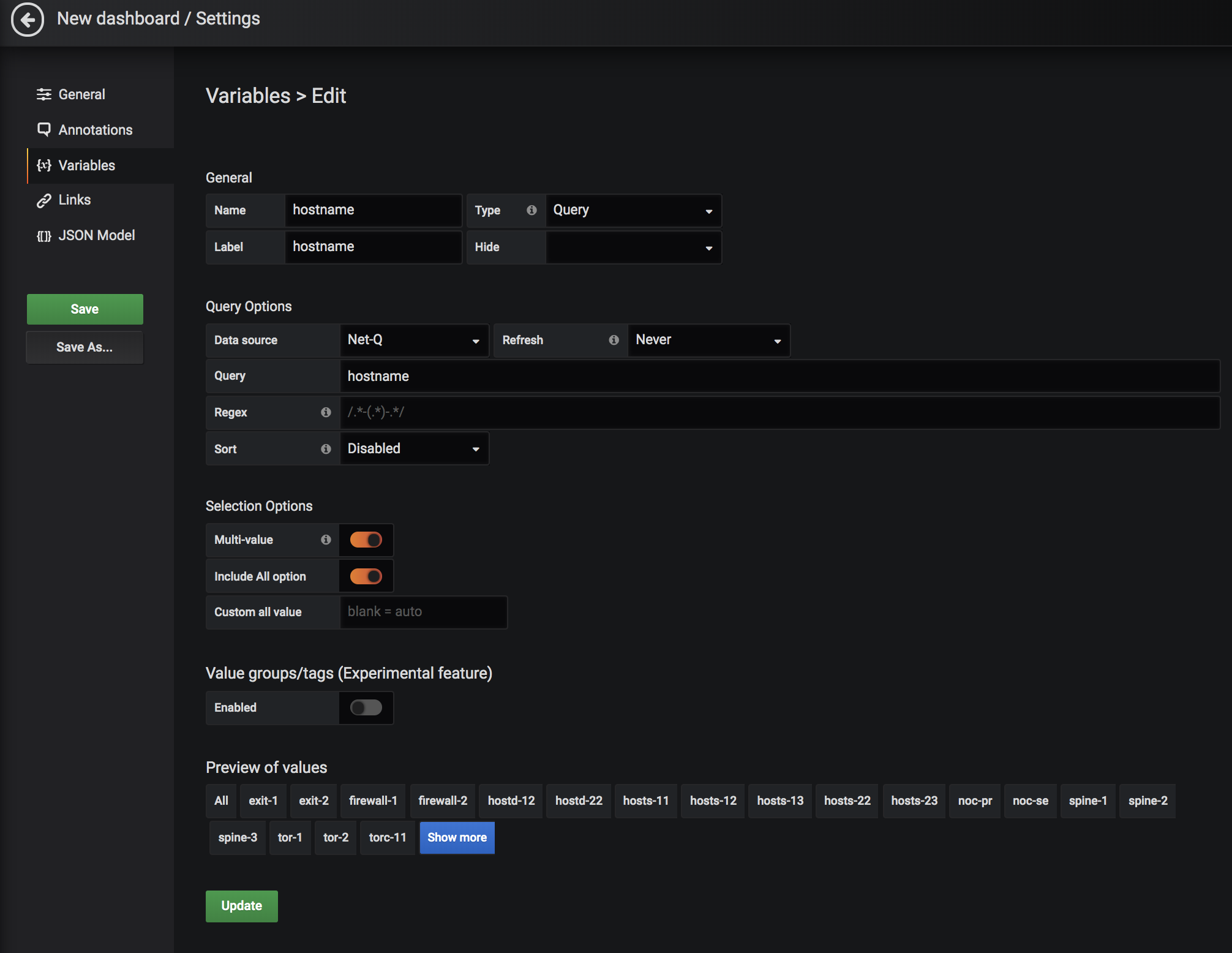
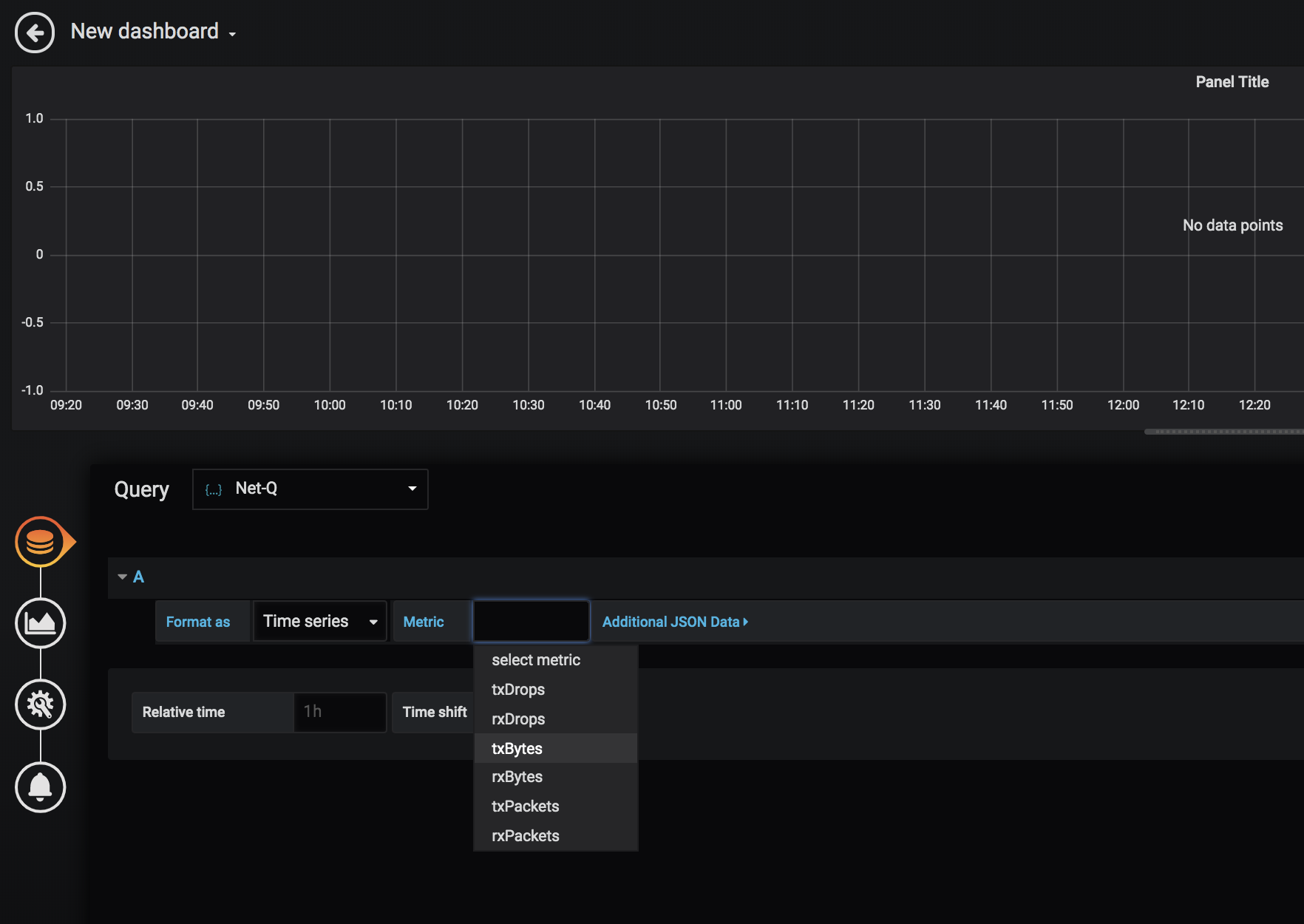
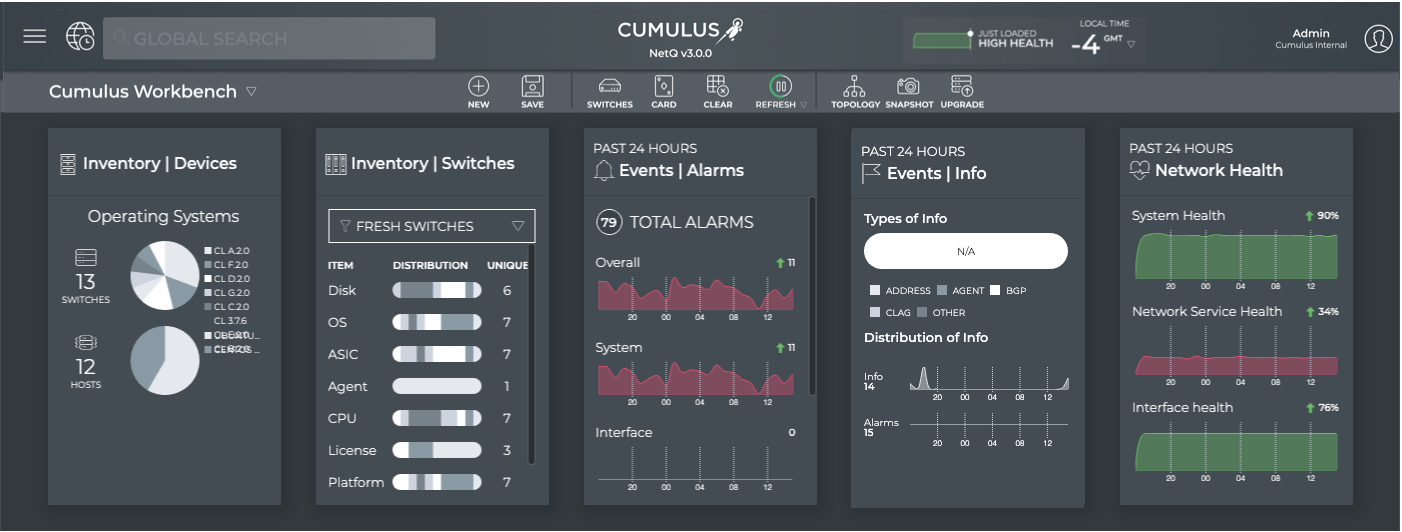
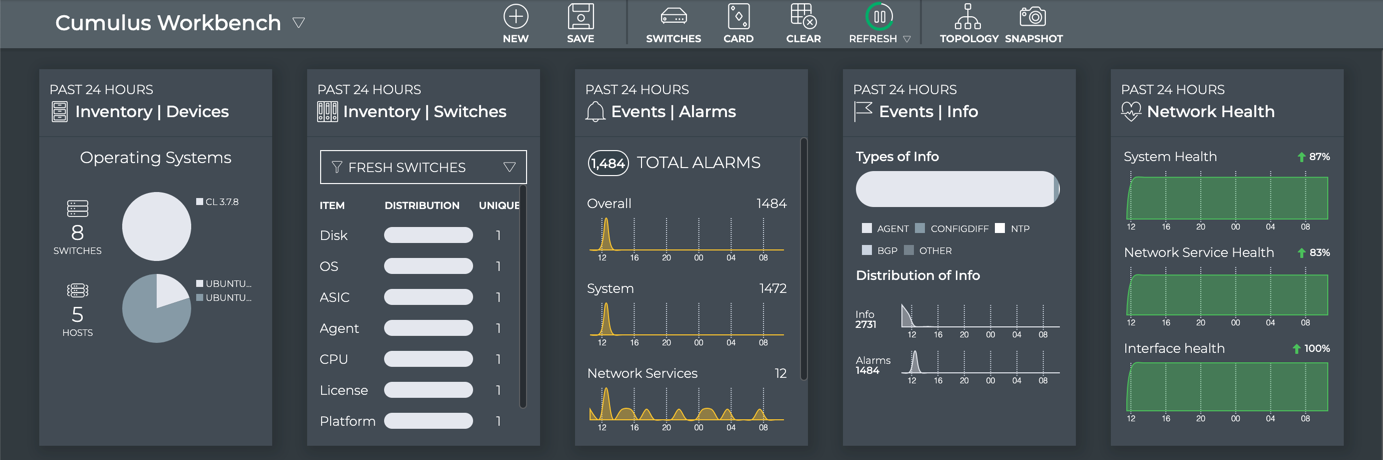
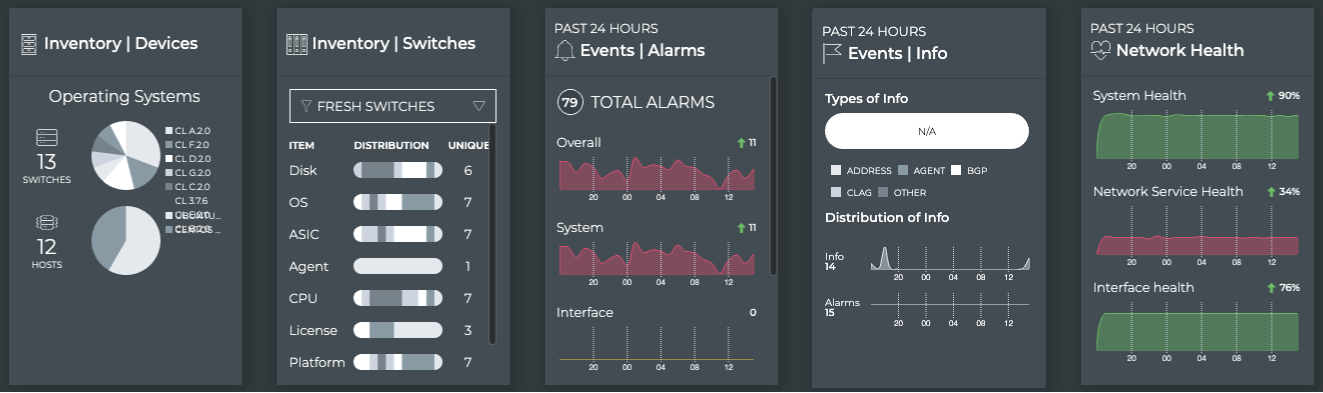
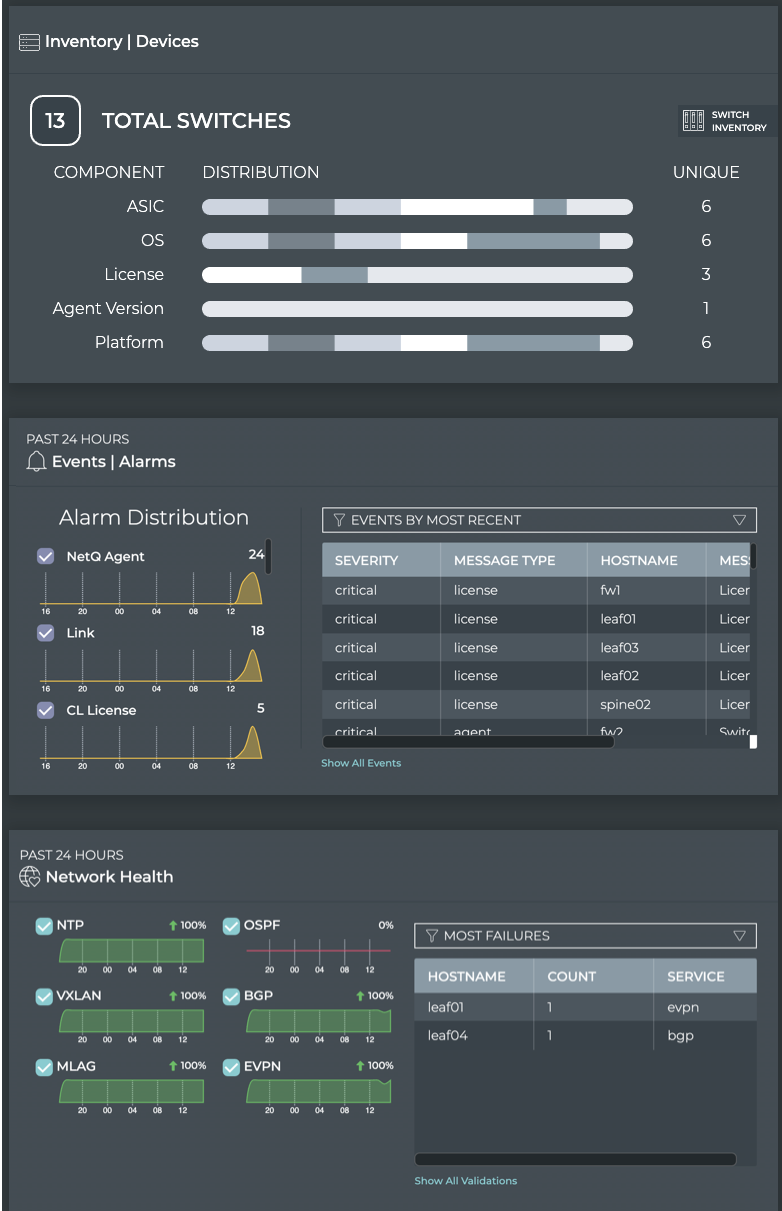
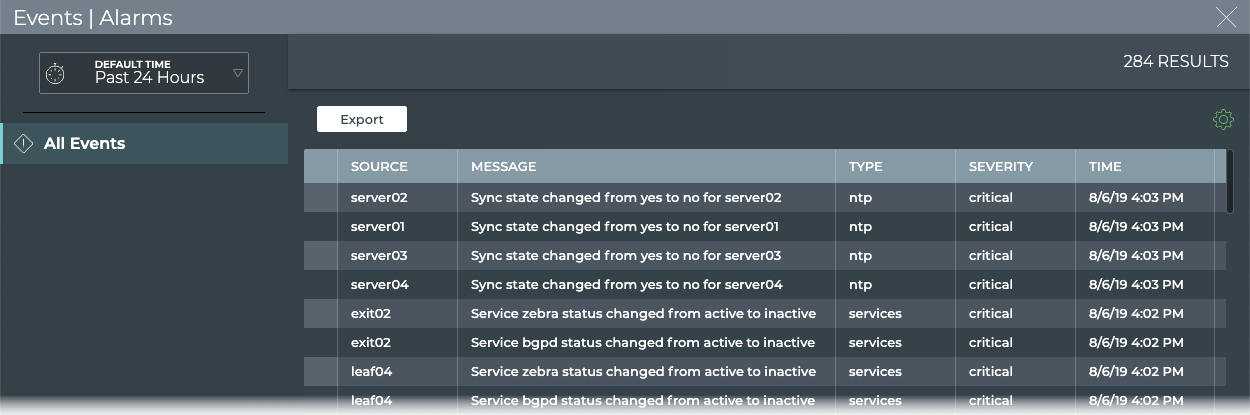
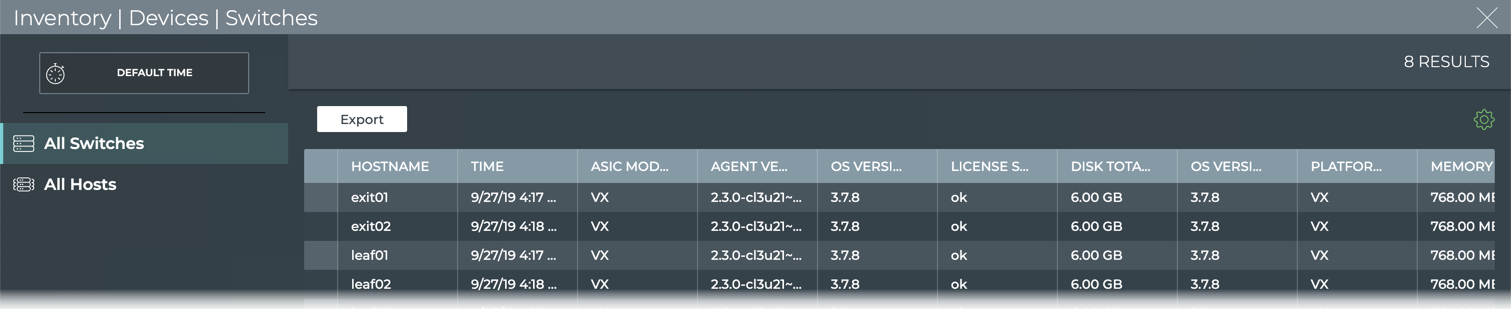
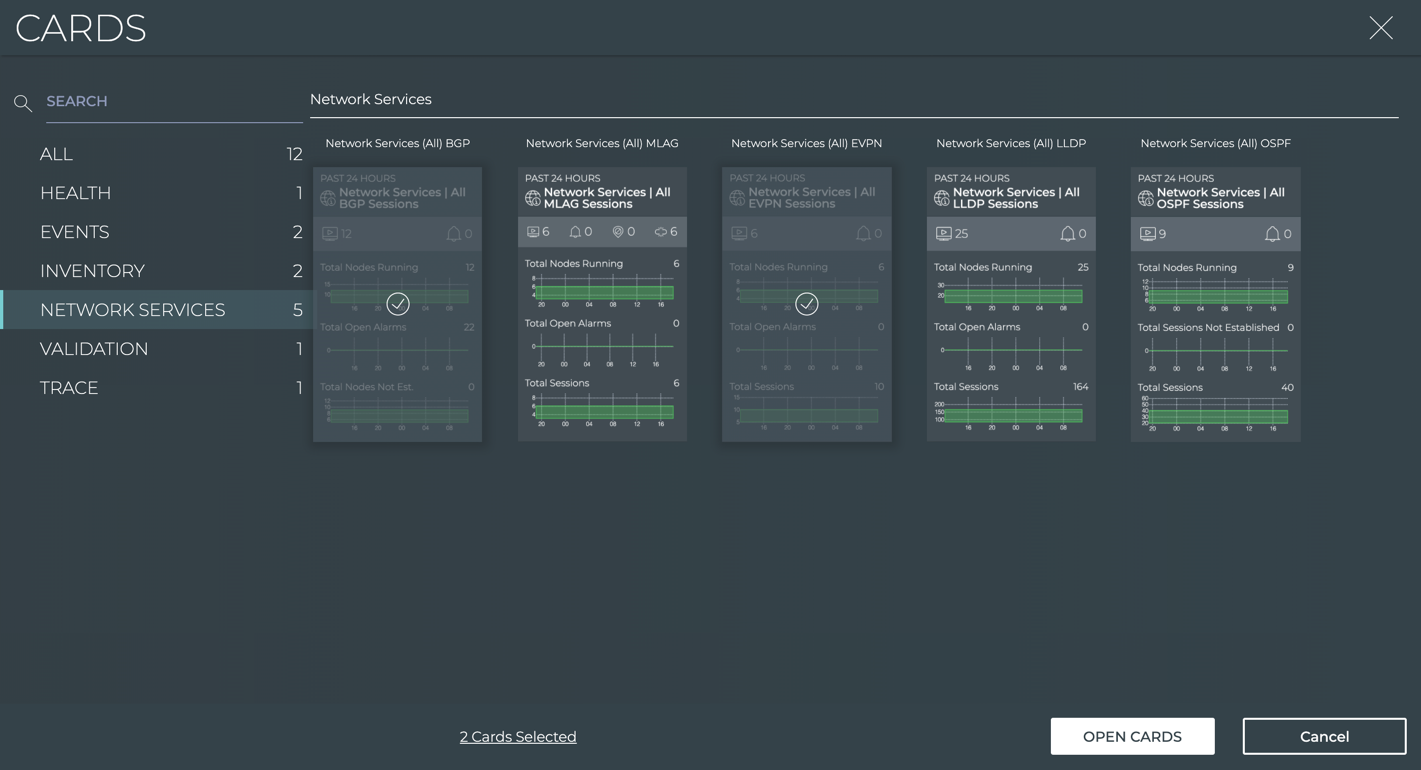
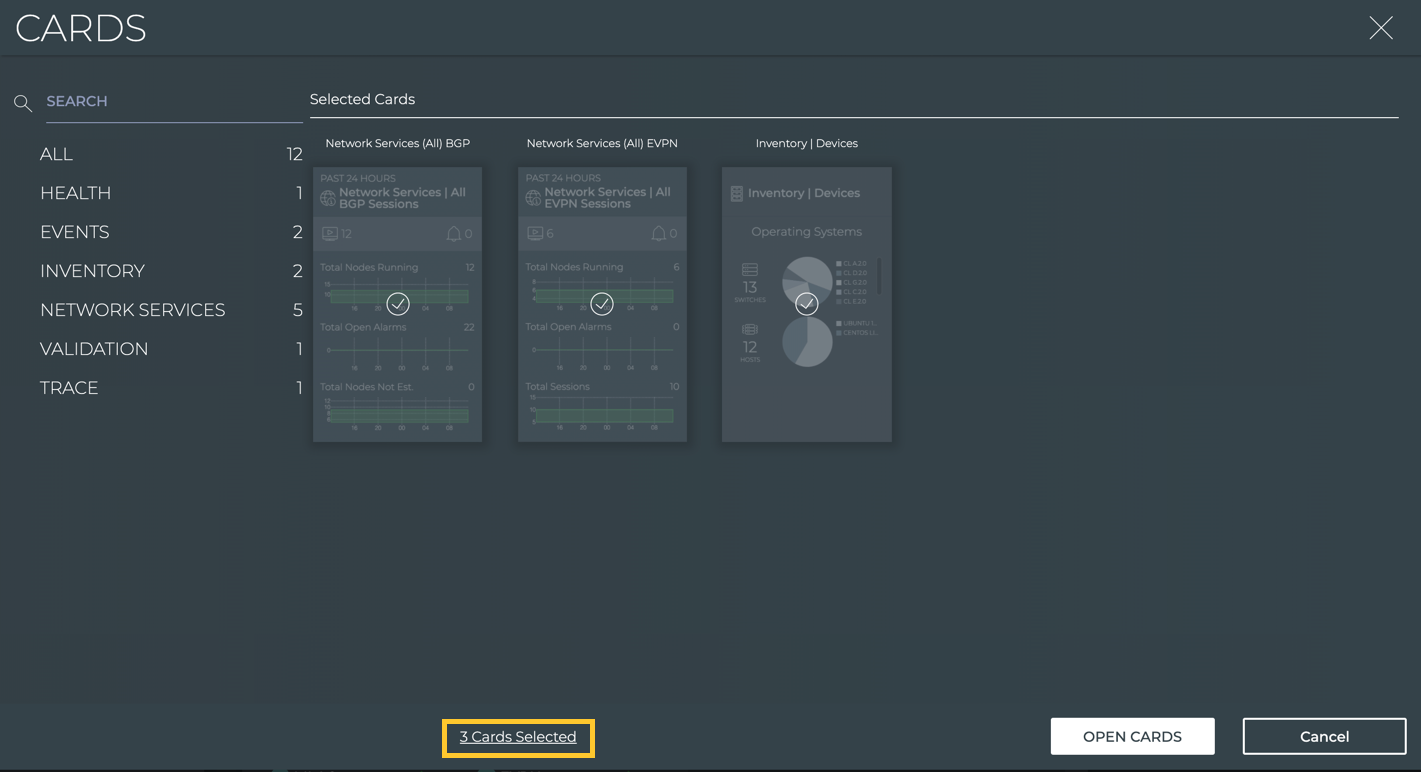
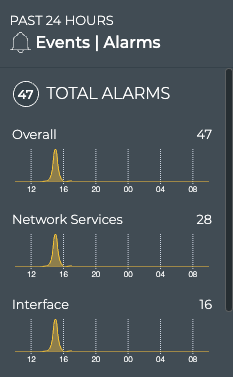
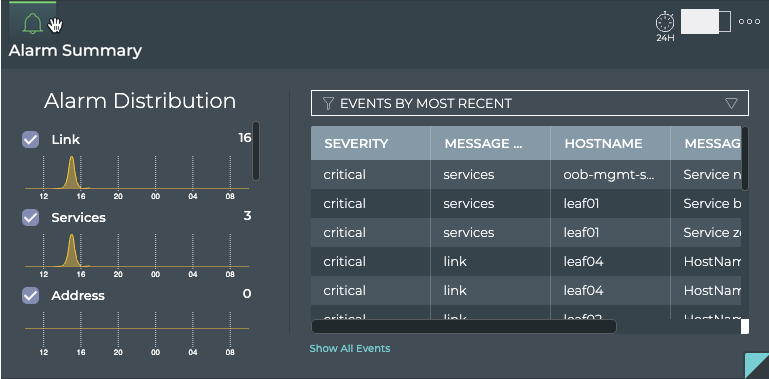
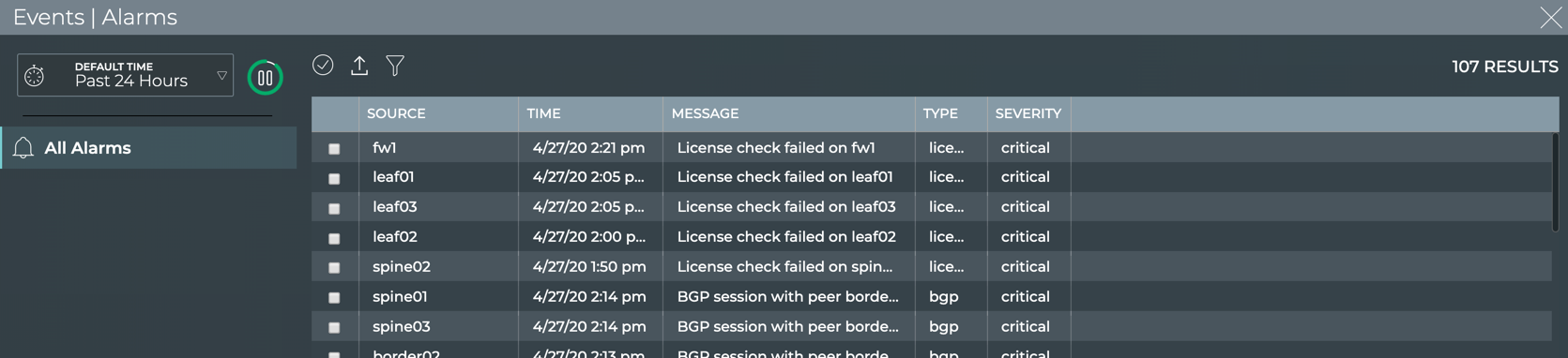
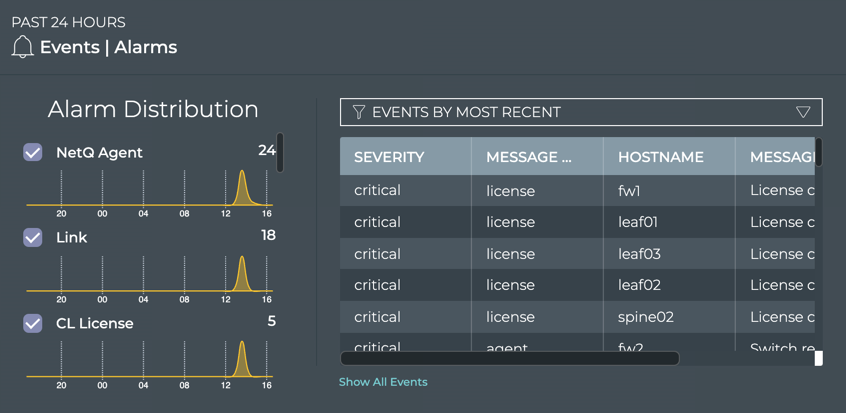
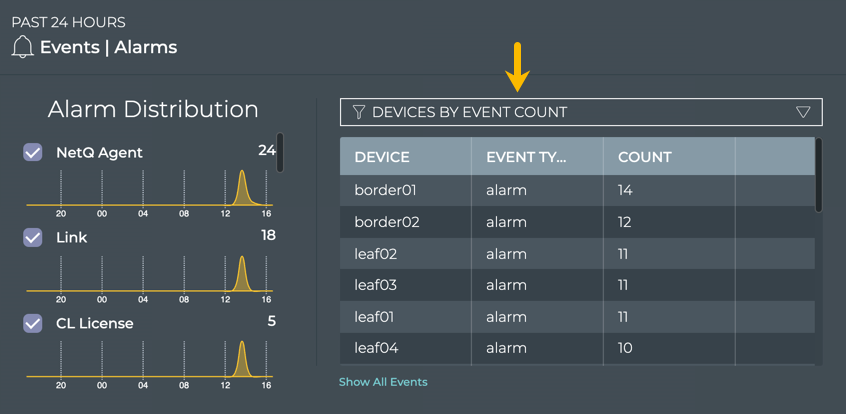
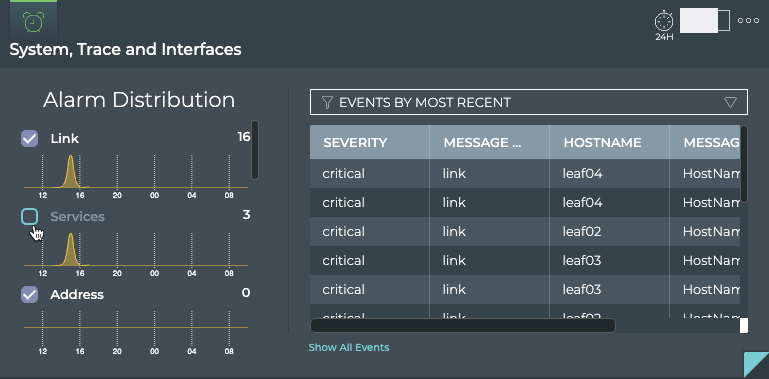
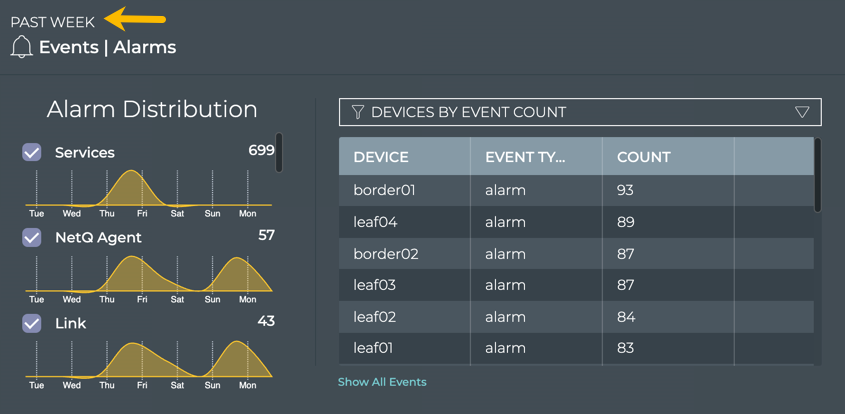
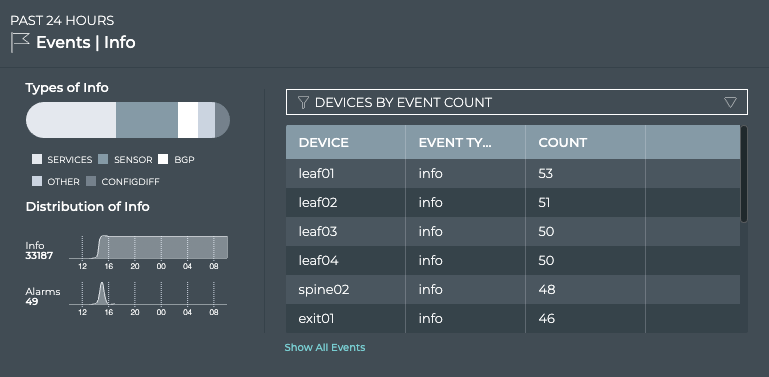
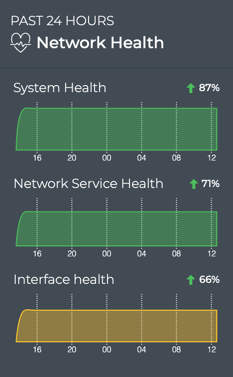
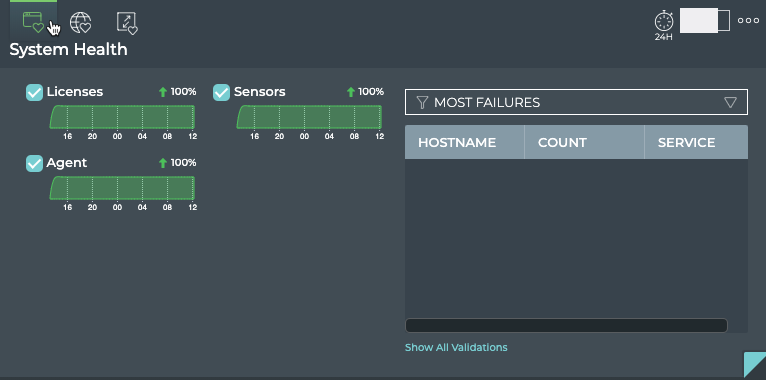
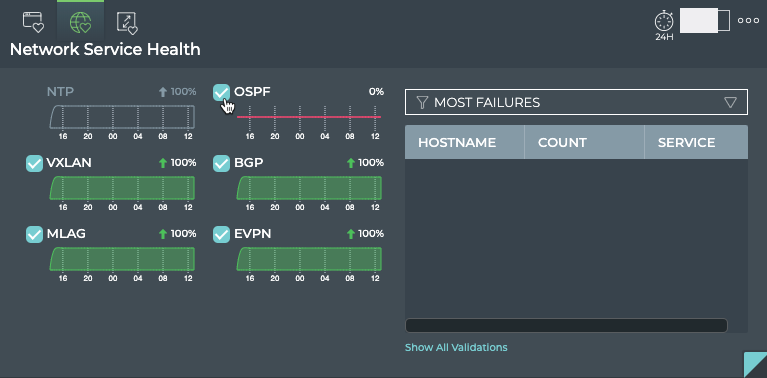
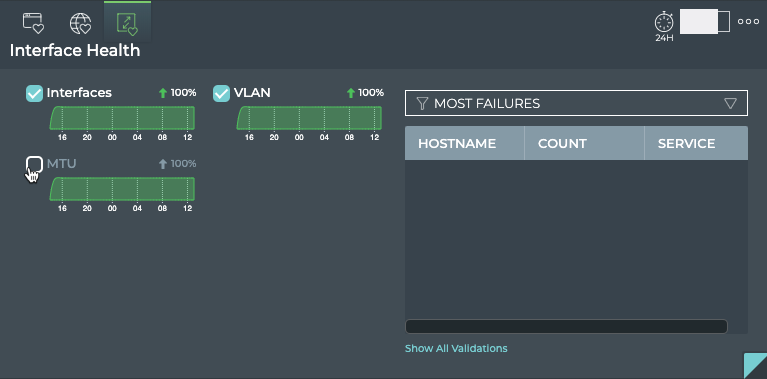
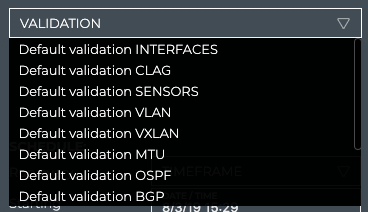
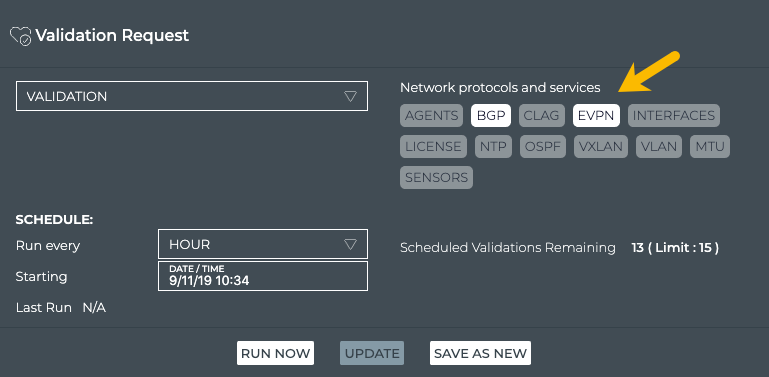
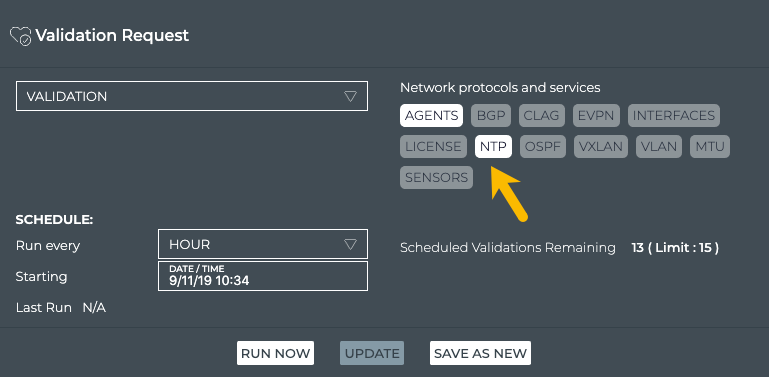
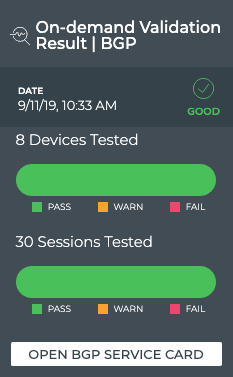
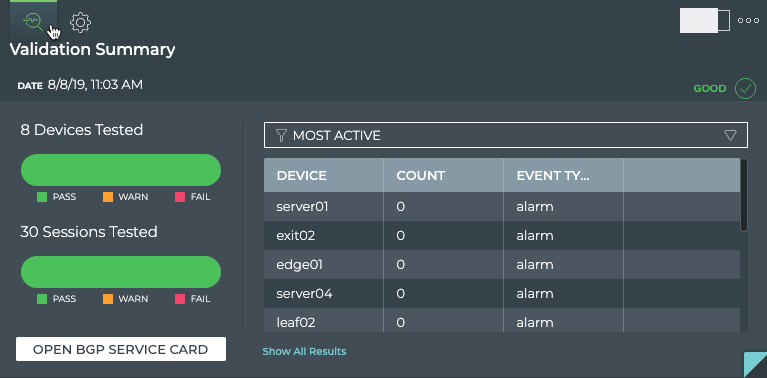
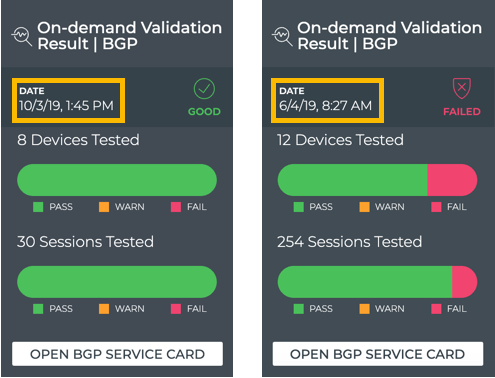
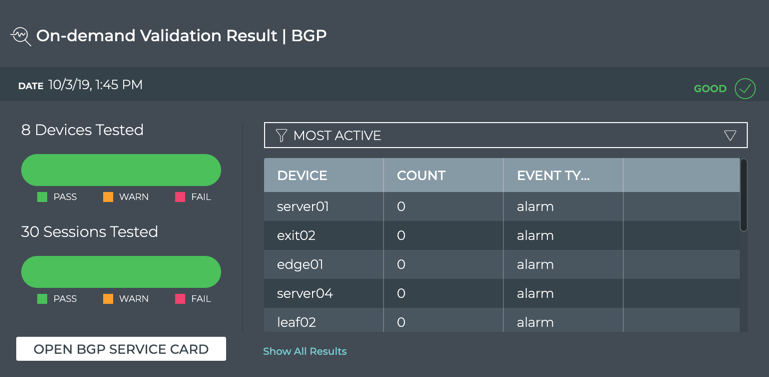
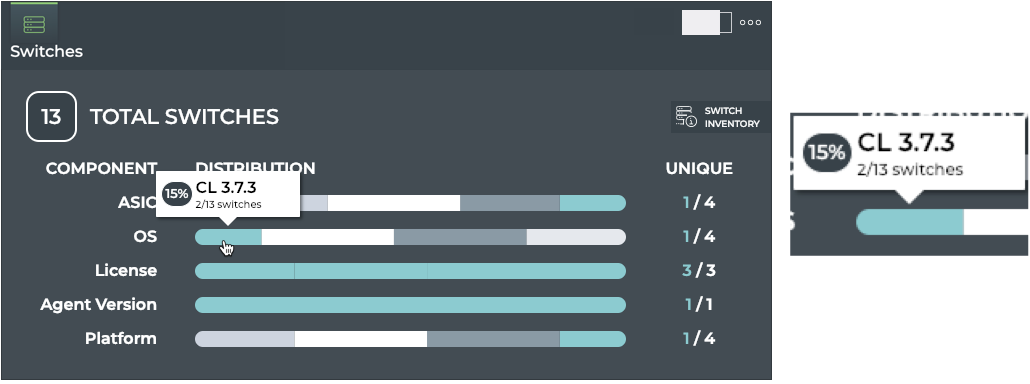
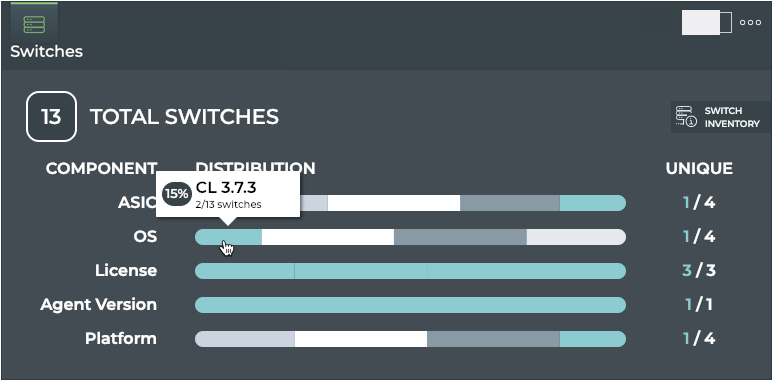
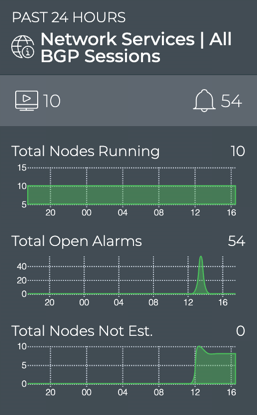
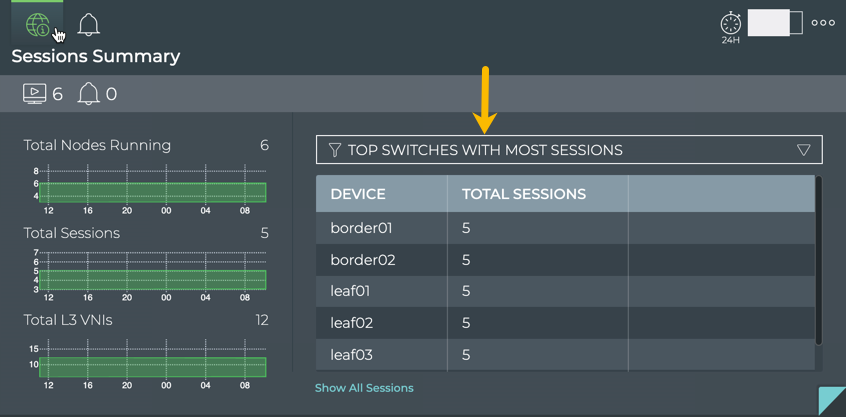
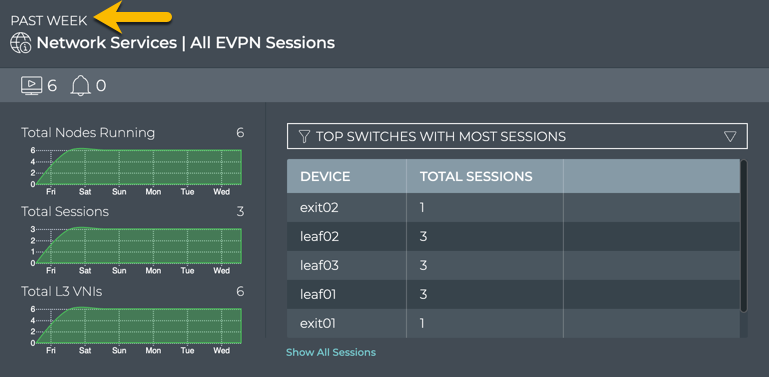
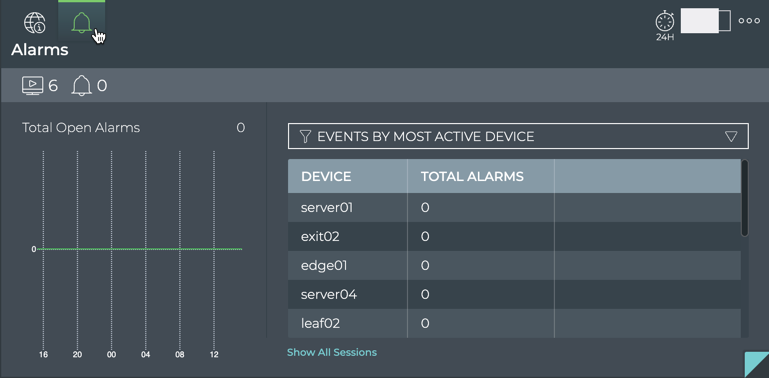
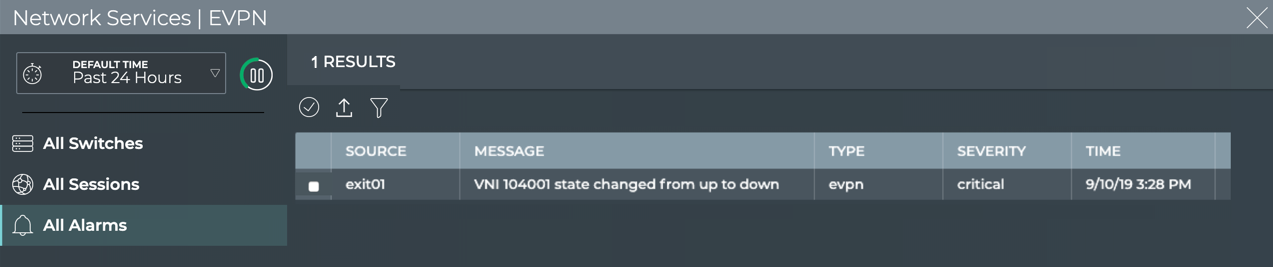
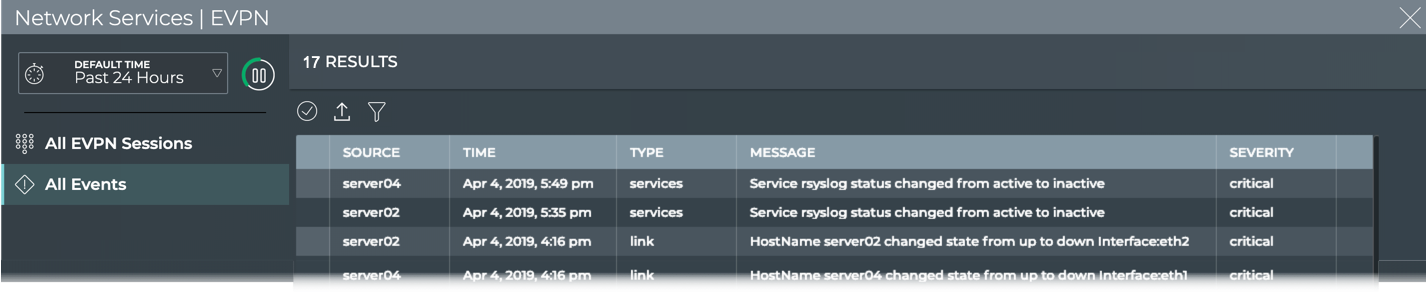
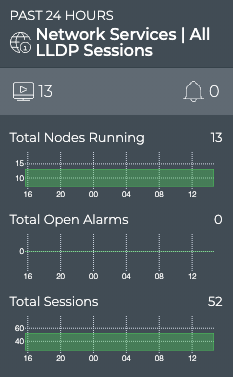
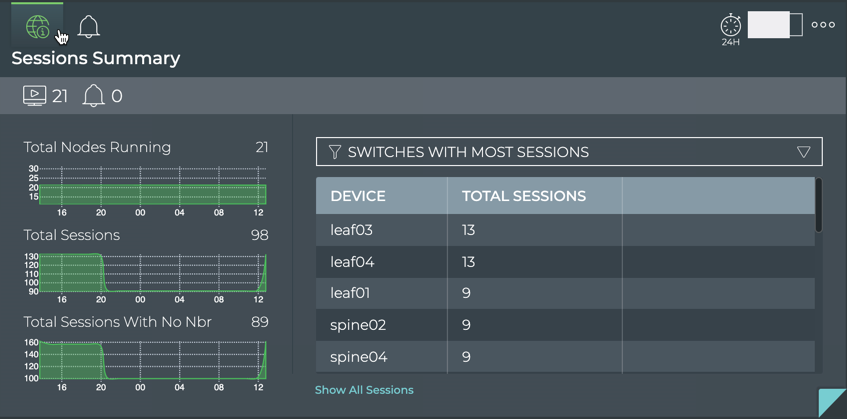
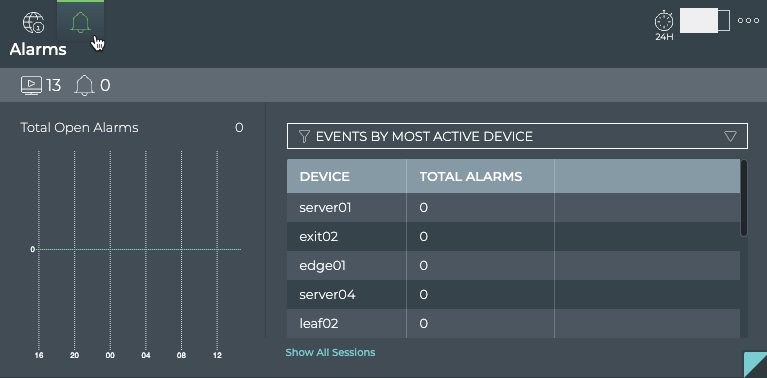
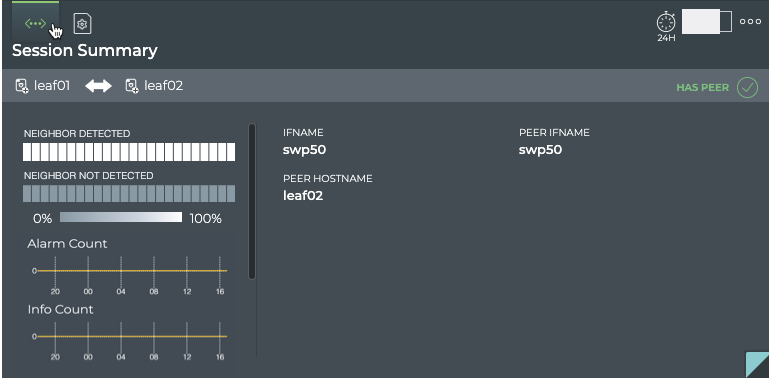
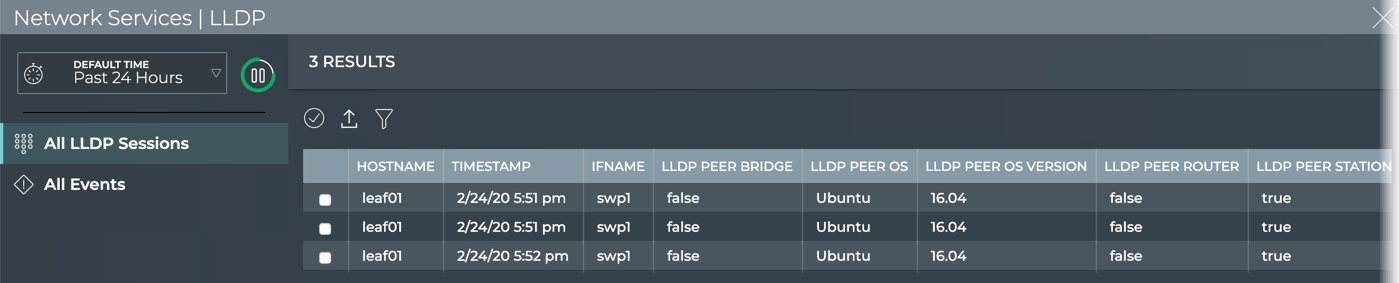
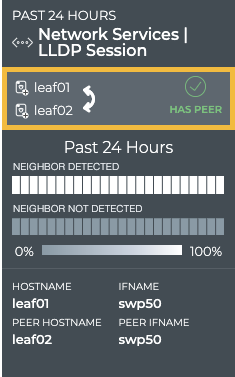
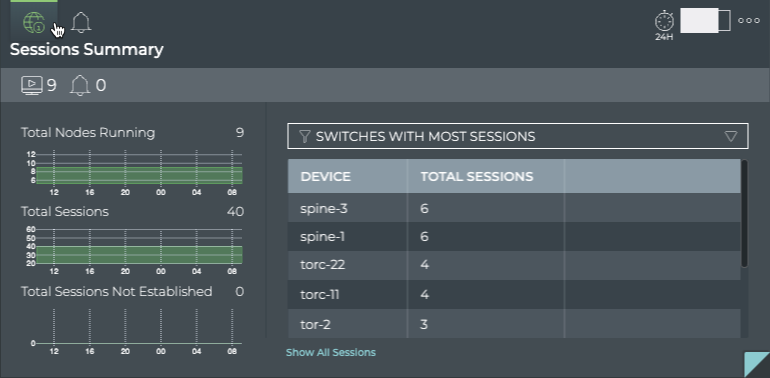
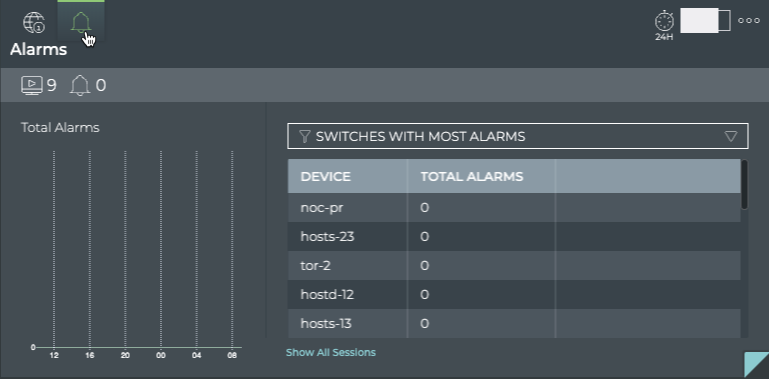
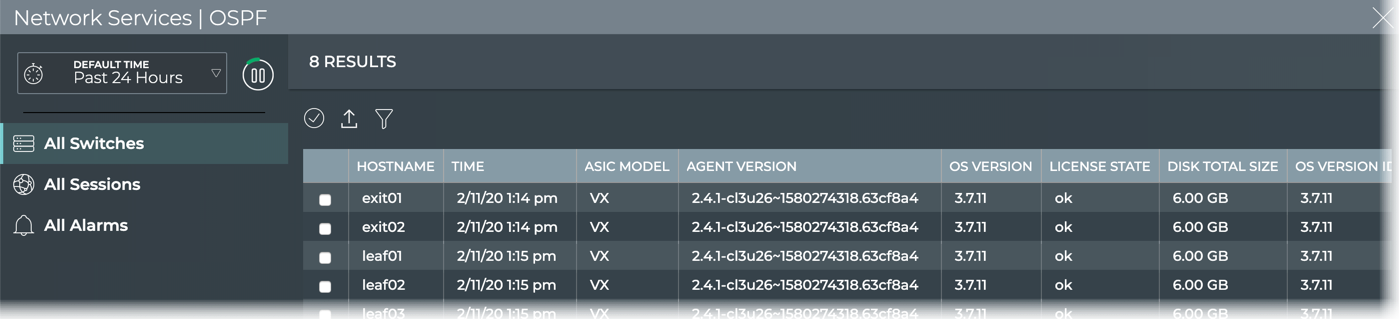
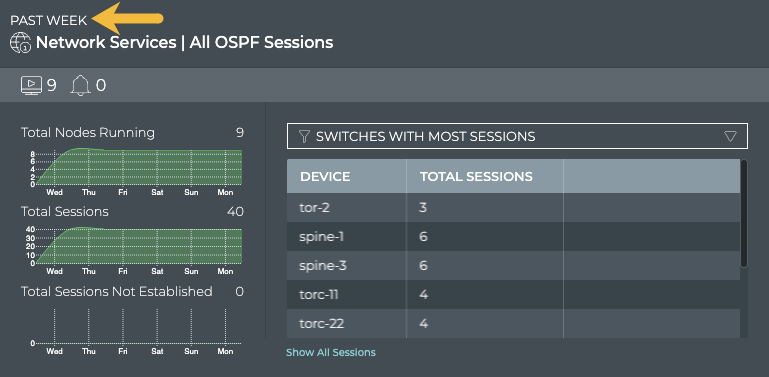
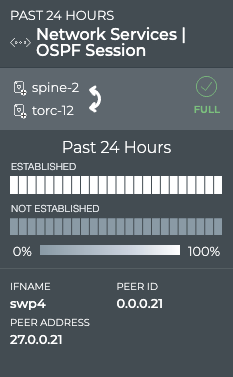
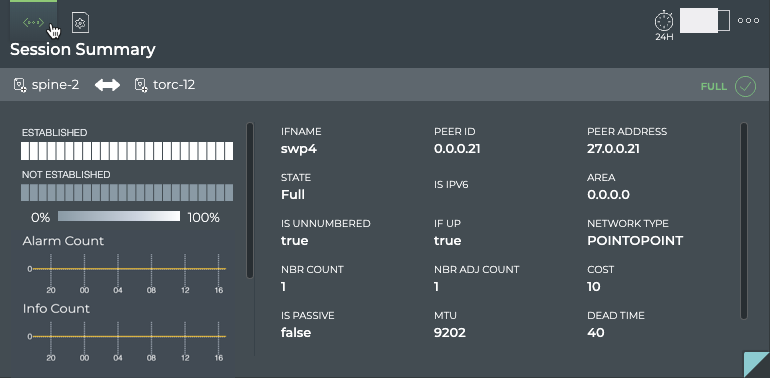
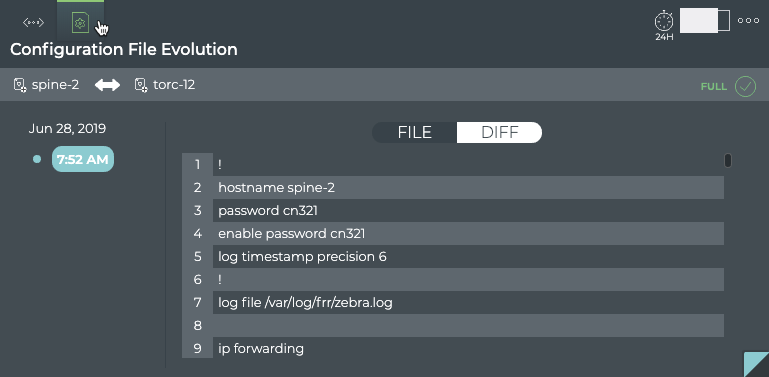
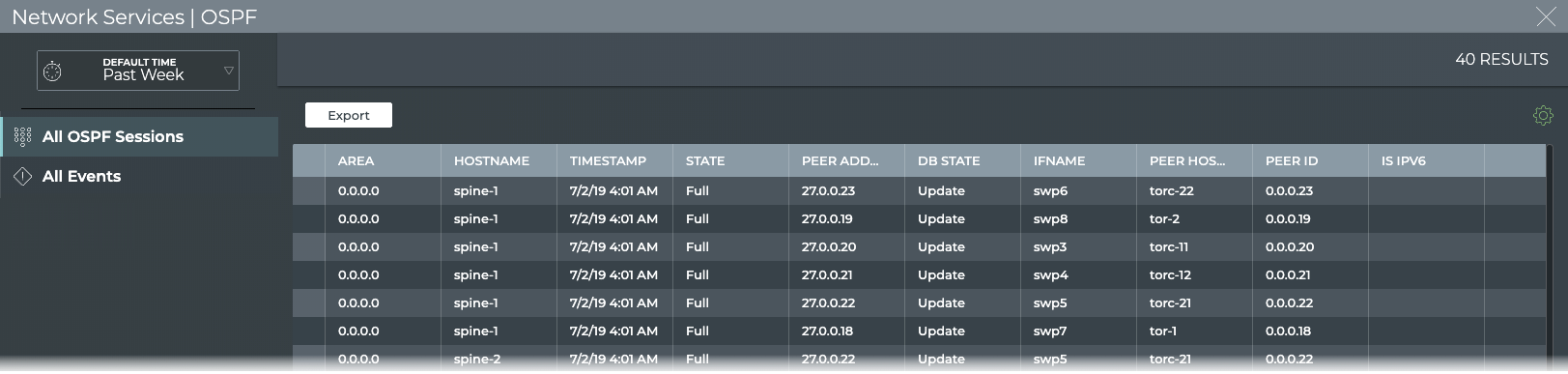
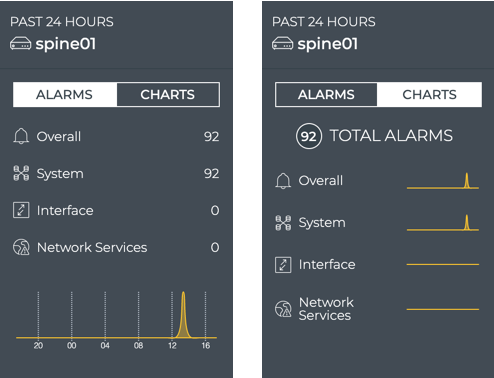
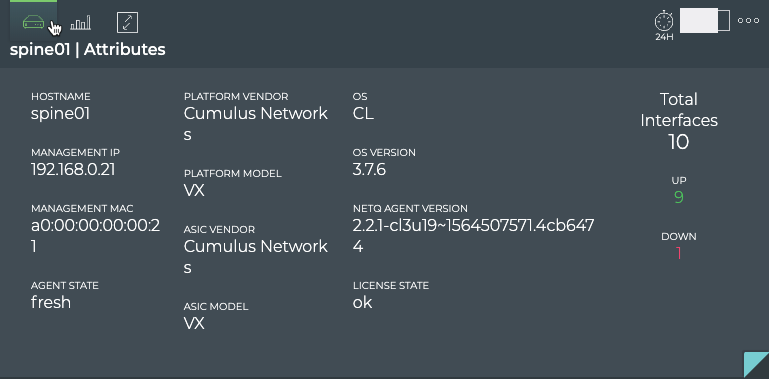
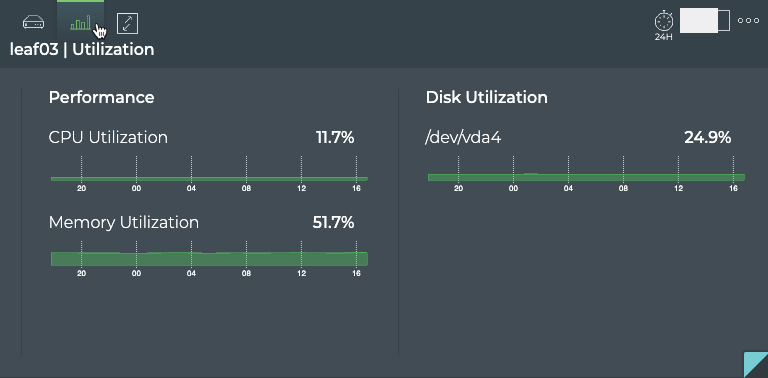
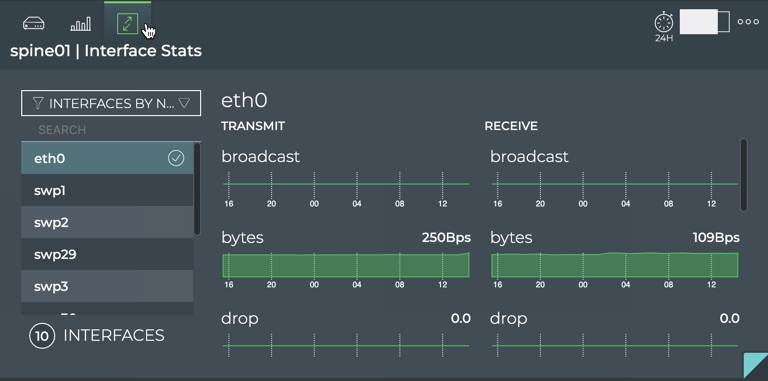
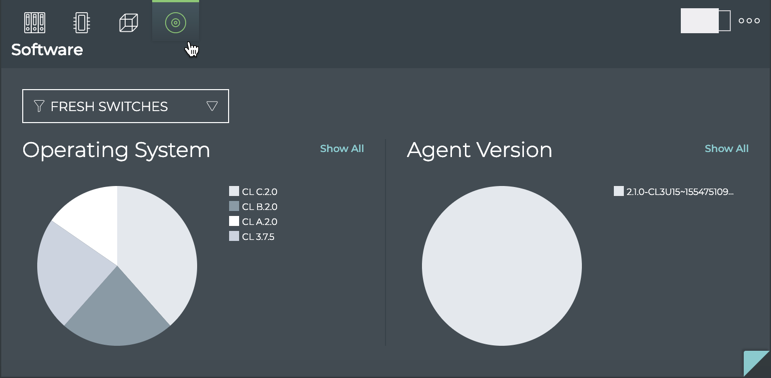
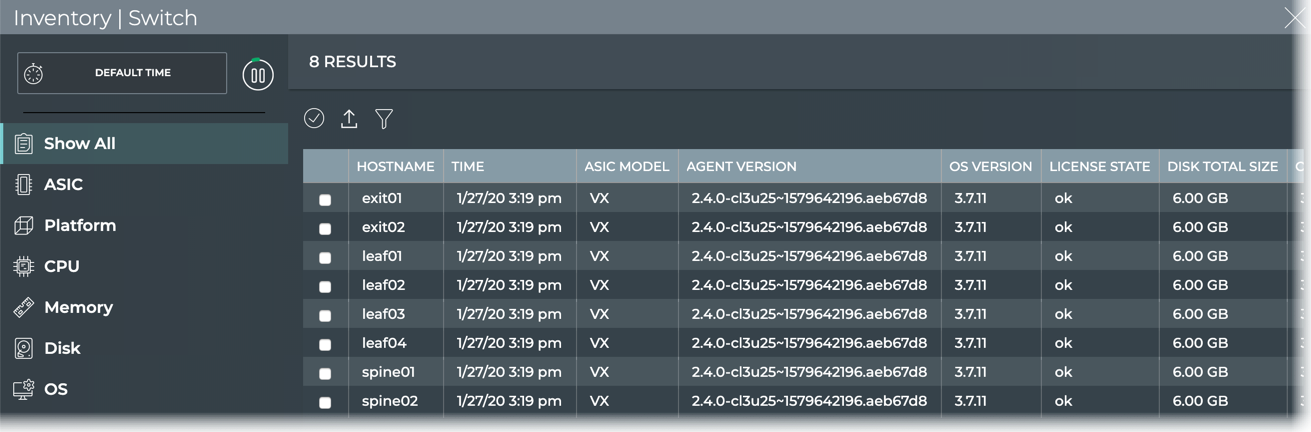
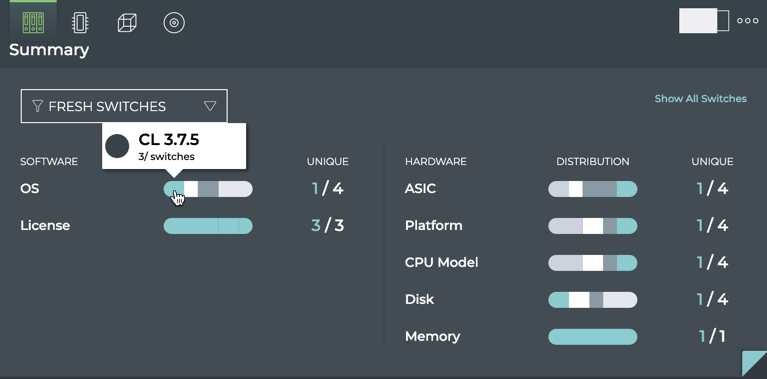
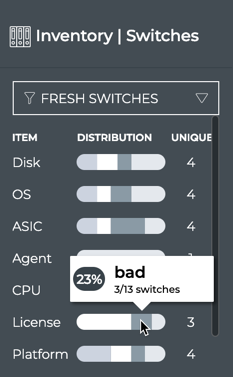
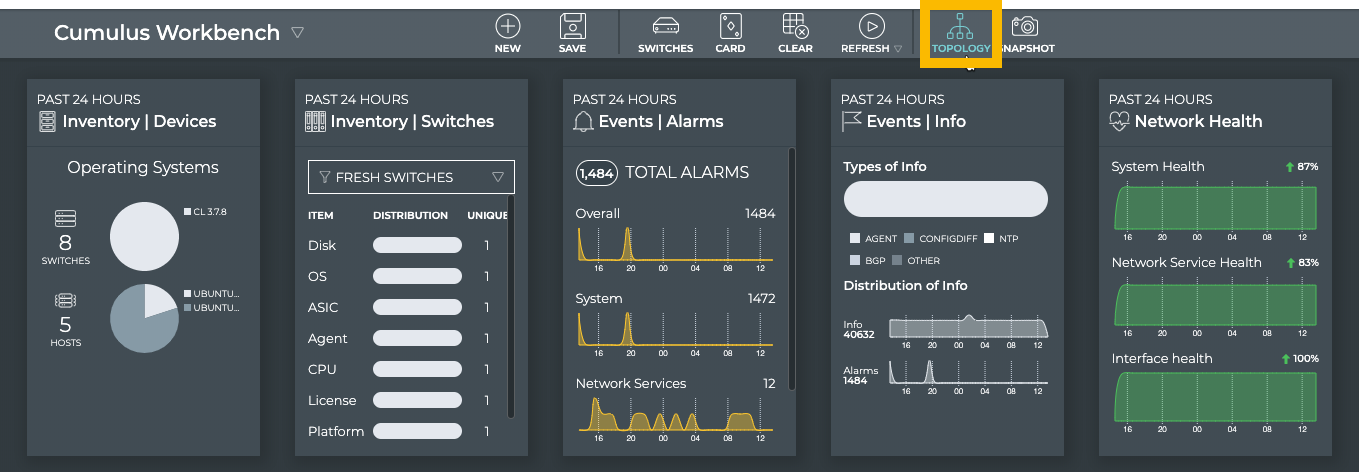
Cumulus® NetQ is a highly-scalable, modern network operations tool set that utilizes telemetry for deep troubleshooting, visibility, and automated workflows from a single GUI interface, reducing maintenance and network downtimes. It combines the ability to easily upgrade, configure and deploy network elements with a full suite of operations capabilities, such as visibility, troubleshooting, validation, trace and comparative look-back functionality.
This documentation is intended for network administrators who are responsible for deploying, configuring, monitoring and troubleshooting the network in their data center or campus environment. NetQ 3.x offers the ability to easily monitor and manage your network infrastructure and operational health. The documentation provides instructions and information about monitoring individual components of the network, the network as a whole, and the NetQ software applications using the NetQ command line interface (NetQ CLI), NetQ (graphical) user interface (NetQ UI), and NetQ Admin UI.
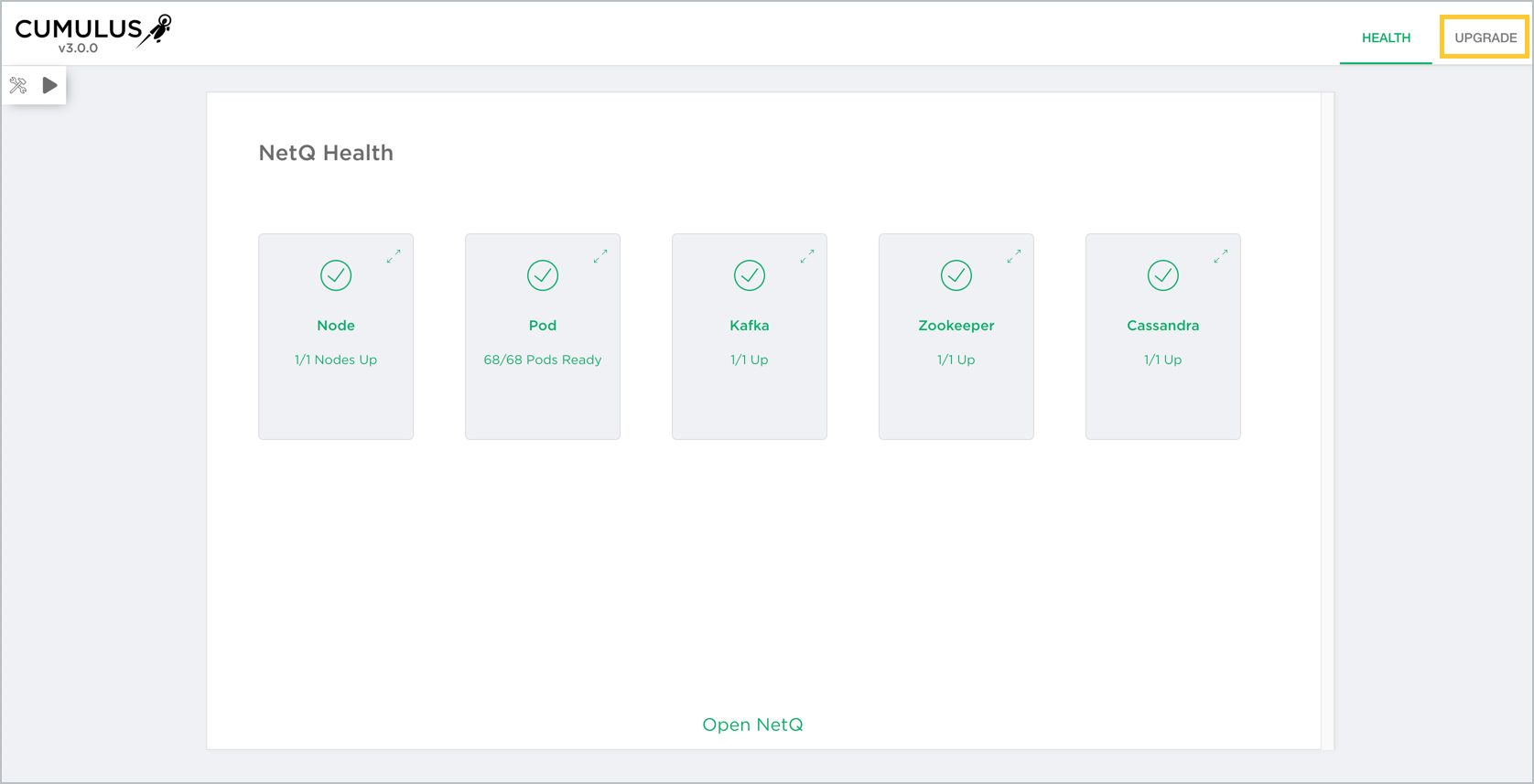
Cumulus NetQ Deployment Guide
This guide is intended for network administrators who are responsible for installation, setup, and maintenance of Cumulus NetQ in their data center environment. NetQ offers the ability to monitor and manage your data center network infrastructure and operational health with simple tools based on open source Linux. This guide provides instructions and information about installing NetQ core capabilities, configuring optional capabilities, and upgrading an existing NetQ installation. This guide assumes you have already installed Cumulus Linux on your network switches and you are ready to add these NetQ capabilities.
Before you get started, you should review the release notes for this version.
Cumulus NetQ Overview
Cumulus® NetQ is a highly-scalable, modern network operations tool set
that provides visibility and troubleshooting of your overlay and
underlay networks in real-time. NetQ delivers actionable insights and
operational intelligence about the health of your data center - from the
container, virtual machine, or host, all the way to the switch and port.
NetQ correlates configuration and operational status, and instantly
identifies and tracks state changes while simplifying management for the
entire Linux-based data center. With NetQ, network operations change
from a manual, reactive, box-by-box approach to an automated, informed
and agile one.
Cumulus NetQ performs three primary
functions:
Data collection: real-time and historical telemetry and network
state information
Data analytics: deep processing of the data
Data visualization: rich graphical user interface (GUI) for
actionable insight
NetQ is available as an on-site or in-cloud deployment.
Unlike other network operations tools, NetQ delivers significant
operational improvements to your network
management and maintenance processes. It simplifies the data center
network by reducing the complexity through real-time visibility into
hardware and software status and eliminating the guesswork associated
with investigating issues through the analysis and presentation of
detailed, focused data.
Demystify Overlay Networks
While overlay networks provide significant advantages in network
management, it can be difficult to troubleshoot issues that occur in the
overlay one box at a time. You are unable to correlate what events
(configuration changes, power outages, etc.) may have caused problems in
the network and when they occurred. Only a sampling of data is available
to use for your analysis. By contrast, with Cumulus NetQ deployed, you
have a network-wide view of the overlay network, can correlate events
with what is happening now or in the past, and have real-time data to
fill out the complete picture of your network health and operation.
In summary:
Without NetQ
With NetQ
Difficult to debug overlay network
View network-wide status of overlay network
Hard to find out what happened in the past
View historical activity with time-machine view
Periodically sampled data
Real-time collection of telemetry data for a more complete data set
Protect Network Integrity with NetQ Validation
Network configuration changes can cause numerous trouble tickets because
you are not able to test a new configuration before deploying it. When
the tickets start pouring in, you are stuck with a large amount of data
that is collected and stored in multiple tools making correlation of the
events to the resolution required difficult at best. Isolating faults in
the past is challenging. By contract, with Cumulus NetQ deployed, you
can proactively verify a configuration change as inconsistencies and
misconfigurations can be caught prior to deployment. And historical data
is readily available to correlate past events with current issues.
In summary:
Without NetQ
With NetQ
Reactive to trouble tickets
Catch inconsistencies and misconfigurations prior to deployment with integrity checks/validation
Large amount of data and multiple tools to
correlate the logs/events with the issues
Correlate network status, all in one place
Periodically sampled data
Readily available historical data for viewing and correlating changes in the past with current issues
Troubleshoot Issues Across the Network
Troubleshooting networks is challenging in the best of times, but trying
to do so manually, one box at a time, and digging through a series of
long and ugly logs make the job harder than it needs to be. Cumulus NetQ
provides rolled up and correlated network status on a regular basis,
enabling you to get down to the root of the problem quickly, whether it
occurred recently or over a week ago. The graphical user interface makes
this possible visually to speed the analysis.
In summary:
Without NetQ
With NetQ
Large amount of data and multiple tools to
correlate the logs/events with the issues
Rolled up and correlated network status, view events and status together
Past events are lost
Historical data gathered and stored for comparison with current network state
Manual, box-by-box troubleshooting
View issues on all devices all at once, pointing to the source of the problem
Track Connectivity with NetQ Trace
Conventional trace only traverses the data path looking for problems,
and does so on a node to node basis. For paths with a small number of
hops that might be fine, but in larger networks, it can become extremely
time consuming. With Cumulus NetQ both the data and control paths are
verified providing additional information. It discovers
misconfigurations along all of the hops in one go, speeding the time to
resolution.
In summary:
Without NetQ
With NetQ
Trace covers only data path; hard to check control path
Both data and control paths are verified
View portion of entire path
View all paths between devices all at once to find problem paths
Node-to-node check on misconfigurations
View any misconfigurations along all hops from source to destination
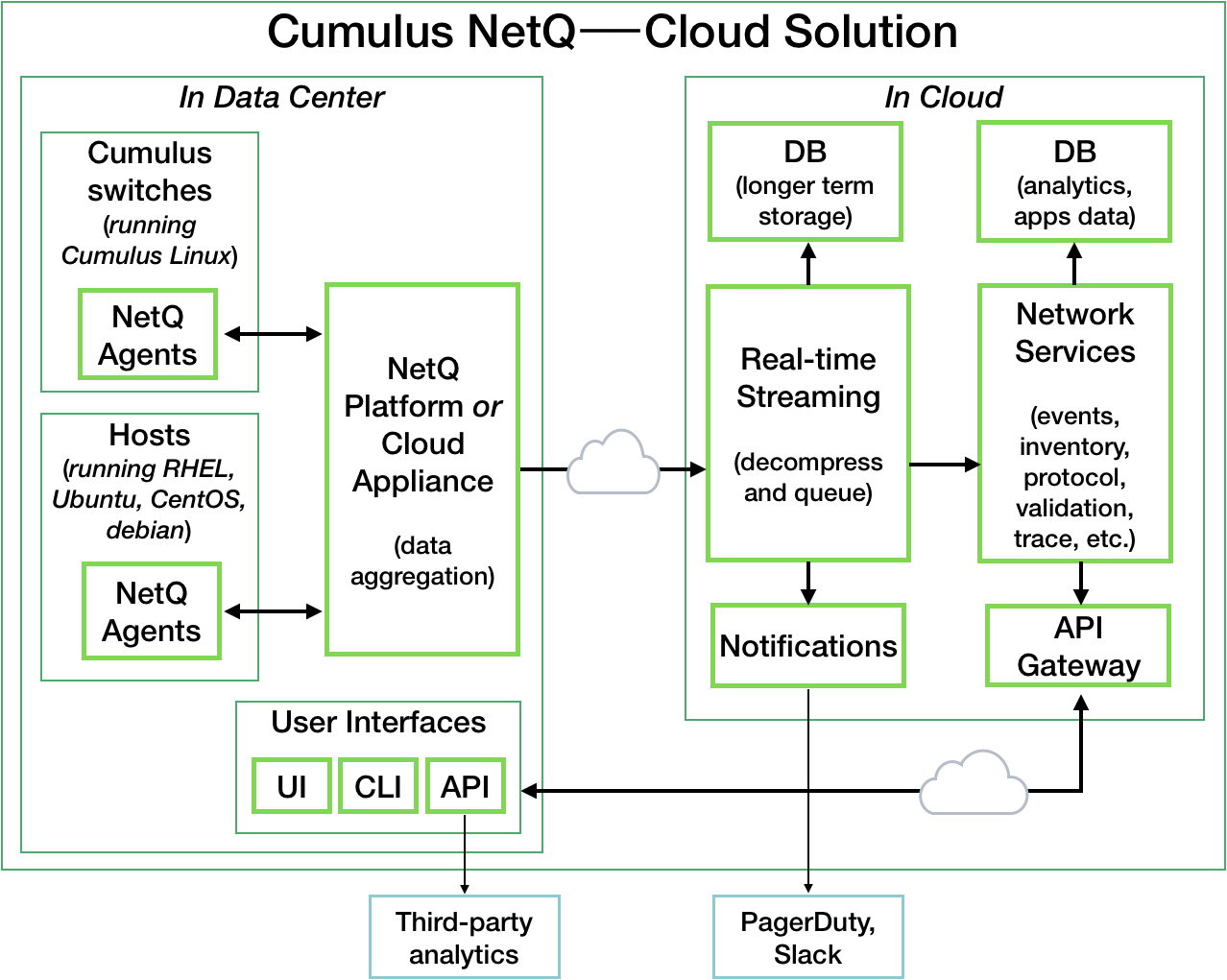
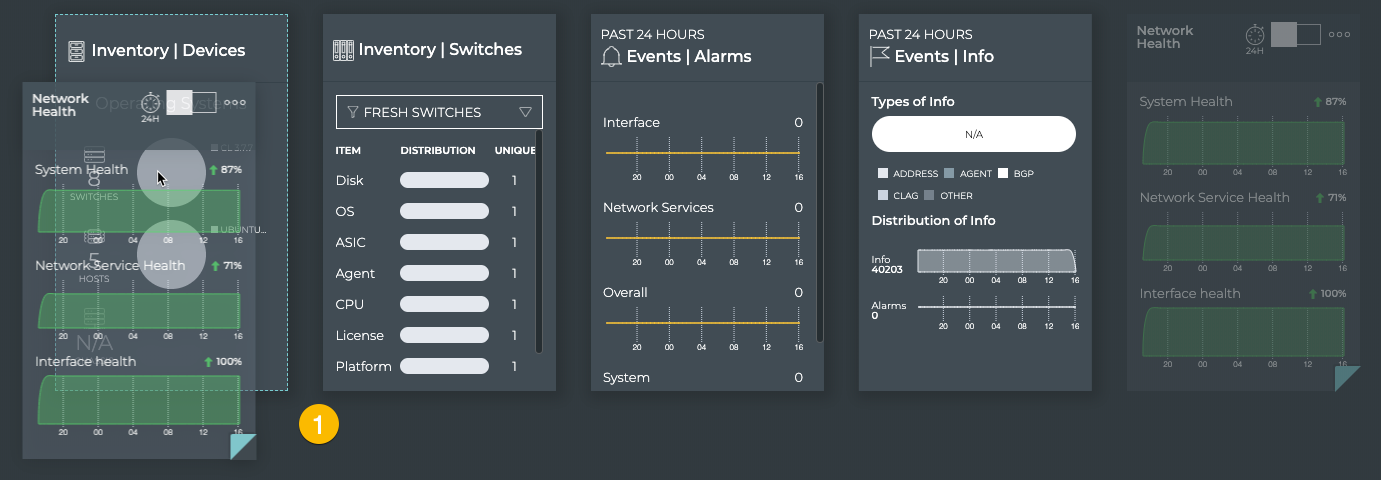
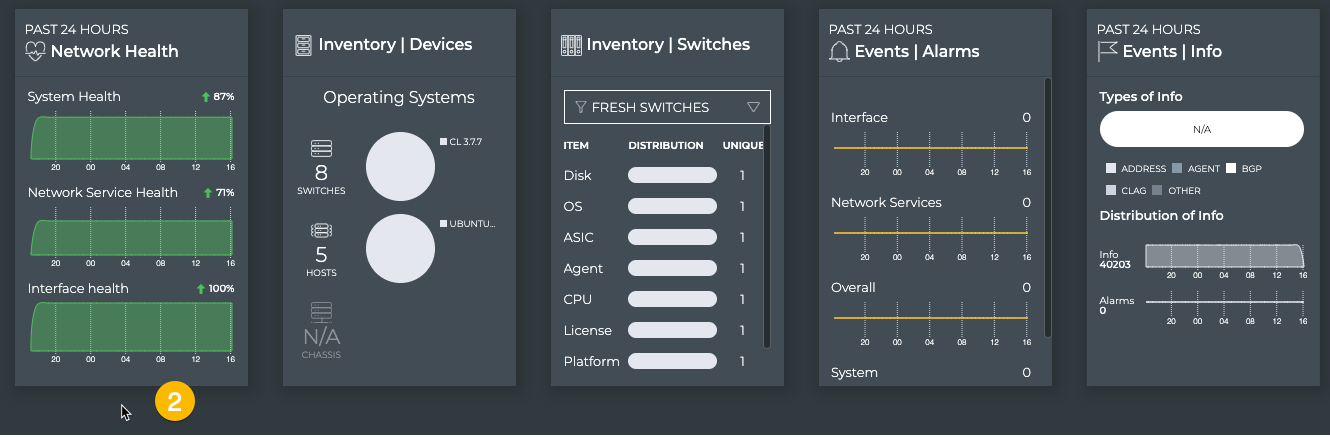
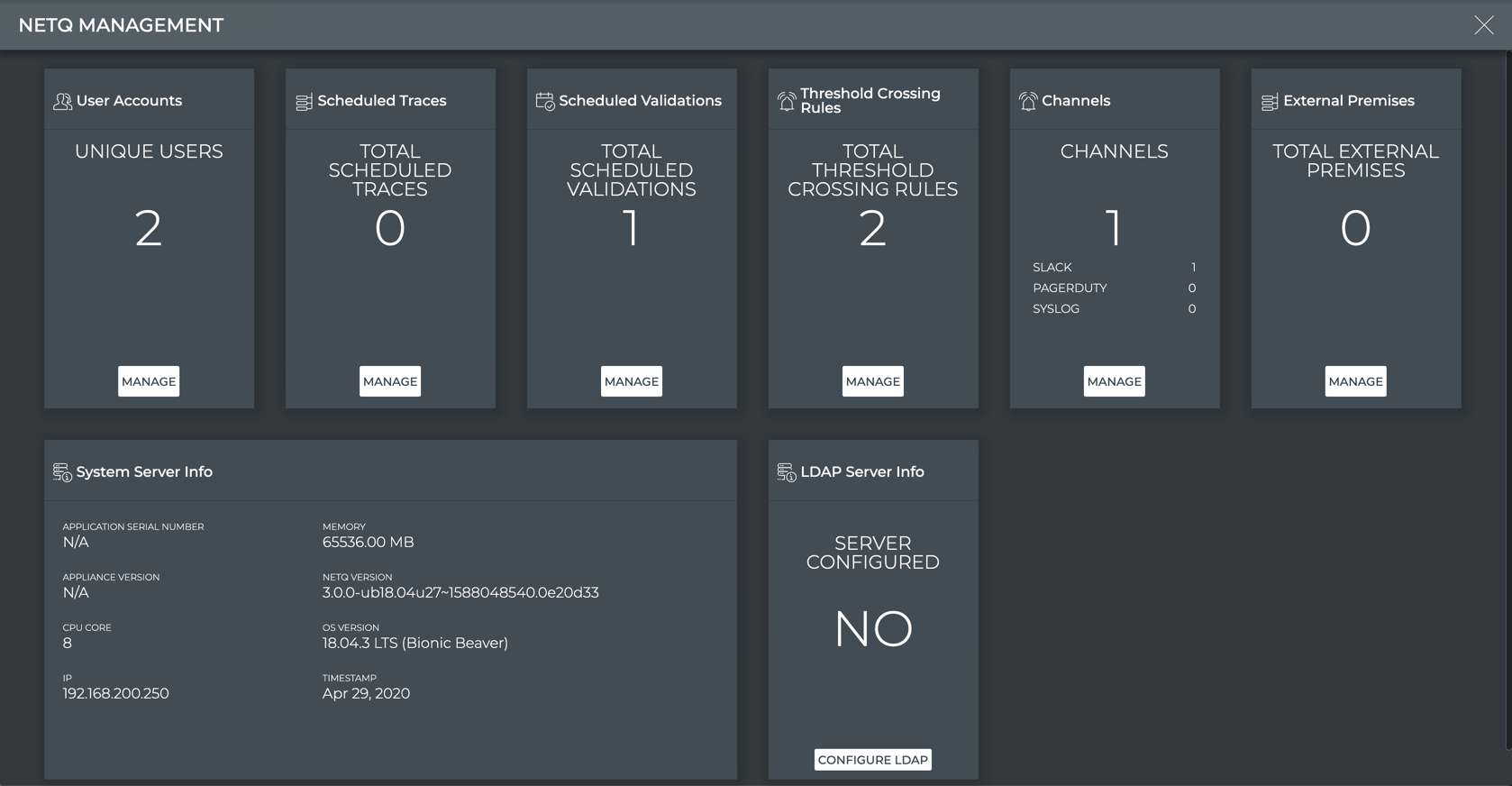
Cumulus NetQ Components
Cumulus NetQ contains the following applications and key components:
Telemetry data collection and aggregation
NetQ switch agents
NetQ host agents
Telemetry data aggregation
Database
Data streaming
Network services
User interfaces
While these function apply to both the on-site and in-cloud solutions, where
the functions reside varies, as shown here.
NetQ interfaces with event notification applications, third-party
analytics tools.
Each of the NetQ components used to gather, store and process data about
the network state are described here.
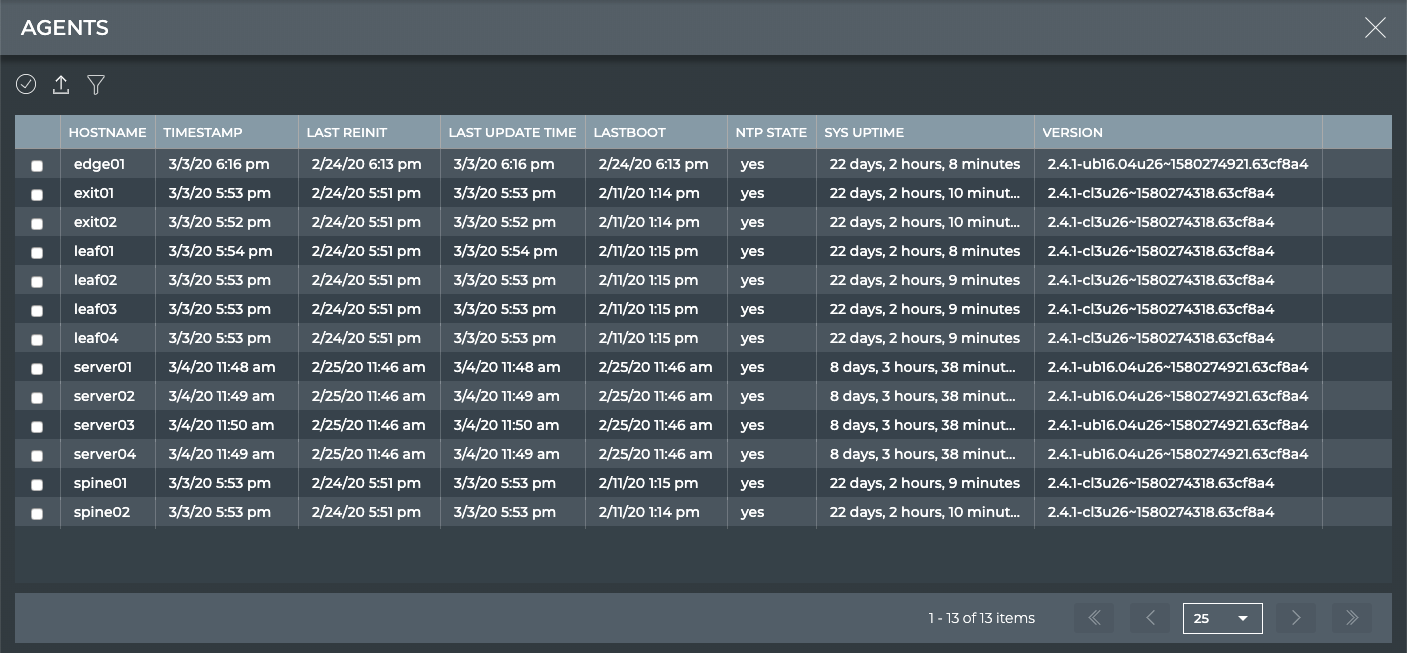
NetQ Agents
NetQ Agents are software installed and running on every monitored node
in the network - including Cumulus® Linux® switches, Linux bare-metal
hosts, and virtual machines. The NetQ Agents push network data regularly
and event information immediately to the NetQ Platform.
Switch Agents
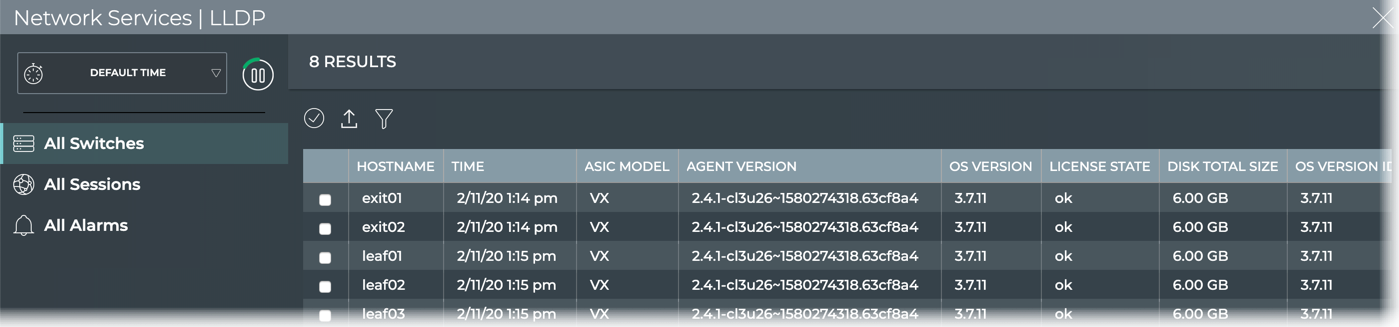
The NetQ Agents running on Cumulus Linux switches gather the following
network data via Netlink:
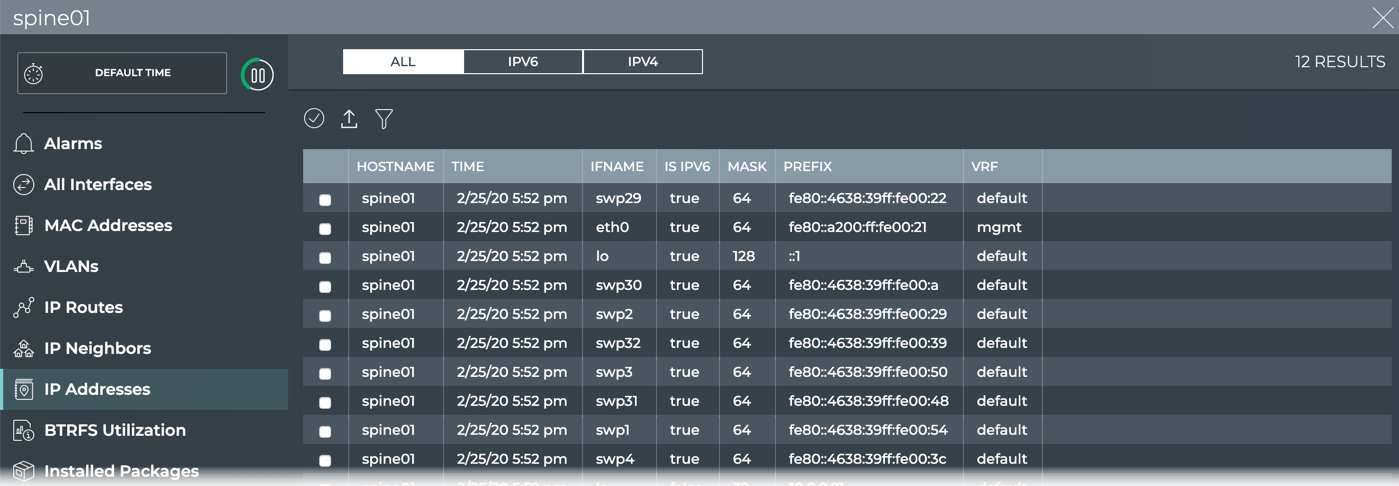
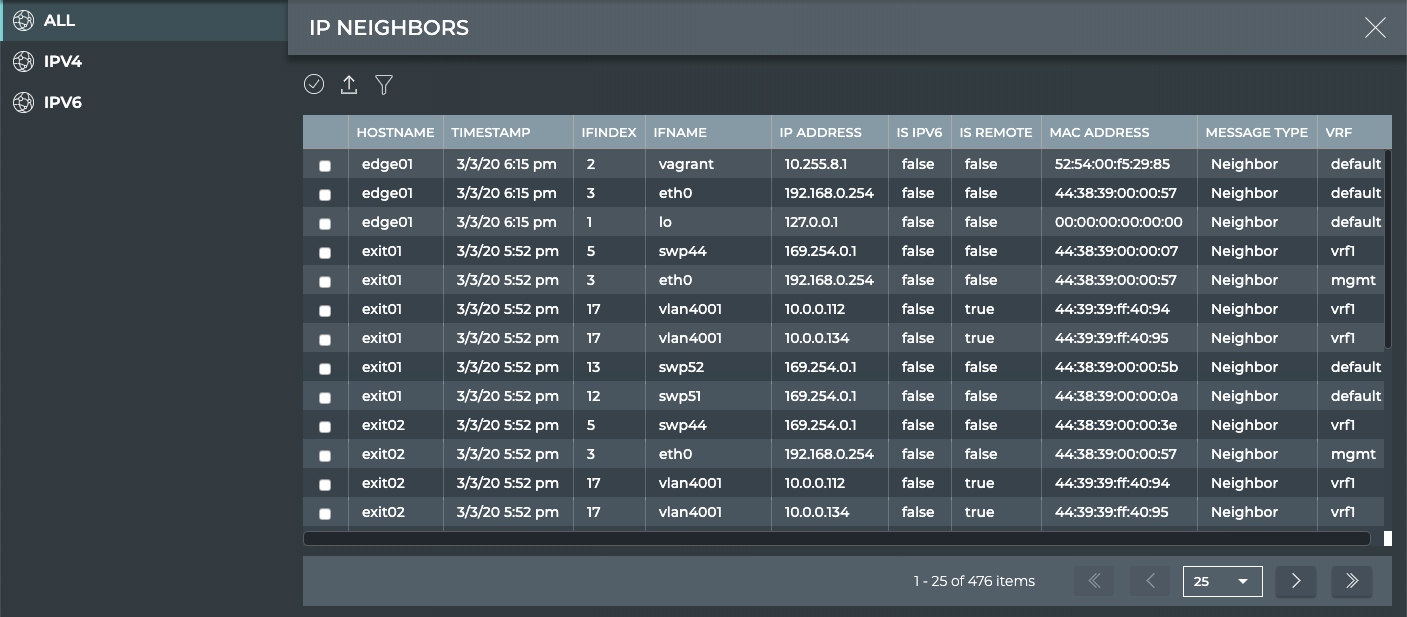
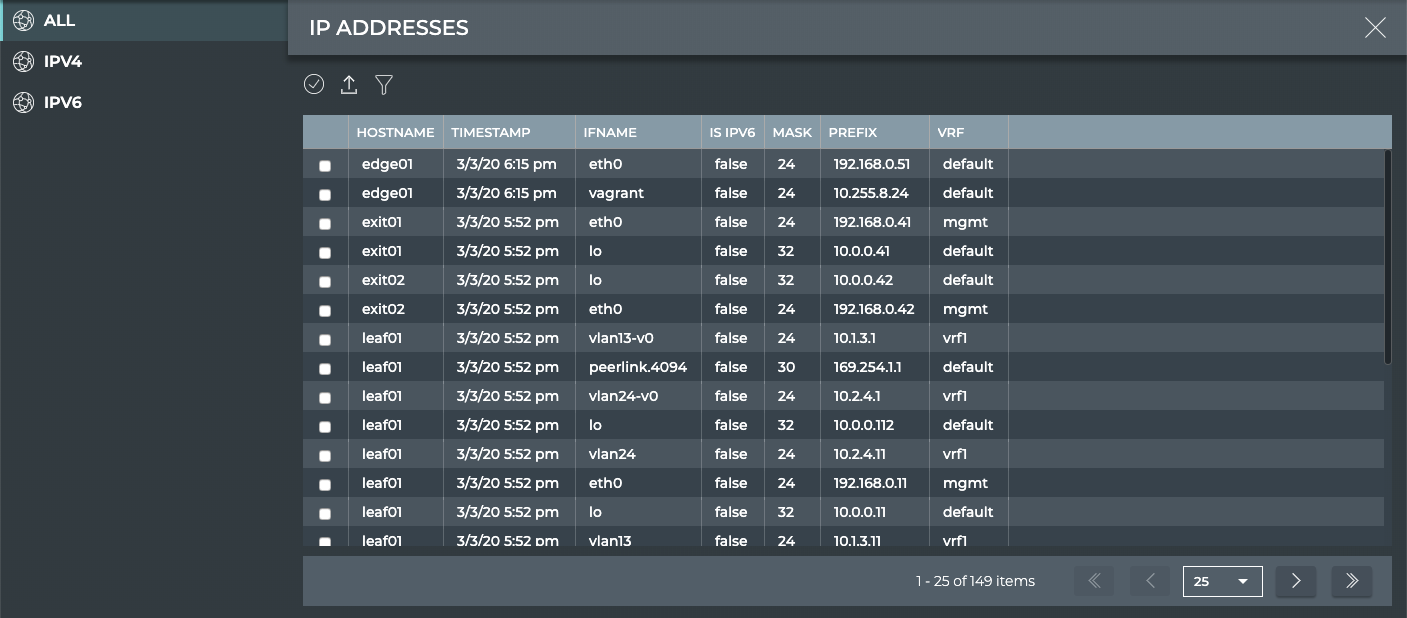
Interfaces
IP addresses (v4 and v6)
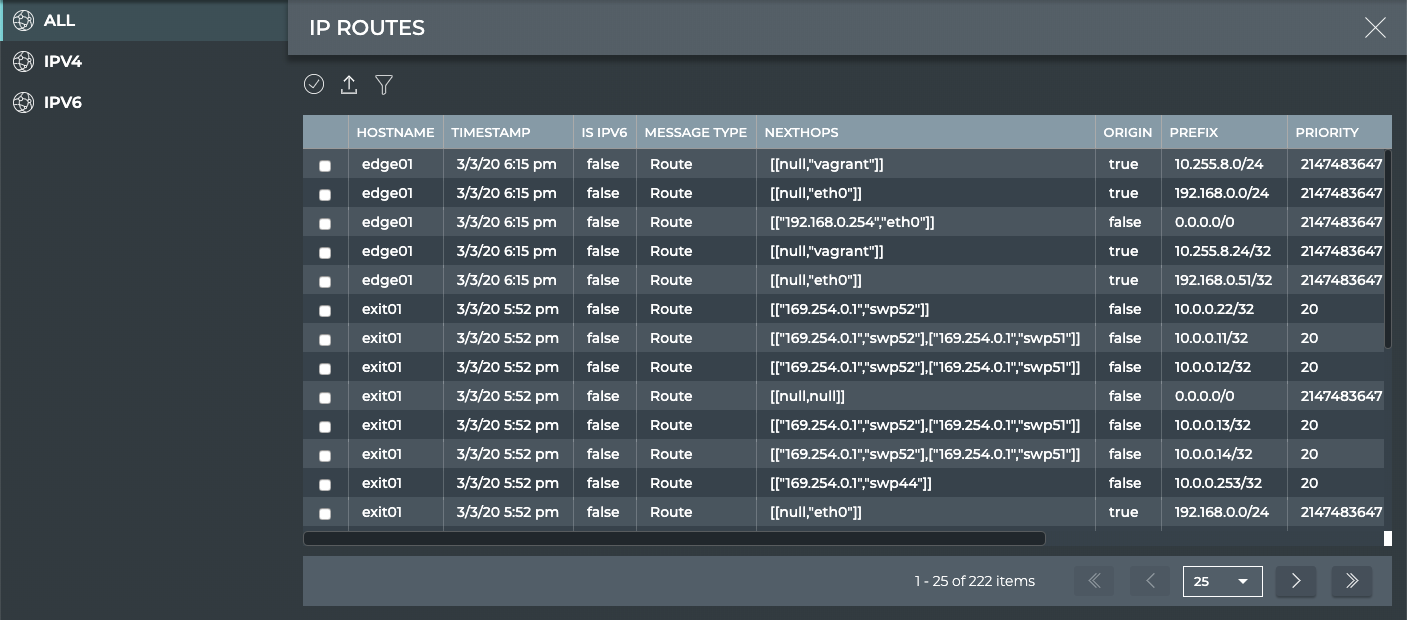
IP routes (v4 and v6)
Links
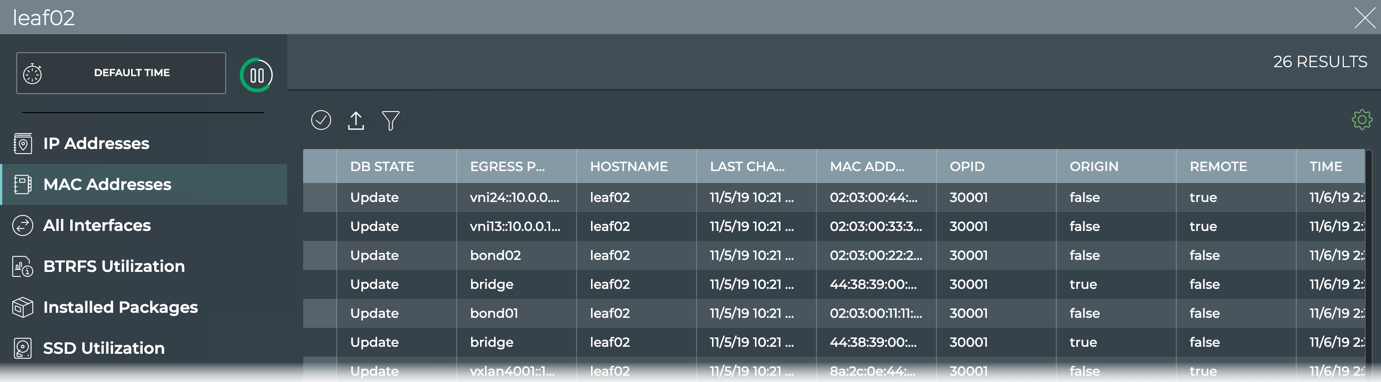
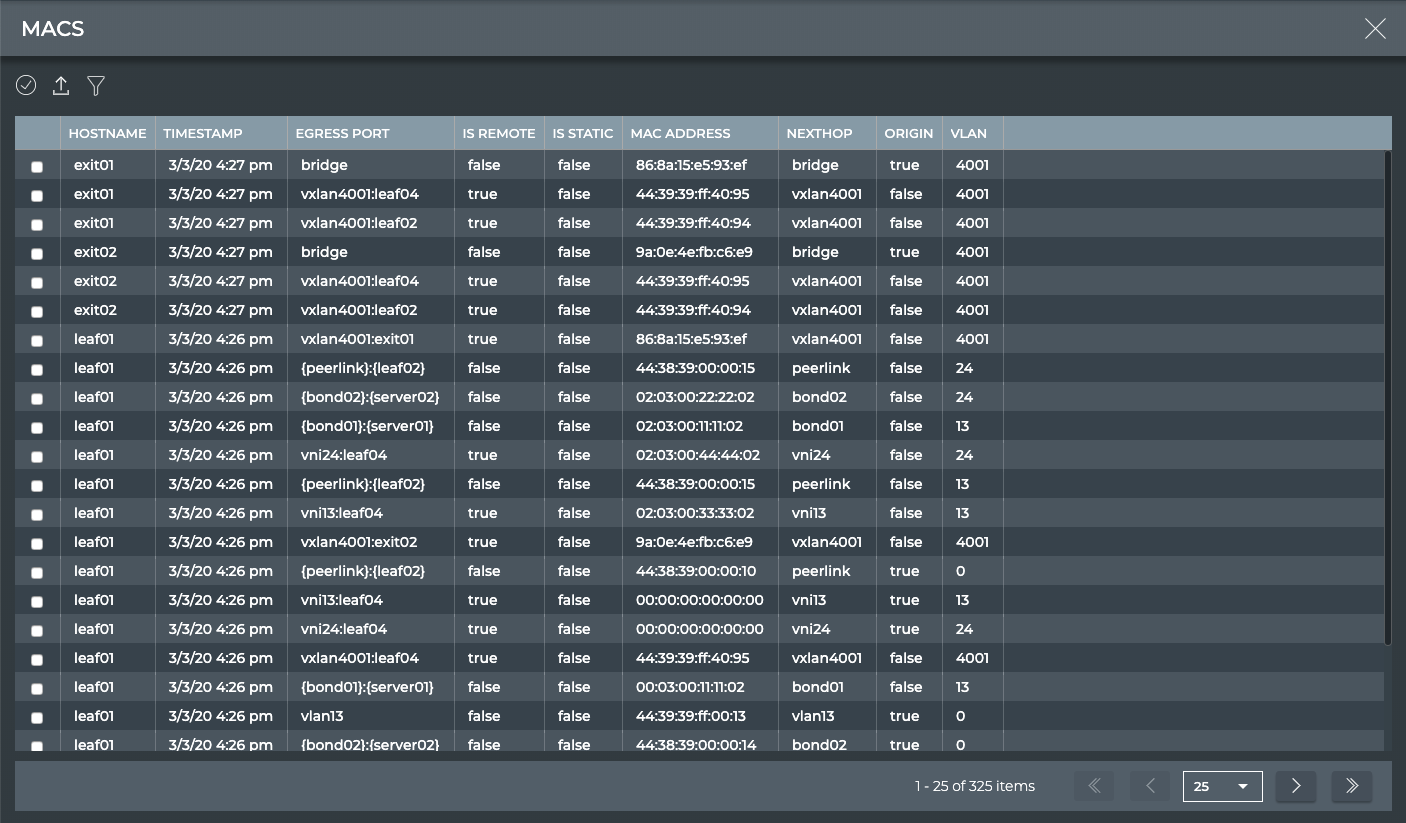
Bridge FDB (MAC Address table)
ARP Entries/Neighbors (IPv4 and IPv6)
for the following protocols:
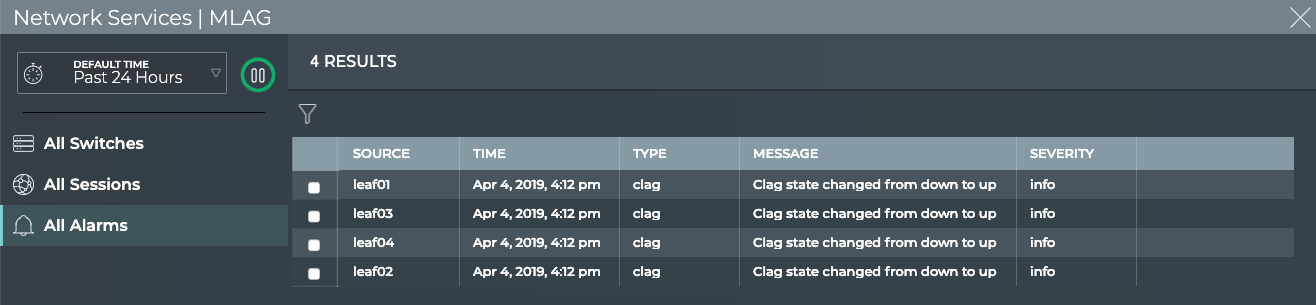
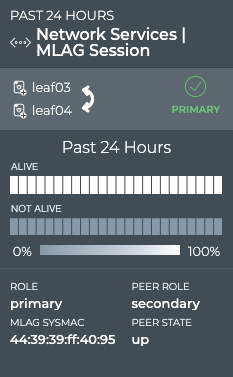
Bridging protocols: LLDP, STP, MLAG
Routing protocols: BGP, OSPF
Network virtualization: EVPN, VXLAN
The NetQ Agent is supported on Cumulus Linux 3.3.2 and later.
Host Agents
The NetQ Agents running on hosts gather the same information as that for
switches, plus the following network data:
Network IP and MAC addresses
Container IP and MAC addresses
The NetQ Agent obtains container
information by listening to the Kubernetes orchestration tool.
The NetQ Agent is supported on hosts running Ubuntu 16.04, Red Hat®
Enterprise Linux 7, and CentOS 7 Operating Systems.
NetQ Core
The NetQ core performs the data collection, storage, and processing
for delivery to various user interfaces. It is comprised of a collection
of scalable components running entirely within a single server. The NetQ
software queries this server, rather than individual devices enabling
greater scalability of the system. Each of these components is described
briefly here.
Data Aggregation
The data aggregation component collects data coming from all of the NetQ
Agents. It then filters, compresses, and forwards the data to the
streaming component. The server monitors for missing messages and also
monitors the NetQ Agents themselves, providing alarms when appropriate.
In addition to the telemetry data collected from the NetQ Agents, the
aggregation component collects information from the switches and hosts,
such as vendor, model, version, and basic operational state.
Data Stores
Two types of data stores are used in the NetQ product. The first stores
the raw data, data aggregations, and discrete events needed for quick
response to data requests. The second stores data based on correlations,
transformations and processing of the raw data.
Real-time Streaming
The streaming component processes the incoming raw data from the
aggregation server in real time. It reads the metrics and stores them as
a time series, and triggers alarms based on anomaly detection,
thresholds, and events.
Network Services
The network services component monitors protocols and services operation
individually and on a network-wide basis and stores status details.
User Interfaces
NetQ data is available through several
user interfaces:
NetQ CLI (command line interface)
NetQ UI (graphical user interface)
NetQ RESTful API (representational state transfer application programming interface)
The CLI and UI query the RESTful API for
the data to present. Standard integrations can be configured to
integrate with third-party notification tools.
Data Center Network Deployments
There are three deployment types that are commonly deployed for network management in the data center:
Out-of-Band Management (recommended)
In-band Management
High Availability
A summary of each type is provided here.
Cumulus NetQ operates over layer 3, and can be used in both layer 2 bridged and
layer 3 routed environments. Cumulus Networks always recommends layer 3
routed environments whenever possible.
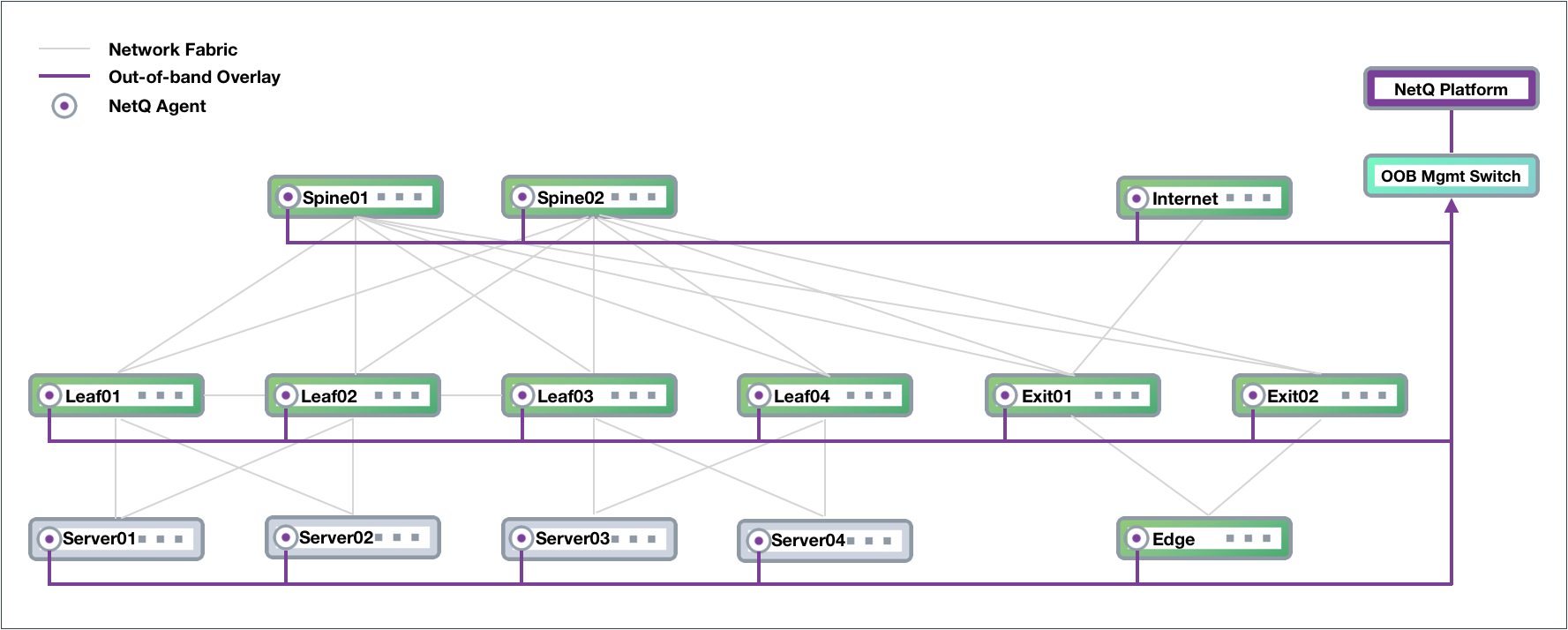
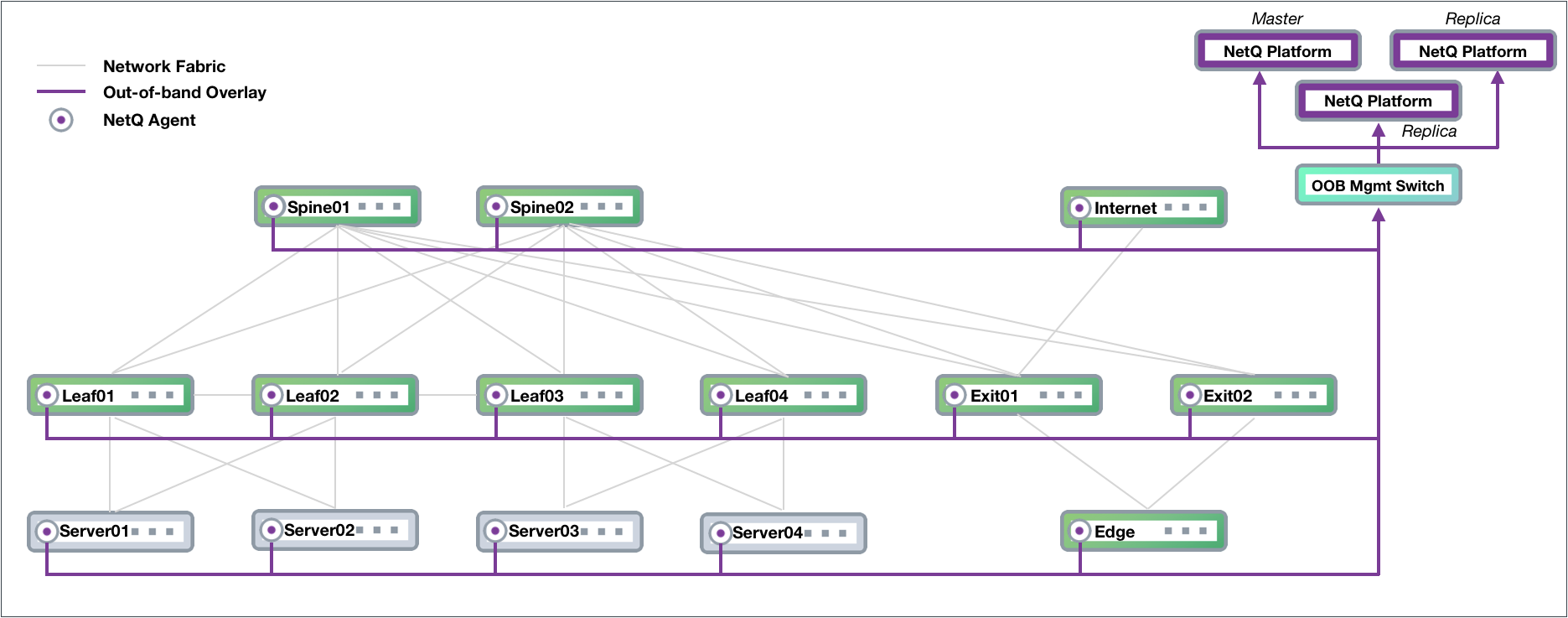
Out-of-Band Management Deployment
Cumulus Networks recommends deploying NetQ on an out-of-band (OOB)
management network to separate network management traffic from standard
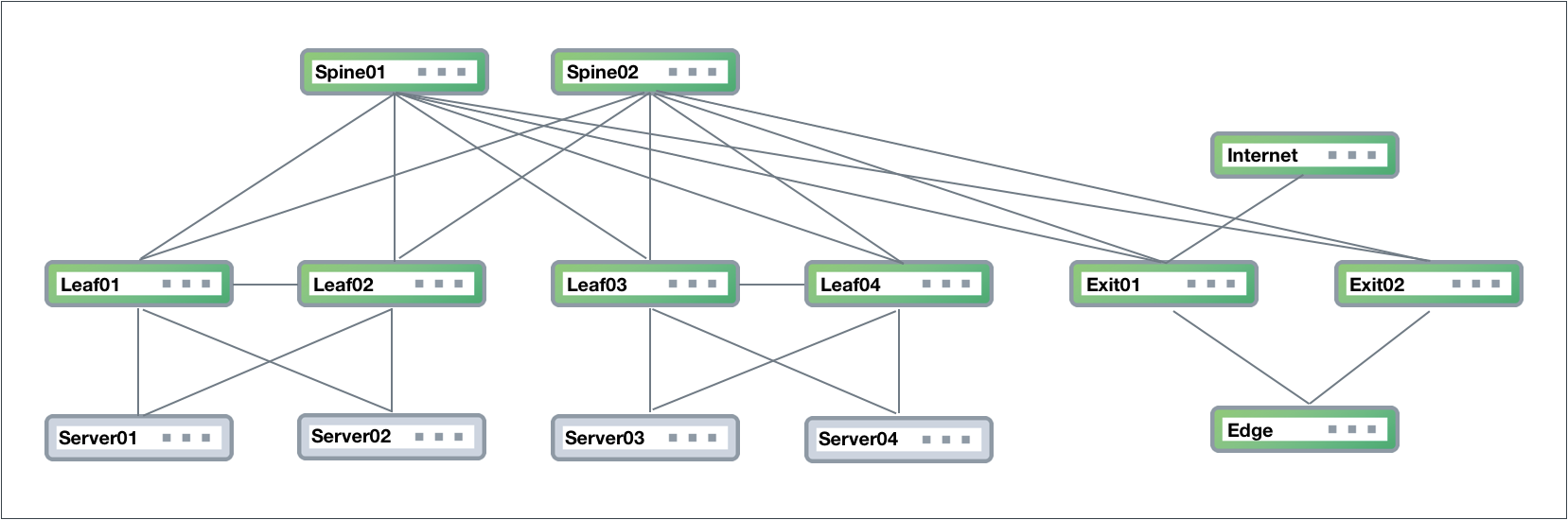
network data traffic, but it is not required. This figure shows a sample
CLOS-based network fabric design for a data center using an OOB
management network overlaid on top, where NetQ is deployed.
The physical network hardware includes:
Spine switches: where data is
aggregated and distributed ; also known as an aggregation switch,
end-of-row (EOR) switch or distribution switch
Leaf switches: where servers connect to the network; also known
as a Top of Rack (TOR) or access switch
Server hosts: where applications
are hosted and data served to the user through the network
Exit switch: where connections to
outside the data center occur; also known as
Border Leaf or Service Leaf
Edge server (optional): where the firewall is the demarcation
point, peering may occur through the exit switch layer to Internet
(PE) devices
Internet device (PE): where provider edge (PE) equipment
communicates at layer 3 with the network fabric
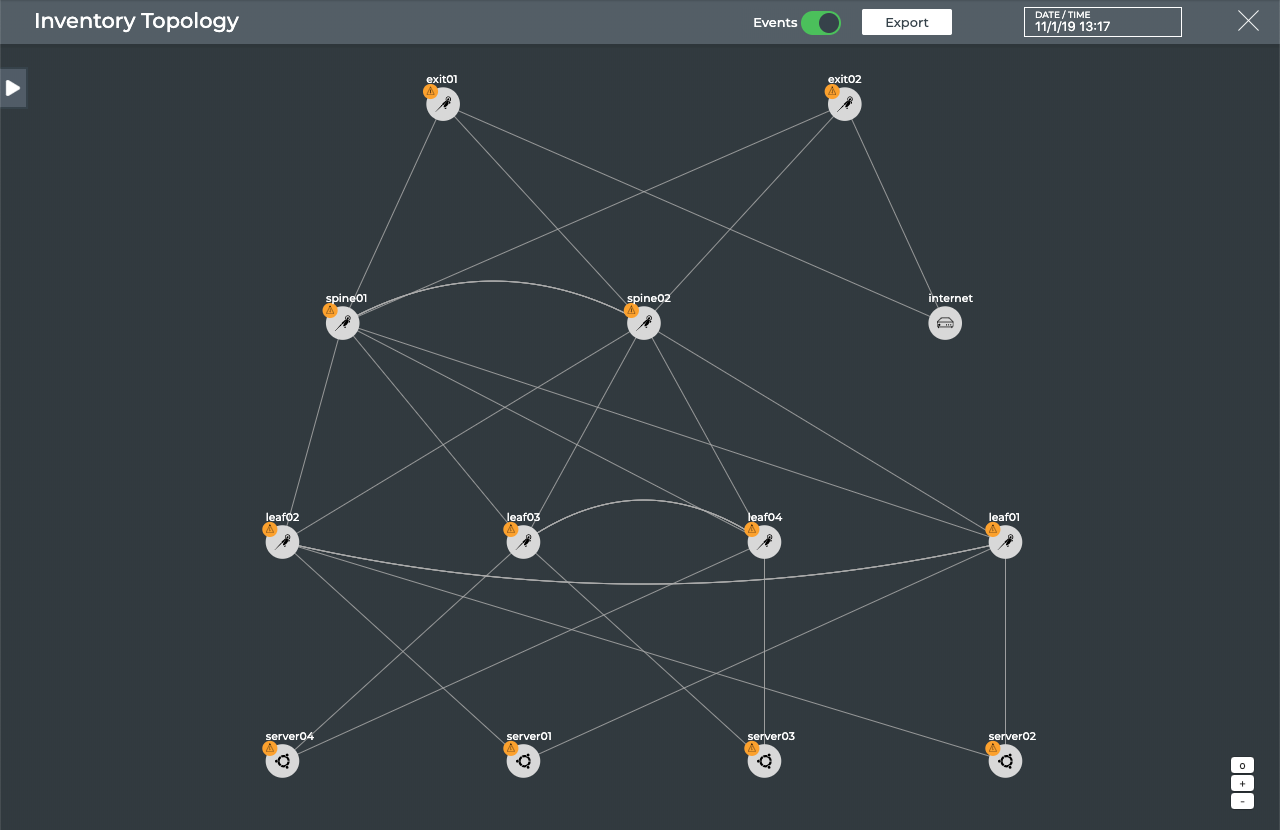
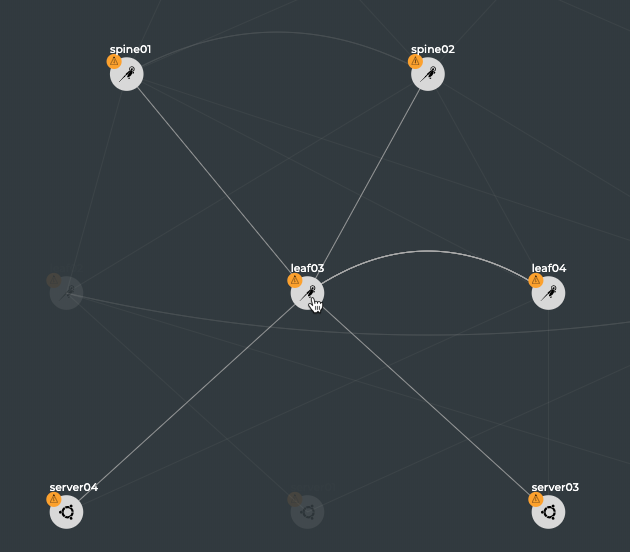
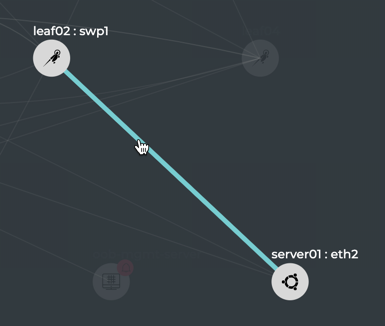
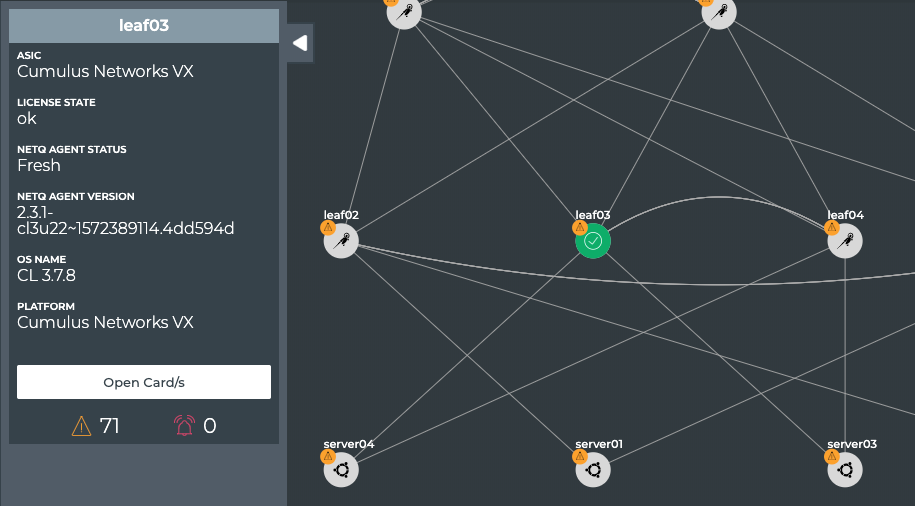
The diagram shows physical connections (in the form of grey lines)
between Spine 01 and four Leaf devices and two Exit devices, and Spine
02 and the same four Leaf devices and two Exit devices. Leaf 01 and Leaf
02 are connected to each other over a peerlink and act as an MLAG pair
for Server 01 and Server 02. Leaf 03 and Leaf 04 are connected to each
other over a peerlink and act as an MLAG pair for Server 03 and Server
04. The Edge is connected to both Exit devices, and the Internet node is
connected to Exit 01.
Data Center Network Example
The physical management hardware includes:
OOB Mgmt Switch: aggregation switch that connects to all of the
network devices through communications with the NetQ Agent on each
node
NetQ Platform: hosts the telemetry software, database and user
interfaces (refer to description above).
These switches are connected to each of the physical network devices
through a virtual network overlay, shown with purple lines.
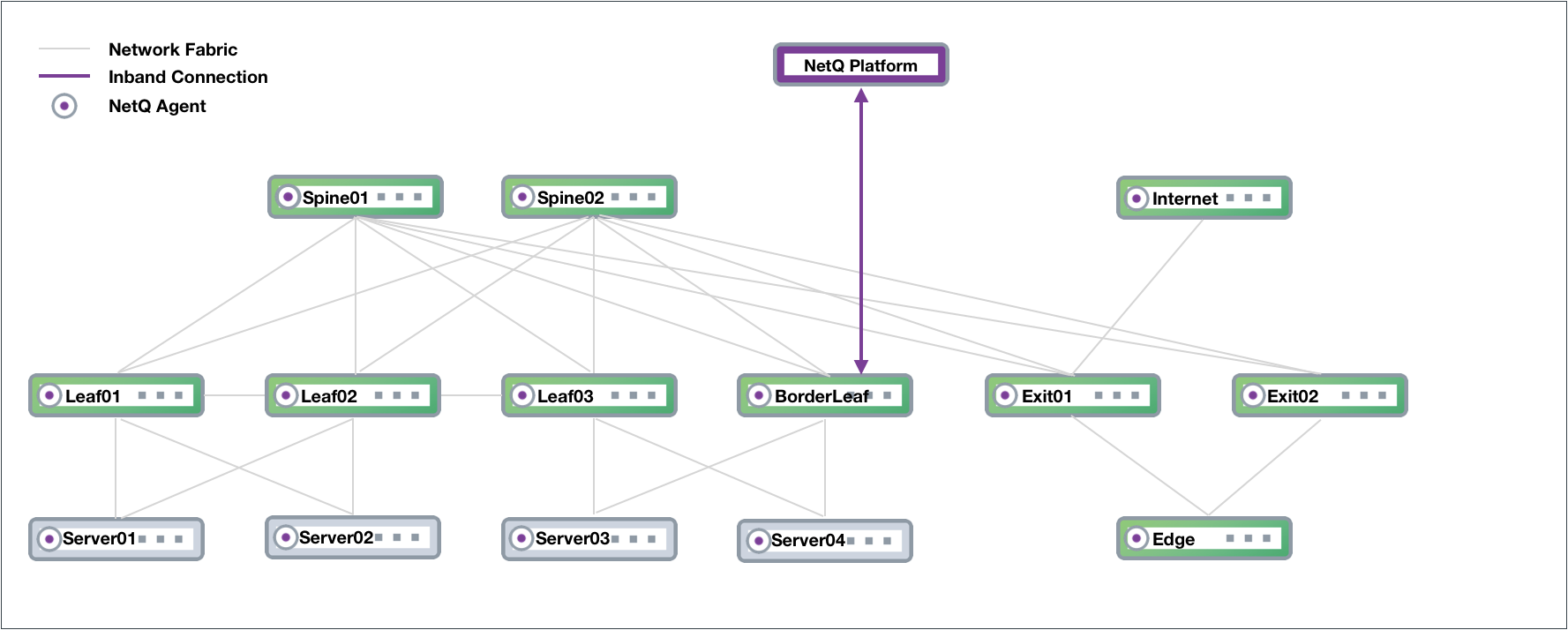
In-band Management Deployment
While not the preferred deployment method, you might choose to implement
NetQ within your data network. In this scenario, there is no overlay and
all traffic to and from the NetQ Agents and the NetQ Platform traverses
the data paths along with your regular network traffic. The roles of the
switches in the CLOS network are the same, except that the NetQ Platform
performs the aggregation function that the OOB management switch
performed. If your network goes down, you might not have access to the
NetQ Platform for troubleshooting.
High Availability Deployment
NetQ supports a high availability deployment for users who prefer a solution in which the collected data and processing provided by the NetQ Platform remains available through alternate equipment should the platform fail for any reason. In this configuration, three NetQ Platforms are deployed, with one as the master and two as workers (or replicas). Data from the NetQ Agents is sent to all three switches so that if the master NetQ Platform fails, one of the replicas automatically becomes the master and continues to store and provide the telemetry data. This example is based on an OOB management configuration, and modified to support high availability for NetQ.
Cumulus NetQ Operation
In either in-band or out-of-band deployments, NetQ offers network-wide configuration
and device management, proactive monitoring capabilities, and
performance diagnostics for complete management of your network. Each
component of the solution provides a critical element to make this
possible.
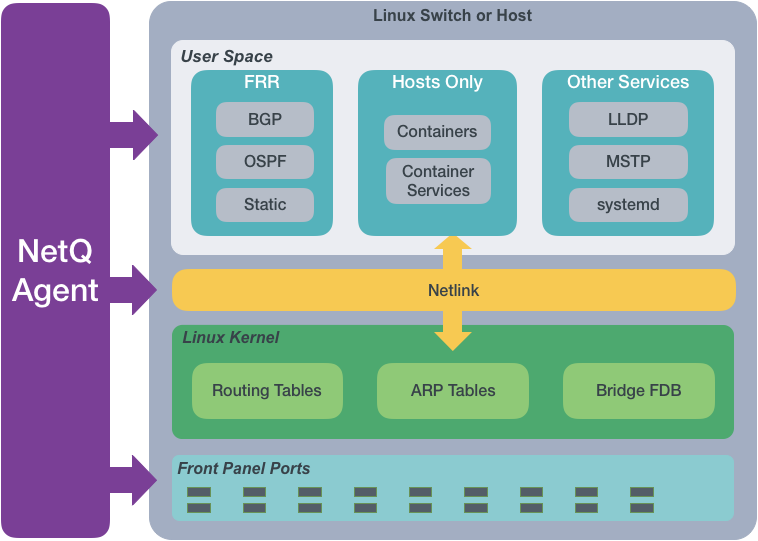
The NetQ Agent
From a software perspective, a network
switch has software associated with the hardware platform, the operating
system, and communications. For data centers, the software on a Cumulus
Linux network switch would be similar to the diagram shown here.
The NetQ Agent interacts with the various
components and software on switches and hosts and provides the gathered
information to the NetQ Platform. You can view the data using the NetQ
CLI or UI.
The NetQ Agent polls the user
space applications for information about the performance of the various
routing protocols and services that are running on the switch. Cumulus
Networks supports BGP and OSPF Free Range Routing (FRR) protocols as
well as static addressing. Cumulus Linux also supports LLDP and MSTP
among other protocols, and a variety of services such as systemd and
sensors . For hosts, the NetQ Agent also polls for performance of
containers managed with Kubernetes. All of this information is used to
provide the current health of the network and verify it is configured
and operating correctly.
For example, if the NetQ Agent learns that an interface has gone down, a
new BGP neighbor has been configured, or a container has moved, it
provides that information to the NetQ
Platform. That information can then be used to notify users of
the operational state change through various channels. By default, data
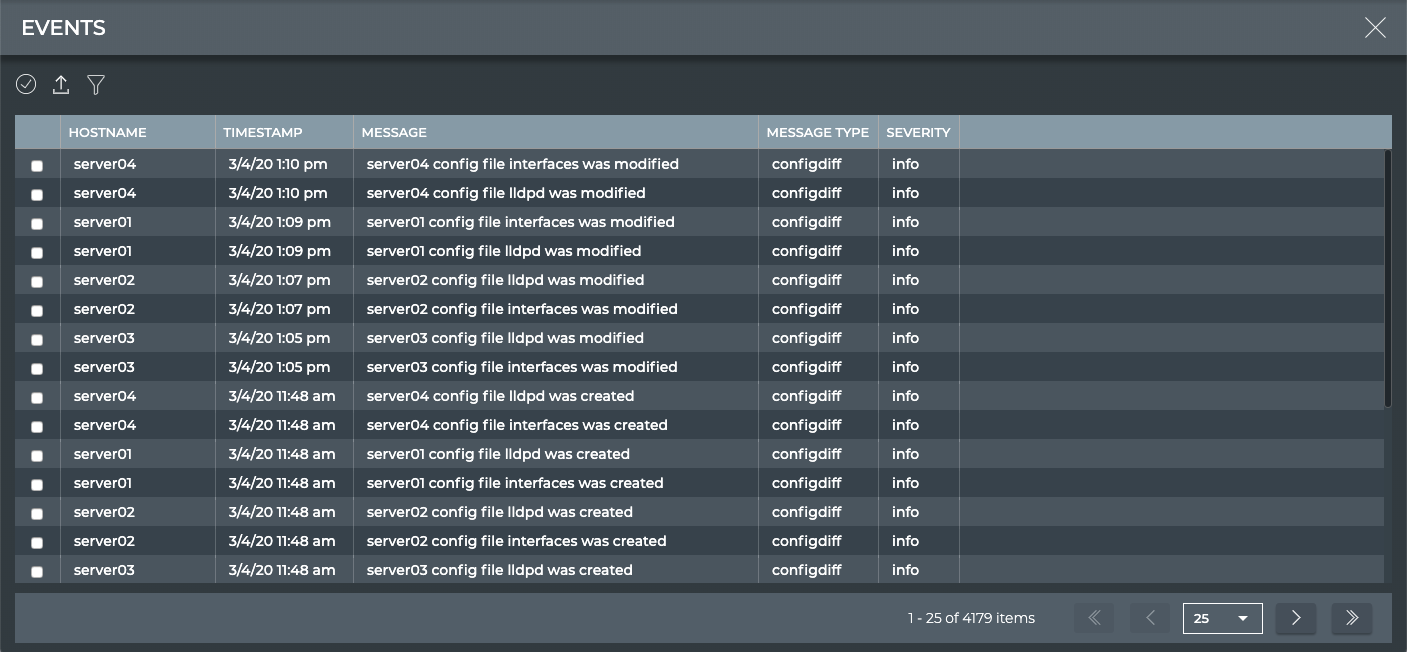
is logged in the database, but you can use the CLI (netq show events)
or configure the Event Service in NetQ to send the information to a
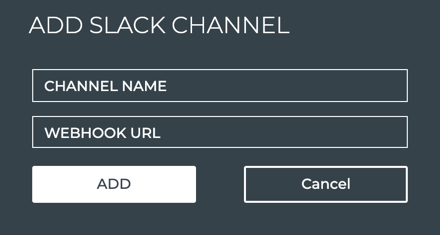
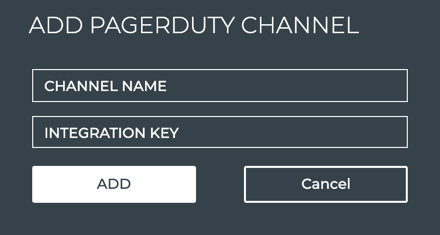
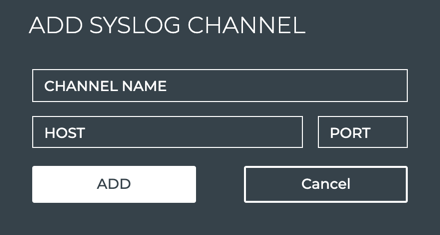
third-party notification application as well. NetQ supports PagerDuty
and Slack integrations.
The NetQ Agent interacts with the Netlink communications between the
Linux kernel and the user space, listening for changes to the network
state, configurations, routes and MAC addresses. NetQ uses this
information to enable notifications about these changes so that network
operators and administrators can respond quickly when changes are not
expected or favorable.
For example, if a new route is added or a MAC address removed, NetQ
Agent records these changes and sends that information to the
NetQ Platform. Based on the
configuration of the Event Service, these changes can be sent to a
variety of locations for end user response.
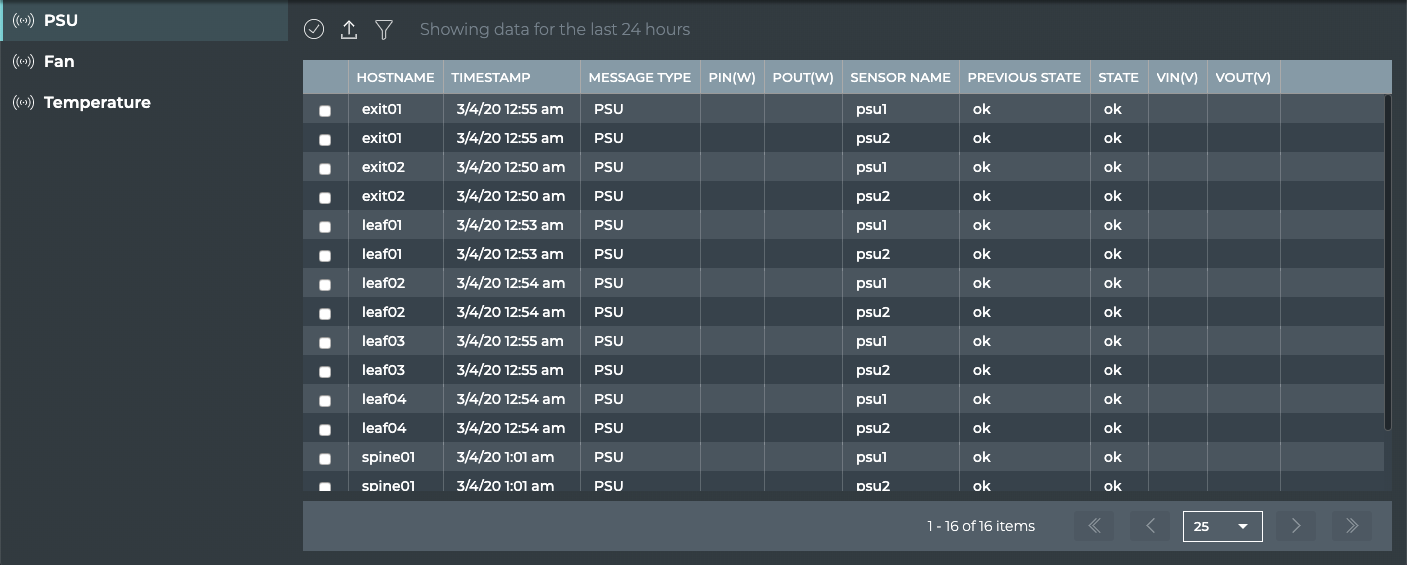
The NetQ Agent also interacts with the hardware platform to obtain
performance information about various physical components, such as fans
and power supplies, on the switch. Operational states and temperatures
are measured and reported, along with cabling information to enable
management of the hardware and cabling, and proactive maintenance.
For example, as thermal sensors in the switch indicate that it is
becoming very warm, various levels of alarms are generated. These are
then communicated through notifications according to the Event Service
configuration.
The NetQ Platform
Once the collected data is sent to and stored in the NetQ database, you
can:
Validate configurations, identifying misconfigurations in your
current network, in the past, or prior to deployment,
Monitor communication paths throughout the network,
Notify users of issues and management information,
Anticipate impact of connectivity changes,
and so forth.
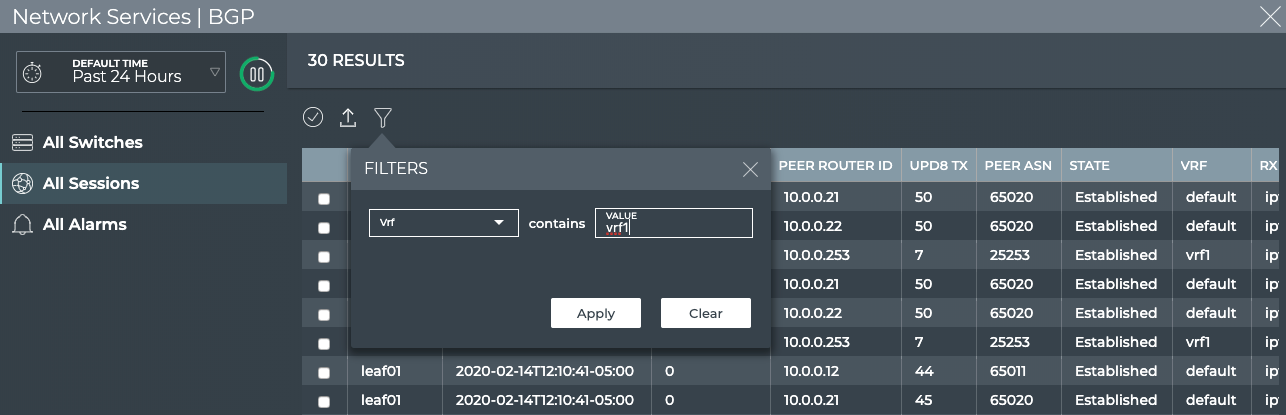
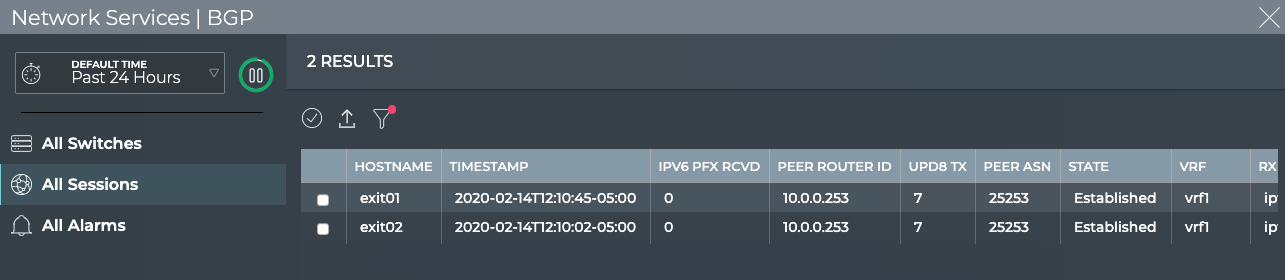
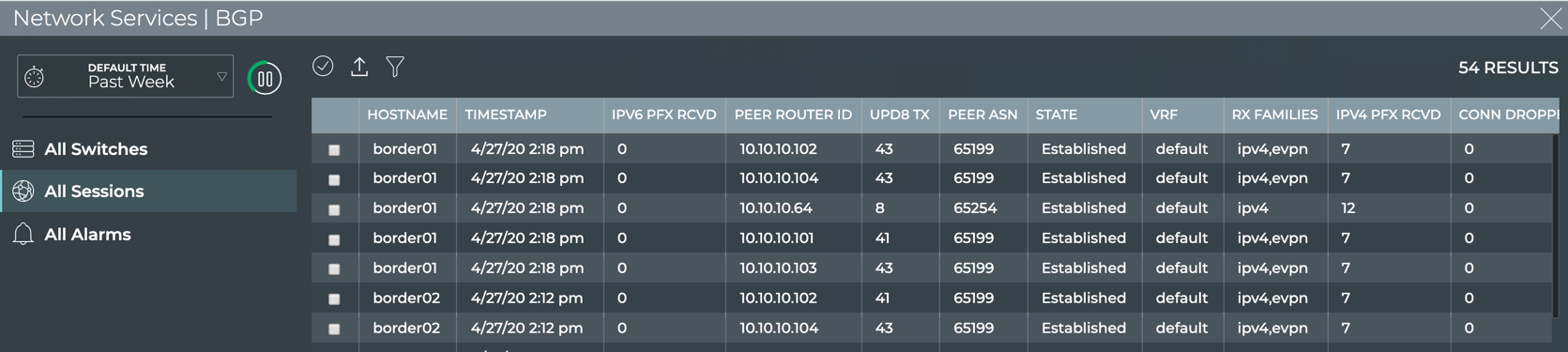
Validate Configurations
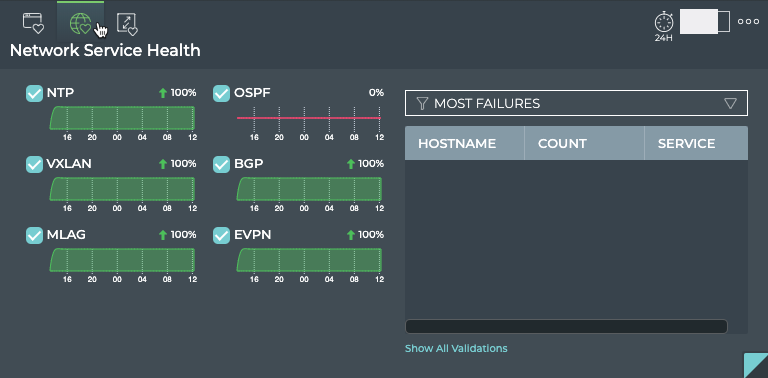
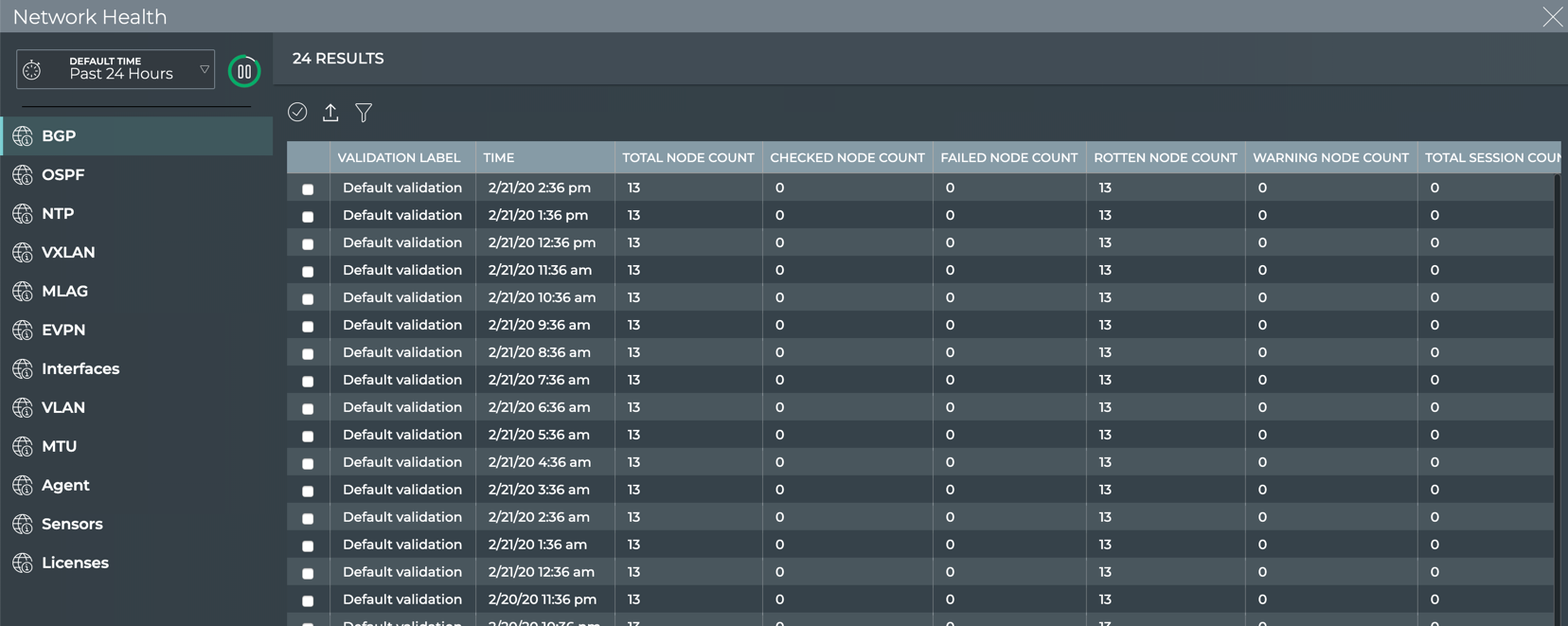
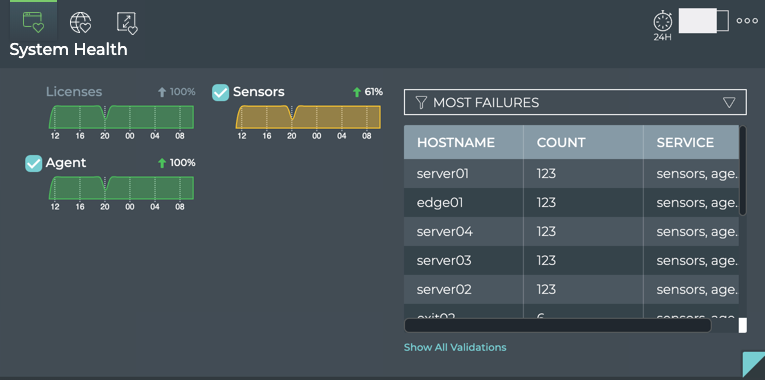
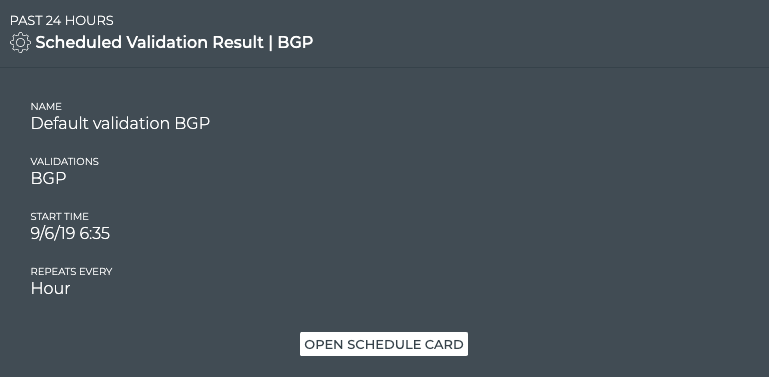
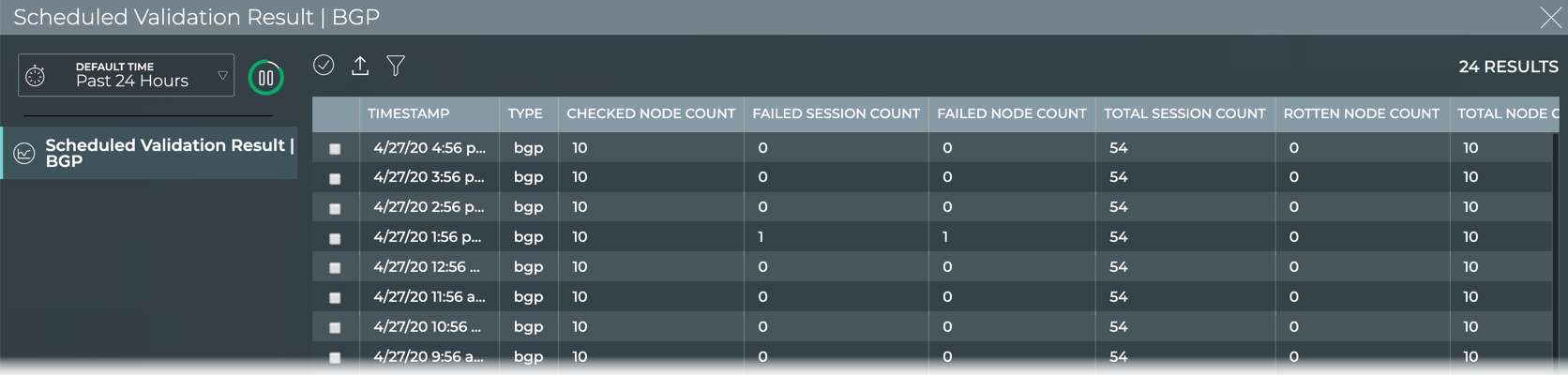
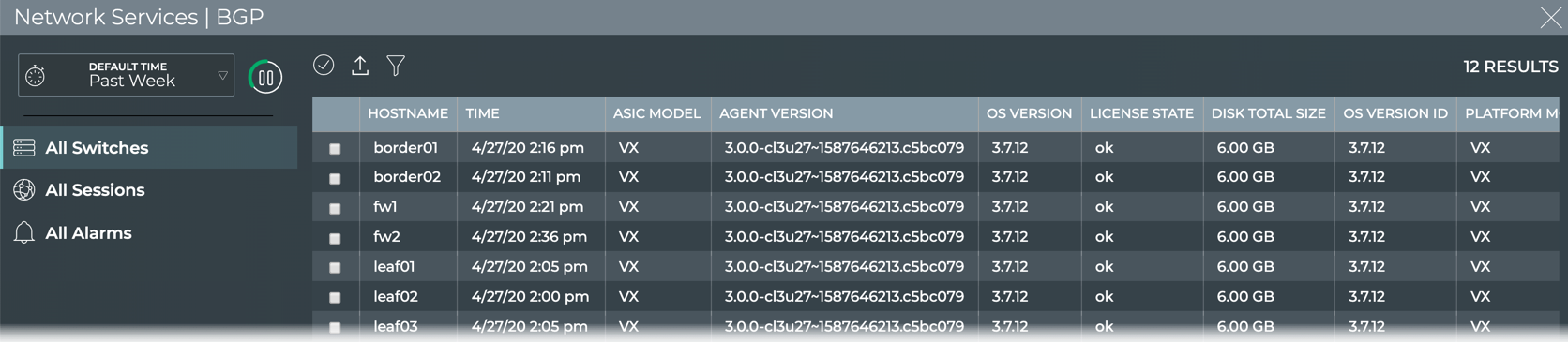
The NetQ CLI enables validation of your network health through two sets
of commands: netq check and netq show. They extract the information
from the Network Service component and Event service. The Network
Service component is continually validating the connectivity and
configuration of the devices and protocols running on the network. Using
the netq check and netq show commands displays the status of the
various components and services on a network-wide and complete software
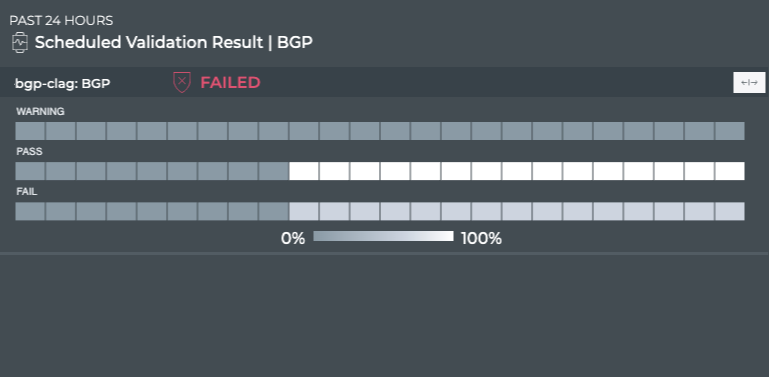
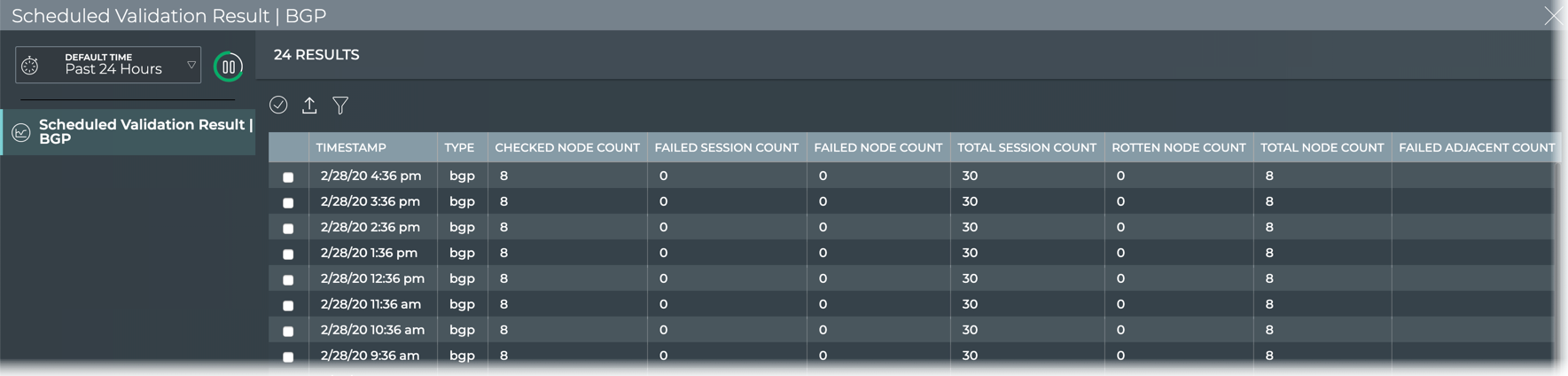
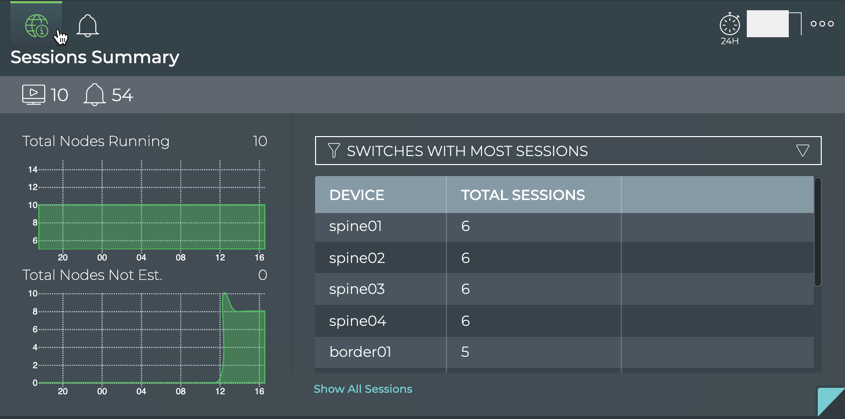
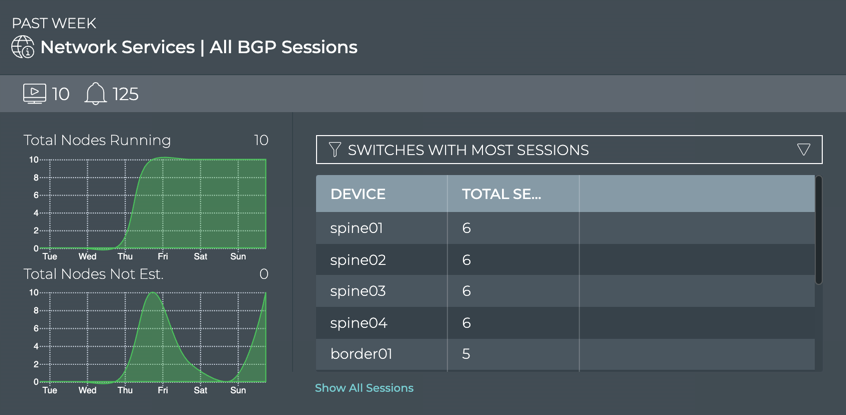
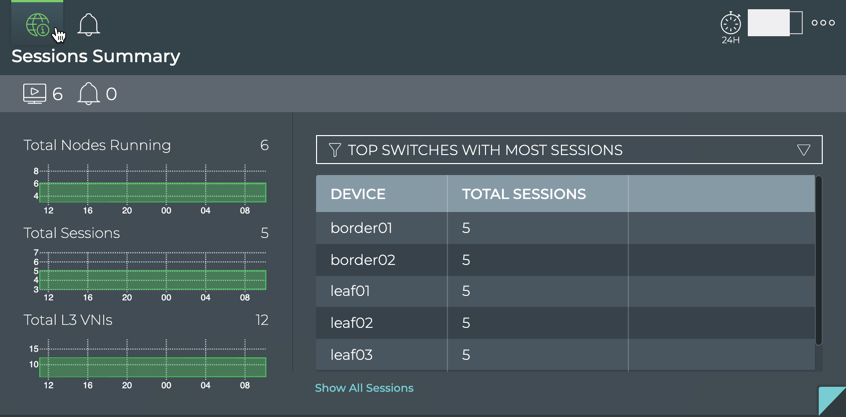
stack basis. For example, you can perform a network-wide check on all
sessions of BGP with a single netq check bgp command. The command
lists any devices that have misconfigurations or other operational
errors in seconds. When errors or misconfigurations are present, using
the netq show bgp command displays the BGP configuration on each
device so that you can compare and contrast each device, looking for
potential causes. netq check and netq show commands are available
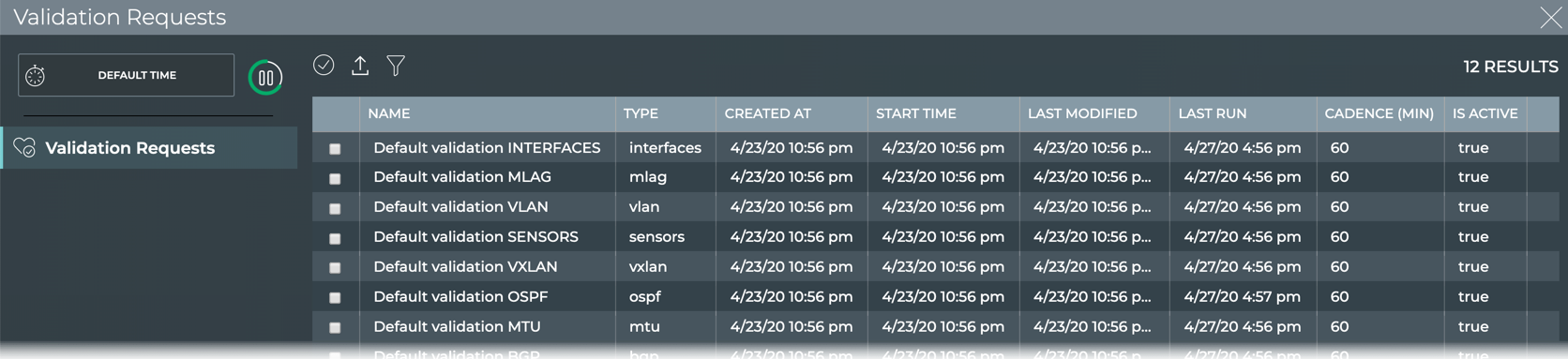
for numerous components and services as shown in the following table.
Component or Service
Check
Show
Component or Service
Check
Show
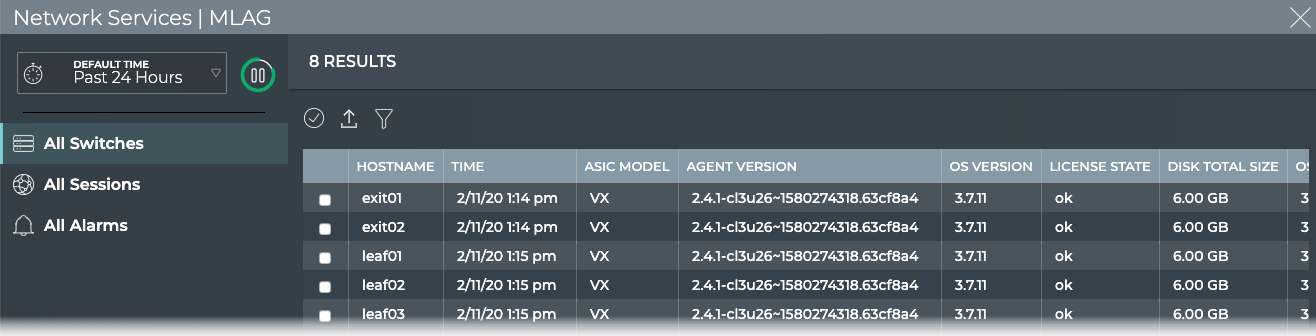
Agents
X
X
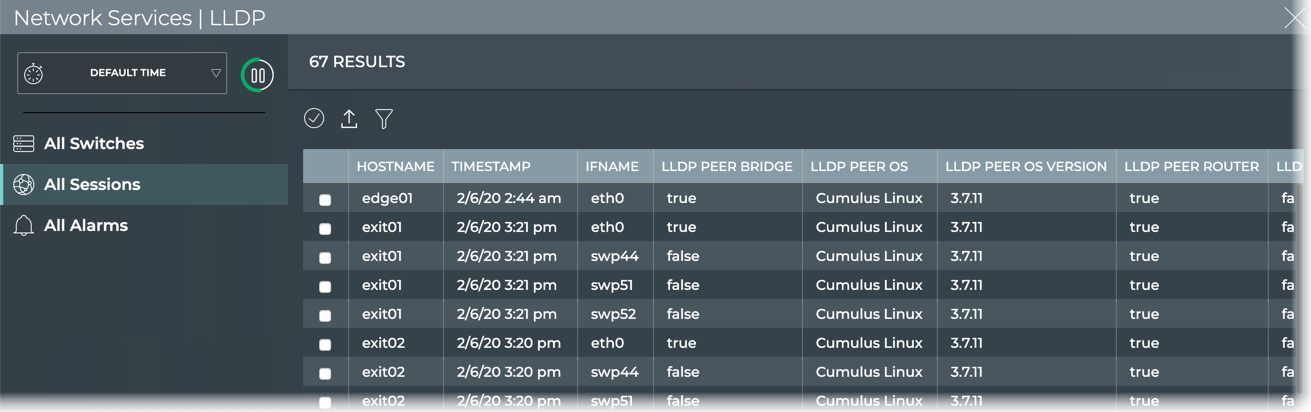
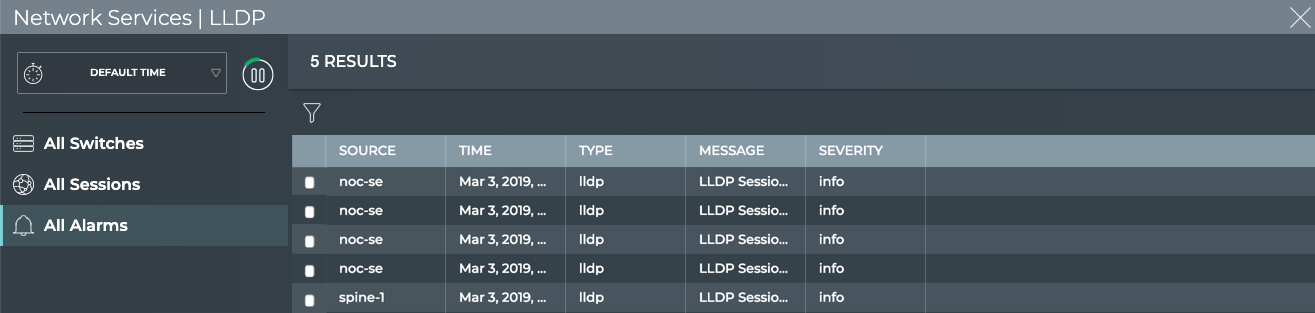
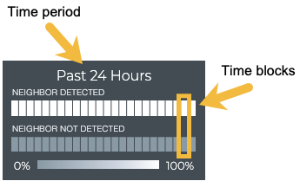
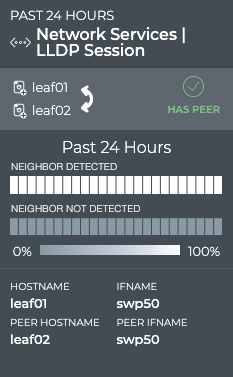
LLDP
X
BGP
X
X
MACs
X
CLAG (MLAG)
X
X
MTU
X
Events
X
NTP
X
X
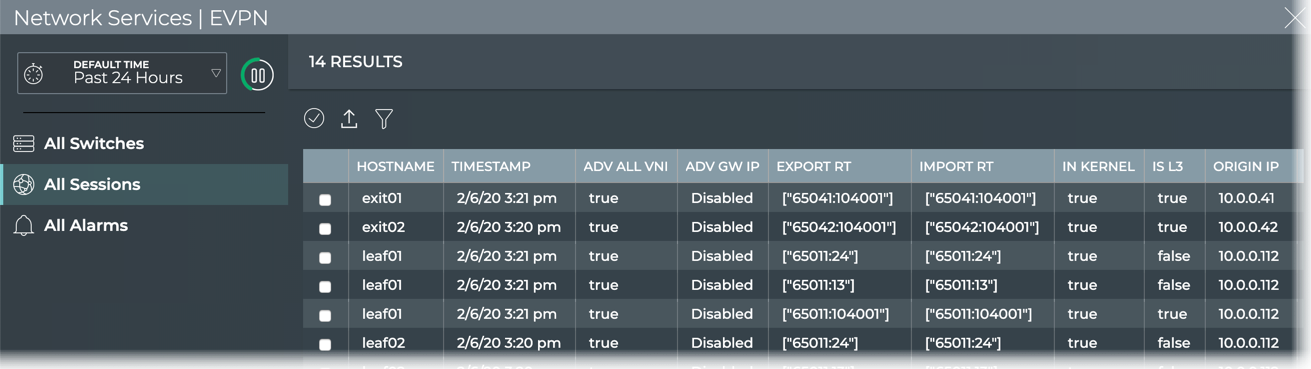
EVPN
X
X
OSPF
X
X
Interfaces
X
X
Sensors
X
X
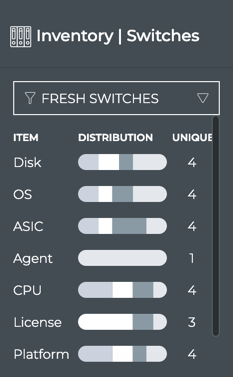
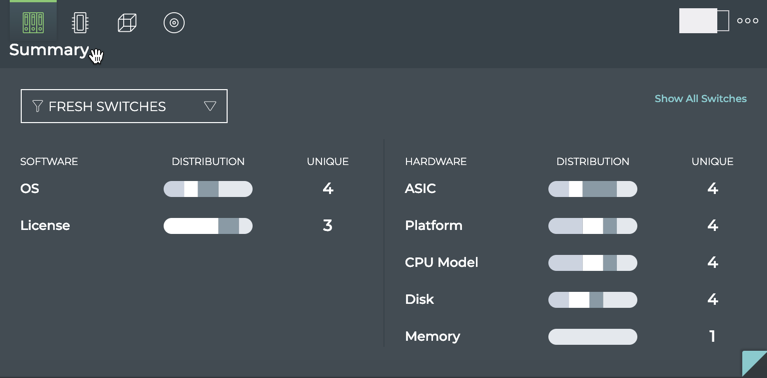
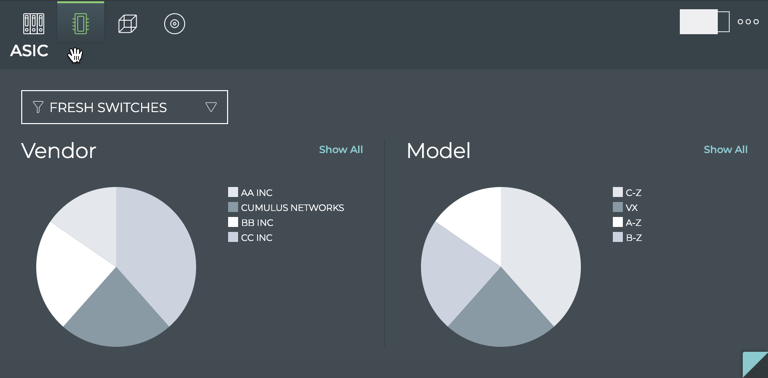
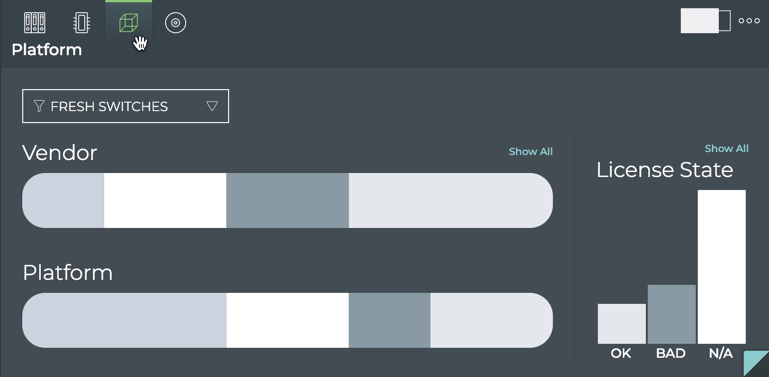
Inventory
X
Services
X
IPv4/v6
X
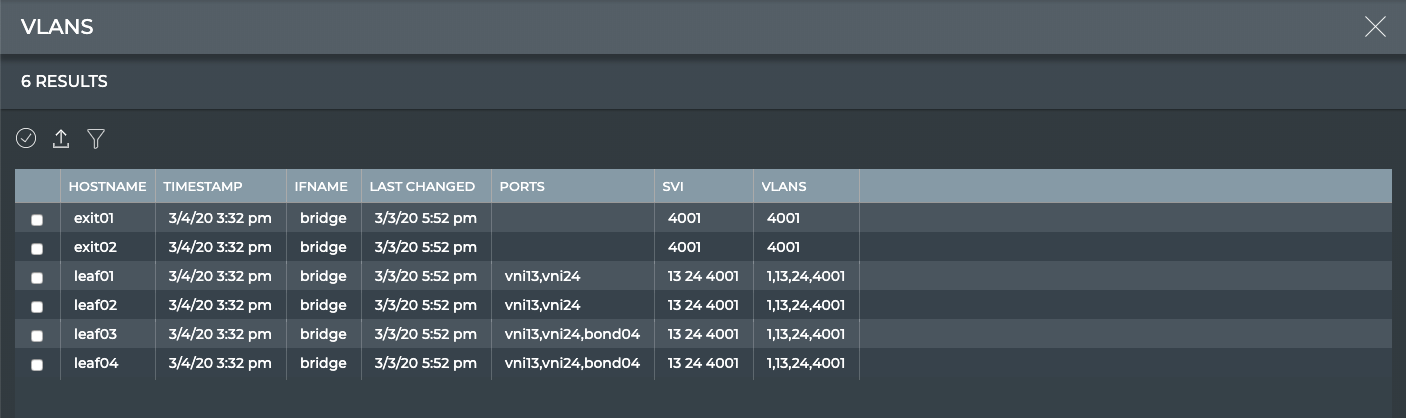
VLAN
X
X
Kubernetes
X
VXLAN
X
X
License
X
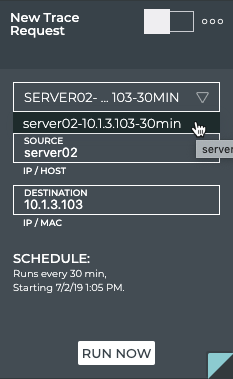
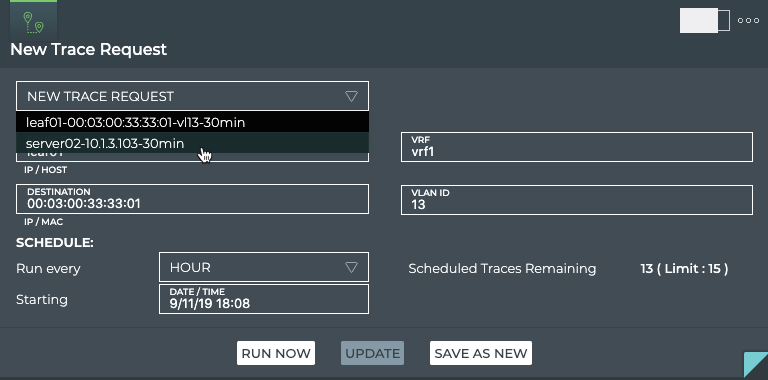
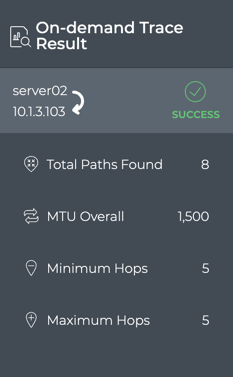
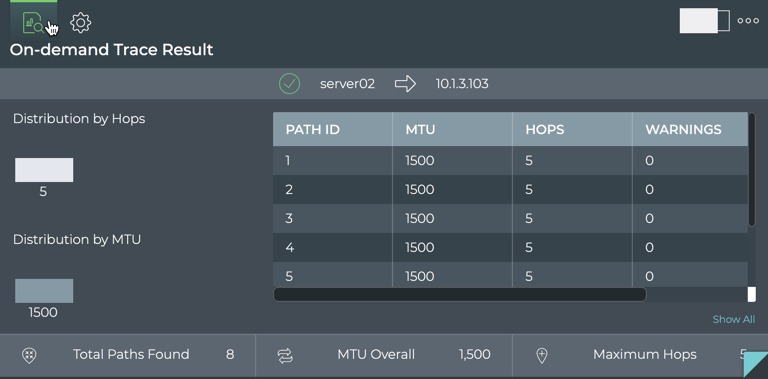
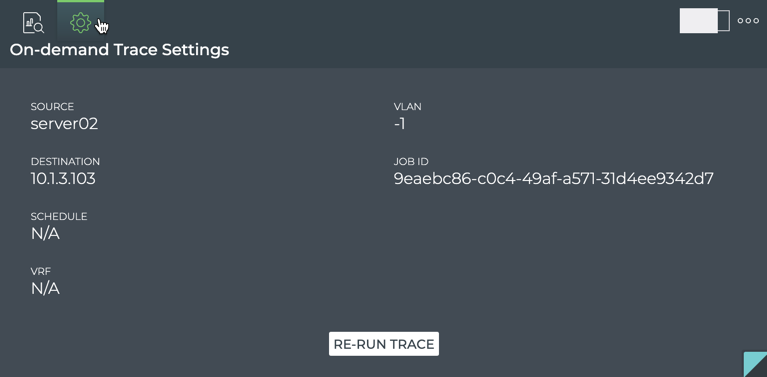
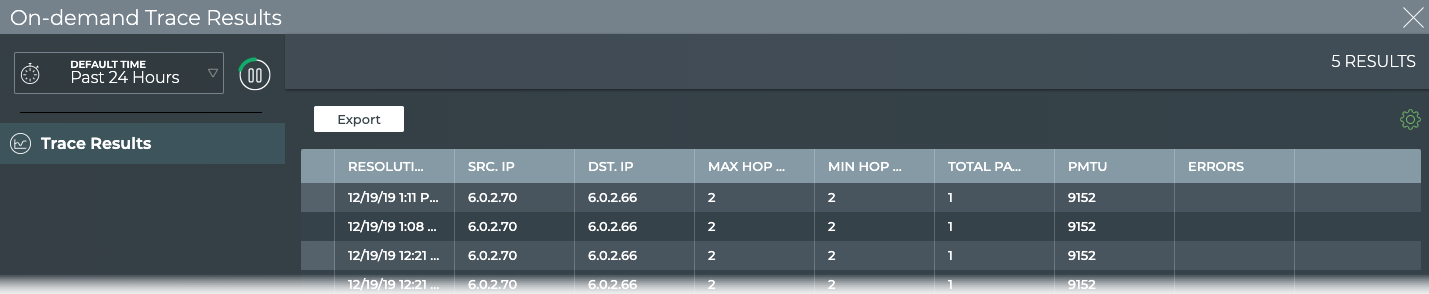
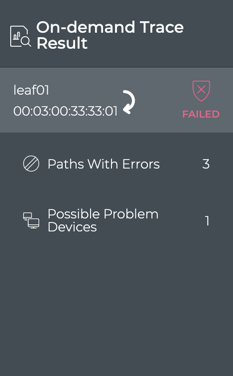
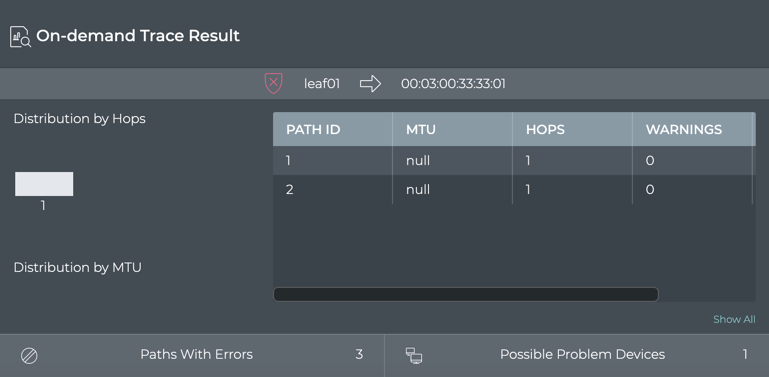
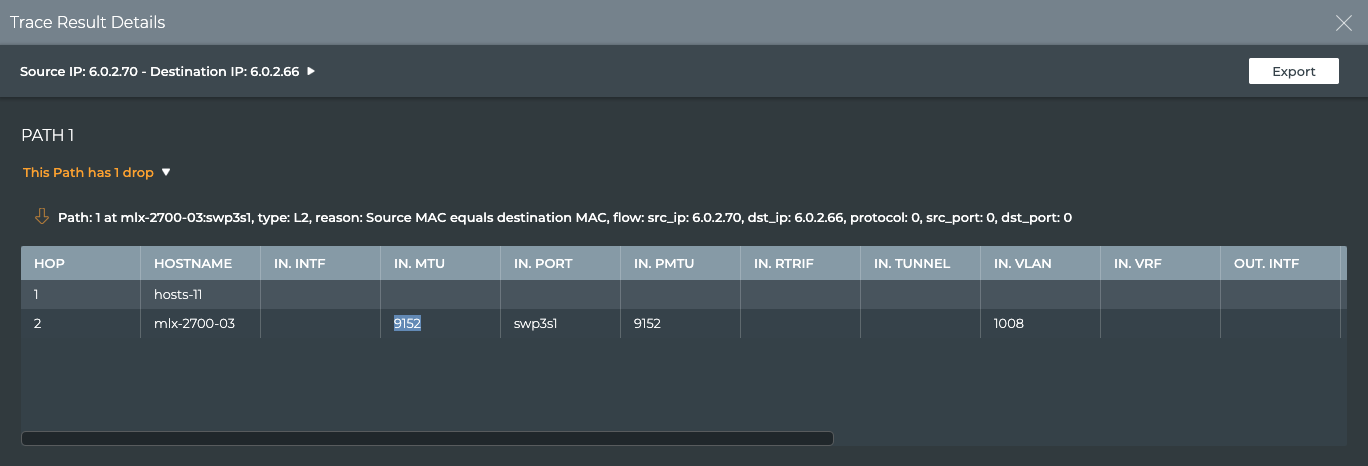
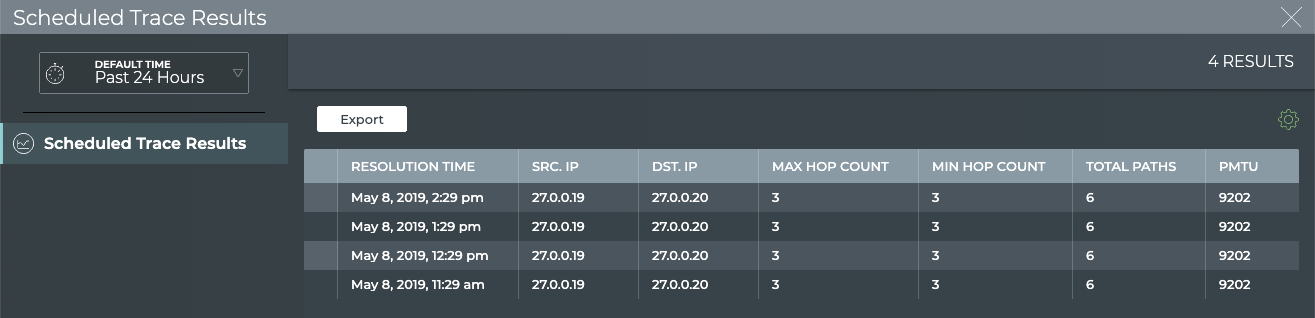
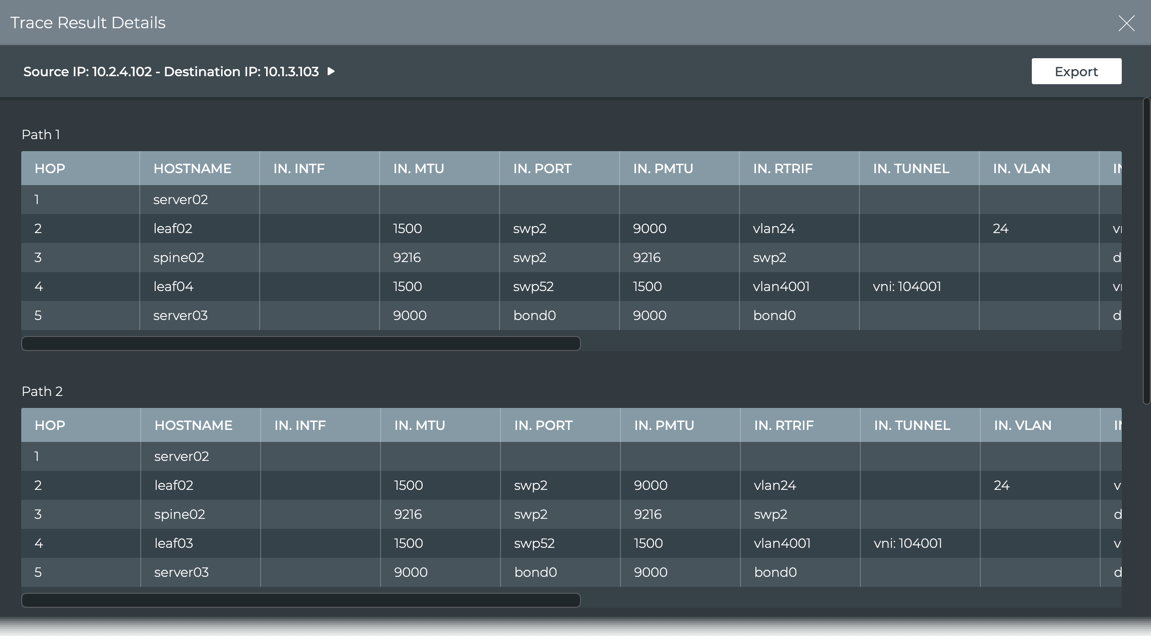
Monitor Communication Paths
The trace engine is used to validate the available communication paths
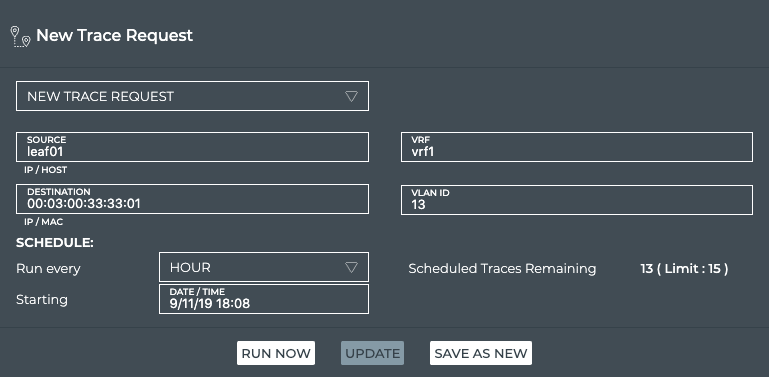
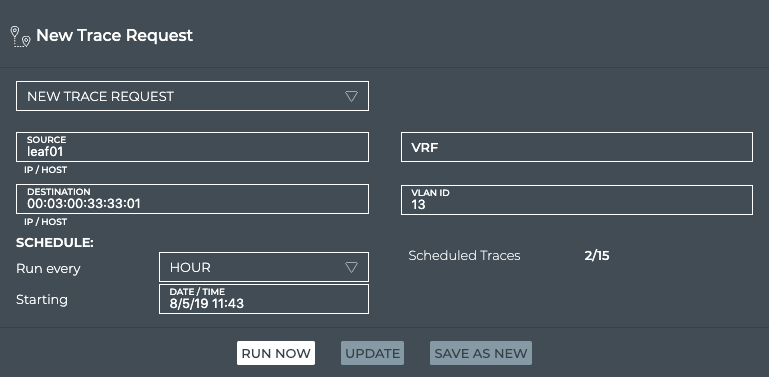
between two network devices. The corresponding netq trace command
enables you to view all of the paths between the two devices and if
there are any breaks in the paths. This example shows two successful
paths between server12 and leaf11, all with an MTU of 9152. The first
command shows the output in path by path tabular mode. The second
command show the same output as a tree.
cumulus@switch:~$ netq trace 10.0.0.13 from 10.0.0.21
Number of Paths: 2
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Path MTU: 9152
Id Hop Hostname InPort InTun, RtrIf OutRtrIf, Tun OutPort
--- --- ----------- --------------- --------------- --------------- ---------------
1 1 server12 bond1.1002
2 leaf12 swp8 vlan1002 peerlink-1
3 leaf11 swp6 vlan1002 vlan1002
--- --- ----------- --------------- --------------- --------------- ---------------
2 1 server12 bond1.1002
2 leaf11 swp8 vlan1002
--- --- ----------- --------------- --------------- --------------- ---------------
cumulus@switch:~$ netq trace 10.0.0.13 from 10.0.0.21 pretty
Number of Paths: 2
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Path MTU: 9152
hostd-12 bond1.1002 -- swp8 leaf12 <vlan1002> peerlink-1 -- swp6 <vlan1002> leaf11 vlan1002
bond1.1002 -- swp8 leaf11 vlan1002
This output is read as:
Path 1 traverses the network from server12 out bond1.1002 into
leaf12 interface swp8 out VLAN1002 peerlink-1 into VLAN1002
interface swp6 on leaf11
Path 2 traverses the network from server12 out bond1.1002 into
VLAN1002 interface swp8 on leaf11.
If the MTU does not match across the network, or any of the paths or
parts of the paths have issues, that data is called out in the summary
at the top of the output and shown in red along the paths, giving you a
starting point for troubleshooting.
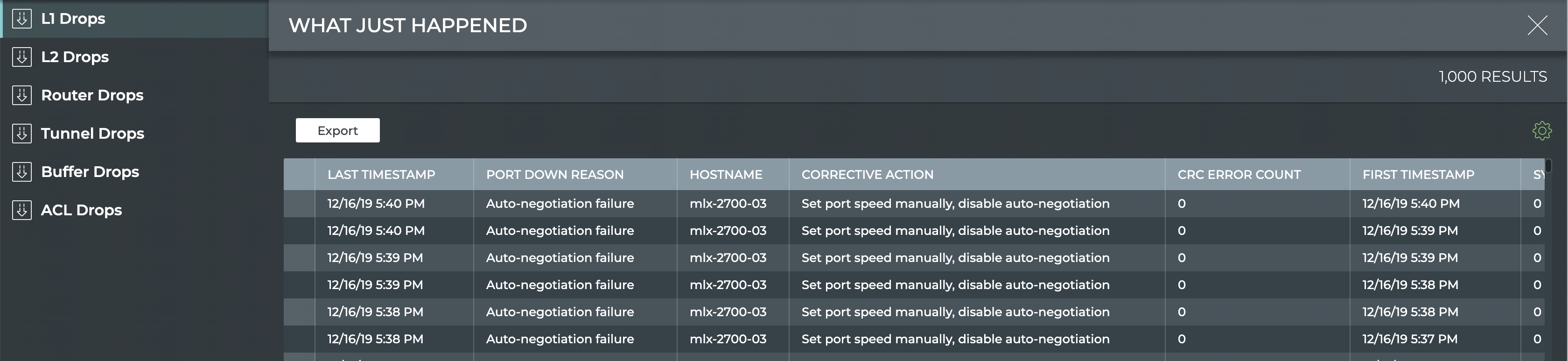
View Historical State and Configuration
All of the check, show and trace commands can be run for the current
status and for a prior point in time. For example, this is useful when
you receive messages from the night before, but are not seeing any
problems now. You can use the netq check command to look for
configuration or operational issues around the time that the messages
are timestamped. Then use the netq show commands to see information
about how the devices in question were configured at that time or if
there were any changes in a given timeframe. Optionally, you can use the
netq trace command to see what the connectivity looked like between
any problematic nodes at that time. This example shows problems occurred
on spine01, leaf04, and server03 last night. The network administrator
received notifications and wants to investigate. The diagram is followed
by the commands to run to determine the cause of a BGP error on spine01.
Note that the commands use the around option to see the results for
last night and that they can be run from any switch in the network.
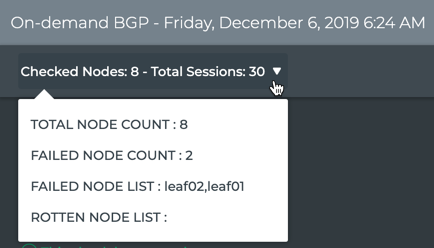
cumulus@switch:~$ netq check bgp around 30m
Total Nodes: 25, Failed Nodes: 3, Total Sessions: 220 , Failed Sessions: 24,
Hostname VRF Peer Name Peer Hostname Reason Last Changed
----------------- --------------- ----------------- ----------------- --------------------------------------------- -------------------------
exit-1 DataVrf1080 swp6.2 firewall-1 BGP session with peer firewall-1 swp6.2: AFI/ 1d:2h:6m:21s
SAFI evpn not activated on peer
exit-1 DataVrf1080 swp7.2 firewall-2 BGP session with peer firewall-2 (swp7.2 vrf 1d:1h:59m:43s
DataVrf1080) failed,
reason: Peer not configured
exit-1 DataVrf1081 swp6.3 firewall-1 BGP session with peer firewall-1 swp6.3: AFI/ 1d:2h:6m:21s
SAFI evpn not activated on peer
exit-1 DataVrf1081 swp7.3 firewall-2 BGP session with peer firewall-2 (swp7.3 vrf 1d:1h:59m:43s
DataVrf1081) failed,
reason: Peer not configured
exit-1 DataVrf1082 swp6.4 firewall-1 BGP session with peer firewall-1 swp6.4: AFI/ 1d:2h:6m:21s
SAFI evpn not activated on peer
exit-1 DataVrf1082 swp7.4 firewall-2 BGP session with peer firewall-2 (swp7.4 vrf 1d:1h:59m:43s
DataVrf1082) failed,
reason: Peer not configured
exit-1 default swp6 firewall-1 BGP session with peer firewall-1 swp6: AFI/SA 1d:2h:6m:21s
FI evpn not activated on peer
exit-1 default swp7 firewall-2 BGP session with peer firewall-2 (swp7 vrf de 1d:1h:59m:43s
...
cumulus@switch:~$ netq exit-1 show bgp
Matching bgp records:
Hostname Neighbor VRF ASN Peer ASN PfxRx Last Changed
----------------- ---------------------------- --------------- ---------- ---------- ------------ -------------------------
exit-1 swp3(spine-1) default 655537 655435 27/24/412 Fri Feb 15 17:20:00 2019
exit-1 swp3.2(spine-1) DataVrf1080 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp3.3(spine-1) DataVrf1081 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp3.4(spine-1) DataVrf1082 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp4(spine-2) default 655537 655435 27/24/412 Fri Feb 15 17:20:00 2019
exit-1 swp4.2(spine-2) DataVrf1080 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp4.3(spine-2) DataVrf1081 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp4.4(spine-2) DataVrf1082 655537 655435 13/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp5(spine-3) default 655537 655435 28/24/412 Fri Feb 15 17:20:00 2019
exit-1 swp5.2(spine-3) DataVrf1080 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp5.3(spine-3) DataVrf1081 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp5.4(spine-3) DataVrf1082 655537 655435 14/12/0 Fri Feb 15 17:20:00 2019
exit-1 swp6(firewall-1) default 655537 655539 73/69/- Fri Feb 15 17:22:10 2019
exit-1 swp6.2(firewall-1) DataVrf1080 655537 655539 73/69/- Fri Feb 15 17:22:10 2019
exit-1 swp6.3(firewall-1) DataVrf1081 655537 655539 73/69/- Fri Feb 15 17:22:10 2019
exit-1 swp6.4(firewall-1) DataVrf1082 655537 655539 73/69/- Fri Feb 15 17:22:10 2019
exit-1 swp7 default 655537 - NotEstd Fri Feb 15 17:28:48 2019
exit-1 swp7.2 DataVrf1080 655537 - NotEstd Fri Feb 15 17:28:48 2019
exit-1 swp7.3 DataVrf1081 655537 - NotEstd Fri Feb 15 17:28:48 2019
exit-1 swp7.4 DataVrf1082 655537 - NotEstd Fri Feb 15 17:28:48 2019
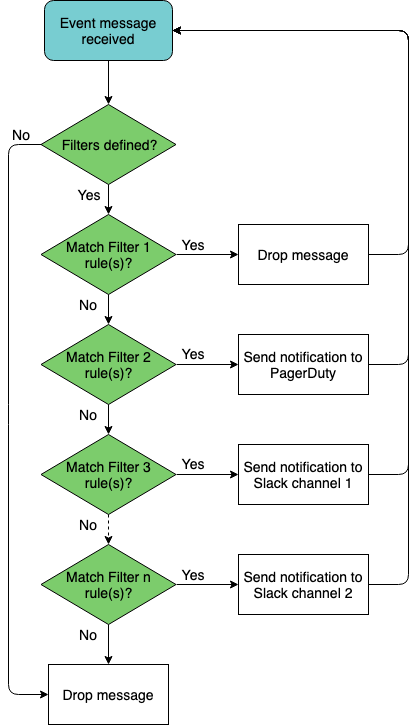
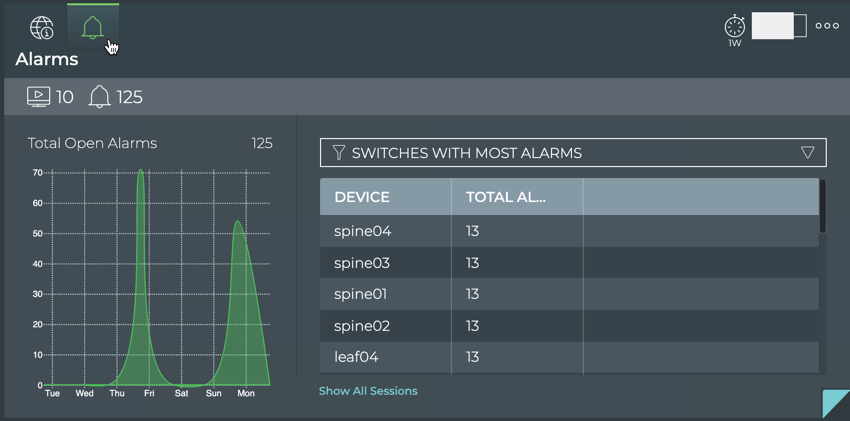
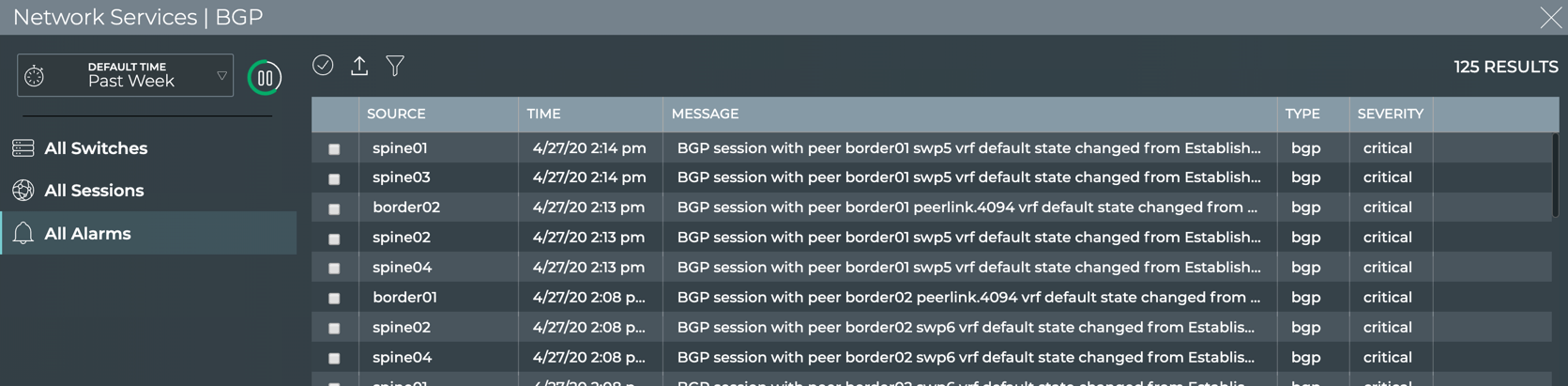
Manage Network Events
The NetQ notifier manages the events that occur for the devices and
components, protocols and services that it receives from the NetQ
Agents. The notifier enables you to capture and filter events that occur
to manage the behavior of your network. This is especially useful when
an interface or routing protocol goes down and you want to get them back
up and running as quickly as possible, preferably before anyone notices
or complains. You can improve resolution time significantly by creating
filters that focus on topics appropriate for a particular group of
users. You can easily create filters around events related to BGP and
MLAG session states, interfaces, links, NTP and other services,
fans, power supplies, and physical sensor measurements.
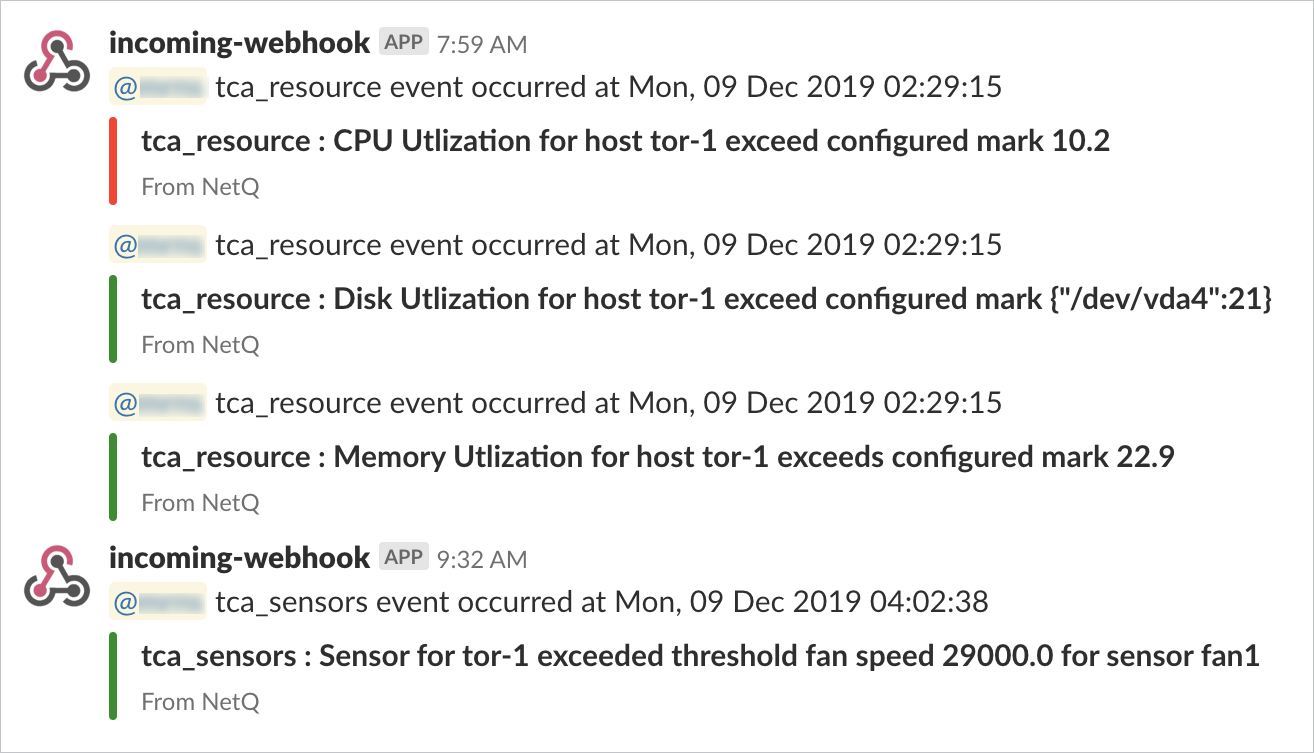
For example, for operators responsible for routing, you can create an
integration with a notification application that notifies them of
routing issues as they occur. This is an example of a Slack message
received on a netq-notifier channel indicating that the BGP session on
switch leaf04 interface swp2 has gone down.
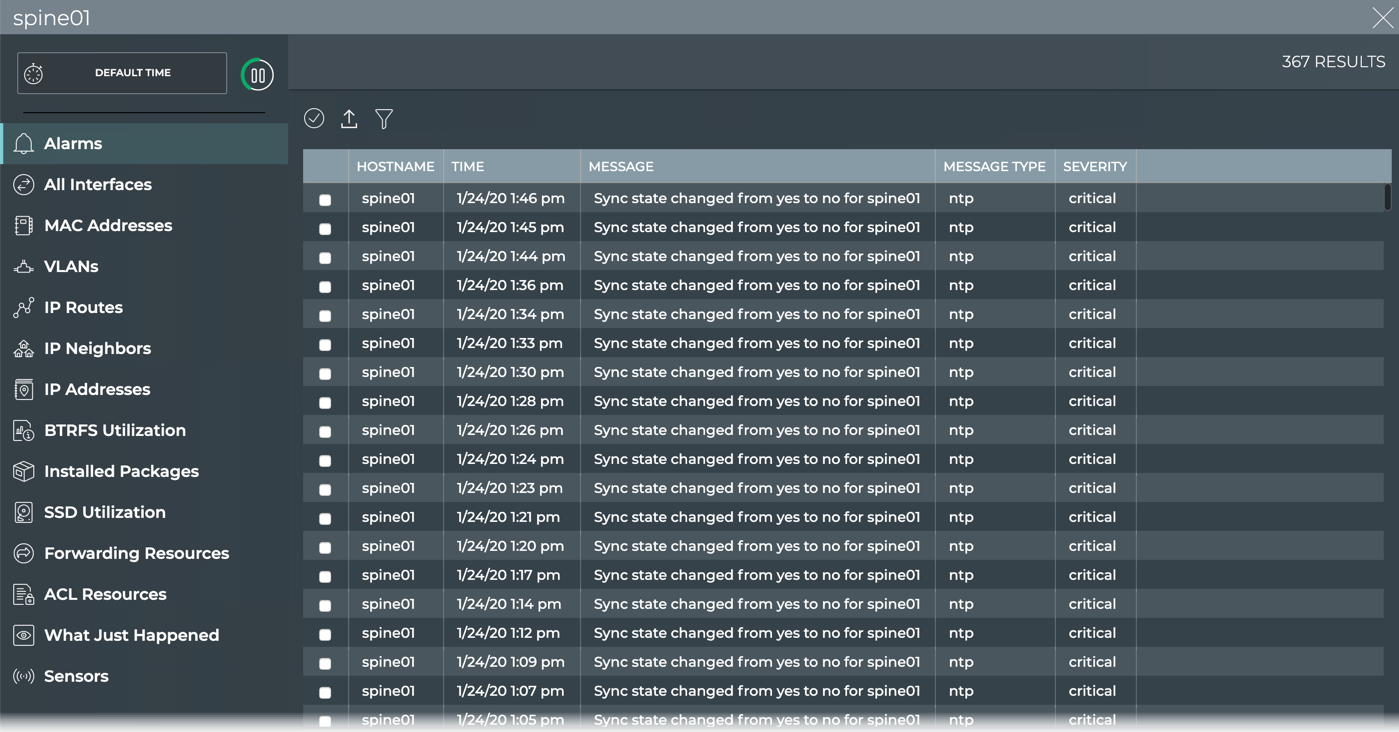
Timestamps in NetQ
Every event or entry in the NetQ database is stored with a timestamp of
when the event was captured by the NetQ Agent on the switch or server.
This timestamp is based on the switch or server time where the NetQ
Agent is running, and is pushed in UTC format. It is important to ensure
that all devices are NTP synchronized to prevent events from being
displayed out of order or not displayed at all when looking for events
that occurred at a particular time or within a time window.
Interface state, IP addresses, routes, ARP/ND table (IP neighbor)
entries and MAC table entries carry a timestamp that represents the time
the event happened (such as when a route is deleted or an interface
comes up) - except the first time the NetQ agent is run. If the
network has been running and stable when a NetQ agent is brought up for
the first time, then this time reflects when the agent was started.
Subsequent changes to these objects are captured with an accurate time
of when the event happened.
Data that is captured and saved based on polling, and just about all
other data in the NetQ database, including control plane state (such as
BGP or MLAG), has a timestamp of when the information was captured
rather than when the event actually happened, though NetQ compensates
for this if the data extracted provides additional information to
compute a more precise time of the event. For example, BGP uptime can be
used to determine when the event actually happened in conjunction with
the timestamp.
When retrieving the timestamp, command outputs display the time in three
ways:
For non-JSON output when the timestamp represents the Last Changed
time, time is displayed in actual date and time when the time change
occurred
For non-JSON output when the timestamp represents an Uptime, time is
displayed as days, hours, minutes, and seconds from the current
time.
For JSON output, time is displayed in microseconds that have passed
since the Epoch time (January 1,
1970 at 00:00:00 GMT)
.
This example shows the difference between the timestamp displays.
If a NetQ Agent is restarted on a device, the timestamps for existing
objects are not updated to reflect this new restart time. Their
timestamps are preserved relative to the original start time of the
Agent. A rare exception is if the device is rebooted between the time it
takes the Agent being stopped and restarted; in this case, the time is
once again relative to the start time of the Agent.
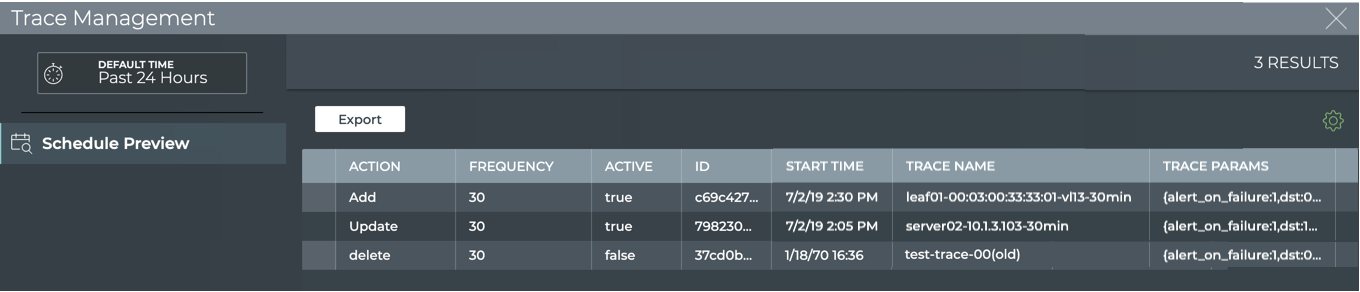
Exporting NetQ Data
Data from the NetQ Platform can be exported in a couple of ways:
use the json option to output command results to JSON format for
parsing in other applications
use the UI to export data from the full screen cards
Example Using the CLI
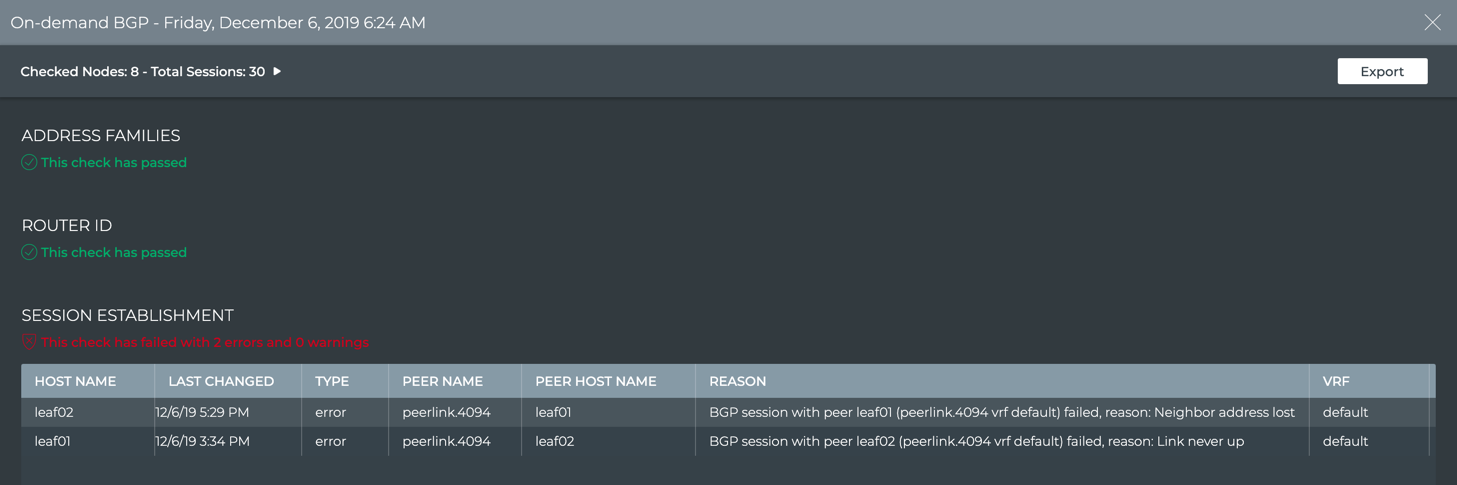
You can check the state of BGP on your network with netq check bgp:
cumulus@leaf01:~$ netq check bgp
Total Nodes: 25, Failed Nodes: 3, Total Sessions: 220 , Failed Sessions: 24,
Hostname VRF Peer Name Peer Hostname Reason Last Changed
----------------- --------------- ----------------- ----------------- --------------------------------------------- -------------------------
exit01 DataVrf1080 swp6.2 firewall01 BGP session with peer firewall01 swp6.2: AFI/ Tue Feb 12 18:11:16 2019
SAFI evpn not activated on peer
exit01 DataVrf1080 swp7.2 firewall02 BGP session with peer firewall02 (swp7.2 vrf Tue Feb 12 18:11:27 2019
DataVrf1080) failed,
reason: Peer not configured
exit01 DataVrf1081 swp6.3 firewall01 BGP session with peer firewall01 swp6.3: AFI/ Tue Feb 12 18:11:16 2019
SAFI evpn not activated on peer
exit01 DataVrf1081 swp7.3 firewall02 BGP session with peer firewall02 (swp7.3 vrf Tue Feb 12 18:11:27 2019
DataVrf1081) failed,
reason: Peer not configured
...
When you show the output in JSON format, this same command looks like
this:
cumulus@leaf01:~$ netq check bgp json
{
"failedNodes":[
{
"peerHostname":"firewall01",
"lastChanged":1549995080.0,
"hostname":"exit01",
"peerName":"swp6.2",
"reason":"BGP session with peer firewall01 swp6.2: AFI/SAFI evpn not activated on peer",
"vrf":"DataVrf1080"
},
{
"peerHostname":"firewall02",
"lastChanged":1549995449.7279999256,
"hostname":"exit01",
"peerName":"swp7.2",
"reason":"BGP session with peer firewall02 (swp7.2 vrf DataVrf1080) failed, reason: Peer not configured",
"vrf":"DataVrf1080"
},
{
"peerHostname":"firewall01",
"lastChanged":1549995080.0,
"hostname":"exit01",
"peerName":"swp6.3",
"reason":"BGP session with peer firewall01 swp6.3: AFI/SAFI evpn not activated on peer",
"vrf":"DataVrf1081"
},
{
"peerHostname":"firewall02",
"lastChanged":1549995449.7349998951,
"hostname":"exit01",
"peerName":"swp7.3",
"reason":"BGP session with peer firewall02 (swp7.3 vrf DataVrf1081) failed, reason: Peer not configured",
"vrf":"DataVrf1081"
},
...
],
"summary": {
"checkedNodeCount": 25,
"failedSessionCount": 24,
"failedNodeCount": 3,
"totalSessionCount": 220
}
}
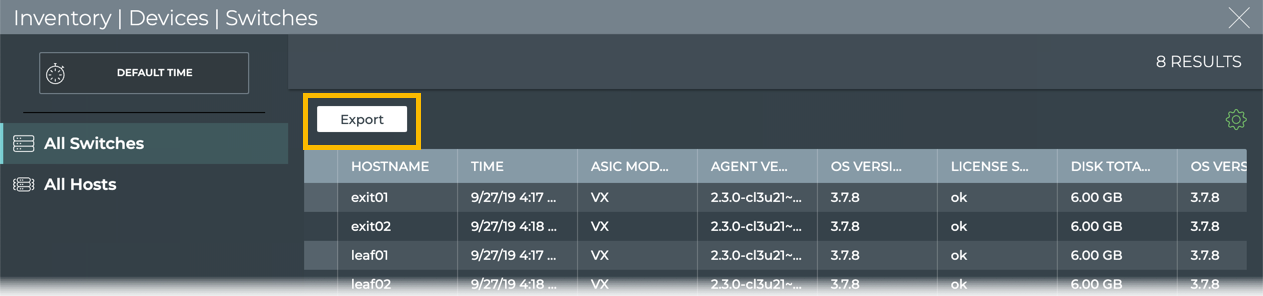
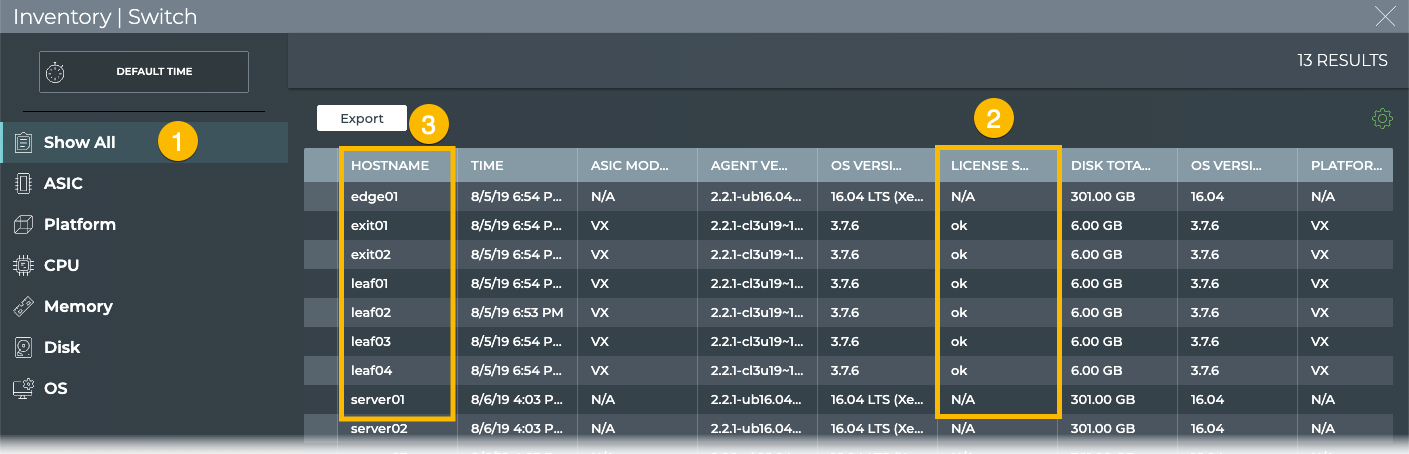
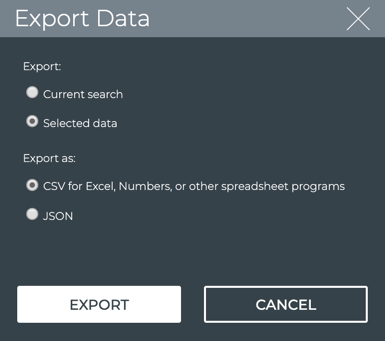
Example Using the UI
Open the full screen Switch Inventory card, select the data to export,
and click Export.
Important File Locations
The primary configuration file for all Cumulus NetQ tools, netq.yml,
resides in /etc/netq by default.
Log files are stored in /var/logs/ by default.
Refer to Investigate NetQ Issues
for a complete listing of configuration files and logs for use in issue resolution.
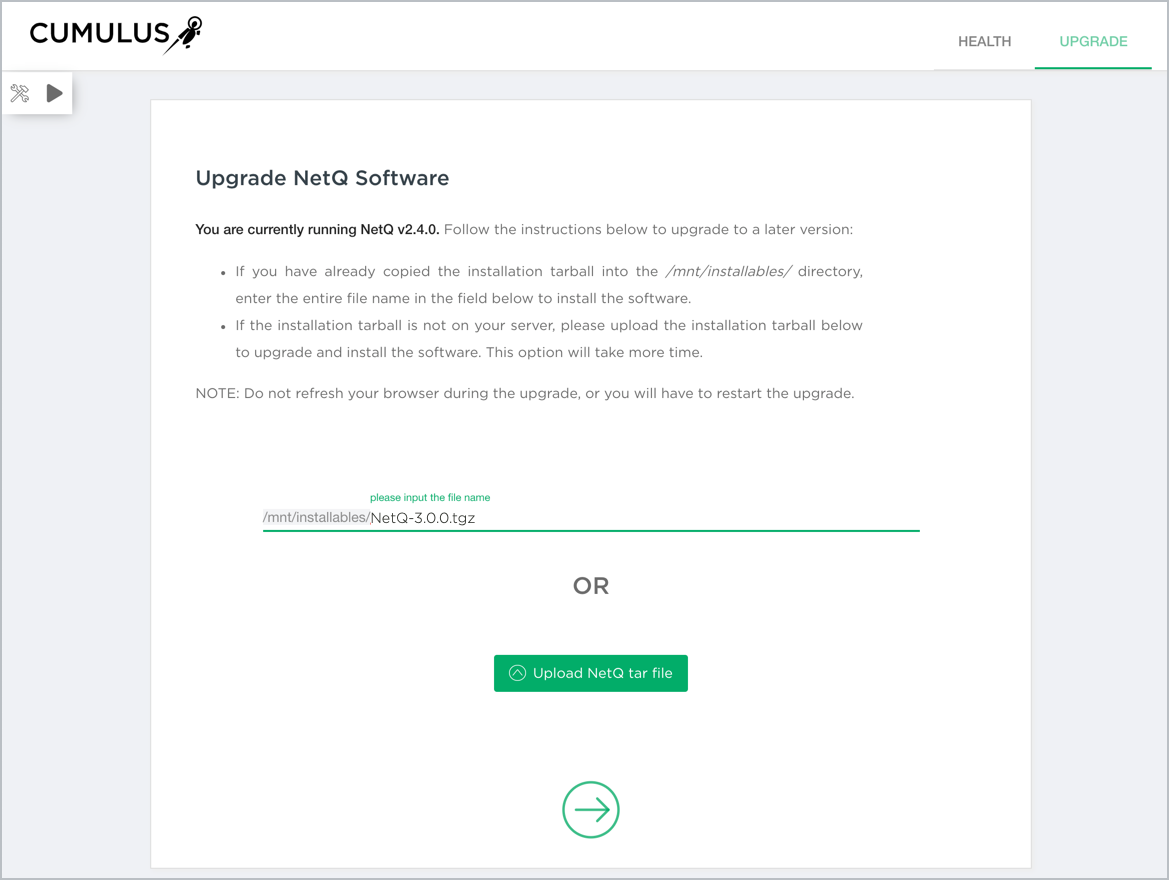
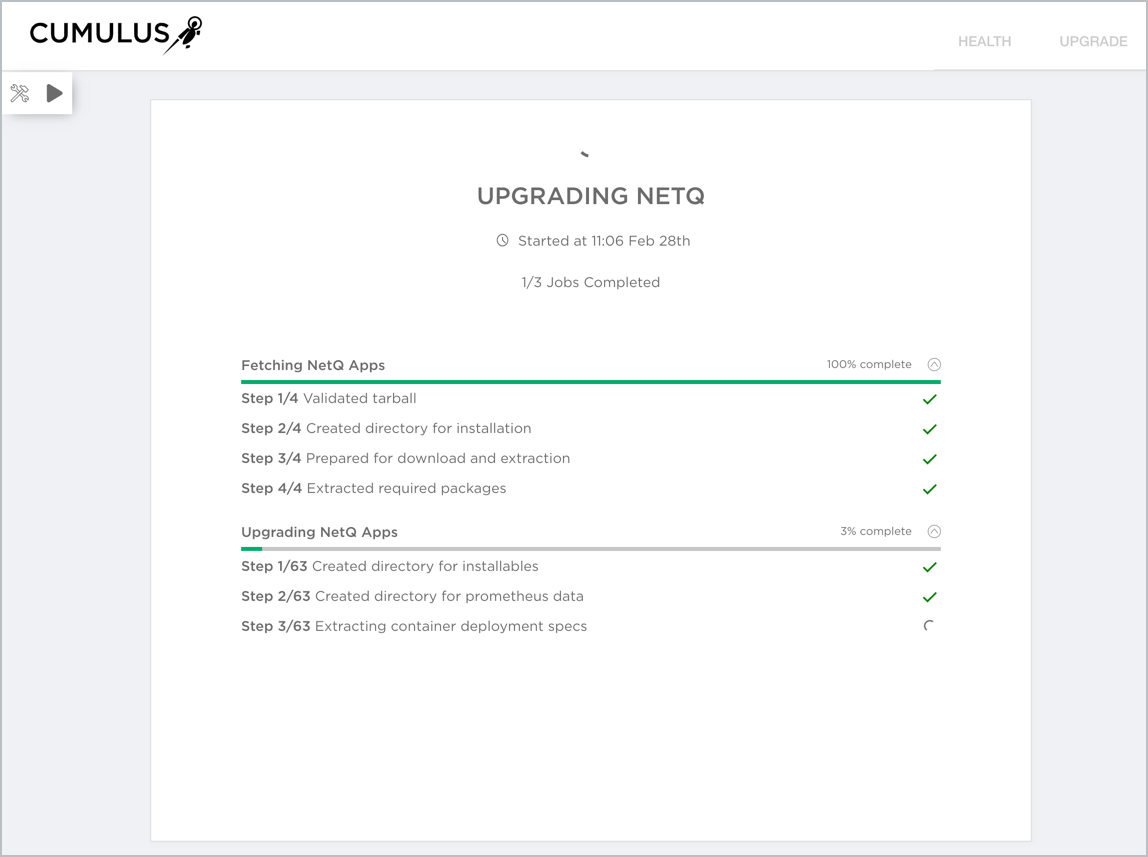
Install NetQ
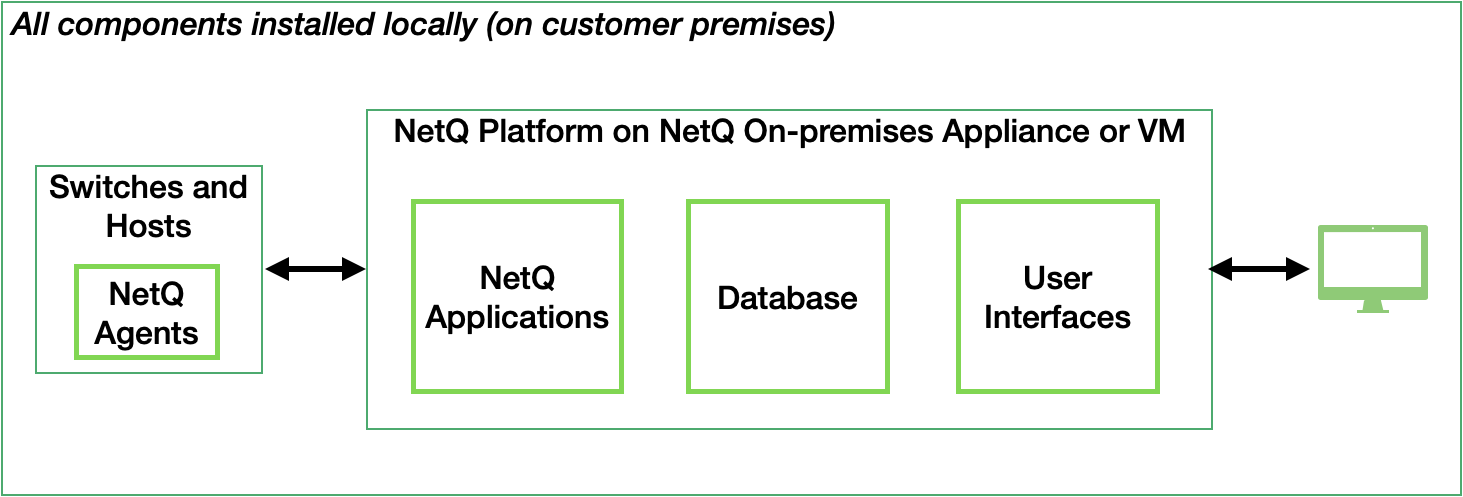
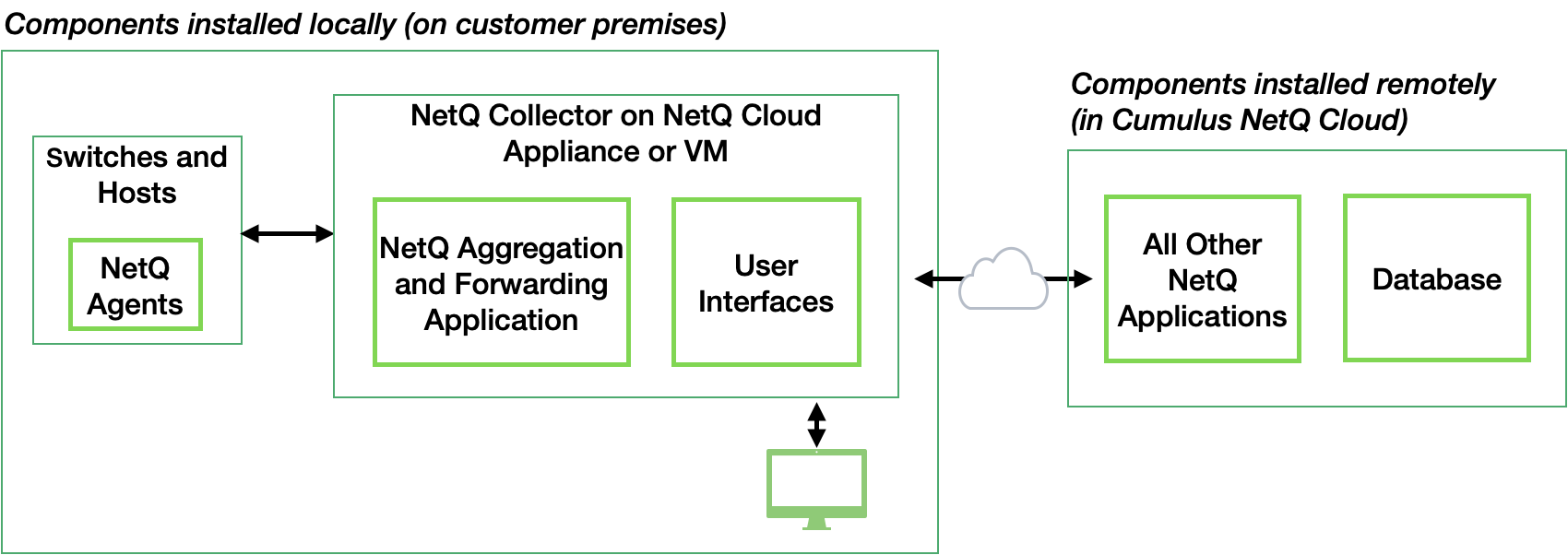
The complete Cumulus NetQ solution contains several components that must be installed, including the NetQ applications, the database, and the NetQ Agents. NetQ can be deployed in two arrangements:
All software components installed locally (the applications and database are installed as a single entity, called the NetQ Platform) running on the NetQ On-premises Appliance or NetQ On-premises Virtual Machine (VM); known hereafter as the on-premises solution
Only the aggregation and forwarding application software installed locally (called the NetQ Collector) running on the NetQ Cloud Appliance or NetQ Cloud VM, with the database and all other applications installed in the cloud; known hereafter as the cloud solution
The NetQ Agents reside on the switches and hosts being monitored in your network.
For the on-premises solution, the NetQ Agents collect and transmit data from the switches and/or hosts back to the NetQ On-premises Appliance or Virtual Machine running the NetQ Platform, which in turn processes and stores the data in its database. This data is then provided for display through several user interfaces.
For the cloud solution, the NetQ Agent function is exactly the same, transmitting collected data, but instead sends it to the NetQ Collector containing only the aggregation and forwarding application. The NetQ Collector then transmits this data to Cumulus Networks cloud-based infrastructure for further processing and storage. This data is then provided for display through the same user interfaces as the on-premises solution. In this solution, the browser interface can be pointed to the local NetQ Cloud Appliance or VM, or directly to netq.cumulusnetworks.com.
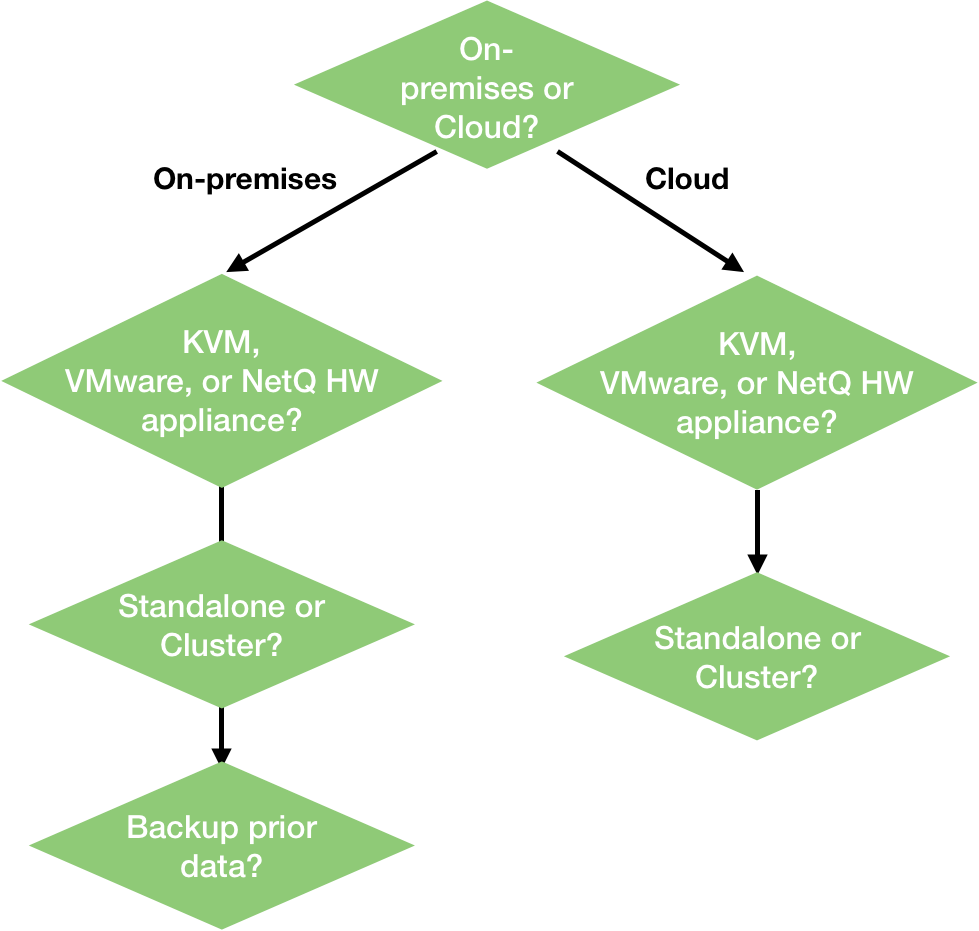
Installation Choices
There are several choices that you must make to determine what steps you need to perform to install the NetQ solution. First and foremost, you must determine whether you intend to deploy the solution fully on your premises or if you intend to deploy the cloud solution. Secondly, you must decide whether you are going to deploy a Virtual Machine on your own hardware or use one of the Cumulus NetQ appliances. Thirdly, you also must determine whether you want to install the software on a single server or as a server cluster. Finally, if you have an existing on-premises solution and want to save your existing NetQ data, you must backup that data before installing the new software.
The documentation walks you through these choices and then provides the instructions specific to your selections.
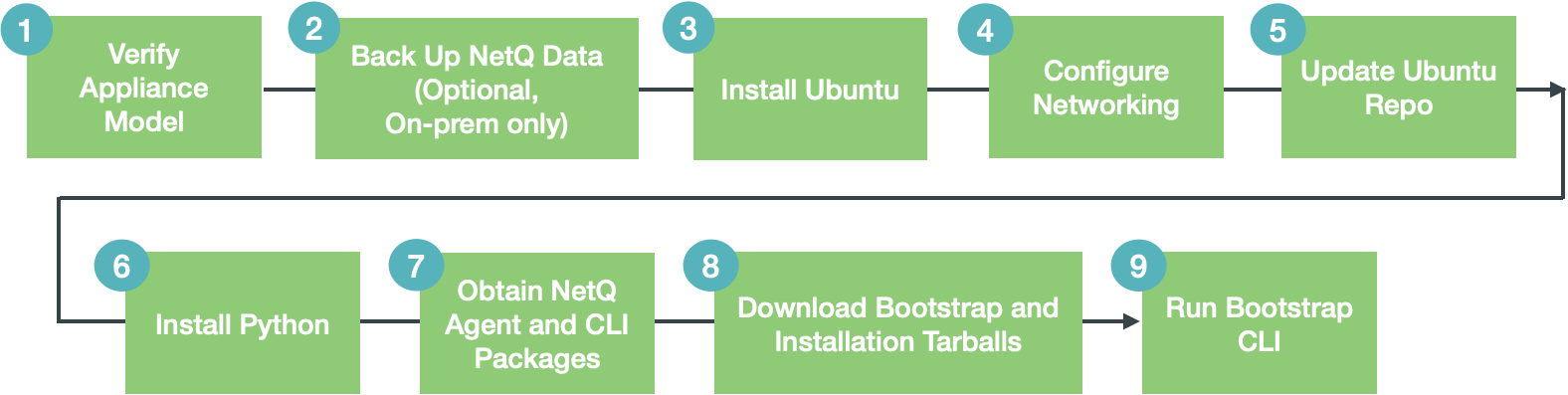
Installation Workflow Summary
No matter how you answer the questions above, the installation workflow can be summarized as follows:
Prepare physical server or virtual machine.
Install the software (NetQ Platform or NetQ Collector).
Install and configure NetQ Agents on switches and hosts.
Install and configure NetQ CLI on switches and hosts (optional, but useful).
Install NetQ System Platform
This topic walks you through the NetQ System Platform installation decisions and then provides installation steps based on those choices. If you are already comfortable with your installation choices, you may use the matrix in Install NetQ Quick Start to go directly to the installation steps.
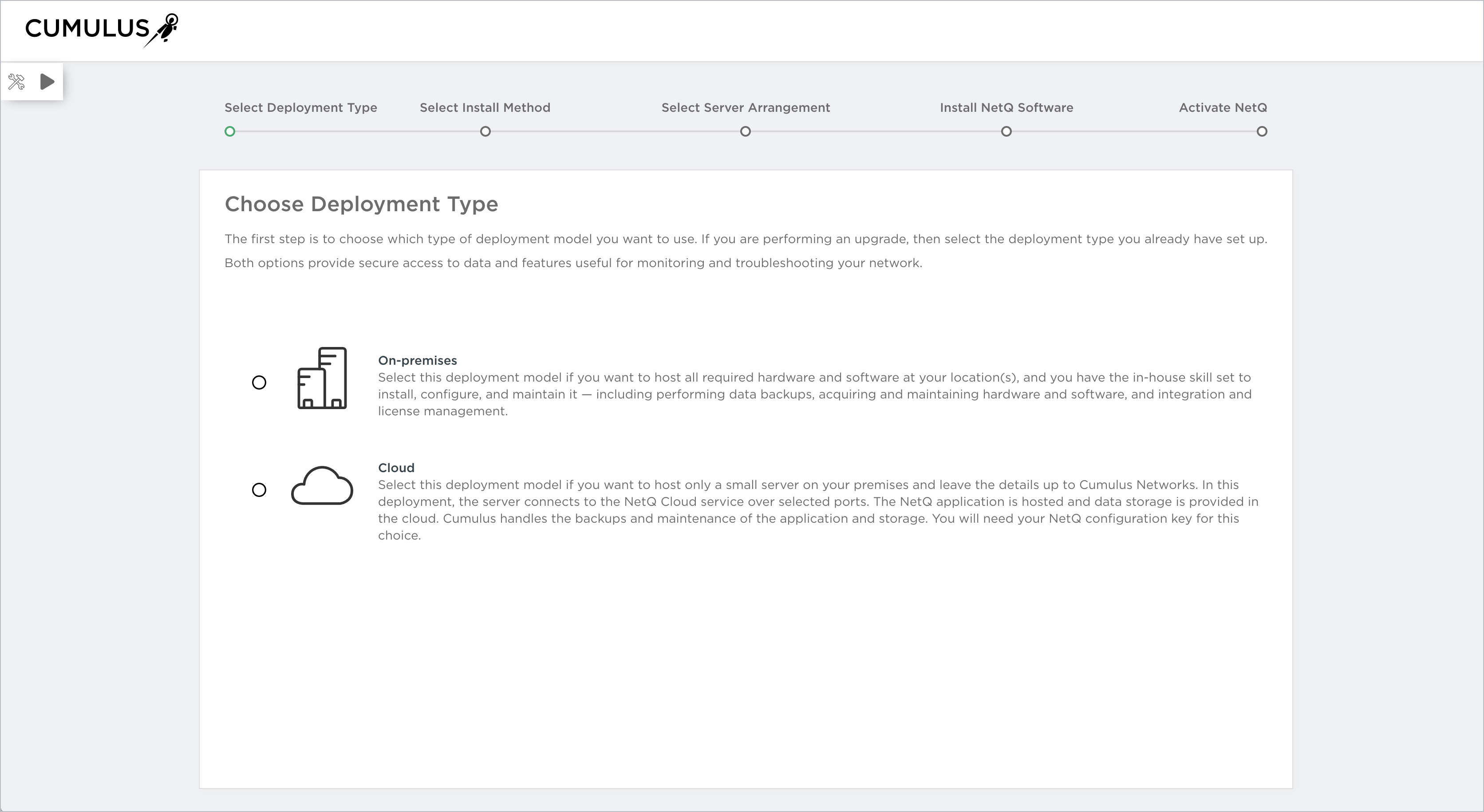
To install NetQ 3.0.x, you must first decide whether you want to install the NetQ Platform in an on-premises or cloud deployment. Both deployment options provide secure access to data and features useful for monitoring and troubleshooting your network, and each has its benefits.
It is common to select an on-premises deployment model if you want to host all required hardware and software at your location, and you have the in-house skill set to install, configure, and maintain it—including performing data backups, acquiring and maintaining hardware and software, and integration and license management. This model is also a good choice if you want very limited or no access to the Internet from switches and hosts in your network. Some companies simply want complete control of the their network, and no outside impact.
If, however, you find that you want to host only a small server on your premises and leave the details up to Cumulus Networks, then a cloud deployment might be the right choice for you. With a cloud deployment, a small local server connects to the NetQ Cloud service over selected ports or through a proxy server. Only data aggregation and forwarding is supported. The majority of the NetQ applications are hosted and data storage is provided in the cloud. Cumulus handles the backups and maintenance of the application and storage. This model is often chosen when it is untenable to support deployment in-house or if you need the flexibility to scale quickly, while also reducing capital expenses.
Click the deployment model you want to use to continue with installation:
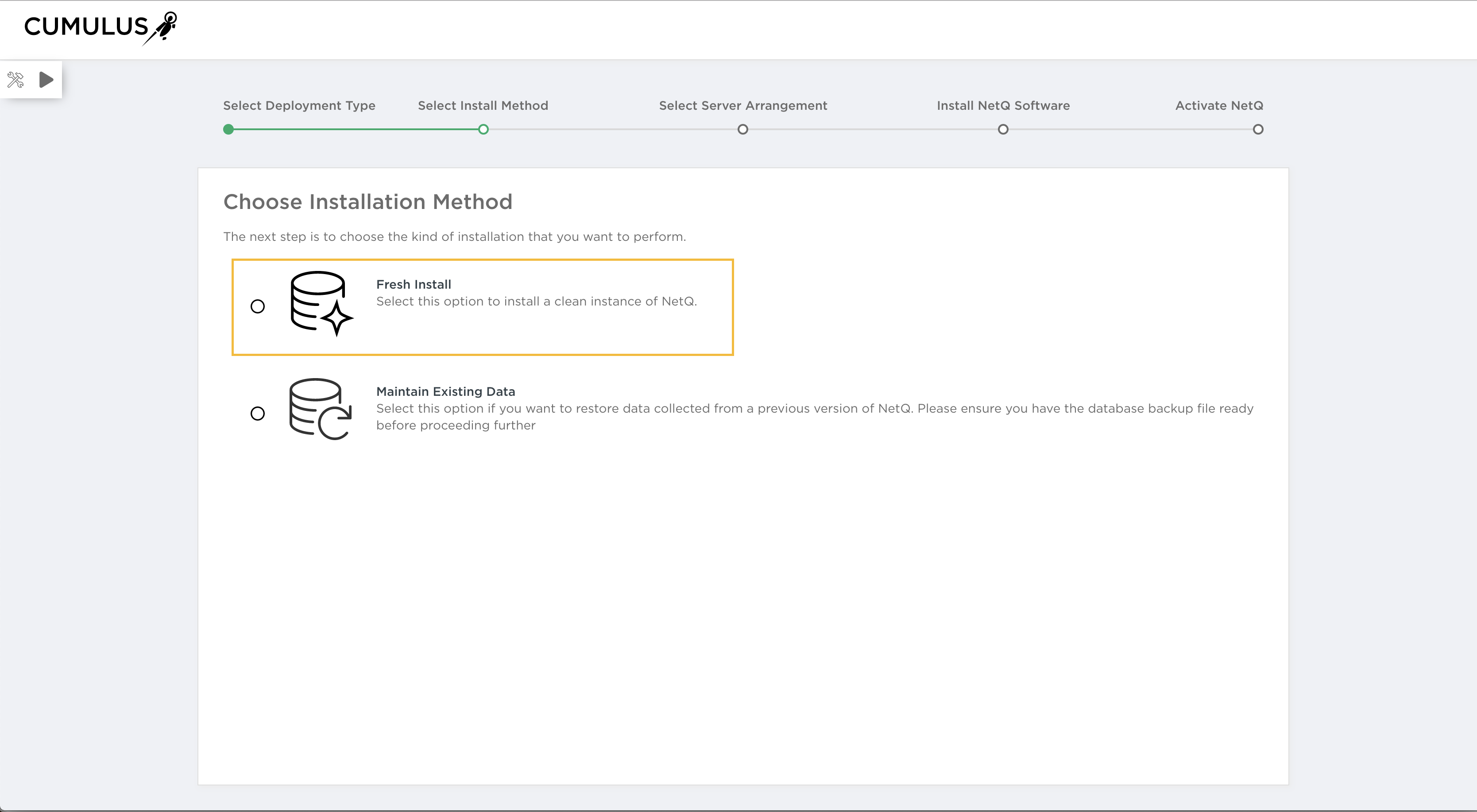
On-premises deployments of NetQ can use a single server or a server cluster. In either case, you can use either the Cumulus NetQ Appliance or your own server running a KVM or VMware Virtual Machine (VM). This topic walks you through the installation for each of these on-premises options.
The next installation step is to decide whether you are deploying a single server or a server cluster. Both options provide the same services and features. The biggest difference is in the number of servers to be deployed and in the continued availability of services running on those servers should hardware failures occur.
A single server is easier to set up, configure and manage, but can limit your ability to scale your network monitoring quickly. Multiple servers is a bit more complicated, but you limit potential downtime and increase availability by having more than one server that can run the software and store the data.
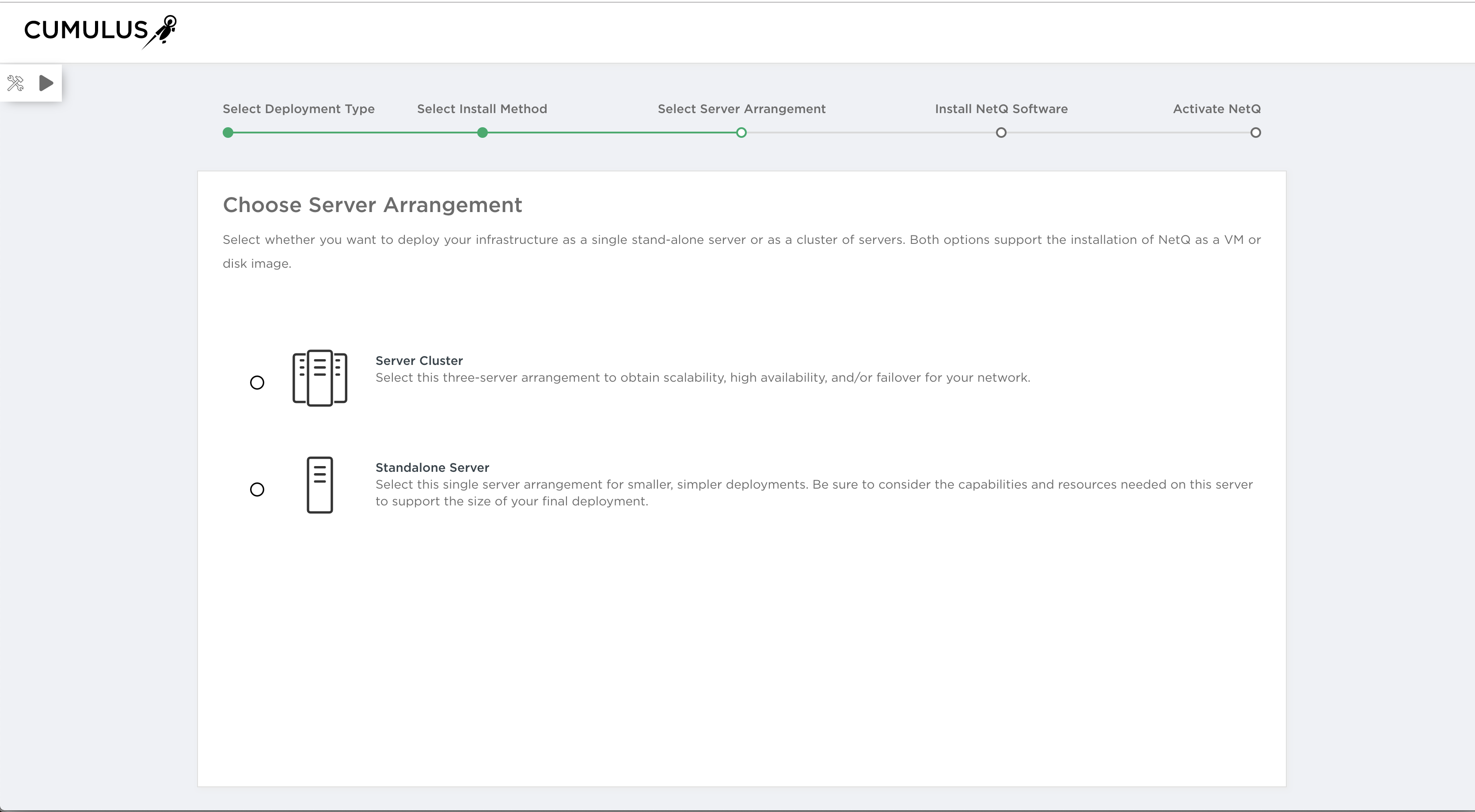
Select the standalone single-server arrangements for smaller, simpler deployments. Be sure to consider the capabilities and resources needed on this server to support the size of your final deployment.
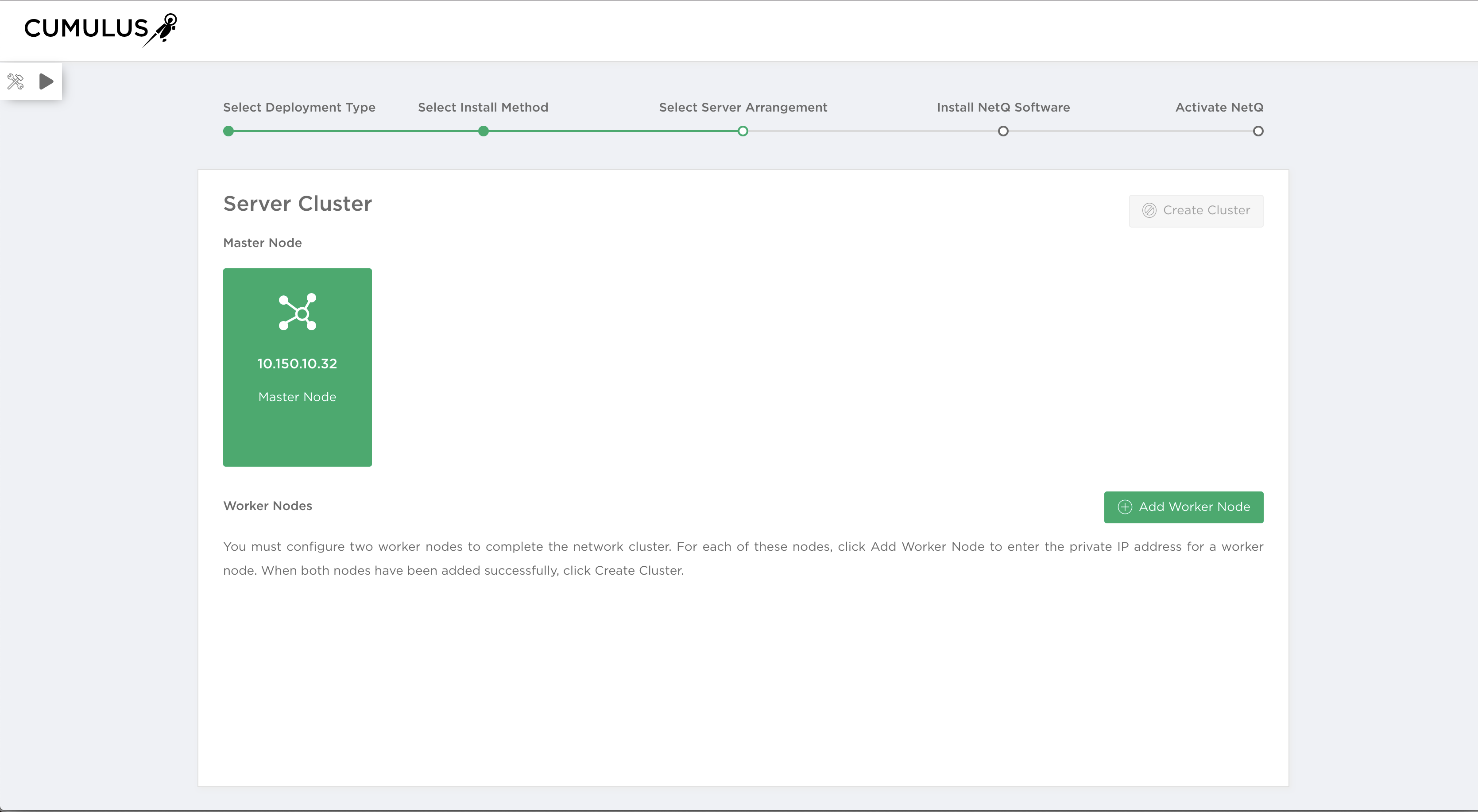
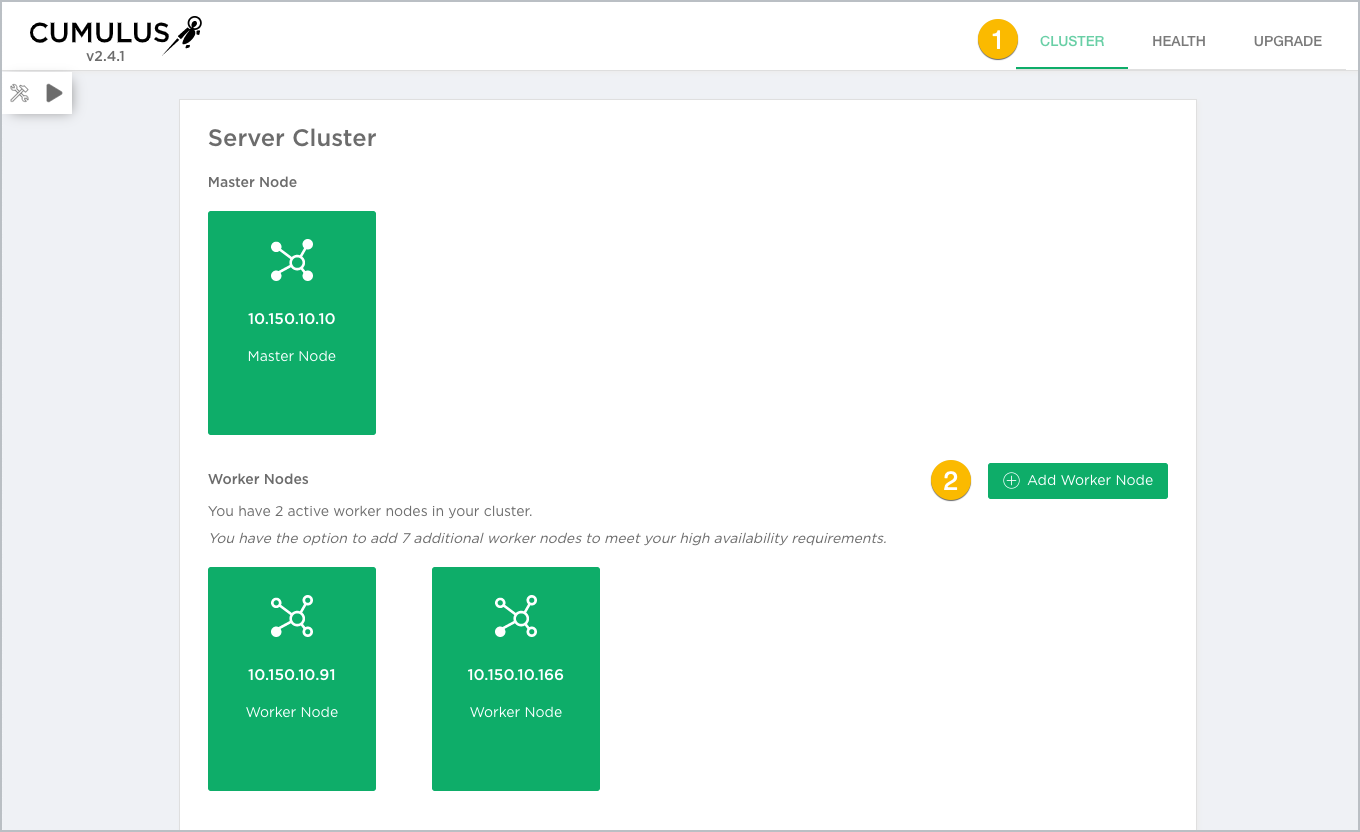
Select the server cluster arrangement to obtain scalability and high availability for your network. You can configure one master node and up to nine worker nodes.
Click the server arrangement you want to use to begin installation:
Cloud deployments of NetQ can use a single server or a server cluster on site. The NetQ database remains in the cloud either way. You can use either the Cumulus NetQ Cloud Appliance or your own server running a KVM or VMware Virtual Machine (VM). This topic walks you through the installation for each of these cloud options.
The next installation step is to decide whether you are deploying a single server or a server cluster. Both options provide the same services and features. The biggest difference is in the number of servers to be deployed and in the continued availability of services running on those servers should hardware failures occur.
A single server is easier to set up, configure and manage, but can limit your ability to scale your network monitoring quickly. Multiple servers is a bit more complicated, but you limit potential downtime and increase availability by having more than one server that can run the software and store the data.
Click the server arrangement you want to use to begin installation:
Set Up Your KVM Virtual Machine for a Single On-premises Server
Follow these steps to setup and configure your VM on a single server in an on-premises deployment:
Verify that your system meets the VM requirements.
Resource
Minimum Requirements
Processor
Eight (8) virtual CPUs
Memory
64 GB RAM
Local disk storage
256 GB SSD with minimum disk IOPS of 1000 for a standard 4kb block size (Note: This must be an SSD; use of other storage options can lead to system instability and are not supported.)
Network interface speed
1 Gb NIC
Hypervisor
KVM/QCOW (QEMU Copy on Write) image for servers running CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises server:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
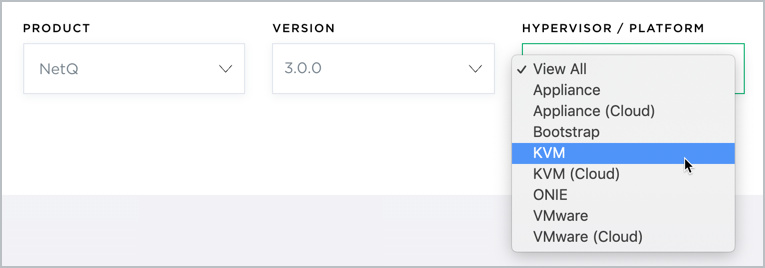
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
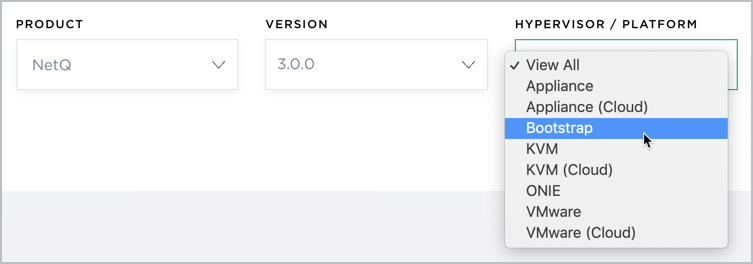
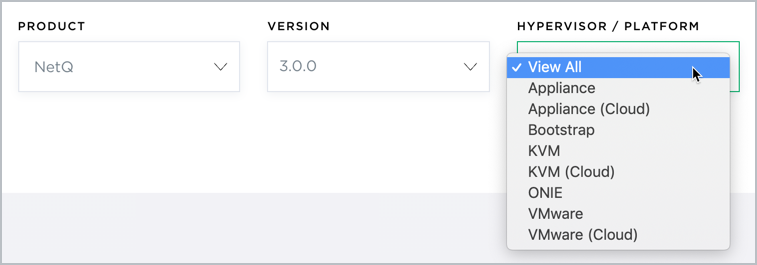
Select KVM from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0.tgz installation package.
Setup and configure your VM.
KVM Example Configuration
This example shows the VM setup process for a system with Libvirt and KVM/QEMU installed.
Confirm that the SHA256 checksum matches the one posted on the NVIDIA Application Hub to ensure the image download has not been corrupted.
Copy the QCOW2 image to a directory where you want to run it.
Tip: Copy, instead of moving, the original QCOW2 image that was downloaded to avoid re-downloading it again later should you need to perform this process again.
Replace the disk path value with the location where the QCOW2 image is to reside. Replace network model value (eth0 in the above example) with the name of the interface where the VM is connected to the external network.
Or, for a Bridged VM, where the VM attaches to a bridge which has already been setup to allow for external access:
Replace network bridge value (br0 in the above example) with the name of the (pre-existing) bridge interface where the VM is connected to the external network.
Make note of the name used during install as this is needed in a later step.
Watch the boot process in another terminal window.
$ virsh console netq_ts
Verify the platform is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
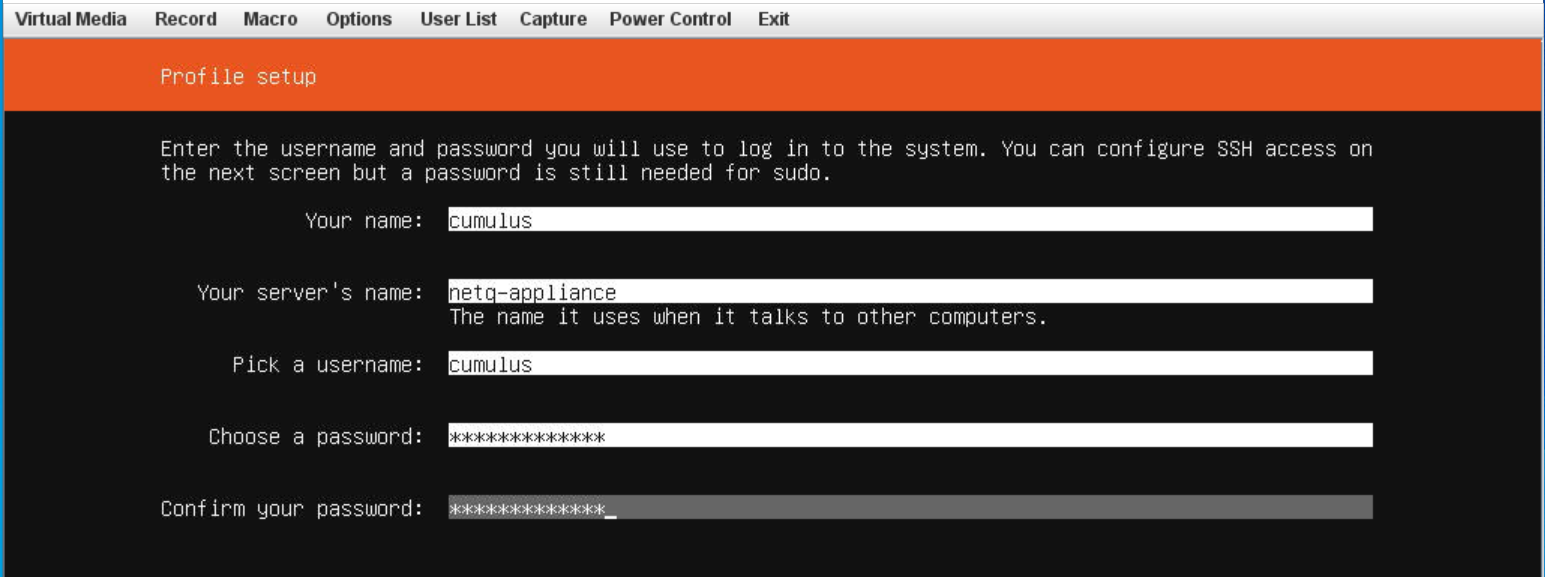
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Copy the QCOW2 image to a directory where you want to run it.
Tip: Copy, instead of moving, the original QCOW2 image that was downloaded to avoid re-downloading it again later should you need to perform this process again.
Replace the disk path value with the location where the QCOW2 image is to reside. Replace network model value (eth0 in the above example) with the name of the interface where the VM is connected to the external network.
Or, for a Bridged VM, where the VM attaches to a bridge which has already been setup to allow for external access:
Replace network bridge value (br0 in the above example) with the name of the (pre-existing) bridge interface where the VM is connected to the external network.
Make note of the name used during install as this is needed in a later step.
Watch the boot process in another terminal window.
$ virsh console netq_ts
Verify the platform is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
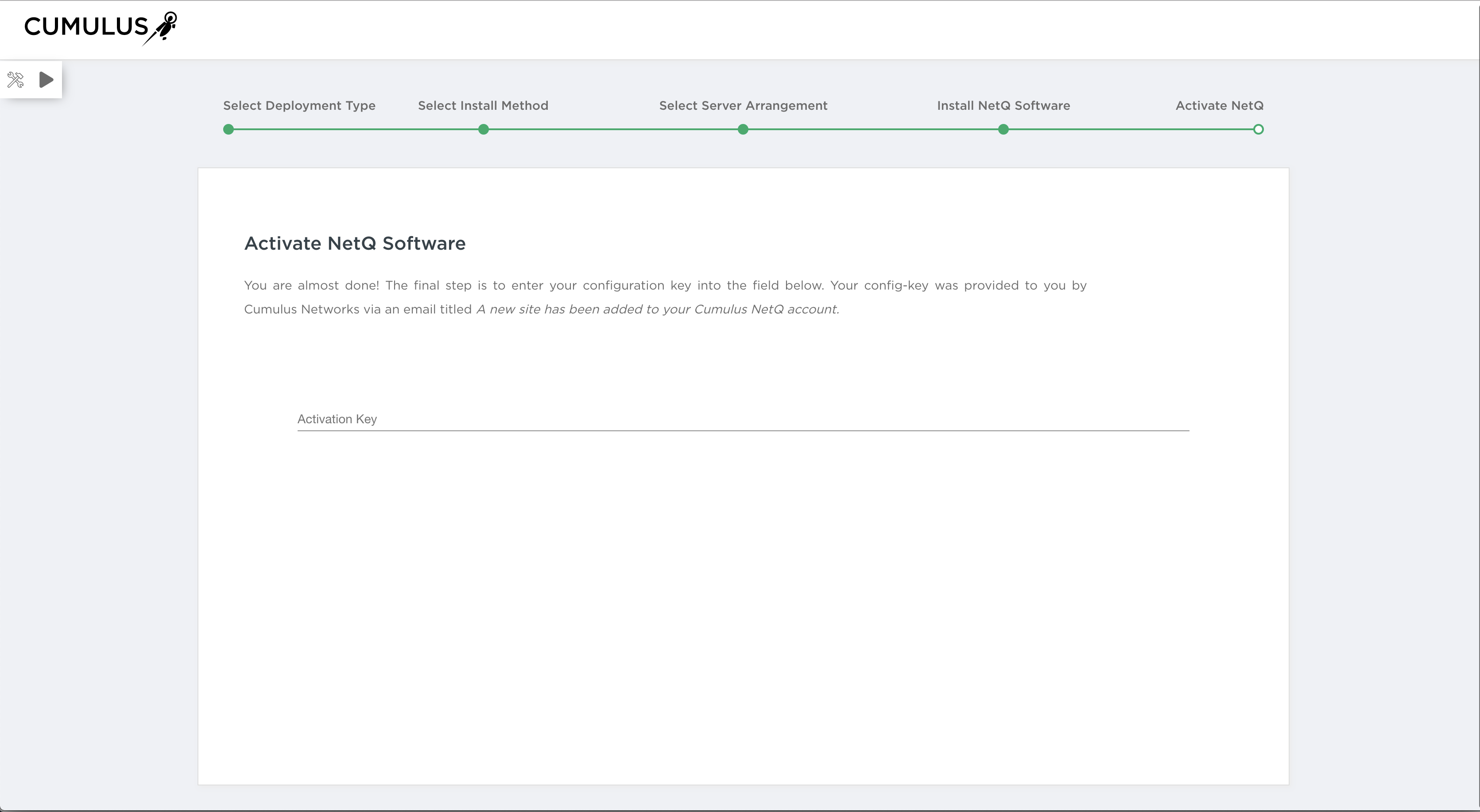
If you have changed the IP address or hostname of the NetQ Cloud VM after this step, you need to re-register this address with NetQ as follows:
Reset the VM.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Set Up Your KVM Virtual Machine for an On-premises Server Cluster
First configure the VM on the master node, and then configure the VM on each worker node.
Follow these steps to setup and configure your VM on a cluster of servers in an on-premises deployment:
Verify that your master node meets the VM requirements.
Resource
Minimum Requirements
Processor
Eight (8) virtual CPUs
Memory
64 GB RAM
Local disk storage
256 GB SSD with minimum disk IOPS of 1000 for a standard 4kb block size (Note: This must be an SSD; use of other storage options can lead to system instability and are not supported.)
Network interface speed
1 Gb NIC
Hypervisor
KVM/QCOW (QEMU Copy on Write) image for servers running CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises servers:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
Additionally, for internal cluster communication, you must open these ports:
Port
Protocol
Component Access
8080
TCP
Admin API
5000
TCP
Docker registry
6443
TCP
Kubernetes API server
10250
TCP
kubelet health probe
2379
TCP
etcd
2380
TCP
etcd
7072
TCP
Kafka JMX monitoring
9092
TCP
Kafka client
7071
TCP
Cassandra JMX monitoring
7000
TCP
Cassandra cluster communication
9042
TCP
Cassandra client
7073
TCP
Zookeeper JMX monitoring
2888
TCP
Zookeeper cluster communication
3888
TCP
Zookeeper cluster communication
2181
TCP
Zookeeper client
36443
TCP
Kubernetes control plane
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
Select KVM from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0.tgz installation package.
Setup and configure your VM.
KVM Example Configuration
This example shows the VM setup process for a system with Libvirt and KVM/QEMU installed.
Confirm that the SHA256 checksum matches the one posted on the NVIDIA Application Hub to ensure the image download has not been corrupted.
Copy the QCOW2 image to a directory where you want to run it.
Tip: Copy, instead of moving, the original QCOW2 image that was downloaded to avoid re-downloading it again later should you need to perform this process again.
Replace the disk path value with the location where the QCOW2 image is to reside. Replace network model value (eth0 in the above example) with the name of the interface where the VM is connected to the external network.
Or, for a Bridged VM, where the VM attaches to a bridge which has already been setup to allow for external access:
Replace network bridge value (br0 in the above example) with the name of the (pre-existing) bridge interface where the VM is connected to the external network.
Make note of the name used during install as this is needed in a later step.
Watch the boot process in another terminal window.
$ virsh console netq_ts
Verify the master node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Add the same NEW_HOSTNAME value to /etc/hosts on your VM for the localhost entry. Example:
127.0.0.1 localhost NEW_HOSTNAME
Run the Bootstrap CLI on the master node. Be sure to replace the eth0 interface used in this example with the interface on the server used to listen for NetQ Agents.
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Verify that your first worker node meets the VM requirements, as described in Step 1.
Confirm that the needed ports are open for communications, as described in Step 2.
Open your hypervisor and setup the VM in the same manner as for the master node.
Make a note of the private IP address you assign to the worker node. It is needed for later installation steps.
Verify the worker node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Copy the QCOW2 image to a directory where you want to run it.
Tip: Copy, instead of moving, the original QCOW2 image that was downloaded to avoid re-downloading it again later should you need to perform this process again.
Replace the disk path value with the location where the QCOW2 image is to reside. Replace network model value (eth0 in the above example) with the name of the interface where the VM is connected to the external network.
Or, for a Bridged VM, where the VM attaches to a bridge which has already been setup to allow for external access:
Replace network bridge value (br0 in the above example) with the name of the (pre-existing) bridge interface where the VM is connected to the external network.
Make note of the name used during install as this is needed in a later step.
Watch the boot process in another terminal window.
$ virsh console netq_ts
Verify the master node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
If you have changed the IP address or hostname of the NetQ Cloud VM after this step, you need to re-register this address with NetQ as follows:
Reset the VM.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Verify that your first worker node meets the VM requirements, as described in Step 1.
Confirm that the needed ports are open for communications, as described in Step 2.
Open your hypervisor and setup the VM in the same manner as for the master node.
Make a note of the private IP address you assign to the worker node. It is needed for later installation steps.
Verify the worker node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Set Up Your VMware Virtual Machine for a Single On-premises Server
Follow these steps to setup and configure your VM on a single server in an on-premises deployment:
Verify that your system meets the VM requirements.
Resource
Minimum Requirements
Processor
Eight (8) virtual CPUs
Memory
64 GB RAM
Local disk storage
256 GB SSD with minimum disk IOPS of 1000 for a standard 4kb block size (Note: This must be an SSD; use of other storage options can lead to system instability and are not supported.)
Network interface speed
1 Gb NIC
Hypervisor
VMware ESXi™ 6.5 or later (OVA image) for servers running Cumulus Linux, CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises server:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
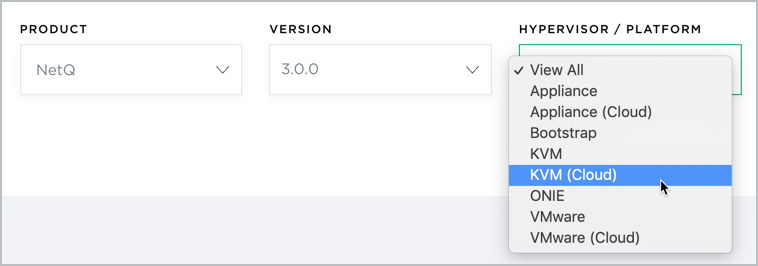
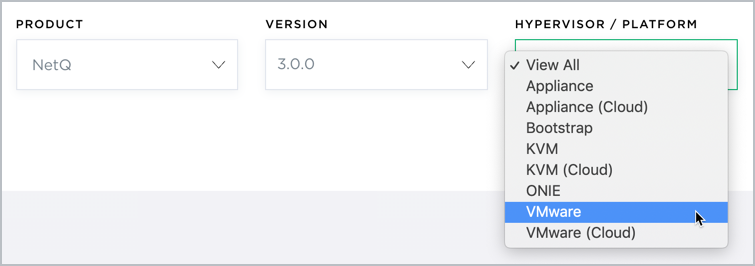
Select VMware from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0.tgz installation package.
Setup and configure your VM.
VMware Example Configuration
This example shows the VM setup process using an OVA file with VMware ESXi.
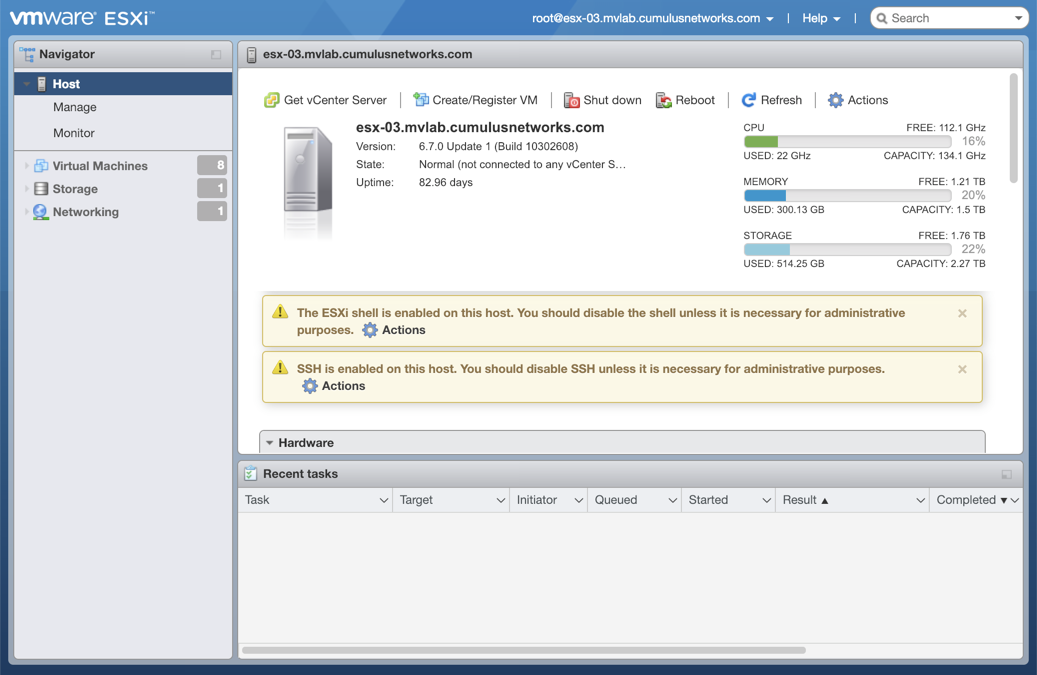
Enter the address of the hardware in your browser.
Log in to VMware using credentials with root access.
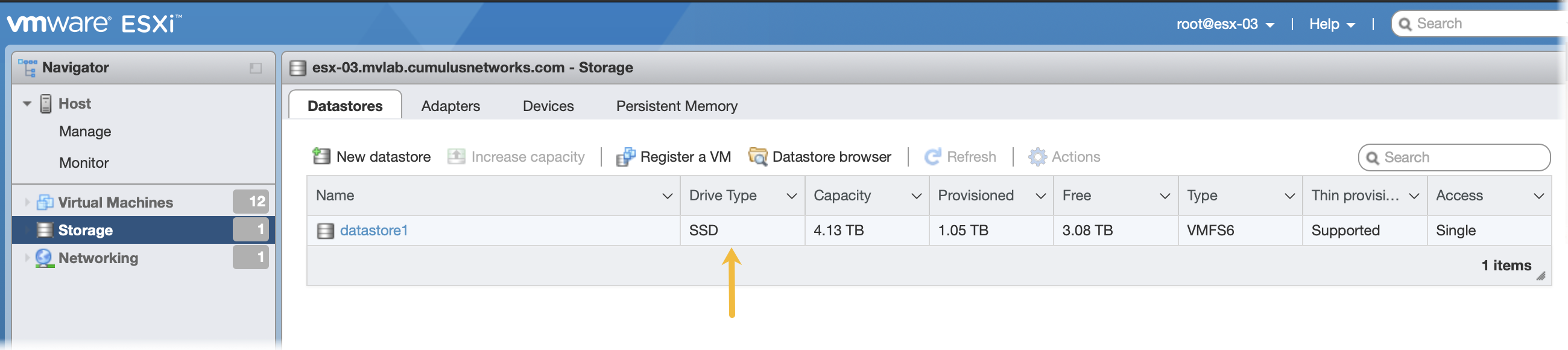
Click Storage in the Navigator to verify you have an SSD installed.
Click Create/Register VM at the top of the right pane.
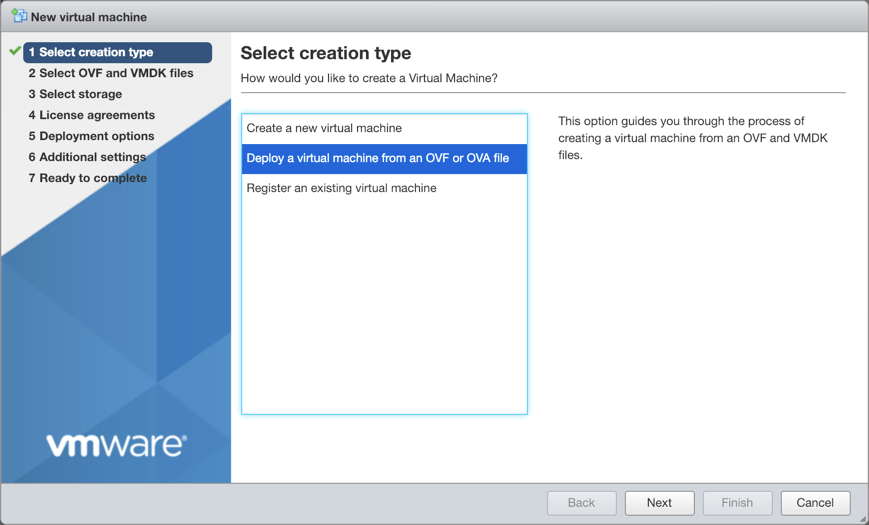
Select Deploy a virtual machine from an OVF or OVA file, and click Next.
Provide a name for the VM, for example NetQ.
Tip: Make note of the name used during install as this is needed in a later step.
Drag the NetQ image file you downloaded from the NVIDIA Application Hub to the installation wizard, then click Next.
Select the storage type and data store for the image, then click Next.
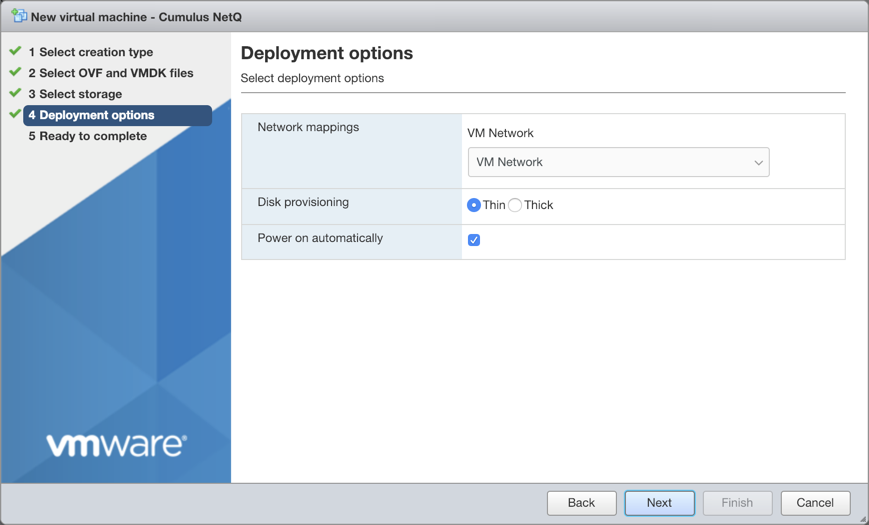
Accept the default deployment options or modify them according to your network needs. Click Next when you are finished.
Review the configuration summary. Click Back to change any of the settings, or click Finish to continue with the creation of the VM.
The progress of the request is shown in the Recent Tasks window at the bottom of the application. This may take some time. After the VM is deployed, the wizard displays the full hardware and configuration details.
Verify the platform is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Set Up Your VMware Virtual Machine for a Single Cloud Server
Follow these steps to setup and configure your VM for a cloud deployment:
Verify that your system meets the VM requirements.
Resource
Minimum Requirements
Processor
Four (4) virtual CPUs
Memory
8 GB RAM
Local disk storage
64 GB
Network interface speed
1 Gb NIC
Hypervisor
VMware ESXi™ 6.5 or later (OVA image) for servers running Cumulus Linux, CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises server:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
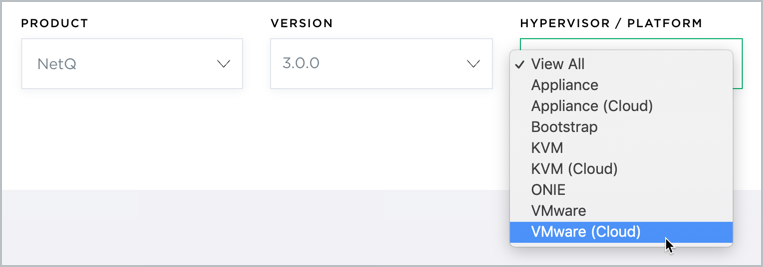
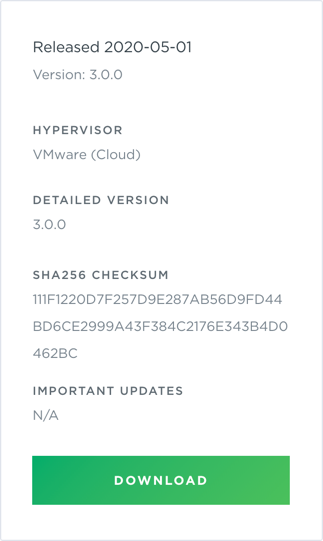
Select VMware (Cloud) from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0-opta.tgz installation package.
Setup and configure your VM.
VMware Example Configuration
This example shows the VM setup process using an OVA file with VMware ESXi.
Enter the address of the hardware in your browser.
Log in to VMware using credentials with root access.
Click Storage in the Navigator to verify you have an SSD installed.
Click Create/Register VM at the top of the right pane.
Select Deploy a virtual machine from an OVF or OVA file, and click Next.
Provide a name for the VM, for example NetQ.
Tip: Make note of the name used during install as this is needed in a later step.
Drag the NetQ image file you downloaded from the NVIDIA Application Hub to the installation wizard, then click Next.
Select the storage type and data store for the image, then click Next.
Accept the default deployment options or modify them according to your network needs. Click Next when you are finished.
Review the configuration summary. Click Back to change any of the settings, or click Finish to continue with the creation of the VM.
The progress of the request is shown in the Recent Tasks window at the bottom of the application. This may take some time. After the VM is deployed, the wizard displays the full hardware and configuration details.
Verify the platform is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
If you have changed the IP address or hostname of the NetQ Cloud VM after this step, you need to re-register this address with NetQ as follows:
Reset the VM.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Set Up Your VMware Virtual Machine for an On-premises Server Cluster
First configure the VM on the master node, and then configure the VM on each worker node.
Follow these steps to setup and configure your VM cluster for an on-premises deployment:
Verify that your master node meets the VM requirements.
Resource
Minimum Requirements
Processor
Eight (8) virtual CPUs
Memory
64 GB RAM
Local disk storage
256 GB SSD with minimum disk IOPS of 1000 for a standard 4kb block size (Note: This must be an SSD; use of other storage options can lead to system instability and are not supported.)
Network interface speed
1 Gb NIC
Hypervisor
VMware ESXi™ 6.5 or later (OVA image) for servers running Cumulus Linux, CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises servers:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
Additionally, for internal cluster communication, you must open these ports:
Port
Protocol
Component Access
8080
TCP
Admin API
5000
TCP
Docker registry
6443
TCP
Kubernetes API server
10250
TCP
kubelet health probe
2379
TCP
etcd
2380
TCP
etcd
7072
TCP
Kafka JMX monitoring
9092
TCP
Kafka client
7071
TCP
Cassandra JMX monitoring
7000
TCP
Cassandra cluster communication
9042
TCP
Cassandra client
7073
TCP
Zookeeper JMX monitoring
2888
TCP
Zookeeper cluster communication
3888
TCP
Zookeeper cluster communication
2181
TCP
Zookeeper client
36443
TCP
Kubernetes control plane
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
Select VMware from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0.tgz installation package.
Setup and configure your VM.
VMware Example Configuration
This example shows the VM setup process using an OVA file with VMware ESXi.
Enter the address of the hardware in your browser.
Log in to VMware using credentials with root access.
Click Storage in the Navigator to verify you have an SSD installed.
Click Create/Register VM at the top of the right pane.
Select Deploy a virtual machine from an OVF or OVA file, and click Next.
Provide a name for the VM, for example NetQ.
Tip: Make note of the name used during install as this is needed in a later step.
Drag the NetQ image file you downloaded from the NVIDIA Application Hub to the installation wizard, then click Next.
Select the storage type and data store for the image, then click Next.
Accept the default deployment options or modify them according to your network needs. Click Next when you are finished.
Review the configuration summary. Click Back to change any of the settings, or click Finish to continue with the creation of the VM.
The progress of the request is shown in the Recent Tasks window at the bottom of the application. This may take some time. After the VM is deployed, the wizard displays the full hardware and configuration details.
Verify the master node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Verify that your first worker node meets the VM requirements, as described in Step 1.
Confirm that the needed ports are open for communications, as described in Step 2.
Open your hypervisor and setup the VM in the same manner as for the master node.
Make a note of the private IP address you assign to the worker node. It is needed for later installation steps.
Verify the worker node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Set Up Your VMware Virtual Machine for a Cloud Server Cluster
First configure the VM on the master node, and then configure the VM on each worker node.
Follow these steps to setup and configure your VM on a cluster of servers in a cloud deployment:
Verify that your master node meets the VM requirements.
Resource
Minimum Requirements
Processor
Four (4) virtual CPUs
Memory
8 GB RAM
Local disk storage
64 GB
Network interface speed
1 Gb NIC
Hypervisor
VMware ESXi™ 6.5 or later (OVA image) for servers running Cumulus Linux, CentOS, Ubuntu, and RedHat operating systems
Confirm that the needed ports are open for communications.
You must open the following ports on your NetQ on-premises servers:
Port or Protocol Number
Protocol
Component Access
4
IP Protocol
Calico networking (IP-in-IP Protocol)
22
TCP
SSH
80
TCP
Nginx
179
TCP
Calico networking (BGP)
443
TCP
NetQ UI
2379
TCP
etcd datastore
4789
UDP
Calico networking (VxLAN)
5000
TCP
Docker registry
6443
TCP
kube-apiserver
30001
TCP
DPU communication
31980
TCP
NetQ Agent communication
31982
TCP
NetQ Agent SSL communication
32708
TCP
API Gateway
Additionally, for internal cluster communication, you must open these ports:
Port
Protocol
Component Access
8080
TCP
Admin API
5000
TCP
Docker registry
6443
TCP
Kubernetes API server
10250
TCP
kubelet health probe
2379
TCP
etcd
2380
TCP
etcd
7072
TCP
Kafka JMX monitoring
9092
TCP
Kafka client
7071
TCP
Cassandra JMX monitoring
7000
TCP
Cassandra cluster communication
9042
TCP
Cassandra client
7073
TCP
Zookeeper JMX monitoring
2888
TCP
Zookeeper cluster communication
3888
TCP
Zookeeper cluster communication
2181
TCP
Zookeeper client
36443
TCP
Kubernetes control plane
Download the NetQ Platform image.
On the MyMellanox Downloads page, select NetQ from the Software -> Cumulus Software list.
Click 3.0 from the Version list, and then select 3.0.0 from the submenu.
Select VMware (Cloud) from the HyperVisor/Platform list.
Scroll down to view the image, and click Download. This downloads the NetQ-3.0.0-opta.tgz installation package.
Setup and configure your VM.
VMware Example Configuration
This example shows the VM setup process using an OVA file with VMware ESXi.
Enter the address of the hardware in your browser.
Log in to VMware using credentials with root access.
Click Storage in the Navigator to verify you have an SSD installed.
Click Create/Register VM at the top of the right pane.
Select Deploy a virtual machine from an OVF or OVA file, and click Next.
Provide a name for the VM, for example NetQ.
Tip: Make note of the name used during install as this is needed in a later step.
Drag the NetQ image file you downloaded from the NVIDIA Application Hub to the installation wizard, then click Next.
Select the storage type and data store for the image, then click Next.
Accept the default deployment options or modify them according to your network needs. Click Next when you are finished.
Review the configuration summary. Click Back to change any of the settings, or click Finish to continue with the creation of the VM.
The progress of the request is shown in the Recent Tasks window at the bottom of the application. This may take some time. After the VM is deployed, the wizard displays the full hardware and configuration details.
Verify the master node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
If you have changed the IP address or hostname of the NetQ Cloud VM after this step, you need to re-register this address with NetQ as follows:
Reset the VM.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI. This example uses interface eth0. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Verify that your first worker node meets the VM requirements, as described in Step 1.
Confirm that the needed ports are open for communications, as described in Step 2.
Open your hypervisor and setup the VM in the same manner as for the master node.
Make a note of the private IP address you assign to the worker node. It is needed for later installation steps.
Verify the worker node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Change the hostname for the VM from the default value.
The default hostname for the NetQ Virtual Machines is ubuntu. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
This topic describes how to prepare your single, NetQ On-premises Appliance for installation of the NetQ Platform software.
Inside the box that was shipped to you, you’ll find:
Your Cumulus NetQ On-premises Appliance (a Supermicro 6019P-WTR server)
Hardware accessories, such as power cables and rack mounting gear (note that network cables and optics ship separately)
Information regarding your order
For more detail about hardware specifications (including LED layouts and FRUs like the power supply or fans, and accessories like included cables) or safety and environmental information, refer to the user manual and quick reference guide.
Install the Appliance
After you unbox the appliance:
Mount the appliance in the rack.
Connect it to power following the procedures described in your appliance's user manual.
Connect the Ethernet cable to the 1G management port (eno1).
Power on the appliance.
If your network runs DHCP, you can configure NetQ over the network. If DHCP is not enabled, then you configure the appliance using the console cable provided.
Configure the Password, Hostname and IP Address
Change the password and specify the hostname and IP address for the appliance before installing the NetQ software.
Log in to the appliance using the default login credentials:
Username: cumulus
Password: CumulusLinux!
Change the password using the passwd command:
cumulus@hostname:~$ passwd
Changing password for cumulus.
(current) UNIX password: CumulusLinux!
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
The default hostname for the NetQ On-premises Appliance is netq-appliance. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
The appliance contains two Ethernet ports. Port eno1, is dedicated for out-of-band management. This is where NetQ Agents should send the telemetry data collected from your monitored switches and hosts. By default, eno1 uses DHCPv4 to get its IP address. You can view the assigned IP address using the following command:
cumulus@hostname:~$ ip -4 -brief addr show eno1
eno1 UP 10.20.16.248/24
Alternately, you can configure the interface with a static IP address by editing the /etc/netplan/01-ethernet.yaml Ubuntu Netplan configuration file.
For example, to set your network interface eno1 to a static IP address of 192.168.1.222 with gateway 192.168.1.1 and DNS server as 8.8.8.8 and 8.8.4.4:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: no
addresses: [192.168.1.222/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Apply the settings.
cumulus@hostname:~$ sudo netplan apply
Verify NetQ Software and Appliance Readiness
Now that the appliance is up and running, verify that the software is available and the appliance is ready for installation.
Verify that the needed packages are present and of the correct release, version 3.0.0 and update 27 or later.
cumulus@hostname:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
Verify the installation images are present and of the correct release, version 3.0.0.
cumulus@hostname:~$ cd /mnt/installables/
cumulus@hostname:/mnt/installables$ ls
NetQ-3.0.0.tgz netq-bootstrap-3.0.0.tgz
Verify the appliance is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Run the Bootstrap CLI. Be sure to replace the eno1 interface used in this example with the interface or IP address on the appliance used to listen for NetQ Agents.
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset [purge-db|keep-db] and then try again.
If you have changed the IP address or hostname of the NetQ On-premises Appliance after this step, you need to re-register this address with NetQ as follows:
Reset the appliance, indicating whether you want to purge any NetQ DB data or keep it.
Re-run the Bootstrap CLI on the appliance. This example uses interface eno1. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
This topic describes how to prepare your single, NetQ Cloud Appliance for installation of the NetQ Collector software.
Inside the box that was shipped to you, you’ll find:
Your Cumulus NetQ Cloud Appliance (a Supermicro SuperServer E300-9D)
Hardware accessories, such as power cables and rack mounting gear (note that network cables and optics ship separately)
Information regarding your order
If you’re looking for hardware specifications (including LED layouts and FRUs like the power supply or fans and accessories like included cables) or safety and environmental information, check out the appliance’s user manual.
Install the Appliance
After you unbox the appliance:
Mount the appliance in the rack.
Connect it to power following the procedures described in your appliance's user manual.
Connect the Ethernet cable to the 1G management port (eno1).
Power on the appliance.
If your network runs DHCP, you can configure NetQ over the network. If DHCP is not enabled, then you configure the appliance using the console cable provided.
Configure the Password, Hostname and IP Address
Log in to the appliance using the default login credentials:
Username: cumulus
Password: CumulusLinux!
Change the password using the passwd command:
cumulus@hostname:~$ passwd
Changing password for cumulus.
(current) UNIX password: CumulusLinux!
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
The default hostname for the NetQ Cloud Appliance is netq-appliance. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
The appliance contains two Ethernet ports. Port eno1, is dedicated for out-of-band management. This is where NetQ Agents should send the telemetry data collected from your monitored switches and hosts. By default, eno1 uses DHCPv4 to get its IP address. You can view the assigned IP address using the following command:
cumulus@hostname:~$ ip -4 -brief addr show eno1
eno1 UP 10.20.16.248/24
Alternately, you can configure the interface with a static IP address by editing the /etc/netplan/01-ethernet.yaml Ubuntu Netplan configuration file.
For example, to set your network interface eno1 to a static IP address of 192.168.1.222 with gateway 192.168.1.1 and DNS server as 8.8.8.8 and 8.8.4.4:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: no
addresses: [192.168.1.222/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Apply the settings.
cumulus@hostname:~$ sudo netplan apply
Verify NetQ Software and Appliance Readiness
Now that the appliance is up and running, verify that the software is available and the appliance is ready for installation.
Verify that the needed packages are present and of the correct release, version 3.0.0 and update 27 or later.
cumulus@hostname:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
Verify the installation images are present and of the correct release, version 3.0.0.
cumulus@hostname:~$ cd /mnt/installables/
cumulus@hostname:/mnt/installables$ ls
NetQ-3.0.0-opta.tgz netq-bootstrap-3.0.0.tgz
Verify the appliance is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Run the Bootstrap CLI. Be sure to replace the eno1 interface used in this example with the interface or IP address on the appliance used to listen for NetQ Agents.
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
If you have changed the IP address or hostname of the NetQ Cloud Appliance after this step, you need to re-register this address with NetQ as follows:
Reset the appliance.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI on the appliance. This example uses interface eno1. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
This topic describes how to prepare your cluster of NetQ On-premises Appliances for installation of the NetQ Platform software.
Inside each box that was shipped to you, you’ll find:
A Cumulus NetQ On-premises Appliance (a Supermicro 6019P-WTR server)
Hardware accessories, such as power cables and rack mounting gear (note that network cables and optics ship separately)
Information regarding your order
For more detail about hardware specifications (including LED layouts and FRUs like the power supply or fans, and accessories like included cables) or safety and environmental information, refer to the user manual and quick reference guide.
Install Each Appliance
After you unbox the appliance:
Mount the appliance in the rack.
Connect it to power following the procedures described in your appliance's user manual.
Connect the Ethernet cable to the 1G management port (eno1).
Power on the appliance.
If your network runs DHCP, you can configure NetQ over the network. If DHCP is not enabled, then you configure the appliance using the console cable provided.
Configure the Password, Hostname and IP Address
Change the password and specify the hostname and IP address for each appliance before installing the NetQ software.
Log in to the appliance that will be your master node using the default login credentials:
Username: cumulus
Password: CumulusLinux!
Change the password using the passwd command:
cumulus@hostname:~$ passwd
Changing password for <user>.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
The default hostname for the NetQ On-premises Appliance is netq-appliance. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
The appliance contains two Ethernet ports. Port eno1, is dedicated for out-of-band management. This is where NetQ Agents should send the telemetry data collected from your monitored switches and hosts. By default, eno1 uses DHCPv4 to get its IP address. You can view the assigned IP address using the following command:
cumulus@hostname:~$ ip -4 -brief addr show eno1
eno1 UP 10.20.16.248/24
Alternately, you can configure the interface with a static IP address by editing the /etc/netplan/01-ethernet.yaml Ubuntu Netplan configuration file.
For example, to set your network interface eno1 to a static IP address of 192.168.1.222 with gateway 192.168.1.1 and DNS server as 8.8.8.8 and 8.8.4.4:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: no
addresses: [192.168.1.222/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Apply the settings.
cumulus@hostname:~$ sudo netplan apply
Repeat these steps for each of the worker node appliances.
Verify NetQ Software and Appliance Readiness
Now that the appliances are up and running, verify that the software is available and the appliance is ready for installation.
On the master node, verify that the needed packages are present and of the correct release, version 3.0.0 and update 27 or later.
cumulus@hostname:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
Verify the installation images are present and of the correct release, version 3.0.0.
cumulus@hostname:~$ cd /mnt/installables/
cumulus@hostname:/mnt/installables$ ls
NetQ-3.0.0.tgz netq-bootstrap-3.0.0.tgz
Verify the master node is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check
Run the Bootstrap CLI. Be sure to replace the eno1 interface used in this example with the interface or IP address on the appliance used to listen for NetQ Agents.
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset [purge-db|keep-db] and then try again.
If you have changed the IP address or hostname of the NetQ On-premises Appliance after this step, you need to re-register this address with NetQ as follows:
Reset the appliance, indicating whether you want to purge any NetQ DB data or keep it.
Re-run the Bootstrap CLI on the appliance. This example uses interface eno1. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
Allow about five to ten minutes for this to complete, and only then continue to the next step.
Repeat Steps 5-10 for each additional worker node (NetQ On-premises Appliance).
The final step is to install and activate the Cumulus NetQ software on each appliance in your cluster. You can do this using the Admin UI or the NetQ CLI.
Click the installation and activation method you want to use to complete installation:
This topic describes how to prepare your cluster of NetQ Cloud Appliances for installation of the NetQ Collector software.
Inside each box that was shipped to you, you’ll find:
A Cumulus NetQ Cloud Appliance (a Supermicro SuperServer E300-9D)
Hardware accessories, such as power cables and rack mounting gear (note that network cables and optics ship separately)
Information regarding your order
For more detail about hardware specifications (including LED layouts and FRUs like the power supply or fans and accessories like included cables) or safety and environmental information, refer to the user manual.
Install Each Appliance
After you unbox the appliance:
Mount the appliance in the rack.
Connect it to power following the procedures described in your appliance's user manual.
Connect the Ethernet cable to the 1G management port (eno1).
Power on the appliance.
If your network runs DHCP, you can configure NetQ over the network. If DHCP is not enabled, then you configure the appliance using the console cable provided.
Configure the Password, Hostname and IP Address
Change the password and specify the hostname and IP address for each appliance before installing the NetQ software.
Log in to the appliance that will be your master node using the default login credentials:
Username: cumulus
Password: CumulusLinux!
Change the password using the passwd command:
cumulus@hostname:~$ passwd
Changing password for <user>.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
The default hostname for the NetQ Cloud Appliance is netq-appliance. Change the hostname to fit your naming conventions while meeting Internet and Kubernetes naming standards.
Kubernetes requires that hostnames are composed of a sequence of labels concatenated with dots. For example, “en.wikipedia.org” is a hostname. Each label must be from 1 to 63 characters long. The entire hostname, including the delimiting dots, has a maximum of 253 ASCII characters.
The Internet standards (RFCs) for protocols specify that labels may contain only the ASCII letters a through z (in lower case), the digits 0 through 9, and the hyphen-minus character ('-').
The appliance contains two Ethernet ports. Port eno1, is dedicated for out-of-band management. This is where NetQ Agents should send the telemetry data collected from your monitored switches and hosts. By default, eno1 uses DHCPv4 to get its IP address. You can view the assigned IP address using the following command:
cumulus@hostname:~$ ip -4 -brief addr show eno1
eno1 UP 10.20.16.248/24
Alternately, you can configure the interface with a static IP address by editing the /etc/netplan/01-ethernet.yaml Ubuntu Netplan configuration file.
For example, to set your network interface eno1 to a static IP address of 192.168.1.222 with gateway 192.168.1.1 and DNS server as 8.8.8.8 and 8.8.4.4:
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: no
addresses: [192.168.1.222/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Apply the settings.
cumulus@hostname:~$ sudo netplan apply
Repeat these steps for each of the worker node appliances.
Verify NetQ Software and Appliance Readiness
Now that the appliances are up and running, verify that the software is available and each appliance is ready for installation.
On the master NetQ Cloud Appliance, verify that the needed packages are present and of the correct release, version 3.0.0 and update 27 or later.
cumulus@hostname:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
Verify the installation images are present and of the correct release, version 3.0.0.
cumulus@hostname:~$ cd /mnt/installables/
cumulus@hostname:/mnt/installables$ ls
NetQ-3.0.0-opta.tgz netq-bootstrap-3.0.0.tgz
Verify the master NetQ Cloud Appliance is ready for installation. Fix any errors indicated before installing the NetQ software.
cumulus@hostname:~$ sudo opta-check-cloud
Run the Bootstrap CLI. Be sure to replace the eno1 interface used in this example with the interface or IP address on the appliance used to listen for NetQ Agents.
Allow about five to ten minutes for this to complete, and only then continue to the next step.
If this step fails for any reason, you can run netq bootstrap reset and then try again.
If you have changed the IP address or hostname of the NetQ Cloud Appliance after this step, you need to re-register this address with NetQ as follows:
Reset the appliance.
cumulus@hostname:~$ netq bootstrap reset
Re-run the Bootstrap CLI on the appliance. This example uses interface eno1. Replace this with your updated IP address, hostname or interface using the interface or ip-addr option.
On one of your worker NetQ Cloud Appliances, verify that the needed packages are present and of the correct release, version 3.0.0 and update 27 or later.
cumulus@hostname:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
Prepare Your Existing NetQ Appliances for a NetQ 3.0 Deployment
This topic describes how to prepare a NetQ 2.4.x or earlier NetQ Appliance before installing NetQ 3.0.x. The steps are the same for both the on-premises and cloud appliances. The only difference is the software you download for each platform. On completion of the steps included here, you will be ready to perform a fresh installation of NetQ 3.0.x.
The preparation workflow is summarized in this figure:
To prepare your appliance:
Verify that your appliance is a supported hardware model.
For on-premises solutions using the NetQ On-premises Appliance, optionally back up your NetQ data.
Run the backup script to create a backup file in /opt/<backup-directory>.
Be sure to replace the backup-directory option with the name of the directory you want to use for the backup file. This location must be somewhere that is off of the appliance to avoid it being overwritten during these preparation steps.
Ubuntu OS should be installed on the SSD disk. Select Micron SSD with ~900 GB at step#9 in the aforementioned instructions.
Set the default username to cumulus and password to CumulusLinux!.
When prompted, select Install SSH server.
Configure networking.
Ubuntu uses Netplan for network configuration. You can give your appliance an IP address using DHCP or a static address.
Create and/or edit the /etc/netplan/01-ethernet.yaml Netplan configuration file.
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: yes
Apply the settings.
$ sudo netplan apply
Create and/or edit the /etc/netplan/01-ethernet.yaml Netplan configuration file.
In this example the interface, eno1, is given a static IP address of 192.168.1.222 with a gateway at 192.168.1.1 and DNS server at 8.8.8.8 and 8.8.4.4.
# This file describes the network interfaces available on your system
# For more information, see netplan(5).
network:
version: 2
renderer: networkd
ethernets:
eno1:
dhcp4: no
addresses: [192.168.1.222/24]
gateway4: 192.168.1.1
nameservers:
addresses: [8.8.8.8,8.8.4.4]
Create the file /etc/apt/sources.list.d/cumulus-host-ubuntu-bionic.list and add
the following line:
root@ubuntu:~# vi /etc/apt/sources.list.d/cumulus-apps-deb-bionic.list
...
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb bionic netq-latest
...
The use of netq-latest in this example means that a get to the repository always retrieves the latest version of NetQ, even in the case where a major version update has been made. If you want to keep the repository on a specific version - such as netq-2.2 - use that instead.
Select 3.0 from the Version list, and then select 3.0.0 from the submenu.
Select Bootstrap from the Hypervisor/Platform list.
Note that the bootstrap file is the same for both appliances.
Scroll down and click Download.
Select Appliance for the NetQ On-premises Appliance or Appliance (Cloud) for the NetQ Cloud Appliance from the Hypervisor/Platform list.
Make sure you select the right install choice based on whether you are preparing the on-premises or cloud version of the appliance.
Scroll down and click Download.
Copy these two files, netq-bootstrap-3.0.0.tgz and either NetQ-3.0.0.tgz (on-premises) or NetQ-3.0.0-opta.tgz (cloud), to the /mnt/installables/ directory on the appliance.
Verify that the needed files are present and of the correct release. This example shows on-premises files. The only difference for cloud files is that it should list NetQ-3.0.0-opta.tgz instead of NetQ-3.0.0.tgz.
cumulus@<hostname>:~$ dpkg -l | grep netq
ii netq-agent 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Telemetry Agent for Ubuntu
ii netq-apps 3.0.0-ub18.04u27~1588242914.9fb5b87_amd64 Cumulus NetQ Fabric Validation Application for Ubuntu
cumulus@<hostname>:~$ cd /mnt/installables/
cumulus@<hostname>:/mnt/installables$ ls
NetQ-3.0.0.tgz netq-bootstrap-3.0.0.tgz
Run the bootstrap CLI on your appliance. Be sure to replace the eth0 interface used in this example with the interface or IP address on the appliance used to listen for NetQ Agents.
If you are creating a server cluster, you need to prepare each of those appliances as well. Repeat these steps if you are using a previously deployed appliance or refer to Install NetQ System Platform for a new appliance.
You can now install the NetQ software using the Admin UI.
This is the final set of steps for installing NetQ. If you have not already performed the installation preparation steps, go to Install NetQ System Platform before continuing here.
To install NetQ:
Log in to your NetQ On-premises Appliance, NetQ Cloud Appliance, the master node of your cluster, or VM.
In your browser address field, enter https://<hostname-or-ipaddr>:8443.
This opens the Admin UI.
Step through the UI.
Having made your installation choices during the preparation steps, you can quickly select the correct path through the UI.
Select your deployment type.
Choose which type of deployment model you want to use. Both options provide secure access to data and features useful for monitoring and troubleshooting your network.
Select your install method.
Choose between restoring data from a previous version of NetQ or performing a fresh installation.
Fresh Install: Continue with Step c.
Maintain Existing Data (on-premises only): If you have created a backup of your NetQ data, choose this option.
If you are moving from a standalone to a server cluster arrangement, you can only restore your data one time. After the data has been converted to the cluster schema, it cannot be returned to the single server format.
Select your server arrangement.
Select whether you want to deploy your infrastructure as a single stand-alone server or as a cluster of servers. One master and two worker nodes are supported for the cluster deployment.
Select arrangement
If you select a server cluster, use the private IP addresses that you used when setting up the worker nodes to add those nodes.
Add worker nodes to a server cluster
Install NetQ software.
You install the NetQ software using the installation files (NetQ-3.0.0.tgz for on-premises deployments or NetQ-3.0.0-opta.tgz for cloud deployments) that you downloaded and stored previously.
Enter the appropriate filename in the field provided.
Activate NetQ.
This final step activates the software and enables you to view the health of your NetQ system. For cloud deployments, you must enter your configuration key.
On-premises activation
Cloud activation
View the system health.
When the installation and activation is complete, the NetQ System Health dashboard is visible for tracking the status of key components in the system. Single server deployments display two cards, one for the server, and one for Kubernetes pods. Server cluster deployments display additional cards, including one each for the Cassandra database, Kafka, and Zookeeper services.
On-premises deployment
Install NetQ Using the CLI
You can now install the NetQ software using the NetQ CLI.
This is the final set of steps for installing NetQ. If you have not already performed the installation preparation steps, go to Install NetQ System Platform before continuing here.
To install NetQ:
Log in to your NetQ platform server, NetQ Appliance, NetQ Cloud Appliance or the master node of your cluster.
Install the software.
Run the following command on your NetQ platform server or NetQ Appliance:
cumulus@hostname:~$ netq install standalone full interface eth0 bundle /mnt/installables/NetQ-3.0.0.tgz
You can specify the IP address instead of the interface name here: use ip-addr <IP address> in place of interface <ifname> above.
Run the netq show opta-health command to verify all applications are operating properly. Please allow 10-15 minutes for all applications to come up and report their status.
If any of the applications or services display Status as DOWN after 30 minutes, open a support ticket and attach the output of the opta-support command.
Run the following commands on your master node, using the IP addresses of your worker nodes:
You can specify the IP address instead of the interface name here: use ip-addr <IP address> in place of interface eth0 above.
Run the netq show opta-health command to verify all applications are operating properly. Please allow 10-15 minutes for all applications to come up and report their status.
If any of the applications or services display Status as DOWN after 30 minutes, open a support ticket and attach the output of the opta-support command.
Run the following command on your NetQ Cloud Appliance with the config-key sent by Cumulus Networks in an email titled “A new site has been added to your Cumulus NetQ account.”
You can specify the IP address instead of the interface name here: use ip-addr <IP address> in place of interface eth0 above.
Run the netq show opta-health command to verify all applications are operating properly.
cumulus@hostname:~$ netq show opta-health
OPTA is healthy
Run the following commands on your master NetQ Cloud Appliance with the config-key sent by Cumulus Networks in an email titled “A new site has been added to your Cumulus NetQ account.”
After installing your Cumulus NetQ 3.0.0 software, you should install the corresponding NetQ 3.0.0 Agent on each switch and server you want to monitor. There are important features and fixes included in the NetQ Agent with each release.
Use the instructions in the following sections based on the OS installed on the switch or server.
Install and Configure the NetQ Agent on Cumulus Linux Switches
After installing your Cumulus NetQ software, you should install the NetQ 3.0.0 Agents on each switch you want to monitor. NetQ Agents can be installed on switches running:
Cumulus Linux version 3.3.2-3.7.x
Cumulus Linux version 4.0.0 and later
Prepare for NetQ Agent Installation on a Cumulus Linux Switch
For servers running Cumulus Linux, you need to:
Install and configure NTP, if needed
Obtain NetQ software packages
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the software package in the Cumulus Networks repository.
Verify NTP is Installed and Configured
Verify that NTP is running on the switch. The switch must be in time synchronization with the NetQ Platform or NetQ Appliance to enable useful statistical analysis.
cumulus@switch:~$ sudo systemctl status ntp
[sudo] password for cumulus:
● ntp.service - LSB: Start NTP daemon
Loaded: loaded (/etc/init.d/ntp; bad; vendor preset: enabled)
Active: active (running) since Fri 2018-06-01 13:49:11 EDT; 2 weeks 6 days ago
Docs: man:systemd-sysv-generator(8)
CGroup: /system.slice/ntp.service
└─2873 /usr/sbin/ntpd -p /var/run/ntpd.pid -g -c /var/lib/ntp/ntp.conf.dhcp -u 109:114
If NTP is not installed, install and configure it before continuing.
If NTP is not running:
verify the IP address or hostname of the NTP server in the /etc/ntp.conf file, and then
reenable and start the NTP service using the systemctl [enable|start] ntp commands.
If you are running NTP in your out-of-band management network with VRF, specify the VRF (ntp@<vrf-name> versus just ntp) in the above commands.
Obtain NetQ Agent Software Package
To install the NetQ Agent you need to install netq-agent on each switch or host. This is available from the Cumulus Networks repository.
To obtain the NetQ Agent package:
Edit the /etc/apt/sources.list file to add the repository for Cumulus NetQ.
Note that NetQ has a separate repository from Cumulus Linux.
cumulus@switch:~$ sudo nano /etc/apt/sources.list
...
deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-3 netq-3.0
...
The repository deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-3 netq-latest can be used if you want to always retrieve the latest posted version of NetQ.
Add the repository:
cumulus@switch:~$ sudo nano /etc/apt/sources.list
...
deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-4 netq-3.0
...
The repository deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-4 netq-latest can be used if you want to always retrieve the latest posted version of NetQ.
Add the apps3.cumulusnetworks.com authentication key to Cumulus Linux:
Continue with NetQ Agent configuration in the next section.
Configure the NetQ Agent on a Cumulus Linux Switch
After the NetQ Agent and CLI have been installed on the servers you want to monitor, the NetQ Agents must be configured to obtain useful and relevant data.
The NetQ Agent is aware of and communicates through the designated VRF. If you do not specify one, the default VRF (named default) is used. If you later change the VRF configured for the NetQ Agent (using a lifecycle management configuration profile, for example), you might cause the NetQ Agent to lose communication.
Two methods are available for configuring a NetQ Agent:
Edit the configuration file on the switch, or
Use the NetQ CLI.
Configure NetQ Agents Using a Configuration File
You can configure the NetQ Agent in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
cumulus@switch:~$ sudo nano /etc/netq/netq.yml
Locate the netq-agent section, or add it.
Set the parameters for the agent as follows:
port: 31980 (default configuration)
server: IP address of the NetQ Appliance or VM where the agent should send its collected data
Configure Advanced NetQ Agent Settings on a Cumulus Linux Switch
A couple of additional options are available for configuring the NetQ Agent. If you are using VRF, you can configure the agent to communicate over a specific VRF. You can also configure the agent to use a particular port.
Configure the Agent to Use a VRF
While optional, Cumulus strongly recommends that you configure NetQ Agents to communicate with the NetQ Appliance or VM only via a VRF, including a management VRF. To do so, you need to specify the VRF name when configuring the NetQ Agent. For example, if the management VRF is configured and you want the agent to communicate with the NetQ Appliance or VM over it, configure the agent like this:
Configure the Agent to Communicate over a Specific Port
By default, NetQ uses port 31980 for communication between the NetQ Appliance or VM and NetQ Agents. If you want the NetQ Agent to communicate with the NetQ Appliance or VM via a different port, you need to specify the port number when configuring the NetQ Agent, like this:
cumulus@leaf01:~$ sudo netq config add agent server 192.168.1.254 port 7379
cumulus@leaf01:~$ sudo netq config restart agent
Install and Configure the NetQ Agent on Ubuntu Servers
After installing your Cumulus NetQ software, you should install the NetQ 3.0.0 Agent on each server you want to monitor. NetQ Agents can be installed on servers running:
Ubuntu 16.04
Ubuntu 18.04 (NetQ 2.2.2 and later)
Prepare for NetQ Agent Installation on an Ubuntu Server
For servers running Ubuntu OS, you need to:
Verify the minimum service packages versions are installed
Verify the server is running lldpd
Install and configure network time server, if needed
Obtain NetQ software packages
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the agent package on the Cumulus Networks repository.
Verify Service Package Versions
The following packages, while not required for installation of the NetQ Agent, must be installed and running for proper operation of the NetQ Agent on an Ubuntu server:
iproute 1:4.3.0-1ubuntu3.16.04.1 all
iproute2 4.3.0-1ubuntu3 amd64
lldpd 0.7.19-1 amd64
ntp 1:4.2.8p4+dfsg-3ubuntu5.6 amd64
Verify the Server is Running lldpd
Make sure you are running lldpd, not lldpad. Ubuntu does not include lldpd by default, which is required for the installation.
To install this package, run the following commands:
If NTP is not already installed and configured, follow these steps:
Install NTP on the server, if not already installed. Servers must be in time synchronization with the NetQ Platform or NetQ Appliance to enable useful statistical analysis.
root@ubuntu:~# sudo apt-get install ntp
Configure the network time server.
Open the /etc/ntp.conf file in your text editor of choice.
Under the Server section, specify the NTP server IP address or hostname.
Create the file /etc/apt/sources.list.d/cumulus-host-ubuntu-xenial.list and add the following line:
root@ubuntu:~# vi /etc/apt/sources.list.d/cumulus-apps-deb-xenial.list
...
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb xenial netq-latest
...
Create the file /etc/apt/sources.list.d/cumulus-host-ubuntu-bionic.list and add the following line:
root@ubuntu:~# vi /etc/apt/sources.list.d/cumulus-apps-deb-bionic.list
...
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb bionic netq-latest
...
The use of netq-latest in these examples means that a get to the repository always retrieves the latest version of NetQ, even in the case where a major version update has been made. If you want to keep the repository on a specific version - such as netq-2.4 - use that instead.
Install NetQ Agent on an Ubuntu Server
After completing the preparation steps, you can successfully install the agent software onto your server.
Continue with NetQ Agent Configuration in the next section.
Configure the NetQ Agent on an Ubuntu Server
After the NetQ Agent and CLI have been installed on the servers you want to monitor, the NetQ Agents must be configured to obtain useful and relevant data.
The NetQ Agent is aware of and communicates through the designated VRF. If you do not specify one, the default VRF (named default) is used. If you later change the VRF configured for the NetQ Agent (using a lifecycle management configuration profile, for example), you might cause the NetQ Agent to lose communication.
Two methods are available for configuring a NetQ Agent:
Edit the configuration file on the device, or
Use the NetQ CLI.
Configure the NetQ Agents Using a Configuration File
You can configure the NetQ Agent in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
root@ubuntu:~# sudo nano /etc/netq/netq.yml
Locate the netq-agent section, or add it.
Set the parameters for the agent as follows:
port: 31980 (default) or one that you specify
server: IP address of the NetQ server or appliance where the agent should send its collected data
If the CLI is configured, you can use it to configure the NetQ Agent to send telemetry data to the NetQ Server or Appliance. If it is not configured, refer to Configure the NetQ CLI on an Ubuntu Server and then return here.
A couple of additional options are available for configuring the NetQ Agent. If you are using VRF, you can configure the agent to communicate over a specific VRF. You can also configure the agent to use a particular port.
Configure the NetQ Agent to Use a VRF
While optional, Cumulus strongly recommends that you configure NetQ Agents to communicate with the NetQ Platform only via a VRF, including a management VRF. To do so, you need to specify the VRF name when configuring the NetQ Agent. For example, if the management VRF is configured and you want the agent to communicate with the NetQ Platform over it, configure the agent like this:
Configure the NetQ Agent to Communicate over a Specific Port
By default, NetQ uses port 31980 for communication between the NetQ Platform and NetQ Agents. If you want the NetQ Agent to communicate with the NetQ Platform via a different port, you need to specify the port number when configuring the NetQ Agent like this:
root@ubuntu:~# sudo netq config add agent server 192.168.1.254 port 7379
root@ubuntu:~# sudo netq config restart agent
Install and Configure the NetQ Agent on RHEL and CentOS Servers
After installing your Cumulus NetQ software, you should install the NetQ 3.0.0 Agents on each server you want to monitor. NetQ Agents can be installed on servers running:
Red Hat RHEL 7.1
CentOS 7
Prepare for NetQ Agent Installation on a RHEL or CentOS Server
For servers running RHEL or CentOS, you need to:
Verify the minimum package versions are installed
Verify the server is running lldpd
Install and configure NTP, if needed
Obtain NetQ software packages
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the software package in the Cumulus Networks repository.
Verify Service Package Versions
The following packages, while not required for installation of the NetQ Agent, must be installed and running for proper operation of the NetQ Agent on a Red Hat or CentOS server:
iproute-3.10.0-54.el7_2.1.x86_64
lldpd-0.9.7-5.el7.x86_64
ntp-4.2.6p5-25.el7.centos.2.x86_64
ntpdate-4.2.6p5-25.el7.centos.2.x86_64
Verify the Server is Running lldpd and wget
Make sure you are running lldpd, not lldpad. CentOS does not include lldpd by default, nor does it include wget, which is required for the installation.
To install this package, run the following commands:
Restart rsyslog so log files are sent to the correct destination.
root@rhel7:~# sudo systemctl restart rsyslog
Continue with NetQ Agent Configuration in the next section.
Configure the NetQ Agent on a RHEL or CentOS Server
After the NetQ Agent and CLI have been installed on the servers you want to monitor, the NetQ Agents must be configured to obtain useful and relevant data.
The NetQ Agent is aware of and communicates through the designated VRF. If you do not specify one, the default VRF (named default) is used. If you later change the VRF configured for the NetQ Agent (using a lifecycle management configuration profile, for example), you might cause the NetQ Agent to lose communication.
Two methods are available for configuring a NetQ Agent:
Edit the configuration file on the device, or
Use the NetQ CLI.
Configure the NetQ Agents Using a Configuration File
You can configure the NetQ Agent in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
root@rhel7:~# sudo nano /etc/netq/netq.yml
Locate the netq-agent section, or add it.
Set the parameters for the agent as follows:
port: 31980 (default) or one that you specify
server: IP address of the NetQ server or appliance where the agent should send its collected data
If the CLI is configured, you can use it to configure the NetQ Agent to send telemetry data to the NetQ Server or Appliance. If it is not configured, refer to Configure the NetQ CLI on a RHEL or CentOS Server and then return here.
A couple of additional options are available for configuring the NetQ Agent. If you are using VRF, you can configure the agent to communicate over a specific VRF. You can also configure the agent to use a particular port.
Configure the NetQ Agent to Use a VRF
While optional, Cumulus strongly recommends that you configure NetQ Agents to communicate with the NetQ Platform only via a VRF, including a management VRF. To do so, you need to specify the VRF name when configuring the NetQ Agent. For example, if the management VRF is configured and you want the agent to communicate with the NetQ Platform over it, configure the agent like this:
Configure the NetQ Agent to Communicate over a Specific Port
By default, NetQ uses port 31980 for communication between the NetQ Platform and NetQ Agents. If you want the NetQ Agent to communicate with the NetQ Platform via a different port, you need to specify the port number when configuring the NetQ Agent like this:
root@rhel7:~# sudo netq config add agent server 192.168.1.254 port 7379
root@rhel7:~# sudo netq config restart agent
Install NetQ CLI
When installing NetQ 3.0.x, it is not required that you install the NetQ CLI on your NetQ Appliances or VMs, or monitored switches and hosts, but it provides new features, important bug fixes, and the ability to manage your network from multiple points in the network.
Use the instructions in the following sections based on the OS installed on the switch or server.
Install and Configure the NetQ CLI on Cumulus Linux Switches
After installing your Cumulus NetQ software and the NetQ 3.0.0 Agent on each switch you want to monitor, you can also install the NetQ CLI on switches running:
Cumulus Linux version 3.3.2-3.7.x
Cumulus Linux version 4.0.0 and later
Install the NetQ CLI on a Cumulus Linux Switch
A simple process installs the NetQ CLI on a Cumulus Linux switch.
To install the NetQ CLI you need to install netq-apps on each switch. This is available from the Cumulus Networks repository.
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the software package in the Cumulus Networks repository.
To obtain the NetQ Agent package:
Edit the /etc/apt/sources.list file to add the repository for Cumulus NetQ.
Note that NetQ has a separate repository from Cumulus Linux.
cumulus@switch:~$ sudo nano /etc/apt/sources.list
...
deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-3 netq-3.0
...
The repository deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-4 netq-latest can be used if you want to always retrieve the latest posted version of NetQ.
cumulus@switch:~$ sudo nano /etc/apt/sources.list
...
deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-4 netq-3.0
...
The repository deb http://apps3.cumulusnetworks.com/repos/deb CumulusLinux-4 netq-latest can be used if you want to always retrieve the latest posted version of NetQ.
Update the local apt repository and install the software on the switch.
The steps to configure the CLI are different depending on whether the NetQ software has been installed for an on-premises or cloud deployment. Follow the instructions for your deployment type.
Use the following command to configure the CLI:
netq config add cli server <text-gateway-dest> [vrf <text-vrf-name>] [port <text-gateway-port>]
Restart the CLI afterward to activate the configuration.
This example uses an IP address of 192.168.1.0 and the default port and VRF.
If you have a server cluster deployed, use the IP address of the master server.
To access and configure the CLI on your NetQ Cloud Appliance or VM, you must have your username and password to access the NetQ UI to generate AuthKeys. These keys provide authorized access (access key) and user authentication (secret key). Your credentials and NetQ Cloud addresses were provided by Cumulus Networks via an email titled Welcome to Cumulus NetQ!
To generate AuthKeys:
In your Internet browser, enter netq.cumulusnetworks.com into the address field to open the NetQ UI login page.
Enter your username and password.
Click (Main Menu), select Management in the Admin column.
Click Manage on the User Accounts card.
Select your user and click above the table.
Copy these keys to a safe place.
The secret key is only shown once. If you do not copy these, you will need to regenerate them and reconfigure CLI access.
You can also save these keys to a YAML file for easy reference, and to avoid having to type or copy the key values. You can:
store the file wherever you like, for example in /home/cumulus/ or /etc/netq
name the file whatever you like, for example credentials.yml, creds.yml, or keys.yml
Restart the CLI afterward to activate the configuration.
This example uses the individual access key, a premises of datacenterwest, and the default Cloud address, port and VRF. Be sure to replace the key values with your generated keys if you are using this example on your server.
cumulus@switch:~$ sudo netq config add cli server api.netq.cumulusnetworks.com access-key 123452d9bc2850a1726f55534279dd3c8b3ec55e8b25144d4739dfddabe8149e secret-key /vAGywae2E4xVZg8F+HtS6h6yHliZbBP6HXU3J98765= premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
cumulus@switch:~$ sudo netq config restart cli
Restarting NetQ CLI... Success!
This example uses an optional keys file. Be sure to replace the keys filename and path with the full path and name of your keys file, and the datacenterwest premises name with your premises name if you are using this example on your server.
cumulus@switch:~$ sudo netq config add cli server api.netq.cumulusnetworks.com cli-keys-file /home/netq/nq-cld-creds.yml premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
cumulus@switch:~$ netq config restart cli
Restarting NetQ CLI... Success!
If you have multiple premises and want to query data from a different premises than you originally configured, rerun the netq config add cli server command with the desired premises name. You can only view the data for one premises at a time with the CLI.
Configure NetQ CLI Using a Configuration File
You can configure the NetQ CLI in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
cumulus@switch:~$ sudo nano /etc/netq/netq.yml
Locate the netq-cli section, or add it.
Set the parameters for the CLI.
Specify the following parameters:
netq-user: User who can access the CLI
server: IP address of the NetQ server or NetQ Appliance
port (default): 32708
Your YAML configuration file should be similar to this:
Install and Configure the NetQ CLI on Ubuntu Servers
After installing your Cumulus NetQ software, you should install the NetQ 3.0.0 Agents on each switch you want to monitor. NetQ Agents can be installed on servers running:
Ubuntu 16.04
Ubuntu 18.04 (NetQ 2.2.2 and later)
Prepare for NetQ CLI Installation on an Ubuntu Server
For servers running Ubuntu OS, you need to:
Verify the minimum service packages versions are installed
Verify the server is running lldpd
Install and configure network time server, if needed
Obtain NetQ software packages
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the software package in the Cumulus Networks repository.
Verify Service Package Versions
Before you install the NetQ Agent on an Ubuntu server, make sure the
following packages are installed and running these minimum versions:
iproute 1:4.3.0-1ubuntu3.16.04.1 all
iproute2 4.3.0-1ubuntu3 amd64
lldpd 0.7.19-1 amd64
ntp 1:4.2.8p4+dfsg-3ubuntu5.6 amd64
Verify the Server is Running lldpd
Make sure you are running lldpd, not lldpad. Ubuntu does not include lldpd by default, which is required for the installation.
To install this package, run the following commands:
If NTP is not already installed and configured, follow these steps:
Install NTP on the server, if not already installed. Servers must be in time synchronization with the NetQ Platform or NetQ Appliance to enable useful statistical analysis.
root@ubuntu:~# sudo apt-get install ntp
Configure the network time server.
Open the /etc/ntp.conf file in your text editor of choice.
Under the Server section, specify the NTP server IP address or hostname.
Create the file /etc/apt/sources.list.d/cumulus-host-ubuntu-xenial.list and add the following line:
root@ubuntu:~# vi /etc/apt/sources.list.d/cumulus-apps-deb-xenial.list
...
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb xenial netq-latest
...
Create the file /etc/apt/sources.list.d/cumulus-host-ubuntu-bionic.list and add the following line:
root@ubuntu:~# vi /etc/apt/sources.list.d/cumulus-apps-deb-bionic.list
...
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb bionic netq-latest
...
The use of netq-latest in these examples means that a get to the repository always retrieves the latest version of NetQ, even in the case where a major version update has been made. If you want to keep the repository on a specific version - such as netq-2.4 - use that instead.
Install NetQ CLI on an Ubuntu Server
A simple process installs the NetQ CLI on an Ubuntu server.
The steps to configure the CLI are different depending on whether the NetQ software has been installed for an on-premises or cloud deployment. Follow the instruction for your deployment type.
Use the following command to configure the CLI:
netq config add cli server <text-gateway-dest> [vrf <text-vrf-name>] [port <text-gateway-port>]
Restart the CLI afterward to activate the configuration.
This example uses an IP address of 192.168.1.0 and the default port and VRF.
If you have a server cluster deployed, use the IP address of the master server.
To access and configure the CLI on your NetQ Platform or NetQ Cloud Appliance, you must have your username and password to access the NetQ UI to generate AuthKeys. These keys provide authorized access (access key) and user authentication (secret key). Your credentials and NetQ Cloud addresses were provided by Cumulus Networks via an email titled Welcome to Cumulus NetQ!
To generate AuthKeys:
In your Internet browser, enter netq.cumulusnetworks.com into the address field to open the NetQ UI login page.
Enter your username and password.
From the Main Menu, select Management in the Admin column.
Click Manage on the User Accounts card.
Select your user and click above the table.
Copy these keys to a safe place.
The secret key is only shown once. If you do not copy these, you will need to regenerate them and reconfigure CLI access.
You can also save these keys to a YAML file for easy reference, and to avoid having to type or copy the key values. You can:
store the file wherever you like, for example in /home/cumulus/ or /etc/netq
name the file whatever you like, for example credentials.yml, creds.yml, or keys.yml
Restart the CLI afterward to activate the configuration.
This example uses the individual access key, a premises of datacenterwest, and the default Cloud address, port and VRF. Be sure to replace the key values with your generated keys if you are using this example on your server.
root@ubuntu:~# sudo netq config add cli server api.netq.cumulusnetworks.com access-key 123452d9bc2850a1726f55534279dd3c8b3ec55e8b25144d4739dfddabe8149e secret-key /vAGywae2E4xVZg8F+HtS6h6yHliZbBP6HXU3J98765= premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
root@ubuntu:~# sudo netq config restart cli
Restarting NetQ CLI... Success!
This example uses an optional keys file. Be sure to replace the keys filename and path with the full path and name of your keys file, and the datacenterwest premises name with your premises name if you are using this example on your server.
root@ubuntu:~# sudo netq config add cli server api.netq.cumulusnetworks.com cli-keys-file /home/netq/nq-cld-creds.yml premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
root@ubuntu:~# sudo netq config restart cli
Restarting NetQ CLI... Success!
Rerun this command if you have multiple premises and want to query a different premises.
Configure NetQ CLI Using Configuration File
You can configure the NetQ CLI in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
root@ubuntu:~# sudo nano /etc/netq/netq.yml
Locate the netq-cli section, or add it.
Set the parameters for the CLI.
Specify the following parameters:
netq-user: User who can access the CLI
server: IP address of the NetQ server or NetQ Appliance
port (default): 32708
Your YAML configuration file should be similar to this:
Install and Configure the NetQ CLI on RHEL and CentOS Servers
After installing your Cumulus NetQ software and the NetQ 3.0.0 Agents on each switch you want to monitor, you can also install the NetQ CLI on servers running:
Red Hat RHEL 7.1
CentOS 7
Prepare for NetQ CLI Installation on a RHEL or CentOS Server
For servers running RHEL or CentOS, you need to:
Verify the minimum package versions are installed
Verify the server is running lldpd
Install and configure NTP, if needed
Obtain NetQ software packages
If your network uses a proxy server for external connections, you should first configure a global proxy so apt-get can access the software package in the Cumulus Networks repository.
Verify Service Package Versions
Before you install the NetQ CLI on a Red Hat or CentOS server, make sure the following packages are installed and running these minimum versions:
iproute-3.10.0-54.el7_2.1.x86_64
lldpd-0.9.7-5.el7.x86_64
ntp-4.2.6p5-25.el7.centos.2.x86_64
ntpdate-4.2.6p5-25.el7.centos.2.x86_64
Verify the Server is Running lldpd and wget
Make sure you are running lldpd, not lldpad. CentOS does not include lldpd by default, nor does it include wget, which is required for the installation.
To install this package, run the following commands:
The steps to configure the CLI are different depending on whether the NetQ software has been installed for an on-premises or cloud deployment. Follow the instructions for your deployment type.
Use the following command to configure the CLI:
netq config add cli server <text-gateway-dest> [vrf <text-vrf-name>] [port <text-gateway-port>]
Restart the CLI afterward to activate the configuration.
This example uses an IP address of 192.168.1.0 and the default port and VRF.
If you have a server cluster deployed, use the IP address of the master server.
To access and configure the CLI on your NetQ Platform or NetQ Cloud Appliance, you must have your username and password to access the NetQ UI to generate AuthKeys. These keys provide authorized access (access key) and user authentication (secret key). Your credentials and NetQ Cloud addresses were provided by Cumulus Networks via an email titled Welcome to Cumulus NetQ!
To generate AuthKeys:
In your Internet browser, enter netq.cumulusnetworks.com into the address field to open the NetQ UI login page.
Enter your username and password.
From the Main Menu, select Management in the Admin column.
Click Manage on the User Accounts card.
Select your user and click above the table.
Copy these keys to a safe place.
The secret key is only shown once. If you do not copy these, you will need to regenerate them and reconfigure CLI access.
You can also save these keys to a YAML file for easy reference, and to avoid having to type or copy the key values. You can:
store the file wherever you like, for example in /home/cumulus/ or /etc/netq
name the file whatever you like, for example credentials.yml, creds.yml, or keys.yml
Restart the CLI afterward to activate the configuration.
This example uses the individual access key, a premises of datacenterwest, and the default Cloud address, port and VRF. Be sure to replace the key values with your generated keys if you are using this example on your server.
root@rhel7:~# sudo netq config add cli server api.netq.cumulusnetworks.com access-key 123452d9bc2850a1726f55534279dd3c8b3ec55e8b25144d4739dfddabe8149e secret-key /vAGywae2E4xVZg8F+HtS6h6yHliZbBP6HXU3J98765= premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
root@rhel7:~# sudo netq config restart cli
Restarting NetQ CLI... Success!
This example uses an optional keys file. Be sure to replace the keys filename and path with the full path and name of your keys file, and the datacenterwest premises name with your premises name if you are using this example on your server.
root@rhel7:~# sudo netq config add cli server api.netq.cumulusnetworks.com cli-keys-file /home/netq/nq-cld-creds.yml premises datacenterwest
Successfully logged into NetQ cloud at api.netq.cumulusnetworks.com:443
Updated cli server api.netq.cumulusnetworks.com vrf default port 443. Please restart netqd (netq config restart cli)
root@rhel7:~# sudo netq config restart cli
Restarting NetQ CLI... Success!
Rerun this command if you have multiple premises and want to query a different premises.
Configure NetQ CLI Using Configuration File
You can configure the NetQ CLI in the netq.yml configuration file contained in the /etc/netq/ directory.
Open the netq.yml file using your text editor of choice. For example:
root@rhel7:~# sudo nano /etc/netq/netq.yml
Locate the netq-cli section, or add it.
Set the parameters for the CLI.
Specify the following parameters:
netq-user: User who can access the CLI
server: IP address of the NetQ server or NetQ Appliance
port (default): 32708
Your YAML configuration file should be similar to this:
If you need to remove the NetQ agent and/or the NetQ CLI from a Cumulus Linux switch or Linux host, follow the steps below.
Remove the Agent and CLI from a Cumulus Linux Switch or Ubuntu Host
Use the apt-get purge command to remove the NetQ agent or CLI package from a Cumulus Linux switch or an Ubuntu host.
cumulus@switch:~$ sudo apt-get update
cumulus@switch:~$ sudo apt-get purge netq-agent netq-apps
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be REMOVED:
netq-agent* netq-apps*
0 upgraded, 0 newly installed, 2 to remove and 0 not upgraded.
After this operation, 310 MB disk space will be freed.
Do you want to continue? [Y/n] Y
Creating pre-apt snapshot... 2 done.
(Reading database ... 42026 files and directories currently installed.)
Removing netq-agent (3.0.0-cl3u27~1587646213.c5bc079) ...
/usr/sbin/policy-rc.d returned 101, not running 'stop netq-agent.service'
Purging configuration files for netq-agent (3.0.0-cl3u27~1587646213.c5bc079) ...
dpkg: warning: while removing netq-agent, directory '/etc/netq/config.d' not empty so not removed
Removing netq-apps (3.0.0-cl3u27~1587646213.c5bc079) ...
/usr/sbin/policy-rc.d returned 101, not running 'stop netqd.service'
Purging configuration files for netq-apps (3.0.0-cl3u27~1587646213.c5bc079) ...
dpkg: warning: while removing netq-apps, directory '/etc/netq' not empty so not removed
Processing triggers for man-db (2.7.0.2-5) ...
grep: extra.services.enabled: No such file or directory
Creating post-apt snapshot... 3 done.
If you only want to remove the agent or the CLI, but not both, specify just the relevant package in the apt-get purge command.
To verify the packages have been removed from the switch, run:
cumulus@switch:~$ dpkg-query -l netq-agent
dpkg-query: no packages found matching netq-agent
cumulus@switch:~$ dpkg-query -l netq-apps
dpkg-query: no packages found matching netq-apps
Remove the Agent and CLI from a RHEL7 or CentOS Host
Use the yum remove command to remove the NetQ agent or CLI package from a RHEL7 or CentOS host.
If you only want to remove the agent or the CLI, but not both, specify just the relevant package in the yum remove command.
To verify the packages have been removed from the switch, run:
root@rhel7:~# rpm -q netq-agent
package netq-agent is not installed
root@rhel7:~# rpm -q netq-apps
package netq-apps is not installed
Upgrade NetQ
This topic describes how to upgrade from your current NetQ 2.4.x installation to the NetQ 3.0.0 release to take advantage of new capabilities and bug fixes (refer to the release notes).
You must upgrade your NetQ On-premises or Cloud Appliance(s) or Virtual Machines (VMs). While NetQ 2.x Agents are compatible with NetQ 3.0.0, upgrading NetQ Agents is always recommended. If you want access to new and updated commands, you can upgrade the CLI on your physical servers or VMs, and monitored switches and hosts as well.
To complete the upgrade for either an on-premises or a cloud deployment:
The first step in upgrading your NetQ 2.4.x installation to NetQ 3.0.0 is to upgrade either the NetQ Platform software running on your NetQ On-premises Appliance(s) or VM(s), or the NetQ Collector software running on your NetQ Cloud Appliance(s) or VM(s).
Prepare for Upgrade
Two important steps are required to prepare for upgrade of your NetQ software:
Download the necessary software tarballs
Update the Debian packages on Appliance(s) and VM(s)
Optionally, you can choose to back up your NetQ Data before performing the upgrade.
To complete the preparation:
For on-premises deployments only, optionally back up your NetQ 2.4.x data. Refer to Back Up Your NetQ Data.
Select 3.0 from the Version list, and then click 3.0.0 in the submenu.
Select the relevant software from the HyperVisor/Platform list:
If you are upgrading NetQ Platform software for a NetQ On-premises Appliance or VM, select Appliance to download the NetQ-3.0.0.tgz file. If you are upgrading NetQ Collector software for a NetQ Cloud Appliance or VM, select Appliance (Cloud) to download the NetQ-3.0.0-opta.tgz file.
Scroll down and click Download on the relevant image card.
You can ignore the note on the image card because, unlike during installation, you do not need to download the bootstrap file for an upgrade.
Copy the file to the /mnt/installables/ directory on your appliance or VM.
Update /etc/apt/sources.list.d/cumulus-netq.list to netq-3.0 as followed
cat /etc/apt/sources.list.d/cumulus-netq.list
deb [arch=amd64] https://apps3.cumulusnetworks.com/repos/deb bionic netq-3.0
Update the NetQ debian packages using the following three commands.
cumulus@<hostname>:~$ sudo dpkg --remove --force-remove-reinstreq cumulus-netq netq-apps netq-agent 2>/dev/null
[sudo] password for cumulus:
(Reading database ... 71621 files and directories currently installed.)
Removing netq-apps (2.4.1-ub18.04u26~1581351889.c5ec3e5) ...
Removing netq-agent (2.4.1-ub18.04u26~1581351889.c5ec3e5) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
cumulus@<hostname>:~$ sudo apt-get install -y netq-agent netq-apps
Reading package lists... Done
Building dependency tree
Reading state information... Done
...
The following NEW packages will be installed:
netq-agent netq-apps
...
Fetched 39.8 MB in 3s (13.5 MB/s)
...
Unpacking netq-agent (3.0.0-ub18.04u27~1588242914.9fb5b87) ...
...
Unpacking netq-apps (3.0.0-ub18.04u27~1588242914.9fb5b87) ...
Setting up netq-apps (3.0.0-ub18.04u27~1588242914.9fb5b87) ...
Setting up netq-agent (3.0.0-ub18.04u27~1588242914.9fb5b87) ...
Processing triggers for rsyslog (8.32.0-1ubuntu4) ...
Processing triggers for man-db (2.8.3-2ubuntu0.1) ...
Now that you have all of the software components prepared, you can upgrade your NetQ On-premises Appliance or VM, or your NetQ Cloud Appliance or VM, using the NetQ Admin UI, in the next section. Alternately, you can upgrade using the CLI here: Upgrade Using the NetQ CLI.
Upgrade Using the NetQ Admin UI
Upgrading your NetQ On-premises or Cloud Appliance(s) or VMs is simple using the Admin UI.
Cumulus Networks strongly recommends that you upgrade your NetQ Agents when you install or upgrade to a new release. If you are using NetQ Agent 2.4.0 update 24 or earlier, you must upgrade to ensure proper operation.
Upgrade NetQ Agents on Cumulus Linux Switches
The following instructions are applicable to both Cumulus Linux 3.x and 4.x, and for both on-premises and cloud deployments.
The following instructions are applicable to both NetQ Platform and NetQ Appliances running Ubuntu 16.04 or 18.04 in on-premises and cloud deployments.
While it is not required to upgrade the NetQ CLI on your monitored switches and hosts when you upgrade to NetQ 3.0.0, doing so gives you access to new features and important bug fixes. Refer to the release notes for details.
It is recommended that you back up your NetQ data according to your company policy. Typically this includes after key configuration changes and on a scheduled basis.
These topics describe how to backup and also restore your NetQ data for NetQ On-premises Appliance and VMs.
These procedures do not apply to your NetQ Cloud Appliance or VM. Data backup is handled automatically with the NetQ cloud service.
Back Up Your NetQ Data
NetQ data is stored in a Cassandra database. A backup is performed by running scripts provided with the software and located in the /usr/sbin directory. When a backup is performed, a single tar file is created. The file is stored on a local drive that you specify and is named netq_master_snapshot_<timestamp>.tar.gz. Currently, only one backup file is supported, and includes the entire set of data tables. It is replaced each time a new backup is created.
If the rollback option is selected during the lifecycle management upgrade process (the default behavior), a backup is created automatically.
To manually create a backup:
If you are backing up data from NetQ 2.4.0 or earlier, or you upgraded from NetQ 2.4.0 to 2.4.1, obtain an updated backuprestore script. If you installed NetQ 2.4.1 as a fresh install, you can skip this step. Replace <version> in these commands with 2.4.1 or later release version.
cumulus@switch:~$ tar -xvzf /mnt/installables/NetQ-<version>.tgz -C /tmp/ ./netq-deploy-<version>.tgz
cumulus@switch:~$ tar -xvzf /tmp/netq-deploy-<version>.tgz -C /usr/sbin/ --strip-components 1 --wildcards backuprestore/*.sh
Run the backup script to create a backup file in /opt/<backup-directory> being sure to replace the backup-directory option with the name of the directory you want to use for the backup file.
You can abbreviate the backup and localdir options of this command to -b and -l to reduce typing. If the backup directory identified does not already exist, the script creates the directory during the backup process.
This is a sample of what you see as the script is running:
[Fri 26 Jul 2019 02:35:35 PM UTC] - Received Inputs for backup ...
[Fri 26 Jul 2019 02:35:36 PM UTC] - Able to find cassandra pod: cassandra-0
[Fri 26 Jul 2019 02:35:36 PM UTC] - Continuing with the procedure ...
[Fri 26 Jul 2019 02:35:36 PM UTC] - Removing the stale backup directory from cassandra pod...
[Fri 26 Jul 2019 02:35:36 PM UTC] - Able to successfully cleanup up /opt/backuprestore from cassandra pod ...
[Fri 26 Jul 2019 02:35:36 PM UTC] - Copying the backup script to cassandra pod ....
/opt/backuprestore/createbackup.sh: line 1: cript: command not found
[Fri 26 Jul 2019 02:35:48 PM UTC] - Able to exeute /opt/backuprestore/createbackup.sh script on cassandra pod
[Fri 26 Jul 2019 02:35:48 PM UTC] - Creating local directory:/tmp/backuprestore/ ...
Directory /tmp/backuprestore/ already exists..cleaning up
[Fri 26 Jul 2019 02:35:48 PM UTC] - Able to copy backup from cassandra pod to local directory:/tmp/backuprestore/ ...
[Fri 26 Jul 2019 02:35:48 PM UTC] - Validate the presence of backup file in directory:/tmp/backuprestore/
[Fri 26 Jul 2019 02:35:48 PM UTC] - Able to find backup file:netq_master_snapshot_2019-07-26_14_35_37_UTC.tar.gz
[Fri 26 Jul 2019 02:35:48 PM UTC] - Backup finished successfully!
Verify the backup file has been created.
cumulus@switch:~$ cd /opt/<backup-directory>
cumulus@switch:~/opt/<backup-directory># ls
netq_master_snapshot_2019-06-04_07_24_50_UTC.tar.gz
To create a scheduled backup, add ./backuprestore.sh --backup --localdir /opt/<backup-directory> to an existing cron job, or create a new one.
Restore Your NetQ Data
You can restore NetQ data using the backup file you created in Back Up Your NetQ Data. You can restore your instance to the same NetQ Platform or NetQ Appliance or to a new platform or appliance. You do not need to stop the server where the backup file resides to perform the restoration, but logins to the NetQ UI will fail during the restoration process.The restore option of the backup script, copies the data from the backup file to the database, decompresses it, verifies the restoration, and starts all necessary services. You should not see any data loss as a result of a restore operation.
To restore NetQ on the same hardware where the backup file resides:
If you are restoring data from NetQ 2.4.0 or earlier, or you upgraded from NetQ 2.4.0 to 2.4.1, obtain an updated backuprestore script. If you installed NetQ 2.4.1 as a fresh install, you can skip this step. Replace <version> in these commands with 2.4.1 or later release version.
cumulus@switch:~$ tar -xvzf /mnt/installables/NetQ-<version>.tgz -C /tmp/ ./netq-deploy-<version>.tgz
cumulus@switch:~$ tar -xvzf /tmp/netq-deploy-<version>.tgz -C /usr/sbin/ --strip-components 1 --wildcards backuprestore/*.sh
Run the restore script being sure to replace the backup-directory option with the name of the directory where the backup file resides.
You can abbreviate the restore and localdir options of this command to -r and -l to reduce typing.
This is a sample of what you see while the script is running:
[Fri 26 Jul 2019 02:37:49 PM UTC] - Received Inputs for restore ...
WARNING: Restore procedure wipes out the existing contents of Database.
Once the Database is restored you loose the old data and cannot be recovered.
"Do you like to continue with Database restore:[Y(yes)/N(no)]. (Default:N)"
You must answer the above question to continue the restoration. After entering Y or yes, the output continues as follows:
[Fri 26 Jul 2019 02:37:50 PM UTC] - Able to find cassandra pod: cassandra-0
[Fri 26 Jul 2019 02:37:50 PM UTC] - Continuing with the procedure ...
[Fri 26 Jul 2019 02:37:50 PM UTC] - Backup local directory:/tmp/backuprestore/ exists....
[Fri 26 Jul 2019 02:37:50 PM UTC] - Removing any stale restore directories ...
Copying the file for restore to cassandra pod ....
[Fri 26 Jul 2019 02:37:50 PM UTC] - Able to copy the local directory contents to cassandra pod in /tmp/backuprestore/.
[Fri 26 Jul 2019 02:37:50 PM UTC] - copying the script to cassandra pod in dir:/tmp/backuprestore/....
Executing the Script for restoring the backup ...
/tmp/backuprestore//createbackup.sh: line 1: cript: command not found
[Fri 26 Jul 2019 02:40:12 PM UTC] - Able to exeute /tmp/backuprestore//createbackup.sh script on cassandra pod
[Fri 26 Jul 2019 02:40:12 PM UTC] - Restore finished successfully!
To restore NetQ on new hardware:
Copy the backup file from /opt/<backup-directory> on the older hardware to the backup directory on the new hardware.
Run the restore script on the new hardware, being sure to replace the backup-directory option with the name of the directory where the backup file resides.
After installation or upgrade of NetQ is complete, there are a few additional configuration tasks that might be required.
Add More Nodes to Your Server Cluster
Installation of NetQ with a server cluster sets up the master and two worker nodes. To expand your cluster to include up to a total of nine worker nodes, use the Admin UI.
Open the Admin UI by entering https://<master-hostname-or-ipaddress>:8443 in your browser address field.
This opens the Health dashboard for NetQ.
Click Cluster to view your current configuration.
On-premises deployment
This opens the Cluster dashboard, with the details about each node in the cluster.
Click Add Worker Node.
Enter the private IP address of the node you want to add.
Click Add.
Monitor the progress of the three jobs by clicking next to the jobs.
On completion, a card for the new node is added to the Cluster dashboard.
If the addition fails for any reason, download the log file by clicking , run netq bootstrap reset on this new worker node, and then try again.
Repeat this process to add more worker nodes as needed.
Update Your Cloud Activation Key
The cloud activation key is the one used to access the Cloud services, not the authorization keys used for configuring the CLI. It is provided by Cumulus Networks when your premises is set up. It is called the config-key.
There are occasions where you might want to update your cloud service activation key. For example, if you mistyped the key during installation and now your existing key does not work, or you received a new key for your premises from Cumulus Networks.
Update the activation key using the Admin UI or NetQ CLI:
Open the Admin UI by entering https://<master-hostname-or-ipaddress>:8443 in your browser address field.
Click Settings.
Click Activation.
Click Edit.
Enter your new configuration key in the designated text box.
Click Apply.
Run the following command on your standalone or master NetQ Cloud Appliance or VM replacing text-opta-key with your new key.
After you have completed the installation of Cumulus NetQ,
you may want to configure some of the additional capabilities that NetQ
offers or integrate it with third-party software or hardware.
This topic describes how to:
integrate and configure NetQ event notifications with popular notification applications
integrate with your LDAP server to use existing user accounts in NetQ
integrate with Grafana to view interface statistics graphically
integrate with customer applications using the Cumulus NetQ API
Integrate NetQ with Notification Applications
After you have installed the NetQ applications package and the NetQ Agents,
you may want to configure some of the additional capabilities that NetQ
offers. This topic describes how to integrate NetQ with an event notification application.
Integrate NetQ with an Event Notification Application
To take advantage of the numerous event messages generated and processed
by NetQ, you must integrate with third-party event notification
applications. You can integrate NetQ with Syslog, PagerDuty and Slack tools.
You may integrate with one or more of these applications simultaneously.
Each network protocol and service in the NetQ Platform receives the raw
data stream from the NetQ Agents, processes the data and delivers events
to the Notification function. Notification then stores, filters and
sends messages to any configured notification applications. Filters are
based on rules you create. You must have at least one rule per filter. A select set of events can be triggered by a user-configured threshold.
You may choose to implement a proxy server (that sits between the NetQ
Platform and the integration channels) that receives, processes and
distributes the notifications rather than having them sent directly to
the integration channel. If you use such a proxy, you must configure
NetQ with the proxy information.
In either case, notifications are generated for the following types of
events:
Category
Events
Network Protocols
BGP status and session state
CLAG (MLAG) status and session state
EVPN status and session state
LLDP status
OSPF status and session state
VLAN status and session state *
VXLAN status and session state *
Interfaces
Link status
Ports and cables status
MTU status
Services
NetQ Agent status
PTM
SSH *
NTP status*
Traces
On-demand trace status
Scheduled trace status
Sensors
Fan status
PSU (power supply unit) status
Temperature status
System Software
Configuration File changes
Running Configuration File changes
Cumulus Linux License status
Cumulus Linux Support status
Software Package status
Operating System version
System Hardware
Physical resources status
BTRFS status
SSD utilization status
Threshold Crossing Alerts (TCAs)
* This type of event can only be viewed in the CLI with this release.
Refer to the Events Reference for descriptions and examples of these events.
Event Message Format
Messages have the following structure:
<message-type><timestamp><opid><hostname><severity><message>
Identifier of the service or process that generated the event
hostname
Hostname of network device where event occurred
severity
Severity level in which the given event is classified; debug, error, info, warning, or critical
message
Text description of event
For example:
To set up the integrations, you must configure NetQ with at least one channel, one rule, and one filter. To refine what messages you want to view and where to send them, you can add additional rules and filters and set thresholds on supported event types. You can also configure a proxy server to receive, process, and forward the messages. This is accomplished using the NetQ CLI in the following order:
Notification Commands Overview
The NetQ Command Line Interface (CLI) is used to filter and send notifications to third-party tools based on severity, service, event-type, and device. You can use TAB completion or the help option to assist when needed.
##Proxy
netq add notification proxy <text-proxy-hostname> [port <text-proxy-port>]
netq show notification proxy
netq del notification proxy
The various command options are described in the following sections where they are used.
Configure Basic NetQ Event Notification
The simplest configuration you can create is one that sends all events generated by all interfaces to a single notification application. This is described here. For more granular configurations and examples, refer to Configure Advanced NetQ Event Notifications.
A notification configuration must contain one channel, one rule, and one filter. Creation of the configuration follows this same path:
Add a channel (slack, pagerduty, syslog)
Add a rule that accepts all interface events
Add a filter that associates this rule with the newly created channel
Create Your Channel
For Pager Duty:
Configure a channel using the integration key for your Pager Duty setup. Verify the configuration.
cumulus@switch:~$ netq add notification channel pagerduty pd-netq-events integration-key c6d666e210a8425298ef7abde0d1998
Successfully added/updated channel pd-netq-events
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: c6d666e
210a8425298ef7abde0d1998
For Slack:
Create an incoming webhook as described in the documentation for your version of Slack. Verify the configuration.
cumulus@switch:~$ netq add notification channel slack slk-netq-events webhook https://hooks.slack.com/services/text/moretext/evenmoretext
Successfully added/updated channel slk-netq-events
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
slk-netq-events slack info webhook:https://hooks.s
lack.com/services/text/
moretext/evenmoretext
For Syslog:
Create the channel using the syslog server hostname (or IP address) and port. Verify the configuration.
cumulus@switch:~$ netq add notification channel syslog syslog-netq-events hostname syslog-server port 514
Successfully added/updated channel syslog-netq-events
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
syslog-netq-eve syslog info host:syslog-server
nts port: 514
Create a Rule
Create and verify a rule that accepts all interface events. Verify the configuration.
cumulus@switch:~$ netq add notification rule all-ifs key ifname value ALL
Successfully added/updated rule all-ifs
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
all-interfaces ifname ALL
Create a Filter
Create a filter to tie the rule to the channel. Verify the configuration.
For PagerDuty:
cumulus@switch:~$ netq add notification filter notify-all-ifs rule all-ifs channel pd-netq-events
Successfully added/updated filter notify-all-ifs
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
notify-all-ifs 1 info pd-netq-events all-ifs
For Slack:
cumulus@switch:~$ netq add notification filter notify-all-ifs rule all-ifs channel slk-netq-events
Successfully added/updated filter notify-all-ifs
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
notify-all-ifs 1 info slk-netq-events all-ifs
For Syslog:
cumulus@switch:~$ netq add notification filter notify-all-ifs rule all-ifs channel syslog-netq-events
Successfully added/updated filter notify-all-ifs
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
notify-all-ifs 1 info syslog-netq-events all-ifs
NetQ is now configured to send all interface events to your selected channel.
Configure Advanced NetQ Event Notifications
If you want to create more granular notifications based on such items as selected devices, characteristics of devices, or protocols, or you want to use a proxy server, you need more than the basic notification configuration. Details for creating these more complex notification configurations are included here.
Configure a Proxy Server
To send notification messages through a proxy server instead of directly
to a notification channel, you configure NetQ with the hostname and
optionally a port of a proxy server. If no port is specified, NetQ
defaults to port 80. Only one proxy server is currently supported. To
simplify deployment, configure your proxy server before configuring
channels, rules, or filters.To configure the proxy server:
You can remove the proxy server by running the netq del notification proxy command. This changes the NetQ behavior to send events directly
to the notification channels.
cumulus@switch:~$ netq del notification proxy
Successfully overwrote notifier proxy to null
Create Channels
Create one or more PagerDuty, Slack, or syslog channels to present the
notifications.
Configure a PagerDuty Channel
NetQ sends notifications to PagerDuty as PagerDuty events.
For example:
To configure the NetQ notifier to send notifications to PagerDuty:
Configure the following options using the netq add notification channel command:
Option
Description
CHANNEL_TYPE <text-channel-name>
The third-party notification channel and name; use pagerduty in this case.
integration-key <text-integration-key>
The integration key is also called the service_key or routing_key. The default is an empty string ("").
severity
(Optional) The log level to set, which can be one of info, warning, error, critical or debug. The severity defaults to info.
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: c6d666e
210a8425298ef7abde0d1998
Configure a Slack Channel
NetQ Notifier sends notifications to Slack as incoming webhooks for a
Slack channel you configure. For example:
To configure NetQ to send notifications to Slack:
If needed, create one or more Slack channels on which to receive the
notifications.
Click + next to Channels.
Enter a name for the channel, and click Create Channel.
Navigate to the new channel.
Click + Add an app link below the channel name to open the
application directory.
In the search box, start typing incoming and select **
Incoming WebHooks when it appears.
Click Add Configuration and enter the name of the channel
you created (where you want to post notifications).
Click Add Incoming WebHooks integration.
Save WebHook URL in a text file for use in next step.
Configure the following options in the netq config add notification channel command:
Option
Description
CHANNEL_TYPE <text-channel-name>
The third-party notification channel name; use slack in this case.
WEBHOOK
Copy the WebHook URL from the text file OR in the desired channel, locate the initial message indicating the addition of the webhook, click incoming-webhook link, click Settings.
Example URL: https://hooks.slack.com/services/text/moretext/evenmoretext
severity
The log level to set, which can be one of error, warning, info, or debug. The severity defaults to info.
tag
Optional tag appended to the Slack notification to highlight particular channels or people. The tag value must be preceded by the @ sign. For example, @netq-info.
Verify the channel is configured correctly.
From the CLI:
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
slk-netq-events slack info webhook:https://hooks.s
lack.com/services/text/
moretext/evenmoretext
From the Slack Channel:
Create Rules
Each rule is comprised of a single key-value pair. The key-value pair
indicates what messages to include or drop from event information sent
to a notification channel. You can create more than one rule for a
single filter. Creating multiple rules for a given filter can provide a
very defined filter. For example, you can specify rules around hostnames
or interface names, enabling you to filter messages specific to those
hosts or interfaces. You should have already defined the PagerDuty or
Slack channels (as described earlier).
There is a fixed set of valid rule keys. Values are entered as regular
expressions and vary according to your deployment.
Service
Rule Key
Description
Example Rule Values
BGP
message_type
Network protocol or service identifier
bgp
hostname
User-defined, text-based name for a switch or host
server02, leaf11, exit01, spine-4
peer
User-defined, text-based name for a peer switch or host
server4, leaf-3, exit02, spine06
desc
Text description
vrf
Name of VRF interface
mgmt, default
old_state
Previous state of the BGP service
Established, NotEstd
new_state
Current state of the BGP service
Established, NotEstd
old_last_reset_time
Previous time that BGP service was reset
Apr3, 2019, 4:17 pm
new_last_reset_time
Most recent time that BGP service was reset
Apr8, 2019, 11:38 am
MLAG (CLAG)
message_type
Network protocol or service identifier
clag
hostname
User-defined, text-based name for a switch or host
server02, leaf-9, exit01, spine04
old_conflicted_bonds
Previous pair of interfaces in a conflicted bond
swp7 swp8, swp3 swp4
new_conflicted_bonds
Current pair of interfaces in a conflicted bond
swp11 swp12, swp23 swp24
old_state_protodownbond
Previous state of the bond
protodown, up
new_state_protodownbond
Current state of the bond
protodown, up
ConfigDiff
message_type
Network protocol or service identifier
configdiff
hostname
User-defined, text-based name for a switch or host
server02, leaf11, exit01, spine-4
vni
Virtual Network Instance identifier
12, 23
old_state
Previous state of the configuration file
created, modified
new_state
Current state of the configuration file
created, modified
EVPN
message_type
Network protocol or service identifier
evpn
hostname
User-defined, text-based name for a switch or host
server02, leaf-9, exit01, spine04
vni
Virtual Network Instance identifier
12, 23
old_in_kernel_state
Previous VNI state, in kernel or not
true, false
new_in_kernel_state
Current VNI state, in kernel or not
true, false
old_adv_all_vni_state
Previous VNI advertising state, advertising all or not
true, false
new_adv_all_vni_state
Current VNI advertising state, advertising all or not
true, false
Link
message_type
Network protocol or service identifier
link
hostname
User-defined, text-based name for a switch or host
server02, leaf-6, exit01, spine7
ifname
Software interface name
eth0, swp53
LLDP
message_type
Network protocol or service identifier
lldp
hostname
User-defined, text-based name for a switch or host
server02, leaf41, exit01, spine-5, tor-36
ifname
Software interface name
eth1, swp12
old_peer_ifname
Previous software interface name
eth1, swp12, swp27
new_peer_ifname
Current software interface name
eth1, swp12, swp27
old_peer_hostname
Previous user-defined, text-based name for a peer switch or host
server02, leaf41, exit01, spine-5, tor-36
new_peer_hostname
Current user-defined, text-based name for a peer switch or host
server02, leaf41, exit01, spine-5, tor-36
Node
message_type
Network protocol or service identifier
node
hostname
User-defined, text-based name for a switch or host
server02, leaf41, exit01, spine-5, tor-36
ntp_state
Current state of NTP service
in sync, not sync
db_state
Current state of DB
Add, Update, Del, Dead
NTP
message_type
Network protocol or service identifier
ntp
hostname
User-defined, text-based name for a switch or host
server02, leaf-9, exit01, spine04
old_state
Previous state of service
in sync, not sync
new_state
Current state of service
in sync, not sync
Port
message_type
Network protocol or service identifier
port
hostname
User-defined, text-based name for a switch or host
server02, leaf13, exit01, spine-8, tor-36
ifname
Interface name
eth0, swp14
old_speed
Previous speed rating of port
10 G, 25 G, 40 G, unknown
old_transreceiver
Previous transceiver
40G Base-CR4, 25G Base-CR
old_vendor_name
Previous vendor name of installed port module
Amphenol, OEM, Mellanox, Fiberstore, Finisar
old_serial_number
Previous serial number of installed port module
MT1507VS05177, AVE1823402U, PTN1VH2
old_supported_fec
Previous forward error correction (FEC) support status
User-defined, text-based name for a switch or host
server02, leaf-26, exit01, spine2-4
old_state
Previous state of a fan, power supply unit, or thermal sensor
Fan: ok, absent, bad
PSU: ok, absent, bad
Temp: ok, busted, bad, critical
new_state
Current state of a fan, power supply unit, or thermal sensor
Fan: ok, absent, bad
PSU: ok, absent, bad
Temp: ok, busted, bad, critical
old_s_state
Previous state of a fan or power supply unit.
Fan: up, down
PSU: up, down
new_s_state
Current state of a fan or power supply unit.
Fan: up, down
PSU: up, down
new_s_max
Current maximum temperature threshold value
Temp: 110
new_s_crit
Current critical high temperature threshold value
Temp: 85
new_s_lcrit
Current critical low temperature threshold value
Temp: -25
new_s_min
Current minimum temperature threshold value
Temp: -50
Services
message_type
Network protocol or service identifier
services
hostname
User-defined, text-based name for a switch or host
server02, leaf03, exit01, spine-8
name
Name of service
clagd, lldpd, ssh, ntp, netqd, net-agent
old_pid
Previous process or service identifier
12323, 52941
new_pid
Current process or service identifier
12323, 52941
old_status
Previous status of service
up, down
new_status
Current status of service
up, down
Rule names are case sensitive, and no wildcards are permitted. Rule
names may contain spaces, but must be enclosed with single quotes in
commands. It is easier to use dashes in place of spaces or mixed case
for better readability. For example, use bgpSessionChanges or
BGP-session-changes or BGPsessions, instead of 'BGP Session Changes'.
Use Tab completion to view the command options syntax.
cumulus@switch:~$ netq add notification rule swp52 key port value swp52
Successfully added/updated rule swp52
View the Rule Configurations
Use the netq show notification command to view the rules on your
platform.
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
fecSupport new_supported_fe supported
c
overTemp new_s_crit 24
svcStatus new_status down
swp52 port swp52
sysconf configdiff updated
Create Filters
You can limit or direct event messages using filters. Filters are
created based on rules you define; like those in the previous section.
Each filter contains one or more rules. When a message matches the rule,
it is sent to the indicated destination. Before you can create filters,
you need to have already defined the rules and configured PagerDuty
and/or Slack channels (as described earlier).
As filters are created, they are added to the bottom of a filter list.
By default, filters are processed in the order they appear in this list
(from top to bottom) until a match is found. This means that each event
message is first evaluated by the first filter listed, and if it matches
then it is processed, ignoring all other filters, and the system moves
on to the next event message received. If the event does not match the
first filter, it is tested against the second filter, and if it matches
then it is processed and the system moves on to the next event received.
And so forth. Events that do not match any filter are ignored.
You may need to change the order of filters in the list to ensure you
capture the events you want and drop the events you do not want. This is
possible using the before or after keywords to ensure one rule is
processed before or after another.
This diagram shows an example with four defined filters with sample
output results.
Filter names may contain spaces, but must be enclosed with single
quotes in commands. It is easier to use dashes in place of spaces or
mixed case for better readability. For example, use bgpSessionChanges or
BGP-session-changes or BGPsessions, instead of 'BGP Session Changes'.
Filter names are also case sensitive.
Example Filters
Create a filter for BGP Events on a Particular Device:
Create a Filter to Drop Messages from a Given Interface, and match
against this filter before any other filters. To create a drop style
filter, do not specify a channel. To put the filter first, use the
before option.
Use the netq show notification command to view the filters on your
platform.
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
swp52Drop 1 error NetqDefaultChann swp52
el
bgpSpine 2 info pd-netq-events bgpHostnam
e
vni42 3 warning pd-netq-events evpnVni
configChange 4 info slk-netq-events sysconf
newFEC 5 info slk-netq-events fecSupport
svcDown 6 critical slk-netq-events svcStatus
critTemp 7 critical pd-netq-events overTemp
Reorder Filters
When you look at the results of the netq show notification filter
command above, you might notice that although you have the drop-based
filter first (no point in looking at something you are going to drop
anyway, so that is good), but the critical severity events are processed
last, per the current definitions. If you wanted to process those before
lesser severity events, you can reorder the list using the before and
after options.
For example, to put the two critical severity event filters just below
the drop filter:
You do not need to reenter all the severity, channel, and rule
information for existing rules if you only want to change their
processing order.
Run the netq show notification command again to verify the changes:
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
swp52Drop 1 error NetqDefaultChann swp52
el
critTemp 2 critical pd-netq-events overTemp
svcDown 3 critical slk-netq-events svcStatus
bgpSpine 4 info pd-netq-events bgpHostnam
e
vni42 5 warning pd-netq-events evpnVni
configChange 6 info slk-netq-events sysconf
newFEC 7 info slk-netq-events fecSupport
Examples of Advanced Notification Configurations
Putting all of these channel, rule, and filter definitions together you
create a complete notification configuration. The following are example
notification configurations are created using the three-step process
outlined above. Refer to Integrate NetQ with an Event Notification Application for details and instructions for creating channels, rules, and filters.
Create a Notification for BGP Events from a Selected Switch
In this example, we created a notification integration with a PagerDuty
channel called pd-netq-events. We then created a rule bgpHostname
and a filter called 4bgpSpine for any notifications from spine-01.
The result is that any info severity event messages from Spine-01 are
filtered to the pd-netq-events ** channel.
cumulus@switch:~$ netq add notification channel pagerduty pd-netq-events integration-key 1234567890
Successfully added/updated channel pd-netq-events
cumulus@switch:~$ netq add notification rule bgpHostname key node value spine-01
Successfully added/updated rule bgpHostname
cumulus@switch:~$ netq add notification filter bgpSpine rule bgpHostname channel pd-netq-events
Successfully added/updated filter bgpSpine
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: 1234567
890
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
bgpSpine 1 info pd-netq-events bgpHostnam
e
Create a Notification for Warnings on a Given EVPN VNI
In this example, we created a notification integration with a PagerDuty
channel called pd-netq-events. We then created a rule evpnVni and a
filter called 3vni42 for any warnings messages from VNI 42 on the EVPN
overlay network. The result is that any warning severity event messages
from VNI 42 are filtered to the pd-netq-events channel.
cumulus@switch:~$ netq add notification channel pagerduty pd-netq-events integration-key 1234567890
Successfully added/updated channel pd-netq-events
cumulus@switch:~$ netq add notification rule evpnVni key vni value 42
Successfully added/updated rule evpnVni
cumulus@switch:~$ netq add notification filter vni42 rule evpnVni channel pd-netq-events
Successfully added/updated filter vni42
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: 1234567
890
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
bgpSpine 1 info pd-netq-events bgpHostnam
e
vni42 2 warning pd-netq-events evpnVni
Create a Notification for Configuration File Changes
In this example, we created a notification integration with a Slack
channel called slk-netq-events. We then created a rule sysconf and a
filter called configChange for any configuration file update messages.
The result is that any configuration update messages are filtered to the
slk-netq-events channel.
cumulus@switch:~$ netq add notification channel slack slk-netq-events webhook https://hooks.slack.com/services/text/moretext/evenmoretext
Successfully added/updated channel slk-netq-events
cumulus@switch:~$ netq add notification rule sysconf key configdiff value updated
Successfully added/updated rule sysconf
cumulus@switch:~$ netq add notification filter configChange severity info rule sysconf channel slk-netq-events
Successfully added/updated filter configChange
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
slk-netq-events slack info webhook:https://hooks.s
lack.com/services/text/
moretext/evenmoretext
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
sysconf configdiff updated
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
bgpSpine 1 info pd-netq-events bgpHostnam
e
vni42 2 warning pd-netq-events evpnVni
configChange 3 info slk-netq-events sysconf
Create a Notification for When a Service Goes Down
In this example, we created a notification integration with a Slack
channel called slk-netq-events. We then created a rule svcStatus and
a filter called svcDown for any services state messages indicating a
service is no longer operational. The result is that any service down
messages are filtered to the slk-netq-events channel.
cumulus@switch:~$ netq add notification channel slack slk-netq-events webhook https://hooks.slack.com/services/text/moretext/evenmoretext
Successfully added/updated channel slk-netq-events
cumulus@switch:~$ netq add notification rule svcStatus key new_status value down
Successfully added/updated rule svcStatus
cumulus@switch:~$ netq add notification filter svcDown severity error rule svcStatus channel slk-netq-events
Successfully added/updated filter svcDown
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
slk-netq-events slack info webhook:https://hooks.s
lack.com/services/text/
moretext/evenmoretext
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
svcStatus new_status down
sysconf configdiff updated
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
bgpSpine 1 info pd-netq-events bgpHostnam
e
vni42 2 warning pd-netq-events evpnVni
configChange 3 info slk-netq-events sysconf
svcDown 4 critical slk-netq-events svcStatus
Create a Filter to Drop Notifications from a Given Interface
In this example, we created a notification integration with a Slack
channel called slk-netq-events. We then created a rule swp52 and a
filter called swp52Drop that drops all notifications for events from
interface swp52.
cumulus@switch:~$ netq add notification channel slack slk-netq-events webhook https://hooks.slack.com/services/text/moretext/evenmoretext
Successfully added/updated channel slk-netq-events
cumulus@switch:~$ netq add notification rule swp52 key port value swp52
Successfully added/updated rule swp52
cumulus@switch:~$ netq add notification filter swp52Drop severity error rule swp52 before bgpSpine
Successfully added/updated filter swp52Drop
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- -------- ----------------------
slk-netq-events slack info webhook:https://hooks.s
lack.com/services/text/
moretext/evenmoretext
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
svcStatus new_status down
swp52 port swp52
sysconf configdiff updated
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
swp52Drop 1 error NetqDefaultChann swp52
el
bgpSpine 2 info pd-netq-events bgpHostnam
e
vni42 3 warning pd-netq-events evpnVni
configChange 4 info slk-netq-events sysconf
svcDown 5 critical slk-netq-events svcStatus
Create a Notification for a Given Device that has a Tendency to Overheat (using multiple rules)
In this example, we created a notification when switch leaf04 has
passed over the high temperature threshold. Two rules were needed to
create this notification, one to identify the specific device and one to
identify the temperature trigger. We sent the message to the
pd-netq-events channel.
cumulus@switch:~$ netq add notification channel pagerduty pd-netq-events integration-key 1234567890
Successfully added/updated channel pd-netq-events
cumulus@switch:~$ netq add notification rule switchLeaf04 key hostname value leaf04
Successfully added/updated rule switchLeaf04
cumulus@switch:~$ netq add notification rule overTemp key new_s_crit value 24
Successfully added/updated rule overTemp
cumulus@switch:~$ netq add notification filter critTemp rule switchLeaf04 channel pd-netq-events
Successfully added/updated filter critTemp
cumulus@switch:~$ netq add notification filter critTemp severity critical rule overTemp channel pd-netq-events
Successfully added/updated filter critTemp
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: 1234567
890
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
overTemp new_s_crit 24
svcStatus new_status down
switchLeaf04 hostname leaf04
swp52 port swp52
sysconf configdiff updated
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
swp52Drop 1 error NetqDefaultChann swp52
el
bgpSpine 2 info pd-netq-events bgpHostnam
e
vni42 3 warning pd-netq-events evpnVni
configChange 4 info slk-netq-events sysconf
svcDown 5 critical slk-netq-events svcStatus
critTemp 6 critical pd-netq-events switchLeaf
04
overTemp
View Notification Configurations in JSON Format
You can view configured integrations using the netq show notification
commands. To view the channels, filters, and rules, run the three
flavors of the command. Include the json option to display
JSON-formatted output.
You might need to modify event notification configurations at some point in the lifecycle of your deployment.
Remove an Event Notification Channel
You can delete an event notification integration using the netq config del notification command. You can verify it has been removed using the
related show command.
For example, to remove a Slack integration and verify it is no longer in
the configuration:
cumulus@switch:~$ netq del notification channel slk-netq-events
cumulus@switch:~$ netq show notification channel
Matching config_notify records:
Name Type Severity Channel Info
--------------- ---------------- ---------------- ------------------------
pd-netq-events pagerduty info integration-key: 1234567
890
Delete an Event Notification Rule
To delete a rule, use the following command, then verify it has been
removed:
cumulus@switch:~$ netq del notification rule swp52
cumulus@switch:~$ netq show notification rule
Matching config_notify records:
Name Rule Key Rule Value
--------------- ---------------- --------------------
bgpHostname hostname spine-01
evpnVni vni 42
overTemp new_s_crit 24
svcStatus new_status down
switchLeaf04 hostname leaf04
sysconf configdiff updated
Delete an Event Notification Filter
To delete a filter, use the following command, then verify it has been
removed:
cumulus@switch:~$ netq del notification filter bgpSpine
cumulus@switch:~$ netq show notification filter
Matching config_notify records:
Name Order Severity Channels Rules
--------------- ---------- ---------------- ---------------- ----------
swp52Drop 1 error NetqDefaultChann swp52
el
vni42 2 warning pd-netq-events evpnVni
configChange 3 info slk-netq-events sysconf
svcDown 4 critical slk-netq-events svcStatus
critTemp 5 critical pd-netq-events switchLeaf
04
overTemp
Configure Threshold-based Event Notifications
NetQ supports a set of events that are triggered by crossing a user-defined threshold, called TCA events. These events allow detection and prevention of network failures for selected interface, utilization, sensor, forwarding, and ACL events.
The simplest configuration you can create is one that sends a TCA event generated by all devices and all interfaces to a single notification application. Use the netq add tca command to configure the event. Its syntax is:
A notification configuration must contain one rule. Each rule must contain a scope and a threshold. Optionally, you can specify an associated channel. Note: If a rule is not associated with a channel, the event information is only reachable from the database. If you want to deliver events to one or more notification channels (syslog, Slack, or PagerDuty), create them by following the instructions in Create Your Channel, and then return here to define your rule.
Supported Events
The following events are supported:
Category
Event ID
Description
Interface Statistics
TCA_RXBROADCAST_UPPER
rx_broadcast bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_RXBYTES_UPPER
rx_bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_RXMULTICAST_UPPER
rx_multicast per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXBROADCAST_UPPER
tx_broadcast bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXBYTES_UPPER
tx_bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXMULTICAST_UPPER
tx_multicast bytes per second on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_CPU_UTILIZATION_UPPER
CPU utilization (%) on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_DISK_UTILIZATION_UPPER
Disk utilization (%) on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_MEMORY_UTILIZATION_UPPER
Memory utilization (%) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_FAN_UPPER
Switch sensor reported fan speed on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_POWER_UPPER
Switch sensor reported power (Watts) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_TEMPERATURE_UPPER
Switch sensor reported temperature (°C) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_VOLTAGE_UPPER
Switch sensor reported voltage (Volts) on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_TOTAL_ROUTE_ENTRIES_UPPER
Number of routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_TOTAL_MCAST_ROUTES_UPPER
Number of multicast routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_MAC_ENTRIES_UPPER
Number of MAC addresses on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV4_ROUTE_UPPER
Number of IPv4 routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV4_HOST_UPPER
Number of IPv4 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV6_ROUTE_UPPER
Number of IPv6 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV6_HOST_UPPER
Number of IPv6 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_ECMP_NEXTHOPS_UPPER
Number of equal cost multi-path (ECMP) next hop entries on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V4_FILTER_UPPER
Number of ingress ACL filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V4_FILTER_UPPER
Number of egress ACL filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V4_MANGLE_UPPER
Number of ingress ACL mangles for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V4_MANGLE_UPPER
Number of egress ACL mangles for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V6_FILTER_UPPER
Number of ingress ACL filters for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V6_FILTER_UPPER
Number of egress ACL filters for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V6_MANGLE_UPPER
Number of ingress ACL mangles for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V6_MANGLE_UPPER
Number of egress ACL mangles for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_8021x_FILTER_UPPER
Number of ingress ACL 802.1 filters on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_L4_PORT_CHECKERS_UPPER
Number of ACL port range checkers on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_REGIONS_UPPER
Number of ACL regions on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_MIRROR_UPPER
Number of ingress ACL mirrors on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_18B_RULES_UPPER
Number of ACL 18B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_32B_RULES_UPPER
Number of ACL 32B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_54B_RULES_UPPER
Number of ACL 54B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_PBR_V4_FILTER_UPPER
Number of ingress policy-based routing (PBR) filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_PBR_V6_FILTER_UPPER
Number of ingress policy-based routing (PBR) filters for IPv6 addresses on a given switch or host is greater than maximum threshold
Define a Scope
A scope is used to filter the events generated by a given rule. Scope values are set on a per TCA rule basis. All rules can be filtered on Hostname. Some rules can also be filtered by other parameters, as shown in this table. Note: Scope parameters must be entered in the order defined.
Category
Event ID
Scope Parameters
Interface Statistics
TCA_RXBROADCAST_UPPER
Hostname, Interface
Interface Statistics
TCA_RXBYTES_UPPER
Hostname, Interface
Interface Statistics
TCA_RXMULTICAST_UPPER
Hostname, Interface
Interface Statistics
TCA_TXBROADCAST_UPPER
Hostname, Interface
Interface Statistics
TCA_TXBYTES_UPPER
Hostname, Interface
Interface Statistics
TCA_TXMULTICAST_UPPER
Hostname, Interface
Resource Utilization
TCA_CPU_UTILIZATION_UPPER
Hostname
Resource Utilization
TCA_DISK_UTILIZATION_UPPER
Hostname
Resource Utilization
TCA_MEMORY_UTILIZATION_UPPER
Hostname
Sensors
TCA_SENSOR_FAN_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_POWER_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_TEMPERATURE_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_VOLTAGE_UPPER
Hostname, Sensor Name
Forwarding Resources
TCA_TCAM_TOTAL_ROUTE_ENTRIES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_TOTAL_MCAST_ROUTES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_MAC_ENTRIES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_ECMP_NEXTHOPS_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV4_ROUTE_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV4_HOST_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV6_ROUTE_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV6_HOST_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V4_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V4_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V6_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V6_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V6_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V6_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_8021x_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_L4_PORT_CHECKERS_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_REGIONS_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_MIRROR_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_18B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_32B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_54B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_PBR_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_PBR_V6_FILTER_UPPER
Hostname
Scopes are defined with regular expressions, as follows. When two paramaters are used, they are separated by a comma, but no space. When as asterisk (*) is used alone, it must be entered inside either single or double quotes. Single quotes are used here.
Parameters
Scope Value
Example
Result
Hostname
<hostname>
leaf01
Deliver events for the specified device
Hostname
<partial-hostname>*
leaf*
Deliver events for devices with hostnames starting with specified text (leaf)
Hostname
'*'
'*'
Deliver events for all devices
Hostname, Interface
<hostname>,<interface>
leaf01,swp9
Deliver events for the specified interface (swp9) on the specified device (leaf01)
Hostname, Interface
<hostname>,'*'
leaf01,'*'
Deliver events for all interfaces on the specified device (leaf01)
Hostname, Interface
'*',<interface>
'*',swp9
Deliver events for the specified interface (swp9) on all devices
Hostname, Interface
'*','*'
'*','*'
Deliver events for all devices and all interfaces
Hostname, Interface
<partial-hostname>*,<interface>
leaf*,swp9
Deliver events for the specified interface (swp9) on all devices with hostnames starting with the specified text (leaf)
Hostname, Interface
<hostname>,<partial-interface>*
leaf01,swp*
Deliver events for all interface with names starting with the specified text (swp) on the specified device (leaf01)
Hostname, Sensor Name
<hostname>,<sensorname>
leaf01,fan1
Deliver events for the specified sensor (fan1) on the specified device (leaf01)
Hostname, Sensor Name
'*',<sensorname>
'*',fan1
Deliver events for the specified sensor (fan1) for all devices
Hostname, Sensor Name
<hostname>,'*'
leaf01,'*'
Deliver events for all sensors on the specified device (leaf01)
Hostname, Sensor Name
<partial-hostname>*,<interface>
leaf*,fan1
Deliver events for the specified sensor (fan1) on all devices with hostnames starting with the specified text (leaf)
Hostname, Sensor Name
<hostname>,<partial-sensorname>*
leaf01,fan*
Deliver events for all sensors with names starting with the specified text (fan) on the specified device (leaf01)
Hostname, Sensor Name
'*','*'
'*','*'
Deliver events for all sensors on all devices
Create a TCA Rule
Now that you know which events are supported and how to set the scope, you can create a basic rule to deliver one of the TCA events to a notification channel using the netq add tca command. Note that the event ID is case sensitive and must be in all caps.
For example, this rule tells NetQ to deliver an event notification to the tca_slack_ifstats pre-configured Slack channel when the CPU utilization exceeds 95% of its capacity on any monitored switch:
This rule tells NetQ to deliver an event notification to the tca_pd_ifstats PagerDuty channel when the number of transmit bytes per second (Bps) on the leaf12 switch exceeds 20,000 Bps on any interface:
This rule tells NetQ to deliver an event notification to the syslog-netq syslog channel when the temperature on sensor temp1 on the leaf12 switch exceeds 32 degrees Celcius:
For a Slack channel, the event messages should be similar to this:
Set the Severity of a Threshold-based Event
In addition to defining a scope for TCA rule, you can also set a severity of either info or critical. To add a severity to a rule, use the severity option.
For example, if you want add a critical severity to the CPU utilization rule you created earlier:
Now you have four rules created (the original one, plus these three new ones) all based on the TCA_SENSOR_TEMPERATURE_UPPER event. To identify the various rules, NetQ automatically generates a TCA name for each rule. As each rule is created, an _# is added to the event name. The TCA Name for the first rule created is then TCA_SENSOR_TEMPERATURE_UPPER_1, the second rule created for this event is TCA_SENSOR_TEMPERATURE_UPPER_2, and so forth.
Suppress a Rule
During troubleshooting or maintenance of switches you may want to suppress a rule to prevent erroneous event messages. Using the suppress_until option allows you to prevent the rule from being applied for a designated amout of time (in seconds). When this time has passed, the rule is automatically reenabled.
For example, to suppress the disk utilization event for an hour:
Once you have created a bunch of rules, you might to manage them; view a list of the rules, disable a rule, delete a rule, and so forth.
Show Threshold-based Event Rules
You can view all TCA rules or a particular rule using the netq show tca command:
Example 1: Display All TCA Rules
cumulus@switch:~$ netq show tca
Matching config_tca records:
TCA Name Event Name Scope Severity Channel/s Active Threshold Suppress Until
---------------------------- -------------------- -------------------------- ---------------- ------------------ ------ ------------------ ----------------------------
TCA_CPU_UTILIZATION_UPPER_1 TCA_CPU_UTILIZATION_ {"hostname":"leaf01"} critical tca_slack_resource True 1 Sun Dec 8 14:17:18 2019
UPPER s
TCA_DISK_UTILIZATION_UPPER_1 TCA_DISK_UTILIZATION {"hostname":"leaf01"} info False 80 Mon Dec 9 05:03:46 2019
_UPPER
TCA_MEMORY_UTILIZATION_UPPER TCA_MEMORY_UTILIZATI {"hostname":"leaf01"} info tca_slack_resource True 1 Sun Dec 8 11:53:15 2019
_1 ON_UPPER s
TCA_RXBYTES_UPPER_1 TCA_RXBYTES_UPPER {"ifname":"swp3","hostname info tca-tx-bytes-slack True 100 Sun Dec 8 17:22:52 2019
":"leaf01"}
TCA_RXMULTICAST_UPPER_1 TCA_RXMULTICAST_UPPE {"ifname":"swp3","hostname info tca-tx-bytes-slack True 0 Sun Dec 8 10:43:57 2019
R ":"leaf01"}
TCA_SENSOR_FAN_UPPER_1 TCA_SENSOR_FAN_UPPER {"hostname":"leaf01","s_na info tca_slack_sensors True 0 Sun Dec 8 12:30:14 2019
me":"*"}
TCA_SENSOR_TEMPERATURE_UPPER TCA_SENSOR_TEMPERATU {"hostname":"leaf01","s_na critical tca_slack_sensors True 10 Sun Dec 8 14:05:24 2019
_1 RE_UPPER me":"*"}
TCA_TXBYTES_UPPER_1 TCA_TXBYTES_UPPER {"ifname":"swp3","hostname critical tca-tx-bytes-slack True 100 Sun Dec 8 14:19:46 2019
":"leaf01"}
TCA_TXMULTICAST_UPPER_1 TCA_TXMULTICAST_UPPE {"ifname":"swp3","hostname info tca-tx-bytes-slack True 0 Sun Dec 8 16:40:14 2269
R ":"leaf01"}
Example 2: Display a Specific TCA Rule
cumulus@switch:~$ netq show tca tca_id TCA_TXMULTICAST_UPPER_1
Matching config_tca records:
TCA Name Event Name Scope Severity Channel/s Active Threshold Suppress Until
---------------------------- -------------------- -------------------------- ---------------- ------------------ ------ ------------------ ----------------------------
TCA_TXMULTICAST_UPPER_1 TCA_TXMULTICAST_UPPE {"ifname":"swp3","hostname info tca-tx-bytes-slack True 0 Sun Dec 8 16:40:14 2269
R ":"leaf01"}
Disable a TCA Rule
Where the suppress option temporarily disables a TCA rule, you can use the is_active option to disable a rule indefinitely. To disable a rule, set the option to false. To reenable it, set the option to true.
If disabling a rule is not sufficient, and you want to remove a rule altogether, you can do so using the netq del tca command.
cumulus@switch:~$ netq del tca tca_id TCA_RXBYTES_UPPER_1
Successfully deleted TCA TCA_RXBYTES_UPPER_1
Resolve Scope Conflicts
There may be occasions where the scope defined by the multiple rules for a given TCA event may overlap each other. In such cases, the TCA rule with the most specific scope that is still true is used to generate the event.
To clarify this, consider this example. Three events have occurred:
First event on switch leaf01, interface swp1
Second event on switch leaf01, interface swp3
Third event on switch spine01, interface swp1
NetQ attempts to match the TCA event against hostname and interface name with three TCA rules with different scopes:
Scope 1 send events for the swp1 interface on switch leaf01 (very specific)
Scope 2 send events for all interfaces on switches that start with leaf (moderately specific)
Scope 3 send events for all switches and interfaces (very broad)
The result is:
For the first event, NetQ applies the scope from rule 1 because it matches scope 1 exactly
For the second event, NetQ applies the scope from rule 2 because it does not match scope 1, but does match scope 2
For the third event, NetQ applies the scope from rule 3 because it does not match either scope 1 or scope 2
In summary:
Input Event
Scope Parameters
TCA Scope 1
TCA Scope 2
TCA Scope 3
Scope Applied
leaf01,swp1
Hostname, Interface
'*','*'
leaf*,'*'
leaf01,swp1
Scope 3
leaf01,swp3
Hostname, Interface
'*','*'
leaf*,'*'
leaf01,swp1
Scope 2
spine01,swp1
Hostname, Interface
'*','*'
leaf*,'*'
leaf01,swp1
Scope 1
Integrate NetQ with Your LDAP Server
With this release and an administrator role, you are able to integrate the NetQ role-based access control (RBAC) with your lightweight directory access protocol (LDAP) server in on-premises deployments. NetQ maintains control over role-based permissions for the NetQ application. Currently there are two roles, admin and user. With the integration, user authentication is handled through LDAP and your directory service, such as Microsoft Active Directory, Kerberos, OpenLDAP, and Red Hat Directory Service. A copy of each user from LDAP is stored in the local NetQ database.
Integrating with an LDAP server does not prevent you from configuring local users (stored and managed in the NetQ database) as well.
Read the Overview to become familiar with LDAP configuration parameters, or skip to Create an LDAP Configuration if you are already an LDAP expert.
Overview
LDAP integration requires information about how to connect to your LDAP server, the type of authentication you plan to use, bind credentials, and, optionally, search attributes.
Provide Your LDAP Server Information
To connect to your LDAP server, you need the URI and bind credentials. The URI identifies the location of the LDAP server. It is comprised of a FQDN (fully qualified domain name) or IP address, and the port of the LDAP server where the LDAP client can connect. For example: myldap.mycompany.com or 192.168.10.2. Typically port 389 is used for connection over TCP or UDP. In production environments, a secure connection with SSL can be deployed. In this case, the port used is typically 636. Setting the Enable SSL toggle automatically sets the server port to 636.
Specify Your Authentication Method
Two methods of user authentication are available: anonymous and basic.
Anonymous: LDAP client does not require any authentication. The user can access all resources anonymously. This is not commonly used for production environments.
Basic: (Also called Simple) LDAP client must provide a bind DN and password to authenticate the connection. When selected, the Admin credentials appear: Bind DN and Bind Password. The distinguished name (DN) is defined using a string of variables. Some common variables include:
Syntax
Description or Usage
cn
common name
ou
organizational unit or group
dc
domain name
dc
domain extension
Bind DN: DN of user with administrator access to query the LDAP server; used for binding with the server. For example, uid =admin,ou=ntwkops,dc=mycompany,dc=com.
Bind Password: Password associated with Bind DN.
The Bind DN and password are sent as clear text. Only users with these credentials are allowed to perform LDAP operations.
If you are unfamiliar with the configuration of your LDAP server, contact your administrator to ensure you select the appropriate authentication method and credentials.
Define User Attributes
Two attributes are required to define a user entry in a directory:
Base DN: Location in directory structure where search begins. For example, dc=mycompany,dc=com
User ID: Type of identifier used to specify an LDAP user. This can vary depending on the authentication service you are using. For example, user ID (UID) or email address can be used with OpenLDAP, whereas sAMAccountName might be used with Active Directory.
Optionally, you can specify the first name, last name, and email address of the user.
Set Search Attributes
While optional, specifying search scope indicates where to start and how deep a given user can search within the directory. The data to search for is specified in the search query.
Search scope options include:
Subtree: Search for users from base, subordinates at any depth (default)
Base: Search for users at the base level only; no subordinates
One Level: Search for immediate children of user; not at base or for any descendants
Subordinate: Search for subordinates at any depth of user; but not at base
A typical search query for users would be {userIdAttribute}={userId}.
Now that you are familiar with the various LDAP configuration parameters, you can configure the integration of your LDAP server with NetQ using the instructions in the next section.
Create an LDAP Configuration
One LDAP server can be configured per bind DN (distinguished name). Once LDAP is configured, you can validate the connectivity (and configuration) and save the configuration.
To create an LDAP configuration:
Click , then select Management under Admin.
Locate the LDAP Server Info card, and click Configure LDAP.
Fill out the LDAP Server Configuration form according to your particular configuration. Refer to Overview for details about the various parameters.
Note: Items with an asterisk (*) are required. All others are optional.
Click Save to complete the configuration, or click Cancel to discard the configuration.
LDAP config cannot be changed once configured. If you need to change the configuration, you must delete the current LDAP configuration and create a new one. Note that if you change the LDAP server configuration, all users created against that LDAP server remain in the NetQ database and continue to be visible, but are no longer viable. You must manually delete those users if you do not want to see them.
Example LDAP Configurations
A variety of example configurations are provided here. Scenarios 1-3 are based on using an OpenLDAP or similar authentication service. Scenario 4 is based on using the Active Directory service for authentication.
Scenario 1: Base Configuration
In this scenario, we are configuring the LDAP server with anonymous authentication, a User ID based on an email address, and a search scope of base.
Parameter
Value
Host Server URL
ldap1.mycompany.com
Host Server Port
389
Authentication
Anonymous
Base DN
dc=mycompany,dc=com
User ID
email
Search Scope
Base
Search Query
{userIdAttribute}={userId}
Scenario 2: Basic Authentication and Subset of Users
In this scenario, we are configuring the LDAP server with basic authentication, for access only by the persons in the network operators group, and a limited search scope.
Parameter
Value
Host Server URL
ldap1.mycompany.com
Host Server Port
389
Authentication
Basic
Admin Bind DN
uid =admin,ou=netops,dc=mycompany,dc=com
Admin Bind Password
nqldap!
Base DN
dc=mycompany,dc=com
User ID
UID
Search Scope
One Level
Search Query
{userIdAttribute}={userId}
Scenario 3: Scenario 2 with Widest Search Capability
In this scenario, we are configuring the LDAP server with basic authentication, for access only by the persons in the network administrators group, and an unlimited search scope.
Parameter
Value
Host Server URL
192.168.10.2
Host Server Port
389
Authentication
Basic
Admin Bind DN
uid =admin,ou=netadmin,dc=mycompany,dc=com
Admin Bind Password
1dap*netq
Base DN
dc=mycompany, dc=net
User ID
UID
Search Scope
Subtree
Search Query
userIdAttribute}={userId}
Scenario 4: Scenario 3 with Active Directory Service
In this scenario, we are configuring the LDAP server with basic authentication, for access only by the persons in the given Active Directory group, and an unlimited search scope.
Parameter
Value
Host Server URL
192.168.10.2
Host Server Port
389
Authentication
Basic
Admin Bind DN
cn=netq,ou=45,dc=mycompany,dc=com
Admin Bind Password
nq&4mAd!
Base DN
dc=mycompany, dc=net
User ID
sAMAccountName
Search Scope
Subtree
Search Query
{userIdAttribute}={userId}
Add LDAP Users to NetQ
Click , then select Management under Admin.
Locate the User Accounts card, and click Manage.
On the User Accounts tab, click Add User.
Select LDAP User.
Enter the user’s ID.
Enter your administrator password.
Click Search.
If the user is found, the email address, first and last name fields are automatically filled in on the Add New User form. If searching is not enabled on the LDAP server, you must enter the information manually.
If the fields are not automatically filled in, and searching is enabled on the LDAP server, you might require changes to the mapping file.
Select the NetQ user role for this user, admin or user, in the User Type dropdown.
Enter your admin password, and click Save, or click Cancel to discard the user account.
LDAP user passwords are not stored in the NetQ database and are always authenticated against LDAP.
Repeat these steps to add additional LDAP users.
Remove LDAP Users from NetQ
You can remove LDAP users in the same manner as local users.
Click , then select Management under Admin.
Locate the User Accounts card, and click Manage.
Select the user or users you want to remove.
Click in the Edit menu.
If an LDAP user is deleted in LDAP it is not automatically deleted from NetQ; however, the login credentials for these LDAP users stop working immediately.
Integrate NetQ with Grafana
Switches collect statistics about the performance of their interfaces. The NetQ Agent on each switch collects these statistics every 15 seconds and then sends them to your NetQ Server or Appliance.
NetQ only collects statistics for physical interfaces; it does not collect statistics for virtual (non-physical) interfaces, such as bonds, bridges, and VXLANs. Specifically, the NetQ Agent collects the following interface statistics:
You can use Grafana version 6.x, an open source analytics and monitoring tool, to view these statistics. The fastest way to achieve this is by installing Grafana on an application server or locally per user, and then installing the NetQ plugin.
If you do not have Grafana installed already, refer to grafana.com for instructions on installing and configuring the Grafana tool.
Install NetQ Plugin for Grafana
Use the Grafana CLI to install the NetQ plugin. For more detail about this command, refer to the Grafana CLI documentation.
Cumulus in the Cloud (CITC): air.netq.cumulusnetworks.com
Enter your credentials (the ones used to login)
For cloud deployments only, if you have more than one premises configured, you can select the premises you want to view, as follows:
If you leave the Premises field blank, the first premises name is selected by default
If you enter a premises name, that premises is selected for viewing
Note: If multiple premises are configured with the same name, then the first premises of that name is selected for viewing
Click Save & Test
Create Your NetQ Dashboard
With the data source configured, you can create a dashboard with the transmit and receive statistics of interest to you.
To create your dashboard:
Click to open a blank dashboard.
Click (Dashboard Settings) at the top of the dashboard.
Click Variables.
Enter hostname into the Name field.
Enter Hostname into the Label field.
Select Net-Q from the Data source list.
Enter hostname into the Query field.
Click Add.
You should see a preview at the bottom of the hostname values.
Click to return to the new dashboard.
Click Add Query.
Select Net-Q from the Query source list.
Select the interface statistic you want to view from the Metric list.
Click the General icon.
Select hostname from the Repeat list.
Set any other parameters around how to display the data.
Return to the dashboard.
Add additional panels with other metrics to complete your dashboard.
Analyze the Data
data.
For reference, this example shows a dashboard with all of the available statistics.
Select the hostname from the variable list at the top left of the charts to see the statistics for that switch or host.
Review the statistics, looking for peaks and valleys, unusual patterns, and so forth.
Explore the data more by modifying the data view in one of several ways using the dashboard tool set:
Select a different time period for the data by clicking the forward or back arrows. The default time range is dependent on the width of your browser window.
Zoom in on the dashboard by clicking the magnifying glass.
Manually refresh the dashboard data, or set an automatic refresh rate for the dashboard from the down arrow.
Add a new variable by clicking the cog wheel, then selecting Variables
Add additional panels
Click any chart title to edit or remove it from the dashboard
Rename the dashboard by clicking the cog wheel and entering the new name
Cumulus NetQ API User Guide
The NetQ API provides access to key telemetry and system monitoring data
gathered about the performance and operation of your data center network
and devices so that you can view that data in your internal or
third-party analytic tools. The API gives you access to the health of
individual switches, network protocols and services, and views of
network-wide inventory and events.
This guide provides an overview of the API framework and some examples
of how to use the API to extract the data you need. Descriptions of each
endpoint and model parameter are contained in the API .json files.
For information regarding new features, improvements, bug fixes, and
known issues present in this release, refer to the
release notes.
Copy the access token for use in making data requests.
API Requests
We will use curl to execute our requests. Each request contains an API
method (GET, POST, etc.), the address and API object to query, a variety
of headers, and sometimes a body. In the log in step you used above:
API method = POST
Address and API object = “https://<netq.domain>:32708/netq/auth/v1/login”
Headers = -H “Content-Type: application/json”
Body = -d ‘{“username”:“admin”,“password”:“admin”}’
We have used the insecure option to work around any certificate issues
with our development configuration. You would likely not use this
option.
API Responses
A NetQ API response is comprised of a status code, any relevant error
codes (if unsuccessful), and the collected data (if successful).
The following HTTP status codes might be presented in the API responses:
Code
Name
Description
Action
200
Success
Request was successfully processed.
Review response
400
Bad Request
Invalid input was detected in request.
Check the syntax of your request and make sure it matches the schema
401
Unauthorized
Authentication has failed or credentials were not provided.
Provide or verify your credentials, or request access from your administrator
403
Forbidden
Request was valid, but user may not have needed permissions.
Verify your credentials or request an account from your administrator
404
Not Found
Requested resource could not be found.
Try the request again after a period of time or verify status of resource
409
Conflict
Request cannot be processed due to conflict in current state of the resource.
Verify status of resource and remove conflict
500
Internal Server Error
Unexpected condition has occurred.
Perform general troubleshooting and try the request again
503
Service Unavailable
The service being requested is currently unavailable.
Verify the status of the NetQ Platform or Appliance, and the associated service
Example Requests and Responses
Some command requests and their responses are shown here, but feel free
to run your own requests. To run a request, you will need your
authorization token. We have piped our responses through a python tool
to make the responses more readable. You may chose to do so as well or
not.
To view all of the endpoints and their associated requests and
responses, refer to Cumulus NetQ API User Guide.
Get Network-wide Status of the BGP Service
Make your request to the bgp endpoint to obtain status information
from all nodes running the BGP service, as follows:
Make your request to the interfaces endpoint to view the status of all
interfaces. By specifying the eq-timestamp option and entering a date
and time in epoch format, you indicate the data for that time (versus in
the last hour by default), as follows:
For simplicity, all of the endpoint APIs are combined into a single
json-formatted file. There have been no changes to the file in the NetQ 3.0.0 release.
▼
netq-300.json
{
"swagger": "2.0",
"info": {
"description": "This API is used to gain access to data collected by the Cumulus NetQ Platform and Agents for integration with third-party monitoring and analytics software. Integrators can pull data for daily monitoring of network protocols and services performance, inventory status, and system-wide events.",
"version": "1.1",
"title": "Cumulus NetQ 3.0.0 API",
"termsOfService": "https://cumulusnetworks.com/legal/"
},
"host": "<netq-platform-or-appliance-ipaddress>:32708",
"basePath": "/netq/telemetry/v1",
"externalDocs": {
"description": "API Documentation",
"url": "https://docs.nvidia.com/networking-ethernet-software/cumulus-netq/Cumulus-NetQ-Integration-Guide/API-User-Guide/"
},
"schemes": [
"https"
],
"paths": {
"/object/address": {
"get": {
"tags": [
"address"
],
"summary": "Get all addresses for all network devices",
"description": "Retrieves all IPv4, IPv6 and MAC addresses deployed on switches and hosts in your network running NetQ Agents.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Address"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/address/hostname/{hostname}": {
"get": {
"tags": [
"address"
],
"summary": "Get all addresses for a given network device by hostname",
"description": "Retrieves IPv4, IPv6, and MAC addresses of a network device (switch or host) specified by its hostname.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Address"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/login": {
"post": {
"tags": [
"auth"
],
"summary": "Perform authenticated user login to NetQ",
"description": "Sends user-provided login credentials (username and password) to the NetQ Authorization service for validation. Grants access to the NetQ platform and software if user credentials are valid.",
"operationId": "login",
"produces": [
"application/json"
],
"parameters": [
{
"in": "body",
"name": "body",
"description": "User credentials provided for login request; username and password.",
"required": true,
"schema": {
"$ref": "#/definitions/LoginRequest"
}
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"$ref": "#/definitions/LoginResponse"
}
},
"401": {
"description": "Invalid credentials",
"schema": {
"$ref": "#/definitions/ErrorResponse"
}
}
}
}
},
"/object/bgp": {
"get": {
"tags": [
"bgp"
],
"summary": "Get all BGP session information for all network devices",
"description": "For every Border Gateway Protocol (BGP) session running on the network, retrieves local node hostname, remote peer hostname, interface, router ID, and ASN, timestamp, VRF, connection state, IP and EVPN prefixes, and so forth. Refer to the BGPSession model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/BgpSession"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/bgp/hostname/{hostname}": {
"get": {
"tags": [
"bgp"
],
"summary": "Get all BGP session information for a given network device by hostname",
"description": "For every BGP session running on the network device, retrieves local node hostname, remote peer hostname, interface, router ID, and ASN, timestamp, VRF, connection state, IP and EVPN prefixes, and so forth. Refer to the BGPSession model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/BgpSession"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/clag": {
"get": {
"tags": [
"clag"
],
"summary": "Get all CLAG session information for all network devices",
"description": "For every Cumulus multiple Link Aggregation (CLAG) session running on the network, retrieves local node hostname, CLAG sysmac, remote peer role, state, and interface, backup IP address, bond status, and so forth. Refer to the ClagSessionInfo model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/ClagSessionInfo"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/clag/hostname/{hostname}": {
"get": {
"tags": [
"clag"
],
"summary": "Get all CLAG session information for a given network device by hostname",
"description": "For every CLAG session running on the network device, retrieves local node hostname, CLAG sysmac, remote peer role, state, and interface, backup IP address, bond status, and so forth. Refer to the ClagSessionInfo model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/ClagSessionInfo"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/events": {
"get": {
"tags": [
"events"
],
"summary": "Get all events from across the entire network",
"description": "Retrieves all alarm (critical severity) and informational (warning, info and debug severity) events from all network devices and services.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "gt_timestamp",
"in": "query",
"description": "Used in combination with lt_timestamp, sets the lower limit of the time range to display. Uses Epoch format. Cannot be used with eq_timestamp. For example, to display events between Monday February 11, 2019 at 1:00am and Tuesday February 12, 2019 at 1:00am, lt_timestamp would be entered as 1549864800 and gt_timestamp would be entered as 1549951200.",
"required": false,
"type": "integer"
},
{
"name": "lt_timestamp",
"in": "query",
"description": "Used in combination with gt_timestamp, sets the upper limit of the time range to display. Uses Epoch format. Cannot be used with eq_timestamp. For example, to display events between Monday February 11, 2019 at 1:00am and Tuesday February 12, 2019 at 1:00am, lt_timestamp would be entered as 1549864800 and gt_timestamp would be entered as 1549951200.",
"required": false,
"type": "integer"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"type": "string"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/evpn": {
"get": {
"tags": [
"evpn"
],
"summary": "Get all EVPN session information from across the entire network",
"description": "For every Ethernet Virtual Private Network (EVPN) session running on the network, retrieves hostname, VNI status, origin IP address, timestamp, export and import routes, and so forth. Refer to the Evpn model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Evpn"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/evpn/hostname/{hostname}": {
"get": {
"tags": [
"evpn"
],
"summary": "Get all EVPN session information from a given network device by hostname",
"description": "For every EVPN session running on the network device, retrieves hostname, VNI status, origin IP address, timestamp, export and import routes, and so forth. Refer to the Evpn model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Evpn"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/interface": {
"get": {
"tags": [
"interface"
],
"summary": "Get software interface information for all network devices",
"description": "Retrieves information about all software interfaces, including type and name of the interfaces, the hostnames of the device where they reside, state, VRF, and so forth. Refer to the Interface model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Interface"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/interface/hostname/{hostname}": {
"get": {
"tags": [
"interface"
],
"summary": "Get software interface information for a given network device by hostname",
"description": "Retrieves information about all software interfaces on a network device, including type and name of the interfaces, state, VRF, and so forth. Refer to the Interface model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Interface"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/inventory": {
"get": {
"tags": [
"inventory"
],
"summary": "Get component inventory information from all network devices",
"description": "Retrieves the hardware and software component information, such as ASIC, platform, and OS vendor and version information, for all switches and hosts in your network. Refer to the InventoryOutput model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"$ref": "#/definitions/InventoryOutput"
}
},
"400": {
"description": "Invalid Input"
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/inventory/hostname/{hostname}": {
"get": {
"tags": [
"inventory"
],
"summary": "Get component inventory information from a given network device by hostname",
"description": "Retrieves the hardware and software component information, such as ASIC, platform, and OS vendor and version information, for the given switch or host in your network. Refer to the InventoryOutput model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"$ref": "#/definitions/InventoryOutput"
}
},
"400": {
"description": "Invalid Input"
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/lldp": {
"get": {
"tags": [
"lldp"
],
"summary": "Get LLDP information for all network devices",
"description": "Retrieves Link Layer Discovery Protocol (LLDP) information, such as hostname, interface name, peer hostname, interface name, bridge, router, OS, timestamp, for all switches and hosts in the network. Refer to the LLDP model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/LLDP"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/lldp/hostname/{hostname}": {
"get": {
"tags": [
"lldp"
],
"summary": "Get LLDP information for a given network device by hostname",
"description": "Retrieves Link Layer Discovery Protocol (LLDP) information, such as hostname, interface name, peer hostname, interface name, bridge, router, OS, timestamp, for the given switch or host. Refer to the LLDP model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/LLDP"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/macfdb": {
"get": {
"tags": [
"macfdb"
],
"summary": "Get all MAC FDB information for all network devices",
"description": "Retrieves all MAC address forwarding database (MACFDB) information for all switches and hosts in the network, such as MAC address, timestamp, next hop, destination, port, and VLAN. Refer to MacFdb model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/MacFdb"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/macfdb/hostname/{hostname}": {
"get": {
"tags": [
"macfdb"
],
"summary": "Get all MAC FDB information for a given network device by hostname",
"description": "Retrieves all MAC address forwarding database (MACFDB) information for a given switch or host in the network, such as MAC address, timestamp, next hop, destination, port, and VLAN. Refer to MacFdb model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/MacFdb"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/mstp": {
"get": {
"tags": [
"mstp"
],
"summary": "Get all MSTP information from all network devices",
"description": "Retrieves all Multiple Spanning Tree Protocol (MSTP) information, including bridge and port information, changes made to topology, and so forth for all switches and hosts in the network. Refer to MstpInfo model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/MstpInfo"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/mstp/hostname/{hostname}": {
"get": {
"tags": [
"mstp"
],
"summary": "Get all MSTP information from a given network device by hostname",
"description": "Retrieves all MSTP information, including bridge and port information, changes made to topology, and so forth for a given switch or host in the network. Refer to MstpInfo model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/MstpInfo"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/neighbor": {
"get": {
"tags": [
"neighbor"
],
"summary": "Get neighbor information for all network devices",
"description": "Retrieves neighbor information, such as hostname, addresses, VRF, interface name and index, for all switches and hosts in the network. Refer to Neighbor model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Neighbor"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/neighbor/hostname/{hostname}": {
"get": {
"tags": [
"neighbor"
],
"summary": "Get neighbor information for a given network device by hostname",
"description": "Retrieves neighbor information, such as hostname, addresses, VRF, interface name and index, for a given switch or host in the network. Refer to Neighbor model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Neighbor"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/node": {
"get": {
"tags": [
"node"
],
"summary": "Get device status for all network devices",
"description": "Retrieves hostname, uptime, last update, boot and re-initialization time, version, NTP and DB state, timestamp, and its current state (active or not) for all switches and hosts in the network.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/NODE"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/node/hostname/{hostname}": {
"get": {
"tags": [
"node"
],
"summary": "Get device status for a given network device by hostname",
"description": "Retrieves hostname, uptime, last update, boot and re-initialization time, version, NTP and DB state, timestamp, and its current state (active or not) for a given switch or host in the network.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/NODE"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/ntp": {
"get": {
"tags": [
"ntp"
],
"summary": "Get all NTP information for all network devices",
"description": "Retrieves all Network Time Protocol (NTP) configuration and status information, such as whether the service is running and if it is in time synchronization, for all switches and hosts in the network. Refer to the NTP model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/NTP"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/ntp/hostname/{hostname}": {
"get": {
"tags": [
"ntp"
],
"summary": "Get all NTP information for a given network device by hostname",
"description": "Retrieves all Network Time Protocol (NTP) configuration and status information, such as whether the service is running and if it is in time synchronization, for a given switch or host in the network. Refer to the NTP model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/NTP"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/port": {
"get": {
"tags": [
"port"
],
"summary": "Get all information for all physical ports on all network devices",
"description": "Retrieves all physical port information, such as speed, connector, vendor, part and serial number, and FEC support, for all network devices. Refer to Port model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Port"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/port/hostname/{hostname}": {
"get": {
"tags": [
"port"
],
"summary": "Get all information for all physical ports on a given network device by hostname",
"description": "Retrieves all physical port information, such as speed, connector, vendor, part and serial number, and FEC support, for a given switch or host in the network. Refer to Port model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Port"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/route": {
"get": {
"tags": [
"route"
],
"summary": "Get all route information for all network devices",
"description": "Retrieves route information, such as VRF, source, next hops, origin, protocol, and prefix, for all switches and hosts in the network. Refer to Route model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Route"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/route/hostname/{hostname}": {
"get": {
"tags": [
"route"
],
"summary": "Get all route information for a given network device by hostname",
"description": "Retrieves route information, such as VRF, source, next hops, origin, protocol, and prefix, for a given switch or host in the network. Refer to Route model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Route"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/sensor": {
"get": {
"tags": [
"sensor"
],
"summary": "Get all sensor information for all network devices",
"description": "Retrieves data from fan, temperature, and power supply unit sensors, such as their name, state, and threshold status, for all switches and hosts in the network. Refer to Sensor model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Sensor"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/sensor/hostname/{hostname}": {
"get": {
"tags": [
"sensor"
],
"summary": "Get all sensor information for a given network device by hostname",
"description": "Retrieves data from fan, temperature, and power supply unit sensors, such as their name, state, and threshold status, for a given switch or host in the network. Refer to Sensor model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Sensor"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/services": {
"get": {
"tags": [
"services"
],
"summary": "Get all services information for all network devices",
"description": "Retrieves services information, such as XXX, for all switches and hosts in the network. Refer to Services for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Services"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/services/hostname/{hostname}": {
"get": {
"tags": [
"services"
],
"summary": "Get all services information for a given network device by hostname",
"description": "Retrieves services information, such as XXX, for a given switch or host in the network. Refer to Services for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Services"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/vlan": {
"get": {
"tags": [
"vlan"
],
"summary": "Get all VLAN information for all network devices",
"description": "Retrieves VLAN information, such as hostname, interface name, associated VLANs, ports, and time of last change, for all switches and hosts in the network. Refer to Vlan model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Vlan"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
},
"/object/vlan/hostname/{hostname}": {
"get": {
"tags": [
"vlan"
],
"summary": "Get all VLAN information for a given network device by hostname",
"description": "Retrieves VLAN information, such as hostname, interface name, associated VLANs, ports, and time of last change, for a given switch or host in the network. Refer to Vlan model for all data collected.",
"produces": [
"application/json"
],
"parameters": [
{
"name": "hostname",
"in": "path",
"description": "User-specified name for a network switch or host. For example, leaf01, spine04, host-6, engr-1, tor-22.",
"required": true,
"type": "string"
},
{
"name": "eq_timestamp",
"in": "query",
"description": "Display results for a given time. Time must be entered in Epoch format. For example, to display the results for Monday February 13, 2019 at 1:25 pm, use a time converter and enter 1550082300.",
"required": false,
"type": "integer"
},
{
"name": "count",
"in": "query",
"description": "Number of entries to display starting from the offset value. For example, a count of 100 displays 100 entries at a time.",
"required": false,
"type": "integer"
},
{
"name": "offset",
"in": "query",
"description": "Used in combination with count, offset specifies the starting location within the set of entries returned. For example, an offset of 100 would display results beginning with entry 101.",
"required": false,
"type": "integer"
}
],
"responses": {
"200": {
"description": "successful operation",
"schema": {
"type": "array",
"items": {
"$ref": "#/definitions/Vlan"
}
}
}
},
"security": [
{
"jwt": []
}
]
}
}
},
"securityDefinitions": {
"jwt": {
"type": "apiKey",
"name": "Authorization",
"in": "header"
}
},
"definitions": {
"Address": {
"description": "This model contains descriptions of the data collected and returned by the Address endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"ifname": {
"type": "string",
"description": "Name of a software (versus physical) interface"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"prefix": {
"type": "string",
"description": "Address prefix for IPv4, IPv6, or EVPN traffic"
},
"mask": {
"type": "integer",
"format": "int32",
"description": "Address mask for IPv4, IPv6, or EVPN traffic"
},
"is_ipv6": {
"type": "boolean",
"description": "Indicates whether address is an IPv6 address (true) or not (false)"
},
"vrf": {
"type": "string",
"description": "Virtual Route Forwarding interface name"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"BgpSession": {
"description": "This model contains descriptions of the data collected and returned by the BGP endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"peer_name": {
"type": "string",
"description": "Interface name or hostname for a peer device"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"state": {
"type": "string",
"description": "Current state of the BGP session. Values include established and not established."
},
"peer_router_id": {
"type": "string",
"description": "If peer is a router, IP address of router"
},
"peer_asn": {
"type": "integer",
"format": "int64",
"description": "Peer autonomous system number (ASN), identifier for a collection of IP networks and routers"
},
"peer_hostname": {
"type": "string",
"description": "User-defined name for the peer device"
},
"asn": {
"type": "integer",
"format": "int64",
"description": "Host autonomous system number (ASN), identifier for a collection of IP networks and routers"
},
"reason": {
"type": "string",
"description": "Text describing the cause of, or trigger for, an event"
},
"ipv4_pfx_rcvd": {
"type": "integer",
"format": "int32",
"description": "Address prefix received for an IPv4 address"
},
"ipv6_pfx_rcvd": {
"type": "integer",
"format": "int32",
"description": "Address prefix received for an IPv6 address"
},
"evpn_pfx_rcvd": {
"type": "integer",
"format": "int32",
"description": "Address prefix received for an EVPN address"
},
"last_reset_time": {
"type": "number",
"format": "float",
"description": "Date and time at which the session was last established or reset"
},
"up_time": {
"type": "number",
"format": "float",
"description": "Number of seconds the session has been established, in EPOCH notation"
},
"conn_estd": {
"type": "integer",
"format": "int32",
"description": "Number of connections established for a given session"
},
"conn_dropped": {
"type": "integer",
"format": "int32",
"description": "Number of dropped connections for a given session"
},
"upd8_rx": {
"type": "integer",
"format": "int32",
"description": "Count of protocol messages received"
},
"upd8_tx": {
"type": "integer",
"format": "int32",
"description": "Count of protocol messages transmitted"
},
"vrfid": {
"type": "integer",
"format": "int32",
"description": "Integer identifier of the VRF interface when used"
},
"vrf": {
"type": "string",
"description": "Name of the Virtual Route Forwarding interface"
},
"tx_families": {
"type": "string",
"description": "Address families supported for the transmit session channel. Values include ipv4, ipv6, and evpn."
},
"rx_families": {
"type": "string",
"description": "Address families supported for the receive session channel. Values include ipv4, ipv6, and evpn."
}
}
},
"ClagSessionInfo": {
"description": "This model contains descriptions of the data collected and returned by the CLAG endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"clag_sysmac": {
"type": "string",
"description": "Unique MAC address for each bond interface pair. This must be a value between 44:38:39:ff:00:00 and 44:38:39:ff:ff:ff."
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time the CLAG session was started, deleted, updated, or marked dead (device went down)"
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"peer_role": {
"type": "string",
"description": "Role of the peer device. Values include primary and secondary."
},
"peer_state": {
"type": "boolean",
"description": "Indicates if peer device is up (true) or down (false)"
},
"peer_if": {
"type": "string",
"description": "Name of the peer interface used for the session"
},
"backup_ip_active": {
"type": "boolean",
"description": "Indicates whether the backup IP address has been specified and is active (true) or not (false)"
},
"backup_ip": {
"type": "string",
"description": "IP address of the interface to use if the peerlink (or bond) goes down"
},
"single_bonds": {
"type": "string",
"description": "Identifies a set of interfaces connecting to only one of the two switches in the bond"
},
"dual_bonds": {
"type": "string",
"description": "Identifies a set of interfaces connecting to both switches in the bond"
},
"conflicted_bonds": {
"type": "string",
"description": "Identifies the set of interfaces in a bond that do not match on each end of the bond"
},
"proto_down_bonds": {
"type": "string",
"description": "Interface on the switch brought down by the clagd service. Value is blank if no interfaces are down due to the clagd service."
},
"vxlan_anycast": {
"type": "string",
"description": "Anycast IP address used for VXLAN termination"
},
"role": {
"type": "string",
"description": "Role of the host device. Values include primary and secondary."
}
}
},
"ErrorResponse": {
"description": "Standard error response",
"type": "object",
"properties": {
"message": {
"type": "string",
"description": "One or more errors have been encountered during the processing of the associated request"
}
}
},
"Evpn": {
"description": "This model contains descriptions of the data collected and returned by the EVPN endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"vni": {
"type": "integer",
"format": "int32",
"description": "Name of the virtual network instance (VNI) where session is running"
},
"origin_ip": {
"type": "string",
"description": "Host device's local VXLAN tunnel IP address for the EVPN instance"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time the session was started, deleted, updated or marked as dead (device is down)"
},
"rd": {
"type": "string",
"description": "Route distinguisher used in the filtering mechanism for BGP route exchange"
},
"export_rt": {
"type": "string",
"description": "IP address and port of the export route target used in the filtering mechanism for BGP route exchange"
},
"import_rt": {
"type": "string",
"description": "IP address and port of the import route target used in the filtering mechanism for BGP route exchange"
},
"in_kernel": {
"type": "boolean",
"description": "Indicates whether the associated VNI is in the kernel (in kernel) or not (not in kernel)"
},
"adv_all_vni": {
"type": "boolean",
"description": "Indicates whether the VNI state is advertising all VNIs (true) or not (false)"
},
"adv_gw_ip": {
"type": "string",
"description": "Indicates whether the host device is advertising the gateway IP address (true) or not (false)"
},
"is_l3": {
"type": "boolean",
"description": "Indicates whether the session is part of a layer 3 configuration (true) or not (false)"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"Field": {
"type": "object",
"required": [
"aliases",
"defaultValue",
"doc",
"jsonProps",
"name",
"objectProps",
"order",
"props",
"schema"
],
"properties": {
"props": {
"type": "object",
"additionalProperties": {
"type": "string"
}
},
"name": {
"type": "string"
},
"schema": {
"$ref": "#/definitions/Schema"
},
"doc": {
"type": "string"
},
"defaultValue": {
"$ref": "#/definitions/JsonNode"
},
"order": {
"type": "string",
"enum": [
"ASCENDING",
"DESCENDING",
"IGNORE"
]
},
"aliases": {
"type": "array",
"uniqueItems": true,
"items": {
"type": "string"
}
},
"jsonProps": {
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/JsonNode"
}
},
"objectProps": {
"type": "object",
"additionalProperties": {
"type": "object",
"properties": {}
}
}
}
},
"Interface": {
"description": "This model contains descriptions of the data collected and returned by the Interface endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"type": {
"type": "string",
"description": "Identifier of the kind of interface. Values include bond, bridge, eth, loopback, macvlan, swp, vlan, vrf, and vxlan."
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time the data was collected"
},
"last_changed": {
"type": "integer",
"format": "int64",
"description": "Date and time the interface was started, deleted, updated or marked as dead (device is down)"
},
"ifname": {
"type": "string",
"description": "Name of the interface"
},
"state": {
"type": "string",
"description": "Indicates whether the interface is up or down"
},
"vrf": {
"type": "string",
"description": "Name of the virtual route forwarding (VRF) interface, if present"
},
"details": {
"type": "string",
"description": ""
}
}
},
"InventoryModel": {
"type": "object",
"required": [
"label",
"value"
],
"properties": {
"label": {
"type": "string"
},
"value": {
"type": "integer",
"format": "int32"
}
}
},
"InventoryOutput": {
"type": "object",
"properties": {
"data": {
"$ref": "#/definitions/InventorySampleClass"
}
}
},
"InventorySampleClass": {
"type": "object",
"properties": {
"total": {
"type": "integer",
"format": "int32",
"example": 100,
"description": "total number of devices"
},
"os_version": {
"$ref": "#/definitions/InventorySuperModel"
},
"os_vendor": {
"$ref": "#/definitions/InventorySuperModel"
},
"asic": {
"$ref": "#/definitions/InventorySuperModel"
},
"asic_vendor": {
"$ref": "#/definitions/InventorySuperModel"
},
"asic_model": {
"$ref": "#/definitions/InventorySuperModel"
},
"cl_license": {
"$ref": "#/definitions/InventorySuperModel"
},
"agent_version": {
"$ref": "#/definitions/InventorySuperModel"
},
"agent_state": {
"$ref": "#/definitions/InventorySuperModel"
},
"platform": {
"$ref": "#/definitions/InventorySuperModel"
},
"platform_vendor": {
"$ref": "#/definitions/InventorySuperModel"
},
"disk_size": {
"$ref": "#/definitions/InventorySuperModel"
},
"memory_size": {
"$ref": "#/definitions/InventorySuperModel"
},
"platform_model": {
"$ref": "#/definitions/InventorySuperModel"
},
"interface_speeds": {
"$ref": "#/definitions/InventorySuperModel"
}
}
},
"InventorySuperModel": {
"type": "object",
"required": [
"data",
"label"
],
"properties": {
"label": {
"type": "string"
},
"data": {
"type": "array",
"items": {
"$ref": "#/definitions/InventoryModel"
}
}
}
},
"IteratorEntryStringJsonNode": {
"type": "object"
},
"IteratorJsonNode": {
"type": "object"
},
"IteratorString": {
"type": "object"
},
"JsonNode": {
"type": "object",
"required": [
"array",
"bigDecimal",
"bigInteger",
"bigIntegerValue",
"binary",
"binaryValue",
"boolean",
"booleanValue",
"containerNode",
"decimalValue",
"double",
"doubleValue",
"elements",
"fieldNames",
"fields",
"floatingPointNumber",
"int",
"intValue",
"integralNumber",
"long",
"longValue",
"missingNode",
"null",
"number",
"numberType",
"numberValue",
"object",
"pojo",
"textValue",
"textual",
"valueAsBoolean",
"valueAsDouble",
"valueAsInt",
"valueAsLong",
"valueAsText",
"valueNode"
],
"properties": {
"elements": {
"$ref": "#/definitions/IteratorJsonNode"
},
"fieldNames": {
"$ref": "#/definitions/IteratorString"
},
"binary": {
"type": "boolean"
},
"intValue": {
"type": "integer",
"format": "int32"
},
"object": {
"type": "boolean"
},
"int": {
"type": "boolean"
},
"long": {
"type": "boolean"
},
"double": {
"type": "boolean"
},
"bigDecimal": {
"type": "boolean"
},
"bigInteger": {
"type": "boolean"
},
"textual": {
"type": "boolean"
},
"boolean": {
"type": "boolean"
},
"valueNode": {
"type": "boolean"
},
"containerNode": {
"type": "boolean"
},
"missingNode": {
"type": "boolean"
},
"pojo": {
"type": "boolean"
},
"number": {
"type": "boolean"
},
"integralNumber": {
"type": "boolean"
},
"floatingPointNumber": {
"type": "boolean"
},
"numberValue": {
"$ref": "#/definitions/Number"
},
"numberType": {
"type": "string",
"enum": [
"INT",
"LONG",
"BIG_INTEGER",
"FLOAT",
"DOUBLE",
"BIG_DECIMAL"
]
},
"longValue": {
"type": "integer",
"format": "int64"
},
"bigIntegerValue": {
"type": "integer"
},
"doubleValue": {
"type": "number",
"format": "double"
},
"decimalValue": {
"type": "number"
},
"booleanValue": {
"type": "boolean"
},
"binaryValue": {
"type": "array",
"items": {
"type": "string",
"format": "byte",
"pattern": "^(?:[A-Za-z0-9+/]{4})*(?:[A-Za-z0-9+/]{2}==|[A-Za-z0-9+/]{3}=)?$"
}
},
"valueAsInt": {
"type": "integer",
"format": "int32"
},
"valueAsLong": {
"type": "integer",
"format": "int64"
},
"valueAsDouble": {
"type": "number",
"format": "double"
},
"valueAsBoolean": {
"type": "boolean"
},
"textValue": {
"type": "string"
},
"valueAsText": {
"type": "string"
},
"array": {
"type": "boolean"
},
"fields": {
"$ref": "#/definitions/IteratorEntryStringJsonNode"
},
"null": {
"type": "boolean"
}
}
},
"LLDP": {
"description": "This model contains descriptions of the data collected and returned by the LLDP endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for the host device"
},
"ifname": {
"type": "string",
"description": "Name of the host interface where the LLDP service is running"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time that the session was started, deleted, updated, or marked dead (device is down)"
},
"peer_hostname": {
"type": "string",
"description": "User-defined name for the peer device"
},
"peer_ifname": {
"type": "string",
"description": "Name of the peer interface where the session is running"
},
"lldp_peer_bridge": {
"type": "boolean",
"description": "Indicates whether the peer device is a bridge (true) or not (false)"
},
"lldp_peer_router": {
"type": "boolean",
"description": "Indicates whether the peer device is a router (true) or not (false)"
},
"lldp_peer_station": {
"type": "boolean",
"description": "Indicates whether the peer device is a station (true) or not (false)"
},
"lldp_peer_os": {
"type": "string",
"description": "Operating system (OS) used by peer device. Values include Cumulus Linux, RedHat, Ubuntu, and CentOS."
},
"lldp_peer_osv": {
"type": "string",
"description": "Version of the OS used by peer device. Example values include 3.7.3, 2.5.x, 16.04, 7.1."
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"LogicalType": {
"type": "object",
"required": [
"name"
],
"properties": {
"name": {
"type": "string"
}
}
},
"LoginRequest": {
"description": "User-entered credentials used to validate if user is allowed to access NetQ",
"type": "object",
"required": [
"password",
"username"
],
"properties": {
"username": {
"type": "string"
},
"password": {
"type": "string"
}
}
},
"LoginResponse": {
"description": "Response to user login request",
"type": "object",
"required": [
"id"
],
"properties": {
"terms_of_use_accepted": {
"type": "boolean",
"description": "Indicates whether user has accepted the terms of use"
},
"access_token": {
"type": "string",
"description": "Grants jason web token (jwt) access token. The access token also contains the NetQ Platform or Appliance (opid) which the user is permitted to access. By default, it is the primary opid given by the user."
},
"expires_at": {
"type": "integer",
"format": "int64",
"description": "Number of hours the access token is valid before it automatically expires, epoch miliseconds. By default, tokens are valid for 24 hours."
},
"id": {
"type": "string"
},
"premises": {
"type": "array",
"description": "List of premises that this user is authorized to view",
"items": {
"$ref": "#/definitions/Premises"
}
},
"customer_id": {
"type": "integer",
"format": "int32",
"description": "customer id of this user"
}
}
},
"MacFdb": {
"description": "This model contains descriptions of the data collected and returned by the MacFdb endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"mac_address": {
"type": "string",
"description": "Media access control address for a device reachable via the local bridge member port 'nexthop' or via remote VTEP with IP address of 'dst'"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"dst": {
"type": "string",
"description": "IP address of a remote VTEP from which this MAC address is reachable"
},
"nexthop": {
"type": "string",
"description": "Interface where the MAC address can be reached"
},
"is_remote": {
"type": "boolean",
"description": "Indicates if the MAC address is reachable locally on 'nexthop' (false) or remotely via a VTEP with address 'dst' (true)"
},
"port": {
"type": "string",
"description": "Currently unused"
},
"vlan": {
"type": "integer",
"format": "int32",
"description": "Name of associated VLAN"
},
"is_static": {
"type": "boolean",
"description": "Indicates if the MAC address is a static address (true) or dynamic address (false)"
},
"origin": {
"type": "boolean",
"description": "Indicates whether the MAC address is one of the host's interface addresses (true) or not (false)"
},
"active": {
"type": "boolean",
"description": "Currently unused"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"MstpInfo": {
"description": "This model contains descriptions of the data collected and returned by the MSTP endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"bridge_name": {
"type": "string",
"description": "User-defined name for a bridge"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"state": {
"type": "boolean",
"description": "Indicates whether MSTP is enabled (true) or not (false)"
},
"root_port_name": {
"type": "string",
"description": "Name of the physical interface (port) that provides the minimum cost path from the Bridge to the MSTI Regional Root"
},
"root_bridge": {
"type": "string",
"description": "Name of the CIST root for the bridged LAN"
},
"topo_chg_ports": {
"type": "string",
"description": "Names of ports that were part of the last topology change event"
},
"time_since_tcn": {
"type": "integer",
"format": "int64",
"description": "Amount of time, in seconds, since the last topology change notification"
},
"topo_chg_cntr": {
"type": "integer",
"format": "int64",
"description": "Number of times topology change notifications have been sent"
},
"bridge_id": {
"type": "string",
"description": "Spanning Tree bridge identifier for current host"
},
"edge_ports": {
"type": "string",
"description": "List of port names that are Spanning Tree edge ports"
},
"network_ports": {
"type": "string",
"description": "List of port names that are Spanning Tree network ports"
},
"disputed_ports": {
"type": "string",
"description": "List of port names that are in Spanning Tree dispute state"
},
"bpduguard_ports": {
"type": "string",
"description": "List of port names where BPDU Guard is enabled"
},
"bpduguard_err_ports": {
"type": "string",
"description": "List of port names where BPDU Guard violation occurred"
},
"ba_inconsistent_ports": {
"type": "string",
"description": "List of port names where Spanning Tree Bridge Assurance is failing"
},
"bpdufilter_ports": {
"type": "string",
"description": "List of port names where Spanning Tree BPDU Filter is enabled"
},
"ports": {
"type": "string",
"description": "List of port names in the Spanning Tree instance"
},
"is_vlan_filtering": {
"type": "boolean",
"description": "Indicates whether the bridge is enabled with VLAN filtering (is VLAN-aware) (true) or not (false)"
}
}
},
"Neighbor": {
"description": "This model contains descriptions of the data collected and returned by the Neighbor endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name of a device"
},
"ifname": {
"type": "string",
"description": "User-defined name of an software interface on a device"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time when data was collected"
},
"vrf": {
"type": "string",
"description": "Name of virtual route forwarding (VRF) interface, when applicable"
},
"is_remote": {
"type": "boolean",
"description": "Indicates if the neighbor is reachable through a local interface (false) or remotely (true)"
},
"ifindex": {
"type": "integer",
"format": "int32",
"description": "IP address index for the neighbor device"
},
"mac_address": {
"type": "string",
"description": "MAC address for the neighbor device"
},
"is_ipv6": {
"type": "boolean",
"description": "Indicates whether the neighbor's IP address is version six (IPv6) (true) or version four (IPv4) (false)"
},
"message_type": {
"type": "string",
"description": "Network protocol or service identifier used in neighbor-related events. Value is neighbor."
},
"ip_address": {
"type": "string",
"description": "IPv4 or IPv6 address for the neighbor device"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"NODE": {
"description": "This model contains descriptions of the data collected and returned by the Node endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name of the device"
},
"sys_uptime": {
"type": "integer",
"format": "int64",
"description": "Amount of time this device has been powered up"
},
"lastboot": {
"type": "integer",
"format": "int64",
"description": "Date and time this device was last booted"
},
"last_reinit": {
"type": "integer",
"format": "int64",
"description": "Date and time this device was last initialized"
},
"active": {
"type": "boolean",
"description": "Indicates whether this device is active (true) or not (false)"
},
"version": {
"type": "string",
"description": ""
},
"ntp_state": {
"type": "string",
"description": "Status of the NTP service running on this device; in sync, not in sync, or unknown"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"last_update_time": {
"type": "integer",
"format": "int64",
"description": "Date and time the device was last updated"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"NTP": {
"description": "This model contains descriptions of the data collected and returned by the NTP endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"hostname": {
"type": "string",
"description": "User-defined name of device running NTP service"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"ntp_sync": {
"type": "string",
"description": "Status of the NTP service running on this device; in sync, not in sync, or unknown"
},
"stratum": {
"type": "integer",
"format": "int32",
"description": ""
},
"ntp_app": {
"type": "string",
"description": "Name of the NTP service
},
"message_type": {
"type": "string",
"description": "Network protocol or service identifier used in NTP-related events. Value is ntp."
},
"current_server": {
"type": "string",
"description": "Name or address of server providing time synchronization"
},
"active": {
"type": "boolean",
"description": "Indicates whether NTP service is running (true) or not (false)"
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"Number": {
"type": "object",
"description": " "
},
"Port": {
"description": "This model contains descriptions of the data collected and returned by the Port endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for the device with this port"
},
"ifname": {
"type": "string",
"description": "User-defined name for the software interface on this port"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"speed": {
"type": "string",
"description": "Maximum rating for port. Examples include 10G, 25G, 40G, unknown."
},
"identifier": {
"type": "string",
"description": "Identifies type of port module if installed. Example values include empty, QSFP+, SFP, RJ45"
},
"autoneg": {
"type": "string",
"description": "Indicates status of the auto-negotiation feature. Values include on and off."
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"transreceiver": {
"type": "string",
"description": "Name of installed transceiver. Example values include 40G Base-CR4, 10Gtek."
},
"connector": {
"type": "string",
"description": "Name of installed connector. Example values include LC, copper pigtail, RJ-45, n/a."
},
"vendor_name": {
"type": "string",
"description": "Name of the port vendor. Example values include OEM, Mellanox, Amphenol, Finisar, Fiberstore, n/a."
},
"part_number": {
"type": "string",
"description": "Manufacturer part number"
},
"serial_number": {
"type": "string",
"description": "Manufacturer serial number"
},
"length": {
"type": "string",
"description": "Length of cable connected. Example values include 1m, 2m, n/a."
},
"supported_fec": {
"type": "string",
"description": "List of forward error correction (FEC) algorithms supported on this port. Example values include BaseR, RS, Not reported, None."
},
"advertised_fec": {
"type": "string",
"description": "Type of FEC advertised by this port"
},
"fec": {
"type": "string",
"description": "Forward error correction"
},
"message_type": {
"type": "string",
"description": "Network protocol or service identifier used in port-related events. Value is port."
},
"state": {
"type": "string",
"description": "Status of the port, either up or down."
}
}
},
"Premises": {
"type": "object",
"required": [
"name",
"opid"
],
"properties": {
"opid": {
"type": "integer",
"format": "int32"
},
"name": {
"type": "string"
}
},
"description": "Premises"
},
"Route": {
"description": "This module contains descirptions of the data collected and returned by the Route endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"vrf": {
"type": "string",
"description": "Name of associated virtual route forwarding (VRF) interface, if applicable"
},
"message_type": {
"type": "string",
"description": "Network protocol or service identifier used in route-related events. Value is route."
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"is_ipv6": {
"type": "boolean",
"description": "Indicates whether the IP address for this route is an IPv6 address (true) or an IPv4 address (false)"
},
"rt_table_id": {
"type": "integer",
"format": "int32",
"description": "Routing table identifier for this route"
},
"src": {
"type": "string",
"description": "Hostname of device where this route originated"
},
"nexthops": {
"type": "string",
"description": "List of hops remaining to reach destination"
},
"route_type": {
"type": "integer",
"format": "int32",
"description": ""
},
"origin": {
"type": "boolean",
"description": "Indicates whether the source of this route is on the device indicated by 'hostname'"
},
"protocol": {
"type": "string",
"description": "Protocol used for routing. Example values include BGP, OSPF."
},
"prefix": {
"type": "string",
"description": "Address prefix for this route"
}
}
},
"Schema": {
"type": "object",
"required": [
"aliases",
"doc",
"elementType",
"enumSymbols",
"error",
"fields",
"fixedSize",
"fullName",
"hashCode",
"jsonProps",
"logicalType",
"name",
"namespace",
"objectProps",
"props",
"type",
"types",
"valueType"
],
"properties": {
"props": {
"type": "object",
"additionalProperties": {
"type": "string"
}
},
"type": {
"type": "string",
"enum": [
"RECORD",
"ENUM",
"ARRAY",
"MAP",
"UNION",
"FIXED",
"STRING",
"BYTES",
"INT",
"LONG",
"FLOAT",
"DOUBLE",
"BOOLEAN",
"NULL"
]
},
"logicalType": {
"$ref": "#/definitions/LogicalType"
},
"hashCode": {
"type": "integer",
"format": "int32"
},
"elementType": {
"$ref": "#/definitions/Schema"
},
"aliases": {
"type": "array",
"uniqueItems": true,
"items": {
"type": "string"
}
},
"namespace": {
"type": "string"
},
"fields": {
"type": "array",
"items": {
"$ref": "#/definitions/Field"
}
},
"types": {
"type": "array",
"items": {
"$ref": "#/definitions/Schema"
}
},
"fullName": {
"type": "string"
},
"enumSymbols": {
"type": "array",
"items": {
"type": "string"
}
},
"doc": {
"type": "string"
},
"valueType": {
"$ref": "#/definitions/Schema"
},
"fixedSize": {
"type": "integer",
"format": "int32"
},
"name": {
"type": "string"
},
"error": {
"type": "boolean"
},
"jsonProps": {
"type": "object",
"additionalProperties": {
"$ref": "#/definitions/JsonNode"
}
},
"objectProps": {
"type": "object",
"additionalProperties": {
"type": "object",
"properties": {}
}
}
}
},
"Sensor": {
"description": "This model contains descriptions of the data collected and returned from the Sensor endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name of the device where the sensor resides"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"s_prev_state": {
"type": "string",
"description": "Previous state of a fan or power supply unit (PSU) sensor. Values include OK, absent, and bad."
},
"s_name": {
"type": "string",
"description": "Type of sensor. Values include fan, psu, temp."
},
"s_state": {
"type": "string",
"description": "Current state of a fan or power supply unit (PSU) sensor. Values include OK, absent, and bad."
},
"s_input": {
"type": "number",
"format": "float",
"description": "Sensor input"
},
"message_type": {
"type": "string",
"description": "Network protocol or service identifier used in sensor-related events. Value is sensor."
},
"s_msg": {
"type": "string",
"description": "Sensor message"
},
"s_desc": {
"type": "string",
"description": "User-defined name of sensor. Example values include fan1, fan-2, psu1, psu02, psu1temp1, temp2."
},
"s_max": {
"type": "integer",
"format": "int32",
"description": "Current maximum temperature threshold value"
},
"s_min": {
"type": "integer",
"format": "int32",
"description": "Current minimum temperature threshold value"
},
"s_crit": {
"type": "integer",
"format": "int32",
"description": "Current critical high temperature threshold value"
},
"s_lcrit": {
"type": "integer",
"format": "int32",
"description": "Current critical low temperature threshold value"
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"active": {
"type": "boolean",
"description": "Indicates whether the identified sensor is operating (true) or not (false)"
},
"deleted": {
"type": "boolean",
"description": "Indicates whether the sensor has been deleted (true) or not (false)"
}
}
},
"Services": {
"description": "This model contains descriptions of the data collected and returned from the Sensor endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name of the device where the network services are running."
},
"name": {
"type": "string",
"description": "Name of the service; for example, BGP, OSPF, LLDP, NTP, and so forth."
},
"vrf": {
"type": "string",
"description": "Name of the Virtual Route Forwarding (VRF) interface if employed."
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"is_enabled": {
"type": "boolean",
"description": "Indicates whether the network service is enabled."
},
"is_active": {
"type": "boolean",
"description": "Indicates whether the network service is currently active."
},
"is_monitored": {
"type": "boolean",
"description": "Indicates whether the network service is currently being monitored."
},
"status": {
"type": "integer",
"format": "int32",
"description": "Status of the network service connection; up or down."
},
"start_time": {
"type": "integer",
"format": "int64",
"description": "Date and time that the network service was most recently started."
},
"db_state": {
"type": "string",
"description": "Internal use only"
}
}
},
"Vlan": {
"description": "This model contains descriptions of the data collected and returned by the VLAN endpoint.",
"type": "object",
"required": [
"schema"
],
"properties": {
"schema": {
"$ref": "#/definitions/Schema"
},
"opid": {
"type": "integer",
"format": "int32",
"description": "Internal use only"
},
"hostname": {
"type": "string",
"description": "User-defined name for a device"
},
"ifname": {
"type": "string",
"description": "User-defined name for a software interface"
},
"timestamp": {
"type": "integer",
"format": "int64",
"description": "Date and time data was collected"
},
"last_changed": {
"type": "integer",
"format": "int64",
"description": "Date and time the VLAN configuration was changed (updated, deleted)"
},
"vlans": {
"type": "string",
"description": "List of other VLANs known to this VLAN or on this device"
},
"svi": {
"type": "string",
"description": "Switch virtual interface (SVI) associated with this VLAN"
},
"db_state": {
"type": "string",
"description": "Internal use only"
},
"ports": {
"type": "string",
"description": "Names of ports on the device associated with this VLAN"
}
}
}
}
}
Cumulus NetQ UI User Guide
This guide is intended for network administrators and operators who are
responsible for monitoring and troubleshooting the network in their data
center environment. NetQ 2.x offers the ability to easily monitor and
manage your data center network infrastructure and operational health.
This guide provides instructions and information about monitoring
individual components of the network, the network as a whole, and the
NetQ software itself using the NetQ graphical user interface (GUI). If
you prefer to use a command line interface, refer to the
Cumulus NetQ CLI User Guide.
NetQ User Interface Overview
The NetQ 2.x graphical user interface (UI) enables you to access NetQ capabilities through a web browser as opposed to through a terminal window using the Command Line Interface (CLI). Visual representations of the health of the network, inventory, and system events make it easy to both find faults and misconfigurations, and to fix them.
The UI is accessible in both on-site and in-cloud deployments. It is supported on Google Chrome. Other popular browsers may be used, but have not been tested and may have some presentation issues.
Before you get started, you should refer to the release notes for this version.
Access the NetQ UI
Logging in to the NetQ UI is as easy as opening any web page.
To log in to the UI:
Open a new Internet browser window or tab.
Enter the following URL into the Address bar for the NetQ On-premises Appliance or VM, or the NetQ Cloud Appliance or VM:
NetQ Cloud: Use credentials provided by Cumulus via email titled Welcome to Cumulus NetQ!
Enter your username.
Enter your password.
Enter a new password.
Enter the new password again to confirm it.
Click Update and Accept after reading the Terms of Use.
The default Cumulus Workbench opens, with your username shown in the upper right corner of the application.
Enter your username.
Enter your password.
The user-specified home workbench is displayed. If a home workbench is not specified, then the Cumulus Default workbench is displayed.
Any workbench can be set as the home workbench. Click (User Settings), click Profiles and Preferences, then on the Workbenches card click to the left of the workbench name you want to be your home workbench.
To log out of the UI:
Click at the top right of the application.
Select Log Out.
Application Layout
The NetQ UI contains two main areas:
Application Header (1): Contains the main menu, recent actions history, search capabilities, NetQ version, quick health status chart, local time zone, premises list (cloud-only), and user account information.
Workbench (2): Contains a task bar and content cards (with status and configuration information about your network and its various components).
Main Menu
Found in the application header, click to open the main menu which provides navigation to:
Favorites: contains link to the user-defined favorite workbenches; Home is points to the Cumulus Workbench until reset by a user
NetQ: contains links to all workbenches
Network: contains links to tabular data about various network elements and the What Just Happened feature
Admin: contains links to application management and lifecycle management features (only visible to users with Admin access role)
Notifications: contains link to threshold-based event rules and notification channels
Recent Actions
Found in the header, Recent Actions keeps track of every action you take on your workbench and then saves each action with a timestamp. This enables you to go back to a previous state or repeat an action.
To open Recent Actions, click . Click on any of the actions to perform that action again.
Search
The Global Search field in the UI header enables you to search for devices. It behaves like most searches and can help you quickly find device information. For more detail on creating and running searches, refer to Create and Run Searches.
Cumulus Networks Logo
Clicking on the Cumulus logo takes you to your favorite workbench. For details about specifying your favorite workbench, refer to Set User Preferences.
Quick Network Health View
Found in the header, the graph and performance rating provide a view into the health of your network at a glance.
On initial start up of the application, it may take up to an hour to reach an accurate health indication as some processes run every 30 minutes.
Workbenches
A workbench is comprised of a given set of cards. A pre-configured default workbench, Cumulus Workbench, is available to get you started. It contains Device Inventory, Switch Inventory, Alarm and Info Events, and Network Health cards. On initial login, this workbench is opened. You can create your own workbenches and add or remove cards to meet your particular needs. For more detail about managing your data using workbenches, refer to Focus Your Monitoring Using Workbenches.
Cards
Cards present information about your network for monitoring and troubleshooting. This is where you can expect to spend most of your time. Each card describes a particular aspect of the network. Cards are available in multiple sizes, from small to full screen. The level of the content on a card varies in accordance with the size of the card, with the highest level of information on the smallest card to the most detailed information on the full-screen view. Cards are collected onto a workbench where you see all of the data relevant to a task or set of tasks. You can add and remove cards from a workbench, move between cards and card sizes, and make copies of cards to show different levels of data at the same time. For details about working with cards, refer to Access Data with Cards.
User Settings
Each user can customize the NetQ application display, change their account password, and manage their workbenches. This is all performed from User Settings > Profile & Preferences. For details, refer to Set User Preferences.
Embedded Application Help
The NetQ UI provides guided walk-throughs for selected tasks and links to additional resources.
You must have connection to the Internet to access this feature.
Click Need Help? to open the menu of tasks and resources currently available.
Is the help button covering content that you want to see?
The button can be dragged and dropped to various locations around the edge of the UI, so if you do not like it on the bottom left (default), you can move it to the bottom center, bottom right, right side bottom, etc. A green dashed border appears in the locations where it can be placed. Alternately, enlarge the NetQ UI application window or scroll within the window to view any hidden content.
Within the help menu, topics are grouped by categories:
General: These items describe or walk you through high-level tasks or information about the NetQ UI.
How to…: These items walk you through how to perform common tasks.
Tell me about…: These items describe features of the application.
Where Can I Find…: These items help you find and use features that may be harder to find than others in the application.
User Documentation: This provides a link to the Cumulus NetQ user documentation. It opens in a separate window so you can have it open while working in the application.
You can search for help items by collapsing and expanding categories or by searching. Click a category title to toggle between viewing and hiding the content. To search, begin entering text into the Search field to see suggested content.
Format Cues
Color is used to indicate links, options, and status within the UI.
Item
Color
Hover on item
Blue
Clickable item
Black
Selected item
Green
Highlighted item
Blue
Link
Blue
Good/Successful results
Green
Result with critical severity event
Pink
Result with high severity event
Red
Result with medium severity event
Orange
Result with low severity event
Yellow
Create and Run Searches
The Global Search field in the UI header enables you to search for
devices or cards. You can create new searches or run existing searches.
Create a Search
As with most search fields, simply begin entering the criteria in the
search field. As you type, items that match the search criteria are
shown in the search history dropdown along with the last time the search
was viewed. Wildcards are not allowed, but this predictive matching
eliminates the need for them. By default, the most recent searches are
shown. If more have been performed, they can be accessed. This may
provide a quicker search by reducing entry specifics and suggesting
recent searches. Selecting a suggested search from the list provides a
preview of the search results to the right.
To create a new search:
Click in the Global Search field.
Enter your search criteria.
Click the device hostname or card workflow in the search list to
open the associated information.
If you have more matches than fit in the window, click the See All
# Results link to view all found matches. The count represents
the number of devices found. It does not include cards found.
Run a Recent Search
You can re-run a recent search, saving time if you are comparing data
from two or more devices.
To re-run a recent search:
Click in the Global Search field.
When the desired search appears in the suggested searches list,
select it.
You may need to click See All # Results to find the desired
search. If you do not find it in the list, you may still be able to
find it in the Recent Actions list.
Focus Your Monitoring Using Workbenches
Workbenches are an integral structure of the Cumulus NetQ application. They are where you collect and view the data that is important to you.
There are two types of workbenches:
Default: Provided by Cumulus Networks for use as they exist; changes made to these workbenches cannot be saved
Custom: Created by application users when default workbenches need some adjustments to better meet your needs or a completely different collection of cards is wanted; changes made to these workbenches are saved automatically.
Both types of workbenches display a set of cards. Default workbenches are public (available for viewing by all users), whereas Custom workbenches are private (only viewable by user who created them).
Default Workbenches
In this release, only one default workbench is available, the Cumulus Workbench, to get you started. It contains Device Inventory, Switch Inventory, Alarm and Info Events, and Network Health cards, giving you a high-level view of how your network is operating.
On initial login, the Cumulus Workbench is opened. On subsequent logins, the last workbench you had displayed is opened.
Custom Workbenches
Users with either administrative or user roles can create and save as many custom workbenches as suits their needs. For example, a user might create a workbench that:
shows all of the selected cards for the past week and one that shows all of the selected cards for the past 24 hours
only has data about your virtual overlays; EVPN plus events cards
has selected switches that you are troubleshooting
focused on application or user account management
etc.
Create a Workbench
To create a workbench:
Click in the workbench header.
Enter a name for the workbench.
Click Create to open a blank new workbench, or Cancel to discard the workbench.
Add cards to the workbench using or .
Refer to Access Data with Cards for information about interacting with cards on your workbenches.
Remove a Workbench
Once you have created a number of custom workbenches, you might find that you no longer need some of them. As an administrative user, you can remove any workbench, except for the default Cumulus Workbench. Users with a user role can only remove workbenches they have created.
To remove a workbench:
Click in the application header to open the User Settings options.
Click Profile & Preferences.
Locate the Workbenches card.
Hover over the workbench you want to remove, and click Delete.
Open an Existing Workbench
There are several options for opening workbenches:
Open through Workbench Header
Click next to the current workbench name and locate the workbench
Under My Home, click the name of your favorite workbench
Under My Most Recent, click the workbench if in list
Search by workbench name
Click All My WB to open all workbenches and select it from the list
Open through Main Menu
Click (Main Menu) and select the workbench from the Favorites or NetQ columns
Open through Cumulus logo
Click the logo in the header to open your favorite workbench
Manage Auto-Refresh for Your Workbenches
With NetQ 2.3.1 and later, you can specify how often to update the data displayed on your workbenches. Three refresh rates are available:
Analyze: updates every 30 seconds
Debug: updates every minute
Monitor: updates every two (2) minutes
By default, auto-refresh is enabled and configured to update every 30 seconds.
Disable/Enable Auto-Refresh
To disable or pause auto-refresh of your workbenches, simply click the Refresh icon. This toggles between the two states, Running and Paused, where indicates it is currently disabled and indicates it is currently enabled.
While having the workbenches update regularly is good most of the time, you may find that you want to pause the auto-refresh feature when you are troubleshooting and you do not want the data to change on a given set of cards temporarily. In this case, you can disable the auto-refresh and then enable it again when you are finished.
View Current Settings
To view the current auto-refresh rate and operational status, hover over the Refresh icon on a workbench header, to open the tool tip as follows:
Change Settings
To modify the auto-refresh setting:
Click on the Refresh icon.
Select the refresh rate you want. The refresh rate is applied immediately. A check mark is shown next to the current selection.
Manage Workbenches
To manage your workbenches as a group, either:
Click next to the current workbench name, then click Manage My WB.
Click , select Profiles & Preferences option.
Both of these open the Profiles & Preferences page. Look for the Workbenches card and refer to Manage Your Workbenches for more information.
Access Data with Cards
Cards present information about your network for monitoring and
troubleshooting. This is where you can expect to spend most of your
time. Each card describes a particular aspect of the network. Cards are
available in multiple sizes, from small to full screen. The level of the
content on a card varies in accordance with the size of the card, with
the highest level of information on the smallest card to the most
detailed information on the full-screen card. Cards are collected onto a
workbench where you see all of the data relevant to a task or set of
tasks. You can add and remove cards from a workbench, move between cards
and card sizes, change the time period of the data shown on a card, and make copies of cards to show different levels of
data at the same time.
Card Sizes
The various sizes of cards enables you to view your content at just the
right level. For each aspect that you are monitoring there is typically
a single card, that presents increasing amounts of data over its four
sizes. For example, a snapshot of your total inventory may be
sufficient, but to monitor the distribution of hardware vendors may
requires a bit more space.
Small Cards
Small cards are most effective at providing a quick view of the
performance or statistical value of a given aspect of your network. They
are commonly comprised of an icon to identify the aspect being
monitored, summary performance or statistics in the form of a graph
and/or counts, and often an indication of any related events. Other
content items may be present. Some examples include a Devices Inventory
card, a Switch Inventory card, an Alarm Events card, an Info Events
card, and a Network Health card, as shown here:
Medium Cards
Medium cards are most effective at providing the key measurements for a
given aspect of your network. They are commonly comprised of an icon to
identify the aspect being monitored, one or more key measurements that
make up the overall performance. Often additional information is also
included, such as related events or components. Some examples include a
Devices Inventory card, a Switch Inventory card, an Alarm Events card,
an Info Events card, and a Network Health card, as shown here. Compare
these with their related small- and large-sized cards.
Large Cards
Large cards are most effective at providing the detailed information for
monitoring specific components or functions of a given aspect of your
network. These can aid in isolating and resolving existing issues or
preventing potential issues. They are commonly comprised of detailed
statistics and graphics. Some large cards also have tabs for additional
detail about a given statistic or other related information. Some
examples include a Devices Inventory card, an Alarm Events card, and a
Network Health card, as shown here. Compare these with their related
small- and medium-sized cards.
Full-Screen Cards
Full-screen cards are most effective for viewing all available data
about an aspect of your network all in one place. When you cannot find
what you need in the small, medium, or large cards, it is likely on the
full-screen card. Most full-screen cards display data in a grid, or
table; however, some contain visualizations. Some examples include All
Events card and All Switches card, as shown here.
Card Size Summary
Card Size
Small
Medium
Large
Full Screen
Primary Purpose
Quick view of status, typically at the level of good or bad
Enable quick actions, run a validation or trace for example
View key performance parameters or statistics
Perform an action
Look for potential issues
View detailed performance and statistics
Perform actions
Compare and review related information
View all attributes for given network aspect
Free-form data analysis and visualization
Export data to third-party tools
Card Workflows
The UI provides a number of card workflows. Card workflows focus on a
particular aspect of your network and are a linked set of each size
card-a small card, a medium card, one or more large cards, and one or
more full screen cards. The following card workflows are available:
Network Health: network-wide view of network health
Devices|Switches: health of a given switch
Inventory|Devices: information about all switches and hosts in the network
Inventory|Switches: information about the components on a given switch
Events|Alarms: information about all critical severity events in the system
Events|Info: information about all warning, info, and debug events in the system
Network Services: information about the network services and sessions
Validation Request (and Results): network-wide validation of network protocols and services
Trace Request (and Results): find available paths between two devices in the network fabric
Access a Card Workflow
You can access a card workflow in multiple ways:
For workbenches available from the main menu, open the workbench that contains the card flow
Open a prior search
Add it to a workbench
Search for it
If you have multiple cards open on your workbench already, you might
need to scroll down to see the card you have just added.
To open the card workflow through an existing workbench:
Click in the workbench task bar.
Select the relevant workbench.
The workbench opens, hiding your previous workbench.
To open the card workflow from Recent Actions:
Click in the application header.
Look for an “Add: <card name>” item.
If it is still available, click the item.
The card appears on the current workbench, at the bottom.
The card appears on the current workbench, at the bottom.
To access the card workflow by searching for the card:
Click in the Global Search field.
Begin typing the name of the card.
Select it from the list.
The card appears on a current workbench, at the bottom.
Card Interactions
Every card contains a standard set of interactions, including the
ability to switch between card sizes, and change the time period of the
presented data. Most cards also have additional actions that can be
taken, in the form of links to other cards, scrolling, and so forth. The
four sizes of cards for a particular aspect of the network are connected
into a flow; however, you can have duplicate cards displayed at the
different sizes. Cards with tabular data provide filtering, sorting, and
export of data. The medium and large cards have descriptive text on the
back of the cards.
To access the time period, card size, and additional actions, hover over
the card. These options appear, covering the card header, enabling you
to select the desired option.
Add Cards to Your Workbench
You can add one or more cards to a workbench at any time. To add Devices|Switches cards, refer to Add Switch Cards to Your Workbench. For all other cards, follow the steps in this section.
To add one or more cards:
Click to open the Cards modal.
Scroll down until you find the card you want to add, select the category of cards, or use Search to find the card you want to add.
This example uses the category tab to narrow the search for a card.
Click on each card you want to add.
As you select each card, it is grayed out and a appears on top of it. If you have selected one or more cards using the category option, you can selected another category without losing your current selection. Note that the total number of cards selected for addition to your workbench is noted at the bottom.
Also note that if you change your mind and do not want to add a particular card you have selected, simply click on it again to remove it from the cards to be added. Note the total number of cards selected decreases with each card you remove.
When you have selected all of the cards you want to add to your workbench, you can confirm which cards have been selected by clicking the Cards Selected link. Modify your selection as needed.
Click Open Cards to add the selected cards, or Cancel to return to your workbench without adding any cards.
The cards are placed at the end of the set of cards currently on the
workbench. You might need to scroll down to see them. By default, the
medium size of the card is added to your workbench for all except the Validation and Trace cards. These are added in the large size by default. You can rearrange the cards as described in Reposition a Card on Your Workbench.
Add Switch Cards to Your Workbench
You can add switch cards to a workbench at any time. For all other cards, follow the steps in Add Cards to Your Workbench. You can either add the card through the Switches icon on a workbench header or by searching for it through Global Search.
To add a switch card using the icon:
Click to open the Add Switch Card modal.
Begin entering the hostname of the switch you want to monitor.
Select the device from the suggestions that appear.
If you attempt to enter a hostname that is unknown to NetQ, a pink border appears around the entry field and you are unable to select Add. Try checking for spelling errors. If you feel your entry is valid, but not an available choice, consult with your network administrator.
Optionally select the small or large size to display instead of the medium size.
Click Add to add the switch card to your workbench, or Cancel to return to your workbench without adding the switch card.
To open the switch card by searching:
Click in Global Search.
Begin typing the name of a switch.
Select it from the options that appear.
Remove Cards from Your Workbench
Removing cards is handled one card at a time.
To remove a card:
Hover over the card you want to remove.
Click (More Actions menu).
Click Remove.
The card is removed from the workbench, but not from the application.
Change the Time Period for the Card Data
All cards have a default time period for the data shown on the card,
typically the last 24 hours. You can change the time period to view the
data during a different time range to aid analysis of previous or
existing issues.
To change the time period for a card:
Hover over any card.
Click in the header.
Select a time period from the dropdown list.
Changing the time period in this manner only changes the time period for
the given card.
Switch to a Different Card Size
You can switch between the different card sizes at any time. Only one
size is visible at a time. To view the same card in different sizes,
open a second copy of the card.
To change the card size:
Hover over the card.
Hover over the Card Size Picker and move the cursor to the right or
left until the desired size option is highlighted.
Single width opens a small card. Double width opens a medium card.
Triple width opens large cards. Full width opens full-screen cards.
Click the Picker.
The card changes to the selected size, and may move its location on
the workbench.
View a Description of the Card Content
When you hover over a medium or large card, the bottom right corner
turns up and is highlighted. Clicking the corner turns the card over
where a description of the card and any relevant tabs are described.
Hover and click again to turn it back to the front side.
Reposition a Card on Your Workbench
You can also move cards around on the workbench, using a simple drag and
drop method.
To move a card:
Simply click and drag the card to left or right of another card, next to where you want to place the card.
Release your hold on the card when the other card becomes highlighted with a dotted line. In this example, we are moving the medium Network Health card to the left of the medium Devices Inventory card.
Table Settings
You can manipulate the data in a data grid in a full-screen card in several ways. The available options are displayed above each table. The options vary depending on the card and what is selected in the table.
Icon
Action
Description
Select All
Selects all items in the list
Clear All
Clears all existing selections in the list.
Add item to the list
Edit
Edits the selected item
Delete
Removes the selected items
Filter
Filters the list using available parameters. Refer to Filter Table Data for more detail.
,
Generate/Delete AuthKeys
Creates or removes NetQ CLI authorization keys
Open Cards
Opens the corresponding validation or trace card(s)
Assign role
Opens role assignment options for switches
Export
Exports selected data into either a .csv or JSON-formatted file. Refer to Export Data for more detail.
When there are numerous items in a table, NetQ loads the first 25 by default and provides the rest in additional table pages. In this case, pagination is shown under the table.
From there, you can:
View the total number of items in the list
Set NetQ to load 25, 50, or 100 items per page
Move forward or backward one page at a time (, )
Go to the first or last page in the list (, )
Change Order of Columns
You can rearrange the columns within a table. Click and hold on a column header, then drag it to the location where you want it.
Filter Table Data
The filter option associated with tables on full-screen cards can be used to filter the data by any parameter (column name). The parameters available vary according to the table you are viewing. Some tables offer the ability to filter on more than one parameter.
Tables that Support a Single Filter
Tables that allow a single filter to be applied let you select the parameter and set the value. You can use partial values.
For example, to set the filter to show only BGP sessions using a particular VRF:
Open the full-screen Network Services | All BGP Sessions card.
Click the All Sessions tab.
Click above the table.
Select VRF from the Field dropdown.
Enter the name of the VRF of interest. In our example, we chose vrf1.
Click Apply.
The filter icon displays a red dot to indicate filters are applied.
To remove the filter, click (with the red dot).
Click Clear.
Close the Filters dialog by clicking .
Tables that Support Multiple Filters
For tables that offer filtering by multiple parameters, the Filter dialog is slightly different. For example, to filter the list of IP Addresses in your system by hostname and interface:
Click .
Select IP Addresses under Network.
Click above the table.
Enter a hostname and interface name in the respective fields.
Click Apply.
The filter icon displays a red dot to indicate filters are applied, and each filter is presented above the table.
To remove a filter, simply click on the filter, or to remove all filters at once, click Clear All Filters.
Export Data
You can export tabular data from a full-screen card to a CSV- or
JSON-formatted file.
To export the all data:
Click above the table.
Select the export format.
Click Export to save the file to your downloads directory.
To export selected data:
Select the individual items from the list by clicking in the checkbox next to each item.
Click above the table.
Select the export format.
Click Export to save the file to your downloads directory.
Set User Preferences
Each user can customize the NetQ application display, change his account
password, and manage his workbenches.
Configure Display Settings
The Display card contains the options for setting the application theme,
language, time zone, and date formats. There are two themes available: a
Light theme and a Dark theme (default). The screen captures in this
document are all displayed with the Dark theme. English is the only
language available for this release. You can choose to view data in the
time zone where you or your data center resides. You can also select the
date and time format, choosing words or number format and a 12- or
24-hour clock. All changes take effect immediately.
To configure the display settings:
Click in the application header to open the User Settings options.
Click Profile & Preferences.
Locate the Display card.
In the Theme field, click to select your choice of theme. This figure shows the light theme. Switch back and forth as desired.
In the Time Zone field, click to change the time zone from the default.
By default, the time zone is set to the user’s local time zone. If a
time zone has not been selected, NetQ defaults to the current local
time zone where NetQ is installed. All time values are based on this
setting. This is displayed in the application header, and is based
on Greenwich Mean Time (GMT).
Tip: You can also change the time zone from the header
display.
If your deployment is not local to you (for example, you want to
view the data from the perspective of a data center in another time
zone) you can change the display to another time zone. The
following table presents a sample of time zones:
Time Zone
Description
Abbreviation
GMT +12
New Zealand Standard Time
NST
GMT +11
Solomon Standard Time
SST
GMT +10
Australian Eastern Time
AET
GMT +9:30
Australia Central Time
ACT
GMT +9
Japan Standard Time
JST
GMT +8
China Taiwan Time
CTT
GMT +7
Vietnam Standard Time
VST
GMT +6
Bangladesh Standard Time
BST
GMT +5:30
India Standard Time
IST
GMT+5
Pakistan Lahore Time
PLT
GMT +4
Near East Time
NET
GMT +3:30
Middle East Time
MET
GMT +3
Eastern African Time/Arab Standard Time
EAT/AST
GMT +2
Eastern European Time
EET
GMT +1
European Central Time
ECT
GMT
Greenwich Mean Time
GMT
GMT -1
Central African Time
CAT
GMT -2
Uruguay Summer Time
UYST
GMT -3
Argentina Standard/Brazil Eastern Time
AGT/BET
GMT -4
Atlantic Standard Time/Puerto Rico Time
AST/PRT
GMT -5
Eastern Standard Time
EST
GMT -6
Central Standard Time
CST
GMT -7
Mountain Standard Time
MST
GMT -8
Pacific Standard Time
PST
GMT -9
Alaskan Standard Time
AST
GMT -10
Hawaiian Standard Time
HST
GMT -11
Samoa Standard Time
SST
GMT -12
New Zealand Standard Time
NST
In the Date Format field, select the data and time format you
want displayed on the cards.
The four options include the date displayed in words or abbreviated
with numbers, and either a 12- or 24-hour time representation. The default is the third option.
Return to your workbench by clicking and selecting a workbench from the NetQ list.
Change Your Password
You can change your account password at any time should you suspect
someone has hacked your account or your administrator requests you to do
so.
To change your password:
Click in the application header to open the User Settings options.
Click Profile & Preferences.
Locate the Basic Account Info card.
Click Change Password.
Enter your current password.
Enter and confirm a new password.
Click Save to change to the new password, or click Cancel to
discard your changes.
Return to your workbench by clicking and selecting a workbench from the NetQ list.
Manage Your Workbenches
You can view all of your workbenches in a list form, making it possible
to manage various aspects of them. There are public and private
workbenches. Public workbenches are visible by all users. Private
workbenches are visible only by the user who created the workbench. From
the Workbenches card, you can:
Specify a home workbench: This tells NetQ to open with that workbench when you log in instead of the default Cumulus Workbench.
Search for a workbench: If you have a large number of workbenches, you can search for a particular workbench by name, or sort workbenches by their access type or cards that reside on them.
Delete a workbench: Perhaps there is one that you no longer use. You can remove workbenches that you have created (private workbenches). An administrative role is required to remove workbenches that are common to all users (public workbenches).
To manage your workbenches:
Click in the application header to open the User Settings options.
Click Profile & Preferences.
Locate the Workbenches card.
To specify a home workbench, click to the left of the desired workbench name. is placed there to indicate its status as your favorite workbench.
To search the workbench list by name, access type, and cards present on the workbench, click the relevant header and begin typing your search criteria.
To sort the workbench list, click the relevant header and click .
To delete a workbench, hover over the workbench name to view the Delete button. As an administrator, you can delete both private and public workbenches.
Return to your workbench by clicking and selecting a workbench from the NetQ list.
Monitor Events
Two event workflows, the Alarms card workflow and the Info card
workflow, provide a view into the events occurring in the network. The
Alarms card workflow tracks critical severity events, whereas the Info
card workflow tracks all warning, info, and debug severity events.
To focus on events from a single device perspective, refer to
Monitor Switches.
Monitor Critical Events
You can easily monitor critical events occurring across your network using the Alarms card. You can determine the number of events for the various system, interface, and network protocols and services components in the network. The content of the cards in the workflow is described first, and then followed by common tasks you would perform using this card workflow.
Alarms Card Workflow Summary
The small Alarms card displays:
Item
Description
Indicates data is for all critical severity events in the network
Alarm trend
Trend of alarm count, represented by an arrow:
Pointing upward and bright pink: alarm count is higher than the last two time periods, an increasing trend
Pointing downward and green: alarm count is lower than the last two time periods, a decreasing trend
No arrow: alarm count is unchanged over the last two time periods, trend is steady
Alarm score
Current count of alarms during the designated time period
Alarm rating
Count of alarms relative to the average count of alarms during the designated time period:
Low: Count of alarms is below the average count; a nominal count
Med: Count of alarms is in range of the average count; some room for improvement
High: Count of alarms is above the average count; user intervention recommended
Chart
Distribution alarms received during the designated time period and a total count of all alarms present in the system
The medium Alarms card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all critical events in the network
Count
Total number of alarms received during the designated time period
Alarm score
Current count of alarms received from each category (overall, system, interface, and network services) during the designated time period
Chart
Distribution of all alarms received from each category during the designated time period
The large Alarms card has one tab.
The Alarm Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all system, trace and interface critical events in the network
Alarm Distribution
Chart: Distribution of all alarms received from each category during the designated time period:
NetQ Agent
BTRFS Information
CL Support
Config Diff
CL License
Installed Packages
Link
LLDP
MTU
Node
Port
Resource
Running Config Diff
Sensor
Services
SSD Utilization
TCA Interface Stats
TCA Resource Utilization
TCA Sensors
The category with the largest number of alarms is shown at the top, followed by the next most, down to the chart with the fewest alarms.
Count: Total number of alarms received from each category during the designated time period
Table
Listing of items that match the filter selection for the selected alarm categories:
Events by Most Recent: Most recent event are listed at the top
Devices by Event Count: Devices with the most events are listed at the top
Show All Events
Opens full screen Events | Alarms card with a listing of all events
The full screen Alarms card provides tabs for all events.
Item
Description
Title
Events | Alarms
Closes full screen card and returns to workbench
Default Time
Range of time in which the displayed data was collected
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Events
Displays all events (both alarms and info) received in the time period. By default, the requests list is sorted by the date and time that the event occurred (Time). This tab provides the following additional data about each request:
Source: Hostname of the given event
Message: Text describing the alarm or info event that occurred
Type: Name of network protocol and/or service that triggered the given event
Severity: Importance of the event-critical, warning, info, or debug
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Alarm Status Summary
A summary of the critical alarms in the network includes the number of alarms, a trend indicator, a performance indicator, and a distribution of those alarms.
To view the summary, open the small Alarms card.
In this example, there are a small number of alarms (2), the number of alarms is decreasing (down arrow), and there are fewer alarms right now than the average number of alarms during this time period. This would indicate no further investigation is needed. Note that with such a small number of alarms, the rating may be a bit skewed.
View the Distribution of Alarms
It is helpful to know where and when alarms are occurring in your network. The Alarms card workflow enables you to see the distribution of alarms based on its source: network services, interfaces, system services, and threshold-based events.
To view the alarm distribution, open the medium Alarms card. Scroll down to view all of the charts.
Monitor Alarm Details
The Alarms card workflow enables users to easily view and track critical severity alarms occurring anywhere in your network. You can sort alarms based on their occurrence or view devices with the most network services alarms.
To view critical alarms, open the large Alarms card.
From this card, you can view the distribution of alarms for each of the categories over time. The charts are sorted by total alarm count, with the highest number of alarms i a category listed at the top. Scroll down to view any hidden charts. A list of the associated alarms is also displayed. By default, the list of the most recent alarms is displayed when viewing the large card.
View Devices with the Most Alarms
You can filter instead for the devices that have the most alarms.
To view devices with the most alarms, open the large Alarms card, and then select Devices by event count from the dropdown.
You can open the switch card for any of the listed devices by clicking on the device name.
Filter Alarms by Category
You can focus your view to include alarms for one or more selected alarm categories.
To filter for selected categories:
Click the checkbox to the left of one or more charts to remove that set of alarms from the table on the right.
Select the Devices by event count to view the devices with the most alarms for the selected categories.
Switch back to most recent events by selecting Events by most recent.
Click the checkbox again to return a category’s data to the table.
In this example, we removed the Services from the event listing.
Compare Alarms with a Prior Time
You can change the time period for the data to compare with a prior time. If the same devices are consistently indicating the most alarms, you might want to look more carefully at those devices using the Switches card workflow.
To compare two time periods:
Open a second Alarm Events card. Remember it goes to the bottom of the workbench.
Switch to the large size view.
Move the card to be next to the original Alarm Events card. Note that moving large cards can take a few extra seconds since they contain a large amount of data.
Hover over the card and click .
Select a different time period.
Compare the two cards with the Devices by event count filter applied.
In this example, the total alarm count and the devices with the most alarms in each time period have changed for the better overall. You could go back further in time or investigate the current status of the largest offenders.
View All Events
You can view all events in the network either by clicking the Show All Events link under the table on the large Alarm Events card, or by opening the full screen Alarm Events card.
OR
To return to your workbench, click in the top right corner of the card.
Monitor Informational Events
You can easily monitor warning, info, and debug severity events occurring across your network using the Info card. You can determine the number of events for the various system, interface, and network
protocols and services components in the network. The content of the cards in the workflow is described first, and then followed by common tasks you would perform using this card workflow.
Info Card Workflow Summary
The Info card workflow enables users to easily view and track informational alarms occurring anywhere in your network.
The small Info card displays:
Item
Description
Indicates data is for all warning, info, and debug severity events in the network
Info count
Number of info events received during the designated time period
Alarm count
Number of alarm events received during the designated time period
Chart
Distribution of all info events and alarms received during the designated time period
The medium Info card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all warning, info, and debug severity events in the network
Types of Info
Chart which displays the services that have triggered events during the designated time period. Hover over chart to view a count for each type.
Distribution of Info
Info Status
Count: Number of info events received during the designated time period
Chart: Distribution of all info events received during the designated time period
Alarms Status
Count: Number of alarm events received during the designated time period
Chart: Distribution of all alarm events received during the designated time period
The large Info card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all warning, info, and debug severity events in the network
Types of Info
Chart which displays the services that have triggered events during the designated time period. Hover over chart to view a count for each type.
Distribution of Info
Info Status
Count: Current number of info events received during the designated time period
Chart: Distribution of all info events received during the designated time period
Alarms Status
Count: Current number of alarm events received during the designated time period
Chart: Distribution of all alarm events received during the designated time period
Table
Listing of items that match the filter selection:
Events by Most Recent: Most recent event are listed at the top
Devices by Event Count: Devices with the most events are listed at the top
Show All Events
Opens full screen Events | Info card with a listing of all events
The full screen Info card provides tabs for all events.
Item
Description
Title
Events | Info
Closes full screen card and returns to workbench
Default Time
Range of time in which the displayed data was collected
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Events
Displays all events (both alarms and info) received in the time period. By default, the requests list is sorted by the date and time that the event occurred (Time). This tab provides the following additional data about each request:
Source: Hostname of the given event
Message: Text describing the alarm or info event that occurred
Type: Name of network protocol and/or service that triggered the given event
Severity: Importance of the event-critical, warning, info, or debug
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Info Status Summary
A summary of the informational events occurring in the network can be found on the small, medium, and large Info cards. Additional details are available as you increase the size of the card.
To view the summary with the small Info card, simply open the card. This card gives you a high-level view in a condensed visual, including the number and distribution of the info events along with the alarms that have occurred during the same time period.
To view the summary with the medium Info card, simply open the card. This card gives you the same count and distribution of info and alarm events, but it also provides information about the sources of the info events and enables you to view a small slice of time using the distribution charts.
Use the chart at the top of the card to view the various sources of info events. The four or so types with the most info events are called out separately, with all others collected together into an Other category. Hover over segment of chart to view the count for each type.
To view the summary with the large Info card, open the card. The left side of the card provides the same capabilities as the medium Info card.
Compare Timing of Info and Alarm Events
While you can see the relative relationship between info and alarm events on the small Info card, the medium and large cards provide considerably more information. Open either of these to view individual line charts for the events. Generally, alarms have some corollary info events. For example, when a network service becomes unavailable, a
critical alarm is often issued, and when the service becomes available again, an info event of severity warning is generated. For this reason, you might see some level of tracking between the info and alarm counts and distributions. Some other possible scenarios:
When a critical alarm is resolved, you may see a temporary increase in info events as a result.
When you get a burst of info events, you may see a follow-on increase in critical alarms, as the info events may have been warning you of something beginning to go wrong.
You set logging to debug, and a large number of info events of severity debug are seen. You would not expect to see an increase in critical alarms.
View All Info Events Sorted by Time of Occurrence
You can view all info events using the large Info card. Open the large card and confirm the Events By Most Recent option is selected in the filter above the table on the right. When this option is selected, all of the info events are listed with the most recently occurring event at the top. Scrolling down shows you the info events that have occurred at an earlier time within the selected time period for the card.
View Devices with the Most Info Events
You can filter instead for the devices that have the most info events by selecting the Devices by Event Count option from the filter above the table.
You can open the switch card for any of the listed devices by clicking on the device name.
View All Events
You can view all events in the network either by clicking the Show All Events link under the table on the large Info Events card, or by opening the full screen Info Events card.
OR
To return to your workbench, click in the top right corner of the card.
Events Reference
The following table lists all event messages organized by type.
The messages can be viewed through third-party notification
applications. For details about configuring notifications using the NetQ
CLI, refer to Integrate NetQ with Notification Applications.
For information about configuring threshold-based events (TCAs), refer to Application Management.
Type
Trigger
Severity
Message Format
Example
agent
NetQ Agent state changed to Rotten (not heard from in over 15 seconds)
Critical
Agent state changed to rotten
Agent state changed to rotten
agent
NetQ Agent rebooted
Critical
Netq-agent rebooted at (@last_boot)
Netq-agent rebooted at 1573166417
agent
Node running NetQ Agent rebooted
Critical
Switch rebooted at (@sys_uptime)
Switch rebooted at 1573166131
agent
NetQ Agent state changed to Fresh
Info
Agent state changed to fresh
Agent state changed to fresh
agent
NetQ Agent state was reset
Info
Agent state was paused and resumed at (@last_reinit)
Agent state was paused and resumed at 1573166125
agent
Version of NetQ Agent has changed
Info
Agent version has been changed old_version:@old_version and new_version:@new_version. Agent reset at @sys_uptime
Agent version has been changed old_version:2.1.2 and new_version:2.3.1. Agent reset at 1573079725
bgp
BGP Session state changed
Critical
BGP session with peer @peer @neighbor vrf @vrf state changed from @old_state to @new_state
BGP session with peer leaf03 leaf04 vrf mgmt state changed from Established to NotEstd
bgp
BGP Session state changed from Failed to Established
Info
BGP session with peer @peer @peerhost @neighbor vrf @vrf session state changed from failed to Established
BGP session with peer swp5 spine02 spine03 vrf default session state changed from failed to Established
bgp
BGP Session state changed from Established to Failed
Info
BGP session with peer @peer @neighbor vrf @vrf state changed from established to failed
BGP session with peer leaf03 leaf04 vrf mgmt state changed from down to up
bgp
The reset time for a BGP session changed
Info
BGP session with peer @peer @neighbor vrf @vrf reset time changed from @old_last_reset_time to @new_last_reset_time
BGP session with peer spine03 swp9 vrf vrf2 reset time changed from 1559427694 to 1559837484
btrfsinfo
Disk space available after BTRFS allocation is less than 80% of partition size or only 2 GB remain.
Critical
@info : @details
high btrfs allocation space : greater than 80% of partition size, 61708420
btrfsinfo
Indicates if space would be freed by a rebalance operation on the disk
Critical
@info : @details
data storage efficiency : space left after allocation greater than chunk size 6170849.2","
cable
Link speed is not the same on both ends of the link
Critical
@ifname speed @speed, mismatched with peer @peer @peer_if speed @peer_speed
swp2 speed 10, mismatched with peer server02 swp8 speed 40
cable
The speed setting for a given port changed
Info
@ifname speed changed from @old_speed to @new_speed
swp9 speed changed from 10 to 40
cable
The transceiver status for a given port changed
Info
@ifname transceiver changed from @old_transceiver to @new_transceiver
swp4 transceiver changed from disabled to enabled
cable
The vendor of a given transceiver changed
Info
@ifname vendor name changed from @old_vendor_name to @new_vendor_name
swp23 vendor name changed from Broadcom to Mellanox
cable
The part number of a given transceiver changed
Info
@ifname part number changed from @old_part_number to @new_part_number
swp7 part number changed from FP1ZZ5654002A to MSN2700-CS2F0
cable
The serial number of a given transceiver changed
Info
@ifname serial number changed from @old_serial_number to @new_serial_number
swp4 serial number changed from 571254X1507020 to MT1552X12041
cable
The status of forward error correction (FEC) support for a given port changed
Info
@ifname supported fec changed from @old_supported_fec to @new_supported_fec
swp12 supported fec changed from supported to unsupported
swp12 supported fec changed from unsupported to supported
cable
The advertised support for FEC for a given port changed
Info
@ifname supported fec changed from @old_advertised_fec to @new_advertised_fec
swp24 supported FEC changed from advertised to not advertised
cable
The FEC status for a given port changed
Info
@ifname fec changed from @old_fec to @new_fec
swp15 fec changed from disabled to enabled
clag
CLAG remote peer state changed from up to down
Critical
Peer state changed to down
Peer state changed to down
clag
Local CLAG host MTU does not match its remote peer MTU
Critical
SVI @svi1 on vlan @vlan mtu @mtu1 mismatched with peer mtu @mtu2
SVI svi7 on vlan 4 mtu 1592 mistmatched with peer mtu 1680
clag
CLAG SVI on VLAN is missing from remote peer state
Warning
SVI on vlan @vlan is missing from peer
SVI on vlan vlan4 is missing from peer
clag
CLAG peerlink is not opperating at full capacity. At least one link is down.
Warning
Clag peerlink not at full redundancy, member link @slave is down
Clag peerlink not at full redundancy, member link swp40 is down
clag
CLAG remote peer state changed from down to up
Info
Peer state changed to up
Peer state changed to up
clag
Local CLAG host state changed from down to up
Info
Clag state changed from down to up
Clag state changed from down to up
clag
CLAG bond in Conflicted state was updated with new bonds
Info
Clag conflicted bond changed from @old_conflicted_bonds to @new_conflicted_bonds
Clag conflicted bond changed from swp7 swp8 to @swp9 swp10
clag
CLAG bond changed state from protodown to up state
Info
Clag conflicted bond changed from @old_state_protodownbond to @new_state_protodownbond
Clag conflicted bond changed from protodown to up
clsupport
A new CL Support file has been created for the given node
Critical
HostName @hostname has new CL SUPPORT file
HostName leaf01 has new CL SUPPORT file
configdiff
Configuration file deleted on a device
Critical
@hostname config file @type was deleted
spine03 config file /etc/frr/frr.conf was deleted
configdiff
Configuration file has been created
Info
@hostname config file @type was created
leaf12 config file /etc/lldp.d/README.conf was created
configdiff
Configuration file has been modified
Info
@hostname config file @type was modified
spine03 config file /etc/frr/frr.conf was modified
evpn
A VNI was configured and moved from the up state to the down state
Critical
VNI @vni state changed from up to down
VNI 36 state changed from up to down
evpn
A VNI was configured and moved from the down state to the up state
Info
VNI @vni state changed from down to up
VNI 36 state changed from down to up
evpn
The kernel state changed on a VNI
Info
VNI @vni kernel state changed from @old_in_kernel_state to @new_in_kernel_state
VNI 3 kernel state changed from down to up
evpn
A VNI state changed from not advertising all VNIs to advertising all VNIs
Info
VNI @vni vni state changed from @old_adv_all_vni_state to @new_adv_all_vni_state
VNI 11 vni state changed from false to true
license
License state is missing or invalid
Critical
License check failed, name @lic_name state @state
License check failed, name agent.lic state invalid
license
License state is missing or invalid on a particular device
Critical
License check failed on @hostname
License check failed on leaf03
link
Link operational state changed from up to down
Critical
HostName @hostname changed state from @old_state to @new_state Interface:@ifname
HostName leaf01 changed state from up to down Interface:swp34
link
Link operational state changed from down to up
Info
HostName @hostname changed state from @old_state to @new_state Interface:@ifname
HostName leaf04 changed state from down to up Interface:swp11
lldp
Local LLDP host has new neighbor information
Info
LLDP Session with host @hostname and @ifname modified fields @changed_fields
LLDP Session with host leaf02 swp6 modified fields leaf06 swp21
lldp
Local LLDP host has new peer interface name
Info
LLDP Session with host @hostname and @ifname @old_peer_ifname changed to @new_peer_ifname
LLDP Session with host spine01 and swp5 swp12 changed to port12
lldp
Local LLDP host has new peer hostname
Info
LLDP Session with host @hostname and @ifname @old_peer_hostname changed to @new_peer_hostname
LLDP Session with host leaf03 and swp2 leaf07 changed to exit01
mtu
VLAN interface link MTU is smaller than that of its parent MTU
Warning
vlan interface @link mtu @mtu is smaller than parent @parent mtu @parent_mtu
vlan interface swp3 mtu 1500 is smaller than parent peerlink-1 mtu 1690
mtu
Bridge interface MTU is smaller than the member interface with the smallest MTU
Warning
bridge @link mtu @mtu is smaller than least of member interface mtu @min
bridge swp0 mtu 1280 is smaller than least of member interface mtu 1500
ntp
NTP sync state changed from in sync to not in sync
Critical
Sync state changed from @old_state to @new_state for @hostname
Sync state changed from in sync to not sync for leaf06
ntp
NTP sync state changed from not in sync to in sync
Info
Sync state changed from @old_state to @new_state for @hostname
Sync state changed from not sync to in sync for leaf06
ospf
OSPF session state on a given interface changed from Full to a down state
Critical
OSPF session @ifname with @peer_address changed from Full to @down_state
OSPF session swp7 with 27.0.0.18 state changed from Full to Fail
OSPF session swp7 with 27.0.0.18 state changed from Full to ExStart
ospf
OSPF session state on a given interface changed from a down state to full
Info
OSPF session @ifname with @peer_address changed from @down_state to Full
OSPF session swp7 with 27.0.0.18 state changed from Down to Full
OSPF session swp7 with 27.0.0.18 state changed from Init to Full
OSPF session swp7 with 27.0.0.18 state changed from Fail to Full
packageinfo
Package version on device does not match the version identified in the existing manifest
Critical
@package_name manifest version mismatch
netq-apps manifest version mismatch
ptm
Physical interface cabling does not match configuration specified in topology.dot file
Critical
PTM cable status failed
PTM cable status failed
ptm
Physical interface cabling matches configuration specified in topology.dot file
Critical
PTM cable status passed
PTM cable status passed
resource
A physical resource has been deleted from a device
Critical
Resource Utils deleted for @hostname
Resource Utils deleted for spine02
resource
Root file system access on a device has changed from Read/Write to Read Only
Critical
@hostname root file system access mode set to Read Only
server03 root file system access mode set to Read Only
resource
Root file system access on a device has changed from Read Only to Read/Write
Info
@hostname root file system access mode set to Read/Write
leaf11 root file system access mode set to Read/Write
resource
A physical resource has been added to a device
Info
Resource Utils added for @hostname
Resource Utils added for spine04
runningconfigdiff
Running configuration file has been modified
Info
@commandname config result was modified
@commandname config result was modified
sensor
A fan or power supply unit sensor has changed state
Critical
Sensor @sensor state changed from @old_s_state to @new_s_state
Sensor fan state changed from up to down
sensor
A temperature sensor has crossed the maximum threshold for that sensor
Critical
Sensor @sensor max value @new_s_max exceeds threshold @new_s_crit
Sensor temp max value 110 exceeds the threshold 95
sensor
A temperature sensor has crossed the minimum threshold for that sensor
Critical
Sensor @sensor min value @new_s_lcrit fall behind threshold @new_s_min
Sensor psu min value 10 fell below threshold 25
sensor
A temperature, fan, or power supply sensor state changed
Info
Sensor @sensor state changed from @old_state to @new_state
Sensor temperature state changed from critical to ok
Sensor fan state changed from absent to ok
Sensor psu state changed from bad to ok
sensor
A fan or power supply sensor state changed
Info
Sensor @sensor state changed from @old_s_state to @new_s_state
Sensor fan state changed from down to up
Sensor psu state changed from down to up
services
A service status changed from down to up
Critical
Service @name status changed from @old_status to @new_status
Service bgp status changed from down to up
services
A service status changed from up to down
Critical
Service @name status changed from @old_status to @new_status
Service lldp status changed from up to down
services
A service changed state from inactive to active
Info
Service @name changed state from inactive to active
Service bgp changed state from inactive to active
Service lldp changed state from inactive to active
ssdutil
3ME3 disk health has dropped below 10%
Critical
@info: @details
low health : 5.0%
ssdutil
A dip in 3ME3 disk health of more than 2% has occurred within the last 24 hours
Critical
@info: @details
significant health drop : 3.0%
tca
Percentage of CPU utilization exceeded user-defined maximum threshold on a switch
Critical
CPU Utilization for host @hostname exceed configured mark @cpu_utilization
CPU Utilization for host leaf11 exceed configured mark 85
tca
Percentage of disk utilization exceeded user-defined maximum threshold on a switch
Critical
Disk Utilization for host @hostname exceed configured mark @disk_utilization
Disk Utilization for host leaf11 exceed configured mark 90
tca
Percentage of memory utilization exceeded user-defined maximum threshold on a switch
Critical
Memory Utilization for host @hostname exceed configured mark @mem_utilization
Memory Utilization for host leaf11 exceed configured mark 95
tca
Number of transmit bytes exceeded user-defined maximum threshold on a switch interface
Fan speed exceeded user-defined maximum threshold on a switch
Critical
Sensor for @hostname exceeded threshold fan speed @s_input for sensor @s_name
Sensor for spine03 exceeded threshold fan speed 700 for sensor fan2
tca
Power supply output exceeded user-defined maximum threshold on a switch
Critical
Sensor for @hostname exceeded threshold power @s_input watts for sensor @s_name
Sensor for leaf14 exceeded threshold power 120 watts for sensor psu1
tca
Temperature (° C) exceeded user-defined maximum threshold on a switch
Critical
Sensor for @hostname exceeded threshold temperature @s_input for sensor @s_name
Sensor for leaf14 exceeded threshold temperature 90 for sensor temp1
tca
Power supply voltage exceeded user-defined maximum threshold on a switch
Critical
Sensor for @hostname exceeded threshold voltage @s_input volts for sensor @s_name
Sensor for leaf14 exceeded threshold voltage 12 volts for sensor psu2
version
An unknown version of the operating system was detected
Critical
unexpected os version @my_ver
unexpected os version cl3.2
version
Desired version of the operating system is not available
Critical
os version @ver
os version cl3.7.9
version
An unknown version of a software package was detected
Critical
expected release version @ver
expected release version cl3.6.2
version
Desired version of a software package is not available
Critical
different from version @ver
different from version cl4.0
vxlan
Replication list is contains an inconsistent set of nodes<>
Critical<>
VNI @vni replication list inconsistent with @conflicts diff:@diff<>
VNI 14 replication list inconsistent with ["leaf03","leaf04"] diff:+:["leaf03","leaf04"] -:["leaf07","leaf08"]
Monitor Network Performance
The core capabilities of Cumulus NetQ enable you to monitor your network by viewing performance and configuration data about your individual network devices and the entire fabric network-wide. The topics contained in this section describe monitoring tasks that apply across the entire network. For device-specific monitoring refer to Monitor Devices.
Monitor Network Health
As with any network, one of the challenges is keeping track of all of the moving parts. With the NetQ GUI, you can view the overall health of your network at a glance and then delve deeper for periodic checks or as conditions arise that require attention. For a general understanding of how well your network is operating, the Network Health card workflow is the best place to start as it contains the highest view and performance roll-ups.
Network Health Card Workflow Summary
The small Network Health card displays:
Item
Description
Indicates data is for overall Network Health
Health trend
Trend of overall network health, represented by an arrow:
Pointing upward and green: Health score in the most recent window is higher than in the last two data collection windows, an increasing trend
Pointing downward and bright pink: Health score in the most recent window is lower than in the last two data collection windows, a decreasing trend
No arrow: Health score is unchanged over the last two data collection windows, trend is steady
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health score
Average of health scores for system health, network services health, and interface health during the last data collection window. The health score for each category is calculated as the percentage of items which passed validations versus the number of items checked.
The collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health rating
Performance rating based on the health score during the time window:
Low: Health score is less than 40%
Med: Health score is between 40% and 70%
High: Health score is greater than 70%
Chart
Distribution of overall health status during the designated time period
The medium Network Health card displays the distribution, score, and
trend of the:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for overall Network Health
Health trend
Trend of system, network service, and interface health, represented by an arrow:
Pointing upward and green: Health score in the most recent window is higher than in the last two data collection windows, an increasing trend
Pointing downward and bright pink: Health score in the most recent window is lower than in the last two data collection windows, a decreasing trend
No arrow: Health score is unchanged over the last two data collection windows, trend is steady
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health score
Percentage of devices which passed validation versus the number of devices checked during the time window for:
System health: NetQ Agent health, Cumulus Linux license status, and sensors
Network services health: BGP, CLAG, EVPN, NTP, OSPF, and VXLAN health
Interface health: interfaces MTU, VLAN health
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Chart
Distribution of overall health status during the designated time period
The large Network Health card contains three tabs.
The System Health tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for System Health
Health trend
Trend of NetQ Agents, Cumulus Linux licenses, and sensor health, represented by an arrow:
Pointing upward and green: Health score in the most recent window is higher than in the last two data collection windows, an increasing trend
Pointing downward and bright pink: Health score in the most recent window is lower than in the last two data collection windows, a decreasing trend
No arrow: Health score is unchanged over the last two data collection windows, trend is steady
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health score
Percentage of devices which passed validation versus the number of devices checked during the time window for NetQ Agents, Cumulus Linux license status, and platform sensors.
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Charts
Distribution of health score for NetQ Agents, Cumulus Linux license status, and platform sensors during the designated time period
Table
Listing of items that match the filter selection:
Most Failures: Devices with the most validation failures are listed at the top
Recent Failures: Most recent validation failures are listed at the top
Show All Validations
Opens full screen Network Health card with a listing of validations performed by network service and protocol
The Network Service Health tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for Network Protocols and Services Health
Health trend
Trend of BGP, CLAG, EVPN, NTP, OSPF, and VXLAN services health, represented by an arrow:
Pointing upward and green: Health score in the most recent window is higher than in the last two data collection windows, an increasing trend
Pointing downward and bright pink: Health score in the most recent window is lower than in the last two data collection windows, a decreasing trend
No arrow: Health score is unchanged over the last two data collection windows, trend is steady
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health score
Percentage of devices which passed validation versus the number of devices checked during the time window for BGP, CLAG, EVPN, NTP, and VXLAN protocols and services.
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Charts
Distribution of passing validations for BGP, CLAG, EVPN, NTP, and VXLAN services during the designated time period
Table
Listing of devices that match the filter selection:
Most Failures: Devices with the most validation failures are listed at the top
Recent Failures: Most recent validation failures are listed at the top
Show All Validations
Opens full screen Network Health card with a listing of validations performed by network service and protocol
The Interface Health tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for Interface Health
Health trend
Trend of interfaces, VLAN, and MTU health, represented by an arrow:
Pointing upward and green: Health score in the most recent window is higher than in the last two data collection windows, an increasing trend
Pointing downward and bright pink: Health score in the most recent window is lower than in the last two data collection windows, a decreasing trend
No arrow: Health score is unchanged over the last two data collection windows, trend is steady
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Health score
Percentage of devices which passed validation versus the number of devices checked during the time window for interfaces, VLAN, and MTU protocols and ports.
The data collection window varies based on the time period of the card. For a 24 hour time period (default), the window is one hour. This gives you current, hourly, updates about your network health.
Charts
Distribution of passing validations for interfaces, VLAN, and MTU protocols and ports during the designated time period
Table
Listing of devices that match the filter selection:
Most Failures: Devices with the most validation failures are listed at the top
Recent Failures: Most recent validation failures are listed at the top
Show All Validations
Opens full screen Network Health card with a listing of validations performed by network service and protocol
The full screen Network Health card displays all events in the network.
Item
Description
Title
Network Health
Closes full screen card and returns to workbench
Default Time
Range of time in which the displayed data was collected
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
Network protocol or service tab
Displays results of that network protocol or service validations that occurred during the designated time period. By default, the requests list is sorted by the date and time that the validation was completed (Time). This tab provides the following additional data about all protocols and services:
Validation Label: User-defined name of a validation or Default validation
Total Node Count: Number of nodes running the protocol or service
Checked Node Count: Number of nodes running the protocol or service included in the validation
Failed Node Count: Number of nodes that failed the validation
Rotten Node Count: Number of nodes that were unreachable during the validation run
Warning Node Count: Number of nodes that had errors during the validation run
The following protocols and services have additional data:
BGP
Total Session Count: Number of sessions running BGP included in the validation
Failed Session Count: Number of BGP sessions that failed the validation
EVPN
Total Session Count: Number of sessions running BGP included in the validation
Checked VNIs Count: Number of VNIs included in the validation
Failed BGP Session Count: Number of BGP sessions that failed the validation
Interfaces
Checked Port Count: Number of ports included in the validation
Failed Port Count: Number of ports that failed the validation.
Unverified Port Count: Number of ports where a peer could not be identified
Licenses
Checked License Count: Number of licenses included in the validation
Failed License Count: Number of licenses that failed the validation
MTU
Total Link Count: Number of links included in the validation
Failed Link Count: Number of links that failed the validation
NTP
Unknown Node Count: Number of nodes that NetQ sees but are not in its inventory an thus not included in the validation
OSPF
Total Adjacent Count: Number of adjacencies included in the validation
Failed Adjacent Count: Number of adjacencies that failed the validation
Sensors
Checked Sensor Count: Number of sensors included in the validation
Failed Sensor Count: Number of sensors that failed the validation
VLAN
Total Link Count: Number of links included in the validation
Failed Link Count: Number of links that failed the validation
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Network Health Summary
Overall network health is based on successful validation results. The summary includes the percentage of successful results, a trend indicator, and a distribution of the validation results.
To view a summary of your network health, open the small Network Health card.
In this example, the overall health is relatively good, but improving compared to recent status. Refer to the next section for viewing the key health metrics.
View Key Metrics of Network Health
Overall network health is a calculated average of several key health metrics: System, Network Services, and Interface health.
To view these key metrics, open the medium Network Health card. Each metric is shown with percentage of successful validations, a trend indicator, and a distribution of the validation results.
In this example, the health of each of the system and network services are good, but interface health is on the lower side. While it is improving, you might choose to dig further if it does not continue to improve. Refer to the following section for additional details.
View System Health
The system health is a calculated average of the NetQ Agent, Cumulus Linux license, and sensor health metrics. In all cases, validation is performed on the agents and licenses. If you are monitoring platform sensors, the calculation includes these as well. You can view the overall health of the system from the medium Network Health card and information about each component from the System Health tab on the large Network Health card.
To view information about each system component:
Open the large Network Health card.
Hover over the card and click .
The health of each system protocol or service is represented on the left side of the card by a distribution of the health score, a trend indicator, and a percentage of successful results. The right side of the card provides a listing of devices running the services.
View Devices with the Most Issues
It is useful to know which devices are experiencing the most issues with their system services in general, as this can help focus troubleshooting efforts toward selected devices versus the service itself. To view devices with the most issues, select Most Failures from the filter above the table on the right.
Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Event cards and filter on the indicated switches.
View Devices with Recent Issues
It is useful to know which devices are experiencing the most issues with their system services right now, as this can help focus troubleshooting efforts toward selected devices versus the service itself. To view devices with recent issues, select Recent Failures from the filter
above the table on the right. Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Switch card or the Event cards and filter on the indicated switches.
Filter Results by System Service
You can focus the data in the table on the right, by unselecting one or more services. Click the checkbox next to the service you want to remove from the data. In this example, we have unchecked Licenses.
This removes the checkbox next to the associated chart and grays out the title of the chart, temporarily removing the data related to that service from the table. Add it back by hovering over the chart and clicking the checkbox that appears.
View Details of a Particular System Service
From the System Health tab on the large Network Health card you can click on a chart to take you to the full-screen card pre-focused on that service data.
View Network Services Health
The network services health is a calculated average of the individual network protocol and services health metrics. In all cases, validation is performed on NTP. If you are running BGP, CLAG, EVPN, OSPF, or VXLAN protocols the calculation includes these as well. You can view the overall health of network services from the medium Network Health card and information about individual services from the Network Service Health tab on the large Network Health card.
To view information about each network protocol or service:
Open the large Network Health card.
Hover over the card and click .
The health of each network protocol or service is represented on the left side of the card by a distribution of the health score, a trend indicator, and a percentage of successful results. The right side of the card provides a listing of devices running the services.
If you have more services running than fit naturally into the chart area, a scroll bar appears for you to access their data. Use the scroll bars on the table to view more columns and rows.
View Devices with the Most Issues
It is useful to know which devices are experiencing the most issues with their system services in general, as this can help focus troubleshooting efforts toward selected devices versus the protocol or service. To view devices with the most issues, open the large Network Health card, then click the Network Services tab. Select Most Failures from the dropdown above the table on the right.
Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Event cards and filter on the indicated switches.
View Devices with Recent Issues
It is useful to know which devices are experiencing the most issues with their network services right now, as this can help focus troubleshooting efforts toward selected devices versus the protocol or service. To view devices with the most issues, open the large Network Health card. Select Recent Failures from the dropdown above the table on the right. Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Switch card or the Event cards and filter on the indicated switches.
Filter Results by Network Service
You can focus the data in the table on the right, by unselecting one or more services. Click the checkbox next to the service you want to remove. In this example, we removed NTP and are in the process of removing OSPF.
This grays out the chart title and removes the associated checkbox, temporarily removing the data related to that service from the table.
View Details of a Particular Network Service
From the Network Service Health tab on the large Network Health card you can click on a chart to take you to the full-screen card pre-focused on that service data.
View Interfaces Health
The interface health is a calculated average of the interfaces, VLAN, and MTU health metrics. You can view the overall health of interfaces from the medium Interface Health card and information about each component from the Interface Health tab on the large Interface Health card.
To view information about each system component:
Open the large Network Health card.
Hover over the card and click .
The health of each interface protocol or service is represented on the left side of the card by a distribution of the health score, a trend indicator, and a percentage of successful results. The right side of the card provides a listing of devices running the services.
View Devices with the Most Issues
It is useful to know which devices are experiencing the most issues with their interfaces in general, as this can help focus troubleshooting efforts toward selected devices versus the service itself. To view devices with the most issues, select Most Failures from the filter
above the table on the right.
Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Event cards and filter on the indicated switches.
View Devices with Recent Issues
It is useful to know which devices are experiencing the most issues with their network services right now, as this can help focus troubleshooting efforts toward selected devices versus the service itself. To view devices with recent issues, select Recent Failures from the filter
above the table on the right. Devices with the highest number of issues are listed at the top. Scroll down to view those with fewer issues. To further investigate the critical devices, open the Switch card or the Event cards and filter on the indicated switches.
Filter Results by Interface Service
You can focus the data in the table on the right, by unselecting one or more services. Click the checkbox next to the interface item you want to remove from the data. In this example, we have unchecked MTU.
This removes the checkbox next to the associated chart and grays out the title of the chart, temporarily removing the data related to that service from the table. Add it back by hovering over the chart and clicking the checkbox that appears.
View Details of a Particular Interface Service
From the Interface Health tab on the large Network Health card you can click on a chart to take you to the full-screen card pre-focused on that service data.
View All Network Protocol and Service Validation Results
The Network Health card workflow enables you to view all of the results
of all validations run on the network protocols and services during the
designated time period.
To view all the validation results:
Open the full screen Network Health card.
Click <network protocol or service name> tab in the navigation panel.
Look for patterns in the data. For example, when did nodes, sessions, links, ports, or devices start failing validation? Was it at a specific time? Was it when you starting running the service on more nodes? Did sessions fail, but nodes were fine?
Where to go next depends on what data you see, but a few options include:
Look for matching event information for the failure points in a given protocol or service.
When you find failures in one protocol, compare with higher level protocols to see if they fail at a similar time (or vice versa with supporting services).
Export the data for use in another analytics tool, by clicking and providing a name for the data file.
Validate Network Protocol and Service Operations
With the NetQ UI, you can validate the operation of the network protocols and services running in your network either on demand or on a scheduled basis. There are three card workflows to perform this validation: one for creating the validation request (either on-demand or scheduled) and two validation results (one for on-demand and one for scheduled).
This release supports validation of the following network protocols and services: Agents, BGP, CLAG, EVPN, Interfaces, License, MTU, NTP, OSPF, Sensors, VLAN, and VXLAN.
For a more general understanding of how well your network is operating, refer to the Monitor Network Health topic.
Create Validation Requests
The Validation Request card workflow is used to create on-demand validation requests to evaluate the health of your network protocols and services.
Validation Request Card Workflow
The small Validation Request card displays:
Item
Description
Indicates a validation request
Validation
Select a scheduled request to run that request on-demand. A default validation is provided for each supported network protocol and service, which runs a network-wide validation check. These validations run every 60 minutes, but you may run them on-demand at any time.
Note: No new requests can be configured from this size card.
GO
Start the validation request. The corresponding On-demand Validation Result cards are opened on your workbench, one per protocol and service.
The medium Validation Request card displays:
Item
Description
Indicates a validation request
Title
Validation Request
Validation
Select a scheduled request to run that request on-demand. A default validation is provided for each supported network protocol and service, which runs a network-wide validation check. These validations run every 60 minutes, but you may run them on-demand at any time.
Note: No new requests can be configured from this size card.
Protocols
The protocols included in a selected validation request are listed here.
Schedule
For a selected scheduled validation, the schedule and the time of the last run are displayed.
Start the validation request
Run Now
The large Validation Request card displays:
Item
Description
Indicates a validation request
Title
Validation Request
Validation
Depending on user intent, this field is used to:
Select a scheduled request to run that request on-demand. A default validation is provided for each supported network protocol and service, which runs a network-wide validation check. These validations run every 60 minutes, but you may run them on-demand at any time.
Leave as is to create a new scheduled validation request
Select a scheduled request to modify
Protocols
For a selected scheduled validation, the protocols included in a validation request are listed here. For new on-demand or scheduled validations, click these to include them in the validation.
Schedule:
For a selected scheduled validation, the schedule and the time of the last run are displayed. For new scheduled validations, select the frequency and starting date and time.
Run Every: Select how often to run the request. Choose from 30 minutes, 1, 3, 6, or 12 hours, or 1 day.
Starting: Select the date and time to start the first request in the series
Last Run: Timestamp of when the selected validation was started
Scheduled Validations
Count of scheduled validations that are currently scheduled compared to the maximum of 15 allowed
Run Now
Start the validation request
Update
When changes are made to a selected validation request, Update becomes available so that you can save your changes.
Be aware, that if you update a previously saved validation request, the historical data collected will no longer match the data results of future runs of the request. If your intention is to leave this request unchanged and create a new request, click Save As New instead.
Save As New
When changes are made to a previously saved validation request, Save As New becomes available so that you can save the modified request as a new request.
The full screen Validation Request card displays all scheduled
validation requests.
Item
Description
Title
Validation Request
Closes full screen card and returns to workbench
Default Time
No time period is displayed for this card as each validation request has its own time relationship.
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
Validation Requests
Displays all scheduled validation requests. By default, the requests list is sorted by the date and time that it was originally created (Created At). This tab provides the following additional data about each request:
Name: Text identifier of the validation
Type: Name of network protocols and/or services included in the validation
Start Time: Data and time that the validation request was run
Last Modified: Date and time of the most recent change made to the validation request
Cadence (Min): How often, in minutes, the validation is scheduled to run. This is empty for new on-demand requests.
Is Active: Indicates whether the request is currently running according to its schedule (true) or it is not running (false)
Table Actions
Select, export, or filter the list. Refer to Table Settings.
Create On-demand and Scheduled Validation Requests
There are several types of validation requests that a user can make. Each has a slightly different flow through the Validation Request card,
and is therefore described separately. The types are based on the intent of the request:
When you want to validate the operation of one or more network protocols and services right now, you can create and run an on-demand validation
request using the large Validation Request card.
To create and run a request for a single protocol or service:
Open the small, medium or large Validation Request card.
Select the validation from the Validation dropdown list.
To create and run a request for more than one protocol and/or service:
Open the large Validation Request card.
Click the names of the protocols and services you want to validate.
We selected BGP and EVPN in this example.
Click Run Now to start the validation.
The associated on-demand validation result cards (one per protocol or service selected) are opened on your current workbench. Refer to View On-demand Validation Results.
Create a New Scheduled Validation Request
When you want to see validation results on a regular basis, it is useful to configure a scheduled validation request to avoid re-creating the
request each time.
To create and run a new scheduled validation:
Open the large Validation Request card.
Select the protocols and/or services you want to include in the validation. In this example we have chosen the Agents and NTP services.
Enter the schedule frequency (30 min, 1 hour, 3 hours, 6 hours, 12 hours, or 1 day) by selecting it from the Run every list. Default is hourly.
Select the time to start the validation runs, by clicking in the Starting field. Select a day and click Next, then select the starting time and click OK.
Verify the selections were made correctly.
Click Save As New.
Enter a name for the validation.
Spaces and special characters are not allowed in validation request names.
Click Save.
The validation can now be selected from the Validation listing (on the small, medium or large size card) and run immediately using Run Now, or you can wait for it to run the first time according to the schedule you specified. Refer to View Scheduled Validation Results. Note that the number of scheduled validations is now two (2).
Modify an Existing Scheduled Validation Request
At some point you might want to change the schedule or validation types that are specified in a scheduled validation request.
When you update a scheduled request, the results for all future runs of the validation will be different than the results of previous runs of the validation.
To modify a scheduled validation:
Open the large Validation Request card.
Select the validation from the Validation dropdown list.
Edit the schedule or validation types.
Click Update.
The validation can now be selected from the Validation listing (on the small, medium or large size card) and run immediately using Run Now, or you can wait for it to run the first time according to the schedule you specified. Refer to View Scheduled Validation Results.
View On-demand Validation Results
The On-demand Validation Result card workflow enables you to view the results of on-demand validation requests. When a request has started processing, the associated medium Validation Result card is displayed on your workbench. When multiple network protocols or services are included in a validation, a validation result card is opened for each protocol and service.
On-Demand Validation Result Card Workflow
The small Validation Result card displays:
Item
Description
Indicates an on-demand validation result
Title
On-demand Result <Network Protocol or Service Name> Validation
Timestamp
Date and time the validation was completed
,
Status of the validation job, where:
Good: Job ran successfully. One or more warnings may have occurred during the run.
Failed: Job encountered errors which prevented the job from completing, or job ran successfully, but errors occurred during the run.
The medium Validation Result card displays:
Item
Description
Indicates an on-demand validation result
Title
On-demand Validation Result | <Network Protocol or Service Name>
Timestamp
Date and time the validation was completed
, ,
Status of the validation job, where:
Good: Job ran successfully.
Warning: Job encountered issues, but it did complete its run.
Failed: Job encountered errors which prevented the job from completing.
Devices Tested
Chart with the total number of devices included in the validation and the distribution of the results.
Pass: Number of devices tested that had successful results
Warn: Number of devices tested that had successful results, but also had at least one warning event
Fail: Number of devices tested that had one or more protocol or service failures
Hover over chart to view the number of devices and the percentage of all tested devices for each result category.
Sessions Tested
For BGP, chart with total number of BGP sessions included in the validation and the distribution of the overall results.
For EVPN, chart with total number of BGP sessions included in the validation and the distribution of the overall results.
For Interfaces, chart with total number of ports included in the validation and the distribution of the overall results.
In each of these charts:
Pass: Number of sessions or ports tested that had successful results
Warn: Number of sessions or ports tested that had successful results, but also had at least one warning event
Fail: Number of sessions or ports tested that had one or more failure events
Hover over chart to view the number of devices, sessions, or ports and the percentage of all tested devices, sessions, or ports for each result category.
This chart does not apply to other Network Protocols and Services, and thus is not displayed for those cards.
Open <Service> Card
Click to open the corresponding medium Network Services card, where available. Refer to Monitor Network Performance for details about these cards and workflows.
The large Validation Result card contains two tabs.
The Summary tab displays:
Item
Description
Indicates an on-demand validation result
Title
On-demand Validation Result | Summary | <Network Protocol or Service Name>
Date
Day and time when the validation completed
, ,
Status of the validation job, where:
Good: Job ran successfully.
Warning: Job encountered issues, but it did complete its run.
Failed: Job encountered errors which prevented the job from completing.
Devices Tested
Chart with the total number of devices included in the validation and the distribution of the results.
Pass: Number of devices tested that had successful results
Warn: Number of devices tested that had successful results, but also had at least one warning event
Fail: Number of devices tested that had one or more protocol or service failures
Hover over chart to view the number of devices and the percentage of all tested devices for each result category.
Sessions Tested
For BGP, chart with total number of BGP sessions included in the validation and the distribution of the overall results.
For EVPN, chart with total number of BGP sessions included in the validation and the distribution of the overall results.
For Interfaces, chart with total number of ports included in the validation and the distribution of the overall results.
For OSPF, chart with total number of OSPF sessions included in the validation and the distribution of the overall results.
In each of these charts:
Pass: Number of sessions or ports tested that had successful results
Warn: Number of sessions or ports tested that had successful results, but also had at least one warning event
Fail: Number of sessions or ports tested that had one or more failure events
Hover over chart to view the number of devices, sessions, or ports and the percentage of all tested devices, sessions, or ports for each result category.
This chart does not apply to other Network Protocols and Services, and thus is not displayed for those cards.
Open <Service> Card
Click to open the corresponding medium Network Services card, when available. Refer to Monitor Network Performance for details about these cards and workflows.
Table/Filter options
When the Most Active filter option is selected, the table displays switches and hosts running the given service or protocol in decreasing order of alarm counts. Devices with the largest number of warnings and failures are listed first. You can click on the device name to open its switch card on your workbench.
When the Most Recent filter option is selected, the table displays switches and hosts running the given service or protocol sorted by timestamp, with the device with the most recent warning or failure listed first. The table provides the following additional information:
Hostname: User-defined name for switch or host
Message Type: Network protocol or service which triggered the event
Message: Short description of the event
Severity: Indication of importance of event; values in decreasing severity include critical, warning, error, info, debug
Show All Results
Click to open the full screen card with all on-demand validation results sorted by timestamp.
The Configuration tab displays:
Item
Description
Indicates an on-demand validation request configuration
Title
On-demand Validation Result | Configuration | <Network Protocol or Service Name>
Validations
List of network protocols or services included in the request that produced these results
Schedule
Not relevant to on-demand validation results. Value is always N/A.
The full screen Validation Result card provides a tab for all on-demand validation results.
Item
Description
Title
Validation Results | On-demand
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
On-demand Validation Result | <network protocol or service>
Displays all unscheduled validation results. By default, the results list is sorted by Timestamp. This tab provides the following additional data about each result:
Job ID: Internal identifier of the validation job that produced the given results
Timestamp: Date and time the validation completed
Type: Network protocol or service type
Total Node Count: Total number of nodes running the given network protocol or service
Checked Node Count: Number of nodes on which the validation ran
Failed Node Count: Number of checked nodes that had protocol or service failures
Rotten Node Count: Number of nodes that could not be reached during the validation
Unknown Node Count: Applies only to the Interfaces service. Number of nodes with unknown port states.
Failed Adjacent Count: Number of adjacent nodes that had protocol or service failures
Total Session Count: Total number of sessions running for the given network protocol or service
Failed Session Count: Number of sessions that had session failures
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View On-demand Validation Results
Once an on-demand validation request has completed, the results are available in the corresponding Validation Result card.
It may take a few minutes for all results to be presented if the load on the NetQ Platform is heavy at the time of the run.
To view the results:
Locate the medium on-demand Validation Result card on your workbench for the protocol or service that was run.
You can identify it by the on-demand result icon, , protocol or service name, and the date and time that it was run.
Note: You may have more than one card open for a given protocol or service, so be sure to use the date and time on the card to ensure you are viewing the correct card.
Note the total number and distribution of results for the tested devices and sessions (when appropriate). Are there many failures?
Hover over the charts to view the total number of warnings or failures and what percentage of the total results that represents for both devices and sessions.
Switch to the large on-demand Validation Result card.
If there are a large number of device warnings or failures, view the devices with the most issues in the table on the right. By default, this table displays the Most Active devices. Click on a device name to open its switch card on your workbench.
To view the most recent issues, select Most Recent from the filter above the table.
If there are a large number of devices or sessions with warnings or failures, the protocol or service may be experiencing issues. View the health of the protocol or service as a whole by clicking Open <network service> Card when available.
To view all data available for all on-demand validation results for a given protocol, switch to the full screen card.
Double-click in a given result row to open details about the validation.
From this view you can:
See a summary of the validation results by clicking in the banner under the title. Toggle the arrow to close the summary.
See detailed results of each test run to validate the protocol or service. When errors or warnings are present, the nodes and relevant detail is provided.
Export the data by clicking Export.
Return to the validation jobs list by clicking .
You may find that comparing various results gives you a clue as to why certain devices are experiencing more warnings or failures. For example, more failures occurred between certain times or on a particular device.
View Scheduled Validation Results
The Scheduled Validation Result card workflow enables you to view the results of scheduled validation requests. When a request has completed processing, you can access the Validation Result card from the full screen Validation Request card. Each protocol and service has its own validation result card, but the content is similar on each.
Scheduled Validation Result Card Workflow Summary
The small Scheduled Validation Result card displays:
Item
Description
Indicates a scheduled validation result
Title
Scheduled Result <Network Protocol or Service Name> Validation
Results
Summary of validation results:
Number of validation runs completed in the designated time period
Number of runs with warnings
Number of runs with errors
,
Status of the validation job, where:
Pass: Job ran successfully. One or more warnings may have occurred during the run.
Failed: Job encountered errors which prevented the job from completing, or job ran successfully, but errors occurred during the run.
The medium Scheduled Validation Result card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates a scheduled validation result
Title
Scheduled Validation Result | <Network Protocol or Service Name>
Summary
Summary of validation results:
Name of scheduled validation
Status of the validation job, where:
Pass: Job ran successfully. One or more warnings may have occurred during the run.
Failed: Job encountered errors which prevented the job from completing, or job ran successfully, but errors occurred during the run.
Chart
Validation results, where:
Time period: Range of time in which the data on the heat map was collected
Heat map: A time segmented view of the results. For each time segment, the color represents the percentage of warning, passing, and failed results. Refer to Validate Network Protocol and Service Operations for details on how to interpret the results.
Open <Service> Card
Click to open the corresponding medium Network Services card, when available. Refer to Monitor Network Performance for details about these cards and workflows.
The large Scheduled Validation Result card contains two tabs.
The Summary tab displays:
Item
Description
Indicates a scheduled validation result
Title
Validation Summary (Scheduled Validation Result | <Network Protocol or Service Name>)
Summary
Summary of validation results:
Name of scheduled validation
Status of the validation job, where:
Pass: Job ran successfully. One or more warnings may have occurred during the run.
Failed: Job encountered errors which prevented the job from completing, or job ran successfully, but errors occurred during the run.
Expand/Collapse: Expand the heat map to full width of card, collapse the heat map to the left
Chart
Validation results, where:
Time period: Range of time in which the data on the heat map was collected
Heat map: A time segmented view of the results. For each time segment, the color represents the percentage of warning, passing, and failed results. Refer to Validate Network Protocol and Service Operations for details on how to interpret the results.
Open <Service> Card
Click to open the corresponding medium Network Services card, when available. Refer to Monitor Network Performance for details about these cards and workflows.
Table/Filter options
When the Most Active filter option is selected, the table displays switches and hosts running the given service or protocol in decreasing order of alarm counts-devices with the largest number of warnings and failures are listed first.
When the Most Recent filter option is selected, the table displays switches and hosts running the given service or protocol sorted by timestamp, with the device with the most recent warning or failure listed first. The table provides the following additional information:
Hostname: User-defined name for switch or host
Message Type: Network protocol or service which triggered the event
Message: Short description of the event
Severity: Indication of importance of event; values in decreasing severity include critical, warning, error, info, debug
Show All Results
Click to open the full screen card with all scheduled validation results sorted by timestamp.
The Configuration tab displays:
Item
Description
Indicates a scheduled validation configuration
Title
Configuration (Scheduled Validation Result | <Network Protocol or Service Name>)
Name
User-defined name for this scheduled validation
Validations
List of validations included in the validation request that created this result
Schedule
User-defined schedule for the validation request that created this result
Open Schedule Card
Opens the large Validation Request card for editing this configuration
The full screen Scheduled Validation Result card provides tabs for all scheduled
validation results for the service.
Item
Description
Title
Scheduled Validation Results | <Network Protocol or Service>
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
Scheduled Validation Result | <network protocol or service>
Displays all unscheduled validation results. By default, the results list is sorted by timestamp. This tab provides the following additional data about each result:
Job ID: Internal identifier of the validation job that produced the given results
Timestamp: Date and time the validation completed
Type: Protocol of Service Name
Total Node Count: Total number of nodes running the given network protocol or service
Checked Node Count: Number of nodes on which the validation ran
Failed Node Count: Number of checked nodes that had protocol or service failures
Rotten Node Count: Number of nodes that could not be reached during the validation
Unknown Node Count: Applies only to the Interfaces service. Number of nodes with unknown port states.
Failed Adjacent Count: Number of adjacent nodes that had protocol or service failures
Total Session Count: Total number of sessions running for the given network protocol or service
Failed Session Count: Number of sessions that had session failures
Table Actions
Select, export, or filter the list. Refer to Table Settings.
Granularity of Data Shown Based on Time Period
On the medium and large Validation Result cards, the status of the runs is represented in heat maps stacked vertically; one for passing runs, one for runs with warnings, and one for runs with failures. Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all validations during that time period pass, then the middle block is 100% saturated (white) and the warning and failure blocks are zero % saturated (gray). As warnings and errors increase in saturation, the passing block is proportionally reduced in saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks and regions.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
View Scheduled Validation Results
Once a scheduled validation request has completed, the results are available in the corresponding Validation Result card.
To view the results:
Open the full size Validation Request card to view all scheduled validations.
Select the validation results you want to view by clicking in the first column of the result and clicking the check box.
On the Edit Menu that appears at the bottom of the window, click (Open Cards). This opens the medium Scheduled Validation Results card(s) for the selected items.
Note the distribution of results. Are there many failures? Are they concentrated together in time? Has the protocol or service recovered after the failures?
Hover over the heat maps to view the status numbers and what percentage of the total results that represents for a given region. The tooltip also shows the number of devices included in the validation and the number with warnings and/or failures. This is useful when you see the failures occurring on a small set of devices, as it might point to an issue with the devices rather than the network service.
Optionally, click Open <network service> Card link to open the medium individual Network Services card. Your current card is not closed.
Switch to the large Scheduled Validation card.
Click to expand the chart.
Collapse the heat map by clicking .
If there are a large number of warnings or failures, view the devices with the most issues by clicking Most Active in the filter above the table. This might help narrow the failures down to a particular device or small set of devices that you can investigate further.
Select the Most Recent filter above the table to see the events that have occurred in the near past at the top of the list.
Optionally, view the health of the protocol or service as a whole by clicking Open <network service> Card (when available).
You can view the configuration of the request that produced the results shown on this card workflow, by hovering over the card and clicking . If you want to change the configuration, click Edit Config to open the large Validation Request card, pre-populated with the current configuration. Follow the instructions in Modify an Existing Scheduled Validation Request to make your changes.
To view all data available for all scheduled validation results for the given protocol or service, click Show All Results or switch to the full screen card.
Look for changes and patterns in the results. Scroll to the right. Are there more failed sessions or nodes during one or more validations?
Double-click in a given result row to open details about the validation.
From this view you can:
See a summary of the validation results by clicking in the banner under the title. Toggle the arrow to close the summary.
See detailed results of each test run to validate the protocol or service. When errors or warnings are present, the nodes and relevant detail is provided.
Export the data by clicking Export.
Return to the validation jobs list by clicking .
You may find that comparing various results gives you a clue as to why certain devices are experiencing more warnings or failures. For example, more failures occurred between certain times or on a particular device.
Monitor Network Inventory
With NetQ, a network administrator can monitor both the switch hardware and its operating system for misconfigurations or misbehaving services. The Devices Inventory card workflow provides a view into the switches and hosts installed in your network and their various hardware and software components. The workflow contains a small card with a count of each device type in your network, a medium card displaying the operating systems running on each set of devices, large cards with component information statistics, and full-screen cards displaying tables with attributes of all switches and all hosts in your network.
The Devices Inventory card workflow helps answer questions such as:
What switches do I have in the network?
What is the distribution of ASICs across my network?
Do all switches have valid licenses?
Are NetQ agents running on all of my switches?
For monitoring inventory and performance on a switch-by-switch basis, refer to Monitor Switches.
Devices Inventory Card Workflow Summary
The small Devices Inventory card displays:
Item
Description
Indicates data is for device inventory
Total number of switches in inventory during the designated time period
Total number of hosts in inventory during the designated time period
The medium Devices Inventory card displays:
Item
Description
Indicates data is for device inventory
Title
Inventory | Devices
Total number of switches in inventory during the designated time period
Total number of hosts in inventory during the designated time period
Charts
Distribution of operating systems deployed on switches and hosts, respectively
The large Devices Inventory card has one tab.
The Switches tab displays:
Item
Description
Time period
Always Now for inventory by default
Indicates data is for device inventory
Title
Inventory | Devices
Total number of switches in inventory during the designated time period
Link to full screen listing of all switches
Component
Switch components monitored-ASIC, Operating System (OS), Cumulus Linux license, NetQ Agent version, and Platform
Distribution charts
Distribution of switch components across the network
Unique
Number of unique items of each component type. For example, for License, you might have CL 2.7.2 and CL 2.7.4, giving you a unique count of two.
The full screen Devices Inventory card provides tabs for all switches and all hosts.
Item
Description
Title
Inventory | Devices | Switches
Closes full screen card and returns to workbench
Time period
Time period does not apply to the Inventory cards. This is always Default Time.
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches and All Hosts tabs
Displays all monitored switches and hosts in your network. By default, the device list is sorted by hostname. These tabs provide the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.1.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples values include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
View the Number of Each Device Type in Your Network
You can view the number of switches and hosts deployed in your network. As you grow your network this can be useful for validating that devices have been added as scheduled.
To view the quantity of devices in your network, open the small Devices Inventory card.
Chassis are not monitored in this release, so an N/A (not applicable) value is displayed for these devices, even if you have chassis in your network.
View Which Operating Systems Are Running on Your Network Devices
You can view the distribution of operating systems running on your switches and hosts. This is useful for verifying which versions of the OS are deployed and for upgrade planning. It also provides a view into the relative dependence on a given OS in your network.
To view the OS distribution, open the medium Devices Inventory card if it is not already on your workbench.
View Switch Components
To view switch components, open the large Devices Inventory card. By default the Switches tab is shown displaying the total number of switches, ASIC vendor, OS versions, license status, NetQ Agent versions, and specific platforms deployed on all of your switches.
Highlight a Selected Component Type
You can hover over any of the segments in a component distribution chart to highlight a specific type of the given component. When you hover, a tooltip appears displaying:
the name or value of the component type, such as the version number or status
the total number of switches with that type of component deployed compared to the total number of switches
percentage of this type with respect to all component types.
Additionally, sympathetic highlighting is used to show the related component types relevant to the highlighted segment and the number of unique component types associated with this type (shown in blue here).
Focus on a Selected Component Type
To dig deeper on a particular component type, you can filter the card data by that type. In this procedure, the result of filtering on the OS is shown.
To view component type data:
Click a segment of the component distribution charts.
Select the first option from the popup, Filter <component name>. The card data is filtered to show only the components associated with selected component type. A filter tag appears next to the total number of switches indicating the filter criteria.
Hover over the segments to view the related components.
To return to the full complement of components, click the in the filter tag.
Navigate to the Switch Inventory Workflow
While the Device Inventory cards provide a network-wide view, you may want to see more detail about your switch inventory. This can be found in the Switches Inventory card workflow. To open that workflow, click the Switch Inventory button at the top right of the Switches card.
View All Switches
You can view all stored attributes for all switches in your network. To view all switch details, open the full screen Devices Inventory card and click the All Switches tab in the navigation panel.
To return to your workbench, click in the top right corner of the card.
View All Hosts
You can view all stored attributes for all hosts in your network. To view all hosts details, open the full screen Devices Inventory card and click the All Hosts tab in the navigation panel.
To return to your workbench, click in the top right corner of the card.
Monitor the BGP Service
The Cumulus NetQ UI enables operators to view the health of the BGP service on a network-wide and a per session basis, giving greater insight into all aspects of the service. This is accomplished through two card workflows, one for the service and one for the session. They are described separately here.
Monitor the BGP Service (All Sessions)
With NetQ, you can monitor the number of nodes running the BGP service, view switches with the most established and unestablished BGP sessions, and view alarms triggered by the BGP service. For an overview and how to configure BGP to run in your data center network, refer to Border Gateway Protocol - BGP.
BGP Service Card Workflow
The small BGP Service card displays:
Item
Description
Indicates data is for all sessions of a Network Service or Protocol
Title
BGP: All BGP Sessions, or the BGP Service
Total number of switches and hosts with the BGP service enabled during the designated time period
Total number of BGP-related alarms received during the designated time period
Chart
Distribution of new BGP-related alarms received during the designated time period
The medium BGP Service card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Network Services | All BGP Sessions
Total number of switches and hosts with the BGP service enabled during the designated time period
Total number of BGP-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the BGP service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running BGP last week or last month might be more or less than the number of nodes running BGP currently.
Total Open Alarms chart
Distribution of BGP-related alarms received during the designated time period, and the total number of current BGP-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Total Nodes Not Est. chart
Distribution of switches and hosts with unestablished BGP sessions during the designated time period, and the total number of unestablished sessions in the network currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of unestablished session last week or last month might be more of less than the number of nodes with unestablished sessions currently.
The large BGP service card contains two tabs.
The Sessions Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Sessions Summary (visible when you hover over card)
Total number of switches and hosts with the BGP service enabled during the designated time period
Total number of BGP-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the BGP service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running BGP last week or last month might be more or less than the number of nodes running BGP currently.
Total Nodes Not Est. chart
Distribution of switches and hosts with unestablished BGP sessions during the designated time period, and the total number of unestablished sessions in the network currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of unestablished session last week or last month might be more of less than the number of nodes with unestablished sessions currently.
Table/Filter options
When the Switches with Most Sessions filter option is selected, the table displays the switches and hosts running BGP sessions in decreasing order of session count-devices with the largest number of sessions are listed first
When the Switches with Most Unestablished Sessions filter option is selected, the table switches and hosts running BGP sessions in decreasing order of unestablished sessions-devices with the largest number of unestablished sessions are listed first
Show All Sessions
Link to view data for all BGP sessions in the full screen card
The Alarms tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
(in header)
Indicates data is for all alarms for all BGP sessions
Title
Alarms (visible when you hover over card)
Total number of switches and hosts with the BGP service enabled during the designated time period
(in summary bar)
Total number of BGP-related alarms received during the designated time period
Total Alarms chart
Distribution of BGP-related alarms received during the designated time period, and the total number of current BGP-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Table/Filter options
When the selected filter option is Switches with Most Alarms, the table displays switches and hosts running BGP in decreasing order of the count of alarms-devices with the largest number of BGP alarms are listed first
Show All Sessions
Link to view data for all BGP sessions in the full screen card
The full screen BGP Service card provides tabs for all switches, all sessions, and all alarms.
Item
Description
Title
Network Services | BGP
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches tab
Displays all switches and hosts running the BGP service. By default, the device list is sorted by hostname. This tab provides the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.2.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples values include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
All Sessions tab
Displays all BGP sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
ASN: Autonomous System Number, identifier for a collection of IP networks and routers. Example values include 633284,655435.
Conn Dropped: Number of dropped connections for a given session
Conn Estd: Number of connections established for a given session
DB State: Session state of DB
Evpn Pfx Rcvd: Address prefix received for EVPN traffic. Examples include 115, 35.
Ipv4, and Ipv6 Pfx Rcvd: Address prefix received for IPv4 or IPv6 traffic. Examples include 31, 14, 12.
Last Reset Time: Date and time at which the session was last established or reset
Objid: Object identifier for service
OPID: Customer identifier. This is always zero.
Peer
ASN: Autonomous System Number for peer device
Hostname: User-defined name for peer device
Name: Interface name or hostname of peer device
Router Id: IP address of router with access to the peer device
Reason: Text describing the cause of, or trigger for, an event
Rx and Tx Families: Address families supported for the receive and transmit session channels. Values include ipv4, ipv6, and evpn.
State: Current state of the session. Values include Established and NotEstd (not established).
Timestamp: Date and time session was started, deleted, updated or marked dead (device is down)
Upd8 Rx: Count of protocol messages received
Upd8 Tx: Count of protocol messages transmitted
Up Time: Number of seconds the session has been established, in EPOCH notation. Example: 1550147910000
Vrf: Name of the Virtual Route Forwarding interface. Examples: default, mgmt, DataVrf1081
Vrfid: Integer identifier of the VRF interface when used. Examples: 14, 25, 37
All Alarms tab
Displays all BGP events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Source: Hostname of network device that generated the event
Message: Text description of a BGP-related event. Example: BGP session with peer tor-1 swp7 vrf default state changed from failed to Established
Type: Network protocol or service generating the event. This always has a value of bgp in this card workflow.
Severity: Importance of the event. Values include critical, warning, info, and debug.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Service Status Summary
A summary of the BGP service is available from the Network Services card workflow, including the number of nodes running the service, the number of BGP-related alarms, and a distribution of those alarms.
To view the summary, open the small BGP Service card.
For more detail, select a different size BGP Service card.
View the Distribution of Sessions and Alarms
It is useful to know the number of network nodes running the BGP protocol over a period of time, as it gives you insight into the amount of traffic associated with and breadth of use of the protocol. It is also useful to compare the number of nodes running BGP with unestablished sessions with the alarms present at the same time to determine if there is any correlation between the issues and the ability to establish a BGP session.
To view these distributions, open the medium BGP Service card.
If a visual correlation is apparent, you can dig a little deeper with the large BGP Service card tabs.
View Devices with the Most BGP Sessions
You can view the load from BGP on your switches and hosts using the large Network Services card. This data enables you to see which switches are handling the most BGP traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most BGP sessions:
Open the large BGP Service card.
Select Switches With Most Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most BGP sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large BGP Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the original time. We chose Past Week for this example.
You can now see whether there are significant differences between this time and the original time. If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running BGP than previously, looking for changes in the topology, and so forth.
View Devices with the Most Unestablished BGP Sessions
You can identify switches and hosts that are experiencing difficulties establishing BGP sessions; both currently and in the past.
To view switches with the most unestablished BGP sessions:
Open the large BGP Service card.
Select Switches with Most Unestablished Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most unestablished BGP sessions at the top. Scroll down to view those with the fewest unestablished sessions.
Where to go next depends on what data you see, but a couple of options
include:
Change the time period for the data to compare with a prior time.
If the same switches are consistently indicating the most unestablished sessions, you might want to look more carefully at those switches using the Switches card workflow to determine probable causes. Refer to Monitor Switches.
Click Show All Sessions to investigate all BGP sessions with events in the full screen card.
View Devices with the Most BGP-related Alarms
Switches or hosts experiencing a large number of BGP alarms may indicate a configuration or performance issue that needs further investigation. You can view the devices sorted by the number of BGP alarms and then use the Switches card workflow or the Alarms card workflow to gather more information about possible causes for the alarms.
To view switches with the most BGP alarms:
Open the large BGP Service card.
Hover over the header and click .
Select Switches with Most Alarms from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most BGP alarms at the top. Scroll down to view those with the fewest alarms.
Where to go next depends on what data you see, but a few options
include:
Change the time period for the data to compare with a prior time.
If the same switches are consistently indicating the most alarms, you might want to look more carefully at those switches using the Switches card workflow.
Click Show All Sessions to investigate all BGP sessions with events in the full screen card.
View All BGP Events
The BGP Network Services card workflow enables you to view all of the BGP events in the designated time period.
To view all BGP events:
Open the full screen BGP Service card.
Click All Alarms tab in the navigation panel.
By default, events are listed in most recent to least recent order.
Where to go next depends on what data you see, but a couple of options
include:
Sort the list by message to see how many devices have had the same issue.
Open one of the other full screen tabs in this flow to focus on devices or sessions.
Export the data for use in another analytics tool, by clicking and providing a name for the data file.
To return to your workbench, click in the top right corner.
View Details for All Devices Running BGP
You can view all stored attributes of all switches and hosts running BGP in your network in the full screen card.
To view all device details, open the full screen BGP Service card and click the All Switches tab.
To return to your workbench, click in the top right corner.
View Details for All BGP Sessions
You can view all stored attributes of all BGP sessions in your network in the full-screen card.
To view all session details, open the full screen BGP Service card and click the All Sessions tab.
To return to your workbench, click in the top right corner.
Use the icons above the table to select/deselect, filter, and export items in the list. Refer to Table Settings for more detail.
To return to original display of results, click the associated tab.
Monitor a Single BGP Session
With NetQ, you can monitor a single session of the BGP service, view session state changes, and compare with alarms occurring at the same time, as well as monitor the running BGP configuration and changes to the configuration file. For an overview and how to configure BGP to run in your data center network, refer to Border Gateway Protocol - BGP.
To access the single session cards, you must open the full screen BGP Service, click the All Sessions tab, select the desired session, then click (Open Cards).
Granularity of Data Shown Based on Time Period
On the medium and large single BGP session cards, the status of the sessions is represented in heat maps stacked vertically; one for established sessions, and one for unestablished sessions. Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all sessions during that time period were established for the entire time block, then the top block is 100% saturated (white) and the not established block is zero percent saturated (gray). As sessions that are not established increase in saturation, the sessions that are established block is proportionally reduced in saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
BGP Session Card Workflow Summary
The small BGP Session card displays:
Item
Description
Indicates data is for a single session of a Network Service or Protocol
Title
BGP Session
Hostnames of the two devices in a session. Arrow points from the host to the peer.
,
Current status of the session, either established or not established
The medium BGP Session card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
Network Services | BGP Session
Hostnames of the two devices in a session. Arrow points in the direction of the session.
,
Current status of the session, either established or not established
Time period for chart
Time period for the chart data
Session State Changes Chart
Heat map of the state of the given session over the given time period. The status is sampled at a rate consistent with the time period. For example, for a 24 hour period, a status is collected every hour. Refer to Granularity of Data Shown Based on Time Period.
Peer Name
Interface name on or hostname for peer device
Peer ASN
Autonomous System Number for peer device
Peer Router ID
IP address of router with access to the peer device
Peer Hostname
User-defined name for peer device
The large BGP Session card contains two tabs.
The Session Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
Session Summary (Network Services | BGP Session)
Summary bar
Hostnames of the two devices in a session.
Current status of the session-either established , or not established
Session State Changes Chart
Heat map of the state of the given session over the given time period. The status is sampled at a rate consistent with the time period. For example, for a 24 hour period, a status is collected every hour. Refer to Granularity of Data Shown Based on Time Period.
Alarm Count Chart
Distribution and count of BGP alarm events over the given time period.
Info Count Chart
Distribution and count of BGP info events over the given time period.
Connection Drop Count
Number of times the session entered the not established state during the time period
ASN
Autonomous System Number for host device
RX/TX Families
Receive and Transmit address types supported. Values include IPv4, IPv6, and EVPN.
Peer Hostname
User-defined name for peer device
Peer Interface
Interface on which the session is connected
Peer ASN
Autonomous System Number for peer device
Peer Router ID
IP address of router with access to the peer device
The Configuration File Evolution tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates configuration file information for a single session of a Network Service or Protocol
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Click on to open associated device card.
,
Indication of host role, primary or secondary
Timestamps
When changes to the configuration file have occurred, the date and time are indicated. Click the time to see the changed file.
Configuration File
When File is selected, the configuration file as it was at the selected time is shown.
When Diff is selected, the configuration file at the selected time is shown on the left and the configuration file at the previous timestamp is shown on the right. Differences are highlighted.
Note: If no configuration file changes have been made, only the original file date is shown.
The full screen BGP Session card provides tabs for all BGP sessions and all events.
Item
Description
Title
Network Services | BGP
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All BGP Sessions tab
Displays all BGP sessions running on the host device. This tab provides the following additional data about each session:
ASN: Autonomous System Number, identifier for a collection of IP networks and routers. Example values include 633284,655435.
Conn Dropped: Number of dropped connections for a given session
Conn Estd: Number of connections established for a given session
DB State: Session state of DB
Evpn Pfx Rcvd: Address prefix for EVPN traffic. Examples include 115, 35.
Ipv4, and Ipv6 Pfx Rcvd: Address prefix for IPv4 or IPv6 traffic. Examples include 31, 14, 12.
Last Reset Time: Time at which the session was last established or reset
Objid: Object identifier for service
OPID: Customer identifier. This is always zero.
Peer
ASN: Autonomous System Number for peer device
Hostname: User-defined name for peer device
Name: Interface name or hostname of peer device
Router Id: IP address of router with access to the peer device
Reason: Event or cause of failure
Rx and Tx Families: Address families supported for the receive and transmit session channels. Values include ipv4, ipv6, and evpn.
State: Current state of the session. Values include Established and NotEstd (not established).
Timestamp: Date and time session was started, deleted, updated or marked dead (device is down)
Upd8 Rx: Count of protocol messages received
Upd8 Tx: Count of protocol messages transmitted
Up Time: Number of seconds the session has be established, in EPOC notation. Example: 1550147910000
Vrf: Name of the Virtual Route Forwarding interface. Examples: default, mgmt, DataVrf1081
Vrfid: Integer identifier of the VRF interface when used. Examples: 14, 25, 37
All Events tab
Displays all events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a BGP-related event. Example: BGP session with peer tor-1 swp7 vrf default state changed from failed to Established
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of bgp in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Session Status Summary
A summary of the BGP session is available from the BGP Session card
workflow, showing the node and its peer and current status.
To view the summary:
Add the Network Services | All BGP Sessions card.
Switch to the full screen card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
Optionally, switch to the small BGP Session card.
View BGP Session State Changes
You can view the state of a given BGP session from the medium and large BGP Session Network Service cards. For a given time period, you can determine the stability of the BGP session between two devices. If you experienced connectivity issues at a particular time, you can use these cards to help verify the state of the session. If it was not established more than it was established, you can then investigate further into possible causes.
To view the state transitions for a given BGP session, on the medium BGP Session card:
Add the Network Services | All BGP Sessions card.
Switch to the full screen card.
Open the large BGP Service card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
The heat map indicates the status of the session over the designated time period. In this example, the session has been established for the entire time period.
From this card, you can also view the Peer ASN, name, hostname and router id identifying the session in more detail.
To view the state transitions for a given BGP session on the large BGP Session card, follow the same steps to open the medium BGP Session card and then switch to the large card.
From this card, you can view the alarm and info event counts, Peer ASN, hostname, and router id, VRF, and Tx/Rx families identifying the session in more detail. The Connection Drop Count gives you a sense of the session performance.
View Changes to the BGP Service Configuration File
Each time a change is made to the configuration file for the BGP service, NetQ logs the change and enables you to compare it with the last version. This can be useful when you are troubleshooting potential causes for alarms or sessions losing their connections.
To view the configuration file changes:
Open the large BGP Session card.
Hover over the card and click to open the BGP Configuration File Evolution tab.
Select the time of interest on the left; when a change may have impacted the performance. Scroll down if needed.
Choose between the File view and the Diff view (selected option is dark; File by default).
The File view displays the content of the file for you to review.
The Diff view displays the changes between this version (on left) and the most recent version (on right) side by side. The changes are highlighted, as seen in this example.
View All BGP Session Details
You can view all stored attributes of all of the BGP sessions associated with the two devices on this card.
To view all session details, open the full screen BGP Session card, and click the All BGP Sessions tab.
To return to your workbench, click in the top right corner.
View All Events
You can view all of the alarm and info events for the two devices on this card.
To view all events, open the full screen BGP Session card, and click the All Events tab.
To return to your workbench, click in the top right corner.
Monitor the EVPN Service
The Cumulus NetQ UI enables operators to view the health of the EVPN service on a network-wide and a per session basis, giving greater insight into all aspects of the service. This is accomplished through two card workflows, one for the service and one for the session. They are described separately here.
Monitor the EVPN Service (All Sessions)
With NetQ, you can monitor the number of nodes running the EVPN service, view switches with the sessions, total number of VNIs, and alarms triggered by the EVPN service. For an overview and how to configure EVPN in your data center network, refer to Ethernet Virtual Private Network-EVPN.
EVPN Service Card Workflow Summary
The small EVPN Service card displays:
Item
Description
Indicates data is for all sessions of a Network Service or Protocol
Title
EVPN: All EVPN Sessions, or the EVPN Service
Total number of switches and hosts with the EVPN service enabled during the designated time period
Total number of EVPN-related alarms received during the designated time period
Chart
Distribution of EVPN-related alarms received during the designated time period
The medium EVPN Service card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Network Services | All EVPN Sessions
Total number of switches and hosts with the EVPN service enabled during the designated time period
Total number of EVPN-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the EVPN service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running EVPN last week or last month might be more or less than the number of nodes running EVPN currently.
Total Open Alarms chart
Distribution of EVPN-related alarms received during the designated time period, and the total number of current EVPN-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Total Sessions chart
Distribution of EVPN sessions during the designated time period, and the total number of sessions running on the network currently.
The large EVPN service card contains two tabs.
The Sessions Summary tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Sessions Summary (visible when you hover over card)
Total number of switches and hosts with the EVPN service enabled during the designated time period
Total number of EVPN-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the EVPN service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running EVPN last week or last month might be more or less than the number of nodes running EVPN currently.
Total Sessions chart
Distribution of EVPN sessions during the designated time period, and the total number of sessions running on the network currently.
Total L3 VNIs chart
Distribution of layer 3 VXLAN Network Identifiers during this time period, and the total number of VNIs in the network currently.
Table/Filter options
When the Top Switches with Most Sessions filter is selected, the table displays devices running EVPN sessions in decreasing order of session count-devices with the largest number of sessions are listed first.
When the Switches with Most L2 EVPN filter is selected, the table displays devices running layer 2 EVPN sessions in decreasing order of session count-devices with the largest number of sessions are listed first.
When the Switches withMost L3 EVPN filter is selected, the table displays devices running layer 3 EVPN sessions in decreasing order of session count-devices with the largest number of sessions are listed first.
Show All Sessions
Link to view data for all EVPN sessions network-wide in the full screen card
The Alarms tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
(in header)
Indicates data is for all alarms for all sessions of a Network Service or Protocol
Title
Alarms (visible when you hover over card)
Total number of switches and hosts with the EVPN service enabled during the designated time period
(in summary bar)
Total number of EVPN-related alarms received during the designated time period
Total Alarms chart
Distribution of EVPN-related alarms received during the designated time period, and the total number of current BGP-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Table/Filter options
When the Events by Most Active Device filter is selected, the table displays devices running EVPN sessions in decreasing order of alarm count-devices with the largest number of alarms are listed first
Show All Sessions
Link to view data for all EVPN sessions in the full screen card
The full screen EVPN Service card provides tabs for all switches, all sessions, all alarms.
Item
Description
Title
Network Services | EVPN
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches tab
Displays all switches and hosts running the EVPN service. By default, the device list is sorted by hostname. This tab provides the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.1.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
All Sessions tab
Displays all EVPN sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Adv All Vni: Indicates whether the VNI state is advertising all VNIs (true) or not (false)
Adv Gw Ip: Indicates whether the host device is advertising the gateway IP address (true) or not (false)
DB State: Session state of the DB
Export RT: IP address and port of the export route target used in the filtering mechanism for BGP route exchange
Import RT: IP address and port of the import route target used in the filtering mechanism for BGP route exchange
In Kernel: Indicates whether the associated VNI is in the kernel (in kernel) or not (not in kernel)
Is L3: Indicates whether the session is part of a layer 3 configuration (true) or not (false)
Origin Ip: Host device's local VXLAN tunnel IP address for the EVPN instance
OPID: LLDP service identifier
Rd: Route distinguisher used in the filtering mechanism for BGP route exchange
Timestamp: Date and time the session was started, deleted, updated or marked as dead (device is down)
Vni: Name of the VNI where session is running
All Alarms tab
Displays all EVPN events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a EVPN-related event. Example: VNI 3 kernel state changed from down to up
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of evpn in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Service Status Summary
A summary of the EVPN service is available from the Network Services card workflow, including the number of nodes running the service, the number of EVPN-related alarms, and a distribution of those alarms.
To view the summary, open the small EVPN Network Service card.
For more detail, select a different size EVPN Network Service card.
View the Distribution of Sessions and Alarms
It is useful to know the number of network nodes running the EVPN protocol over a period of time, as it gives you insight into the amount of traffic associated with and breadth of use of the protocol. It is also useful to compare the number of nodes running EVPN with the alarms present at the same time to determine if there is any correlation between the issues and the ability to establish an EVPN session.
To view these distributions, open the medium EVPN Service card.
If a visual correlation is apparent, you can dig a little deeper with the large EVPN Service card tabs.
View the Distribution of Layer 3 VNIs
It is useful to know the number of layer 3 VNIs, as it gives you insight into the complexity of the VXLAN.
To view this distribution, open the large EVPN Service card and view the bottom chart on the left.
View Devices with the Most EVPN Sessions
You can view the load from EVPN on your switches and hosts using the large EVPN Service card. This data enables you to see which switches are handling the most EVPN traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most EVPN sessions:
Open the large EVPN Service card.
Select Top Switches with Most Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most EVPN sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large EVPN Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the current time.
You can now see whether there are significant differences between this time period and the previous time period.
If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running EVPN than previously, looking for changes in the topology, and so forth.
View Devices with the Most Layer 2 EVPN Sessions
You can view the number layer 2 EVPN sessions on your switches and hosts using the large EVPN Service card. This data enables you to see which switches are handling the most EVPN traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most layer 2 EVPN sessions:
Open the large EVPN Service card.
Select Switches with Most L2 EVPN from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most layer 2 EVPN sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large EVPN Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the current time.
You can now see whether there are significant differences between this time period and the previous time period.
If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running EVPN than previously, looking for changes in the topology, and so forth.
View Devices with the Most Layer 3 EVPN Sessions
You can view the number layer 3 EVPN sessions on your switches and hosts using the large EVPN Service card. This data enables you to see which switches are handling the most EVPN traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most layer 3 EVPN sessions:
Open the large EVPN Service card.
Select Switches with Most L3 EVPN from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most layer 3 EVPN sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large EVPN Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the current time.
You can now see whether there are significant differences between this time period and the previous time period.
If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running EVPN than previously, looking for changes in the topology, and so forth.
View Devices with the Most EVPN-related Alarms
Switches experiencing a large number of EVPN alarms may indicate a configuration or performance issue that needs further investigation. You can view the switches sorted by the number of BGP alarms and then use the Switches card workflow or the Alarms card workflow to gather more information about possible causes for the alarms.
To view switches with the most EVPN alarms:
Open the large EVPN Service card.
Hover over the header and click .
Select Events by Most Active Device from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most EVPN alarms at the top. Scroll down to view those with the fewest alarms.
Where to go next depends on what data you see, but a few options include:
Hover over the Total Alarms chart to focus on the switches exhibiting alarms during that smaller time slice. The table content changes to match the hovered content. Click on the chart to persist the table changes.
Change the time period for the data to compare with a prior time. If the same switches are consistently indicating the most alarms, you might want to look more carefully at those switches using the Switches card workflow.
Click Show All Sessions to investigate all EVPN sessions network-wide in the full screen card.
View All EVPN Events
The EVPN Service card workflow enables you to view all of the EVPN events in the designated time period.
To view all EVPN events:
Open the full screen EVPN Service card.
Click All Alarms tab in the navigation panel. By default, events are sorted by Time, with most recent events listed first.
Where to go next depends on what data you see, but a few options
include:
Open one of the other full screen tabs in this flow to focus on devices or sessions.
Sort by the Message or Severity to narrow your focus.
Export the data for use in another analytics tool, by selecting all or some of the events and clicking .
Click at the top right to return to your workbench.
View Details for All Devices Running EVPN
You can view all stored attributes of all switches running EVPN in your network in the full screen card.
To view all switch and host details, open the full screen EVPN Service card, and click the All Switches tab.
To return to your workbench, click at the top right.
View Details for All EVPN Sessions
You can view all stored attributes of all EVPN sessions in your network in the full screen card.
To view all session details, open the full screen EVPN Service card, and click the All Sessions tab.
To return to your workbench, click at the top right.
Use the icons above the table to select/deselect, filter, and export items in the list. Refer to Table Settings for more detail.
To return to original display of results, click the associated tab.
Monitor a Single EVPN Session
With NetQ, you can monitor the performance of a single EVPN session, including the number of associated VNI, VTEPs and type. For an overview and how to configure EVPN in your data center network, refer to Ethernet Virtual Private Network - EVPN.
To access the single session cards, you must open the full screen EVPN Service, click the All Sessions tab, select the desired session, then click (Open Cards).
EVPN Session Card Workflow Summary
The small EVPN Session card displays:
Item
Description
Indicates data is for an EVPN session
Title
EVPN Session
VNI Name
Name of the VNI (virtual network instance) used for this EVPN session
Current VNI Nodes
Total number of VNI nodes participating in the EVPN session currently
The medium EVPN Session card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for an EVPN session
Title
Network Services | EVPN Session
Summary bar
VTEP (VXLAN Tunnel EndPoint) Count: Total number of VNI nodes participating in the EVPN session currently
VTEP Count Over Time chart
Distribution of VTEP counts during the designated time period
VNI Name
Name of the VNI used for this EVPN session
Type
Indicates whether the session is established as part of a layer 2 or layer 3 overlay network
The large EVPN Session card contains two tabs.
The Session Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for an EVPN session
Title
Session Summary (Network Services | EVPN Session)
Summary bar
VTEP (VXLAN Tunnel EndPoint) Count: Total number of VNI devices participating in the EVPN session currently
VTEP Count Over Time chart
Distribution of VTEPs during the designated time period
Alarm Count chart
Distribution of alarms during the designated time period
Info Count chart
Distribution of info events during the designated time period
Table
VRF (for layer 3) or VLAN (for layer 2) identifiers by device
The Configuration File Evolution tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates configuration file information for a single session of a Network Service or Protocol
When changes to the configuration file have occurred, the date and time are indicated. Click the time to see the changed file.
Configuration File
When File is selected, the configuration file as it was at the selected time is shown.
When Diff is selected, the configuration file at the selected time is shown on the left and the configuration file at the previous timestamp is shown on the right. Differences are highlighted.
Note: If no configuration file changes have been made, only the original file date is shown.
The full screen EVPN Session card provides tabs for all EVPN sessions
and all events.
Item
Description
Title
Network Services | EVPN
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All EVPN Sessions tab
Displays all EVPN sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Adv All Vni: Indicates whether the VNI state is advertising all VNIs (true) or not (false)
Adv Gw Ip: Indicates whether the host device is advertising the gateway IP address (true) or not (false)
DB State: Session state of the DB
Export RT: IP address and port of the export route target used in the filtering mechanism for BGP route exchange
Import RT: IP address and port of the import route target used in the filtering mechanism for BGP route exchange
In Kernel: Indicates whether the associated VNI is in the kernel (in kernel) or not (not in kernel)
Is L3: Indicates whether the session is part of a layer 3 configuration (true) or not (false)
Origin Ip: Host device's local VXLAN tunnel IP address for the EVPN instance
OPID: LLDP service identifier
Rd: Route distinguisher used in the filtering mechanism for BGP route exchange
Timestamp: Date and time the session was started, deleted, updated or marked as dead (device is down)
Vni: Name of the VNI where session is running
All Events tab
Displays all events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a EVPN-related event. Example: VNI 3 kernel state changed from down to up
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of evpn in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Session Status Summary
A summary of the EVPN session is available from the EVPN Session card workflow, showing the node and its peer and current status.
To view the summary:
Add the Network Services | All EVPN Sessions card.
Switch to the full screen card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
Optionally, switch to the small EVPN Session card.
For more detail, select a different size EVPN Session card.
View VTEP Count
You can view the count of VTEPs for a given EVPN session from the medium
and large EVPN Session cards.
To view the count for a given EVPN session, on the medium EVPN Session
card:
Add the Network Services | All EVPN Sessions card.
Switch to the full screen card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
To view the count for a given EVPN session on the large EVPN Session card, follow the same steps as for the medium card and then switch to the large card.
View All EVPN Session Details
You can view all stored attributes of all of the EVPN sessions running network-wide.
To view all session details, open the full screen EVPN Session card and click the All EVPN Sessions tab.
To return to your workbench, click in the top right of the card.
View All Events
You can view all of the alarm and info events occurring network wide.
To view all events, open the full screen EVPN Session card and click the All Events tab.
Where to go next depends on what data you see, but a few options include:
Open one of the other full screen tabs in this flow to focus on sessions.
Sort by the Message or Severity to narrow your focus.
Export the data for use in another analytics tool, by selecting all or some of the events and clicking .
Click at the top right to return to your workbench.
Monitor the LLDP Service
The Cumulus NetQ UI enables operators to view the health of the LLDP service on a network-wide and a per session basis, giving greater insight into all aspects of the service. This is accomplished through two card workflows, one for the service and one for the session. They are described separately here.
Monitor the LLDP Service (All Sessions)
With NetQ, you can monitor the number of nodes running the LLDP service, view nodes with the most LLDP neighbor nodes, those nodes with the least neighbor nodes, and view alarms triggered by the LLDP service. For an overview and how to configure LLDP in your data center network, refer to Link Layer Discovery Protocol.
LLDP Service Card Workflow Summary
The small LLDP Service card displays:
Item
Description
Indicates data is for all sessions of a Network Service or Protocol
Title
LLDP: All LLDP Sessions, or the LLDP Service
Total number of switches with the LLDP service enabled during the designated time period
Total number of LLDP-related alarms received during the designated time period
Chart
Distribution of LLDP-related alarms received during the designated time period
The medium LLDP Service card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
LLDP: All LLDP Sessions, or the LLDP Service
Total number of switches with the LLDP service enabled during the designated time period
Total number of LLDP-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the LLDP service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running LLDP last week or last month might be more or less than the number of nodes running LLDP currently.
Total Open Alarms chart
Distribution of LLDP-related alarms received during the designated time period, and the total number of current LLDP-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Total Sessions chart
Distribution of LLDP sessions running during the designated time period, and the total number of sessions running on the network currently.
The large LLDP service card contains two tabs.
The Sessions Summary tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Sessions Summary (Network Services | All LLDP Sessions)
Total number of switches with the LLDP service enabled during the designated time period
Total number of LLDP-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the LLDP service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running LLDP last week or last month might be more or less than the number of nodes running LLDP currently.
Total Sessions chart
Distribution of LLDP sessions running during the designated time period, and the total number of sessions running on the network currently
Total Sessions with No Nbr chart
Distribution of LLDP sessions missing neighbor information during the designated time period, and the total number of session missing neighbors in the network currently
Table/Filter options
When the Switches with Most Sessions filter is selected, the table displays switches running LLDP sessions in decreasing order of session count-devices with the largest number of sessions are listed first
When the Switches with Most Unestablished Sessions filter is selected, the table displays switches running LLDP sessions in decreasing order of unestablished session count-devices with the largest number of unestablished sessions are listed first
Show All Sessions
Link to view all LLDP sessions in the full screen card
The Alarms tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
(in header)
Indicates data is all alarms for all LLDP sessions
Title
Alarms (visible when you hover over card)
Total number of switches with the LLDP service enabled during the designated time period
(in summary bar)
Total number of LLDP-related alarms received during the designated time period
Total Alarms chart
Distribution of LLDP-related alarms received during the designated time period, and the total number of current LLDP-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Table/Filter options
When the Events by Most Active Device filter is selected, the table displays switches running LLDP sessions in decreasing order of alarm count-devices with the largest number of sessions are listed first
Show All Sessions
Link to view all LLDP sessions in the full screen card
The full screen LLDP Service card provides tabs for all switches, all sessions, and all alarms.
Item
Description
Title
Network Services | LLDP
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches tab
Displays all switches and hosts running the LLDP service. By default, the device list is sorted by hostname. This tab provides the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.1.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
All Sessions tab
Displays all LLDP sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Ifname: Name of the host interface where LLDP session is running
LLDP Peer:
Os: Operating system (OS) used by peer device. Values include Cumulus Linux, RedHat, Ubuntu, and CentOS.
Osv: Version of the OS used by peer device. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Bridge: Indicates whether the peer device is a bridge (true) or not (false)
Router: Indicates whether the peer device is a router (true) or not (false)
Station: Indicates whether the peer device is a station (true) or not (false)
Peer:
Hostname: User-defined name for the peer device
Ifname: Name of the peer interface where the session is running
Timestamp: Date and time that the session was started, deleted, updated, or marked dead (device is down)
All Alarms tab
Displays all LLDP events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a LLDP-related event. Example: LLDP Session with host leaf02 swp6 modified fields leaf06 swp21
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of lldp in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Service Status Summary
A summary of the LLDP service is available from the Network Services card workflow, including the number of nodes running the service, the number of LLDP-related alarms, and a distribution of those alarms.
To view the summary, open the small LLDP Service card.
In this example, there are no LLDP alarms present on the network of 14 devices.
For more detail, select a different size LLDP Network Services card.
View the Distribution of Nodes, Alarms, and Sessions
It is useful to know the number of network nodes running the LLDP protocol over a period of time, as it gives you insight into nodes that might be misconfigured or experiencing communication issues. Additionally, if there are a large number of alarms, it is worth investigating either the service or particular devices.
To view the distribution, open the medium LLDP Service card.
In this example, we see that 13 nodes are running the LLDP protocol, that there are 52 sessions established, and that no LLDP-related alarms have occurred in the last 24 hours.
View the Distribution of Missing Neighbors
You can view the number of missing neighbors in any given time period and how that number has changed over time. This is a good indicator of link communication issues.
To view the distribution, open the large LLDP Service card and view the bottom chart on the left, Total Sessions with No Nbr.
In this example, we see that 16 of the 52 sessions are missing the neighbor (peer) device.
View Devices with the Most LLDP Sessions
You can view the load from LLDP on your switches using the large LLDP Service card. This data enables you to see which switches are handling the most LLDP traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most LLDP sessions:
Open the large LLDP Service card.
Select Switches with Most Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most LLDP sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large LLDP Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the current time. You can now see whether there are significant differences between this time period and the previous time period.
In this case, notice that their are fewer nodes running the protocol, but the total number of sessions running has nearly doubled. If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running LLDP than previously, looking for changes in the topology, and so forth.
View Devices with the Most Unestablished LLDP Sessions
You can identify switches that are experiencing difficulties establishing LLDP sessions; both currently and in the past.
To view switches with the most unestablished LLDP sessions:
Open the large LLDP Service card.
Select Switches with Most Unestablished Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most unestablished CLAG sessions at the top. Scroll down to view those with the fewest unestablished sessions.
Where to go next depends on what data you see, but a few options include:
Change the time period for the data to compare with a prior time.
If the same switches are consistently indicating the most unestablished sessions, you might want to look more carefully at those switches using the Switches card workflow to determine probable causes. Refer to Monitor Switches.
Click Show All Sessions to investigate all LLDP sessions with events in the full screen card.
View Switches with the Most LLDP-related Alarms
Switches experiencing a large number of LLDP alarms may indicate a configuration or performance issue that needs further investigation. You can view the switches sorted by the number of LLDP alarms and then use the Switches card workflow or the Alarms card workflow to gather more information about possible causes for the alarms.
To view switches with most LLDP alarms:
Open the large LLDP Service card.
Hover over the header and click .
Select Events by Most Active Device from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most BGP alarms at the top. Scroll down to view those with the fewest alarms.
Where to go next depends on what data you see, but a few options include:
Hover over the Total Alarms chart to focus on the switches exhibiting alarms during that smaller time slice. The table content changes to match the hovered content. Click on the chart to persist the table changes.
Change the time period for the data to compare with a prior time. If the same switches are consistently indicating the most alarms, you might want to look more carefully at those switches using the Switches card workflow.
Click Show All Sessions to investigate all switches running LLDP sessions in the full screen card.
View All LLDP Events
The LLDP Network Services card workflow enables you to view all of the LLDP events in the designated time period.
To view all LLDP events:
Open the full screen LLDP Service card.
Click the All Alarms tab.
Where to go next depends on what data you see, but a few options include:
Open the All Switches or All Sessions tabs to look more closely at the alarms from the switch or session perspective.
Sort on other parameters:
by Message to determine the frequency of particular events
by Severity to determine the most critical events
by Time to find events that may have occurred at a particular time to try to correlate them with other system events
Export data to a file
Return to your workbench by clicking in the top right corner
View Details About All Switches Running LLDP
You can view all stored attributes of all switches running LLDP in your network in the full screen card.
To view all switch details, open the LLDP Service card, and click the All Switches tab.
Return to your workbench by clicking in the top right corner.
View Detailed Information About All LLDP Sessions
You can view all stored attributes of all LLDP sessions in your network
in the full screen card.
To view all session details, open the LLDP Service card, and click the
All Sessions tab.
Return to your workbench by clicking in the top right corner.
Use the icons above the table to select/deselect, filter, and export items in the list. Refer to Table Settings for more detail. To return to original display of results, click the associated tab.
Monitor a Single LLDP Session
With NetQ, you can monitor the number of nodes running the LLDP service, view neighbor state changes, and compare with events occurring at the same time, as well as monitor the running LLDP configuration and changes to the configuration file. For an overview and how to configure LLDP in your data center network, refer to Link Layer Discovery Protocol.
To access the single session cards, you must open the full screen LLDP Service card, click the All Sessions tab, select the desired session, then click (Open Cards).
Granularity of Data Shown Based on Time Period
On the medium and large single LLDP session cards, the status of the neighboring peers is represented in heat maps stacked vertically; one for peers that are reachable (neighbor detected), and one for peers that are unreachable (neighbor not detected). Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all peers during that time period were detected for the entire time block, then the top block is 100% saturated (white) and the neighbor not detected block is zero percent saturated (gray). As peers become reachable, the neighbor detected block increases in saturation, the peers that are unreachable (neighbor not detected) block is proportionally reduced in saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
LLDP Session Card Workflow Summary
The small LLDP Session card displays:
Item
Description
Indicates data is for a single session of a Network Service or Protocol
Title
LLDP Session
Host and peer devices in session. Host is shown on top, with peer below.
,
Indicates whether the host sees the peer or not; has a peer, no peer
The medium LLDP Session card displays:
Item
Description
Time period
Range of time in which the displayed data was collected
Indicates data is for a single session of a Network Service or Protocol
Title
LLDP Session
Host and peer devices in session. Arrow points from host to peer.
,
Indicates whether the host sees the peer or not; has a peer, no peer
Time period
Range of time for the distribution chart
Heat map
Distribution of neighbor availability (detected or undetected) during this given time period
Hostname
User-defined name of the host device
Interface Name
Software interface on the host device where the session is running
Peer Hostname
User-defined name of the peer device
Peer Interface Name
Software interface on the peer where the session is running
The large LLDP Session card contains two tabs.
The Session Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected
Indicates data is for a single session of a Network Service or Protocol
Title
Summary Session (Network Services | LLDP Session)
Host and peer devices in session. Arrow points from host to peer.
,
Indicates whether the host sees the peer or not; has a peer, no peer
Heat map
Distribution of neighbor state (detected or undetected) during this given time period
Alarm Count chart
Distribution and count of LLDP alarm events during the given time period
Info Count chart
Distribution and count of LLDP info events during the given time period
Host Interface Name
Software interface on the host where the session is running
Peer Hostname
User-defined name of the peer device
Peer Interface Name
Software interface on the peer where the session is running
The Configuration File Evolution tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates configuration file information for a single session of a Network Service or Protocol
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Click to open associated device card.
,
Indicates whether the host sees the peer or not; has a peer, no peer
Timestamps
When changes to the configuration file have occurred, the date and time are indicated. Click the time to see the changed file.
Configuration File
When File is selected, the configuration file as it was at the selected time is shown. When Diff is selected, the configuration file at the selected time is shown on the left and the configuration file at the previous timestamp is shown on the right. Differences are highlighted.
Note: If no configuration file changes have been made, the card shows no results.
The full screen LLDP Session card provides tabs for all LLDP sessions and all events.
Item
Description
Title
Network Services | LLDP
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All LLDP Sessions tab
Displays all LLDP sessions on the host device. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Ifname: Name of the host interface where LLDP session is running
LLDPPeer:
Os: Operating system (OS) used by peer device. Values include Cumulus Linux, RedHat, Ubuntu, and CentOS.
Osv: Version of the OS used by peer device. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Bridge: Indicates whether the peer device is a bridge (true) or not (false)
Router: Indicates whether the peer device is a router (true) or not (false)
Station: Indicates whether the peer device is a station (true) or not (false)
Peer:
Hostname: User-defined name for the peer device
Ifname: Name of the peer interface where the session is running
Timestamp: Date and time that the session was started, deleted, updated, or marked dead (device is down)
All Events tab
Displays all events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of an event. Example: LLDP Session with host leaf02 swp6 modified fields leaf06 swp21
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of lldp in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Session Status Summary
A summary of the LLDP session is available from the LLDP Session card workflow, showing the node and its peer and current status.
To view the summary:
Open the full screen LLDP Service card.
Double-click on a session. The full screen card closes automatically.
Locate the medium LLDP Session card.
Optionally, open the small LLDP Session card.
View LLDP Session Neighbor State Changes
You can view the neighbor state for a given LLDP session from the medium and large LLDP Session cards. For a given time period, you can determine the stability of the LLDP session between two devices. If you experienced connectivity issues at a particular time, you can use these cards to help verify the state of the neighbor. If the neighbor was not alive more than it was alive, you can then investigate further into possible causes.
To view the neighbor availability for a given LLDP session on the medium card:
Open the full screen LLDP Service card.
Double-click on a session. The full screen card closes automatically.
Locate the medium LLDP Session card.
In this example, the heat map tells us that this LLDP session has been able to detect a neighbor for the entire time period.
From this card, you can also view the host name and interface name, and the peer name and interface name.
To view the neighbor availability for a given LLDP session on the large LLDP Session card, open that card.
From this card, you can also view the alarm and info event counts, host interface name, peer hostname, and peer interface identifying the session in more detail.
View Changes to the LLDP Service Configuration File
Each time a change is made to the configuration file for the LLDP service, NetQ logs the change and enables you to compare it with the last version. This can be useful when you are troubleshooting potential causes for alarms or sessions losing their connections.
To view the configuration file changes:
Open the large LLDP Session card.
Hover over the card and click to open the LLDP Configuration File Evolution tab.
Select the time of interest on the left; when a change may have impacted the performance. Scroll down if needed.
Choose between the File view and the Diff view (selected option is dark; File by default).
The File view displays the content of the file for you to review.
The Diff view displays the changes between this version (on left) and the most recent version (on right) side by side. The changes are highlighted in red and green. In this example, we don’t have any changes to the file, so the same file is shown on both sides, and thus no highlighted lines.
View All LLDP Session Details
You can view all stored attributes of all of the LLDP sessions associated with the two devices on this card.
To view all session details, open the full screen LLDP Session card, and click the All LLDP Sessions tab.
To return to your workbench, click in the top right of the card.
View All Events
You can view all of the alarm and info events in the network.
To view all events, open the full screen LLDP Session card, and click the All Events tab.
Where to go next depends on what data you see, but a few options include:
Open the All LLDP Sessions tabs to look more closely at the details of the sessions between these two devices.
Sort on other parameters:
by Message to determine the frequency of particular events
by Severity to determine the most critical events
by Time to find events that may have occurred at a particular time to try to correlate them with other system events
Export data to a file by clicking
Return to your workbench by clicking in the top right corner
Monitor the MLAG Service
The Cumulus NetQ UI enables operators to view the health of the MLAG service on a network-wide and a per session basis, giving greater insight into all aspects of the service. This is accomplished through two card workflows, one for the service and one for the session. They are described separately here.
MLAG or CLAG?
The Cumulus Linux implementation of MLAG is referred to by other vendors as MLAG, MC-LAG or VPC. The Cumulus NetQ UI uses the MLAG terminology predominantly.
Monitor the MLAG Service (All Sessions)
With NetQ, you can monitor the number of nodes running the MLAG service, view sessions running, and view alarms triggered by the MLAG service. For an overview and how to configure MLAG in your data center network, refer to Multi-Chassis Link Aggregation - MLAG.
MLAG Service Card Workflow Summary
The small MLAG Service card displays:
Item
Description
Indicates data is for all sessions of a Network Service or Protocol
Title
MLAG: All MLAG Sessions, or the MLAG Service
Total number of switches with the MLAG service enabled during the designated time period
Total number of MLAG-related alarms received during the designated time period
Chart
Distribution of MLAG-related alarms received during the designated time period
The medium MLAG Service card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Network Services | All MLAG Sessions
Total number of switches with the MLAG service enabled during the designated time period
Total number of MLAG-related alarms received during the designated time period
Total number of sessions with an inactive backup IP address during the designated time period
Total number of bonds with only a single connection during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the MLAG service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running MLAG last week or last month might be more or less than the number of nodes running MLAG currently.
Total Open Alarms chart
Distribution of MLAG-related alarms received during the designated time period, and the total number of current MLAG-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Total Sessions chart
Distribution of MLAG sessions running during the designated time period, and the total number of sessions running on the network currently
The large MLAG service card contains two tabs.
The All MLAG Sessions summary tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
All MLAG Sessions Summary
Total number of switches with the MLAG service enabled during the designated time period
Total number of MLAG-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the MLAG service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running MLAG last week or last month might be more or less than the number of nodes running MLAG currently.
Total Sessions chart
Distribution of MLAG sessions running during the designated time period, and the total number of sessions running on the network currently
Total Sessions with Inactive-backup-ip chart
Distribution of sessions without an active backup IP defined during the designated time period, and the total number of these sessions running on the network currently
Table/Filter options
When the Switches with Most Sessions filter is selected, the table displays switches running MLAG sessions in decreasing order of session count-devices with the largest number of sessions are listed first
When the Switches with Most Unestablished Sessions filter is selected, the table displays switches running MLAG sessions in decreasing order of unestablished session count-devices with the largest number of unestablished sessions are listed first
Show All Sessions
Link to view all MLAG sessions in the full screen card
The All MLAG Alarms tab which displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
(in header)
Indicates alarm data for all MLAG sessions
Title
Network Services | All MLAG Alarms (visible when you hover over card)
Total number of switches with the MLAG service enabled during the designated time period
(in summary bar)
Total number of MLAG-related alarms received during the designated time period
Total Alarms chart
Distribution of MLAG-related alarms received during the designated time period, and the total number of current MLAG-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Table/Filter options
When the Events by Most Active Device filter is selected, the table displays switches running MLAG sessions in decreasing order of alarm count-devices with the largest number of sessions are listed first
Show All Sessions
Link to view all MLAG sessions in the full screen card
The full screen MLAG Service card provides tabs for all switches, all
sessions, and all alarms.
Item
Description
Title
Network Services | MLAG
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches tab
Displays all switches and hosts running the MLAG service. By default, the device list is sorted by hostname. This tab provides the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.1.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples values include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
All Sessions tab
Displays all MLAG sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Backup Ip: IP address of the interface to use if the peerlink (or bond) goes down
Backup Ip Active: Indicates whether the backup IP address has been specified and is active (true) or not (false)
Bonds
Conflicted: Identifies the set of interfaces in a bond that do not match on each end of the bond
Single: Identifies a set of interfaces connecting to only one of the two switches
Dual: Identifies a set of interfaces connecting to both switches
Proto Down: Interface on the switch brought down by the clagd service. Value is blank if no interfaces are down due to clagd service.
Clag Sysmac: Unique MAC address for each bond interface pair. Note: Must be a value between 44:38:39:ff:00:00 and 44:38:39:ff:ff:ff.
Peer:
If: Name of the peer interface
Role: Role of the peer device. Values include primary and secondary.
State: Indicates if peer device is up (true) or down (false)
Role: Role of the host device. Values include primary and secondary.
Timestamp: Date and time the MLAG session was started, deleted, updated, or marked dead (device went down)
Vxlan Anycast: Anycast IP address used for VXLAN termination
All Alarms tab
Displays all MLAG events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a MLAG-related event. Example: Clag conflicted bond changed from swp7 swp8 to swp9 swp10
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of clag in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Service Status Summary
A summary of the MLAG service is available from the MLAG Service card workflow, including the number of nodes running the service, the number of MLAG-related alarms, and a distribution of those alarms.
To view the summary, open the small MLAG Service card.
For more detail, select a different size MLAG Service card.
View the Distribution of Sessions and Alarms
It is useful to know the number of network nodes running the MLAG protocol over a period of time, as it gives you insight into the amount of traffic associated with and breadth of use of the protocol. It is also useful to compare the number of nodes running MLAG with the alarms present at the same time to determine if there is any correlation between the issues and the ability to establish a MLAG session.
To view these distributions, open the medium MLAG Service card.
If a visual correlation is apparent, you can dig a little deeper with the large MLAG Service card tabs.
View Devices with the Most CLAG Sessions
You can view the load from MLAG on your switches using the large MLAG Service card. This data enables you to see which switches are handling the most MLAG traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most MLAG sessions:
Open the large MLAG Service card.
Select Switches with Most Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most MLAG sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large MLAG Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the current time. You can now see whether there are significant differences between this time period and the previous time period.
If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running MLAG than previously, looking for changes in the topology, and so forth.
View Devices with the Most Unestablished MLAG Sessions
You can identify switches that are experiencing difficulties establishing MLAG sessions; both currently and in the past.
To view switches with the most unestablished MLAG sessions:
Open the large MLAG Service card.
Select Switches with Most Unestablished Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most unestablished MLAG sessions at the top. Scroll down to view those with the fewest unestablished sessions.
Where to go next depends on what data you see, but a few options include:
Change the time period for the data to compare with a prior time. If the same switches are consistently indicating the most unestablished sessions, you might want to look more carefully at those switches using the Switches card workflow to determine probable causes. Refer to Monitor Switches.
Click Show All Sessions to investigate all MLAG sessions with events in the full screen card.
View Switches with the Most MLAG-related Alarms
Switches experiencing a large number of MLAG alarms may indicate a configuration or performance issue that needs further investigation. You can view the switches sorted by the number of MLAG alarms and then use the Switches card workflow or the Alarms card workflow to gather more information about possible causes for the alarms.
To view switches with most MLAG alarms:
Open the large MLAG Service card.
Hover over the header and click .
Select Events by Most Active Device from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most MLAG alarms at the top. Scroll down to view those with the fewest alarms.
Where to go next depends on what data you see, but a few options include:
Change the time period for the data to compare with a prior time. If the same switches are consistently indicating the most alarms, you might want to look more carefully at those switches using the Switches card workflow.
Click Show All Sessions to investigate all MLAG sessions with alarms in the full screen card.
View All MLAG Events
The MLAG Service card workflow enables you to view all of the MLAG events in the designated time period.
To view all MLAG events:
Open the full screen MLAG Service card.
Click All Alarms tab.
Where to go next depends on what data you see, but a few options include:
Open the All Switches or All Sessions tabs to look more closely at the alarms from the switch or session perspective.
Sort on other parameters:
by Message to determine the frequency of particular events
by Severity to determine the most critical events
by Time to find events that may have occurred at a particular time to try to correlate them with other system events
Export the data to a file by clicking
Return to your workbench by clicking in the top right corner
View Details About All Switches Running MLAG
You can view all stored attributes of all switches running MLAG in your network in the full-screen card.
To view all switch details, open the full screen MLAG Service card, and click the All Switches tab.
To return to your workbench, click in the top right corner.
Use the icons above the table to select/deselect, filter, and export items in the list. Refer to Table Settings for more detail. To return to original display of results, click the associated tab.
Monitor a Single MLAG Session
With NetQ, you can monitor the number of nodes running the MLAG service, view switches with the most peers alive and not alive, and view alarms triggered by the MLAG service. For an overview and how to configure MLAG in your data center network, refer to Multi-Chassis Link Aggregation - MLAG.
To access the single session cards, you must open the full screen MLAG Service, click the All Sessions tab, select the desired session, then click (Open Cards).
Granularity of Data Shown Based on Time Period
On the medium and large single MLAG session cards, the status of the peers is represented in heat maps stacked vertically; one for peers that are reachable (alive), and one for peers that are unreachable (not alive). Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all peers during that time period were alive for the entire time block, then the top block is 100% saturated (white) and the not alive block is zero percent saturated (gray). As peers that are not alive increase in saturation, the peers that are alive block is proportionally reduced in saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
MLAG Session Card Workflow Summary
The small MLAG Session card displays:
Item
Description
Indicates data is for a single session of a Network Service or Protocol
Title
CLAG Session
Device identifiers (hostname, IP address, or MAC address) for host and peer in session.
,
Indication of host role, primary or secondary
The medium MLAG Session card displays:
Item
Description
Time period (in header)
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
Network Services | MLAG Session
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Arrow points from the host to the peer. Click to open associated device card.
,
Indication of host role, primary or secondary
Time period (above chart)
Range of time for data displayed in peer status chart
Peer Status chart
Distribution of peer availability, alive or not alive, during the designated time period. The number of time segments in a time period varies according to the length of the time period.
Role
Role that host device is playing. Values include primary and secondary.
CLAG sysmac
System MAC address of the MLAG session
Peer Role
Role that peer device is playing. Values include primary and secondary.
Peer State
Operational state of the peer, up (true) or down (false)
The large MLAG Session card contains two tabs.
The Session Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
(Network Services | MLAG Session) Session Summary
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Arrow points from the host to the peer. Click to open associated device card.
,
Indication of host role, primary or secondary
Alarm Count Chart
Distribution and count of CLAG alarm events over the given time period
Info Count Chart
Distribution and count of CLAG info events over the given time period
Peer Status chart
Distribution of peer availability, alive or not alive, during the designated time period. The number of time segments in a time period varies according to the length of the time period.
Backup IP
IP address of the interface to use if the peerlink (or bond) goes down
Backup IP Active
Indicates whether the backup IP address is configured
CLAG SysMAC
System MAC address of the MLAG session
Peer State
Operational state of the peer, up (true) or down (false)
Count of Dual Bonds
Number of bonds connecting to both switches
Count of Single Bonds
Number of bonds connecting to only one switch
Count of Protocol Down Bonds
Number of bonds with interfaces that were brought down by the clagd service
Count of Conflicted Bonds
Number of bonds which have a set of interfaces that are not the same on both switches
The Configuration File Evolution tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates configuration file information for a single session of a Network Service or Protocol
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Arrow points from the host to the peer. Click to open associated device card.
,
Indication of host role, primary or secondary
Timestamps
When changes to the configuration file have occurred, the date and time are indicated. Click the time to see the changed file.
Configuration File
When File is selected, the configuration file as it was at the selected time is shown.
When Diff is selected, the configuration file at the selected time is shown on the left and the configuration file at the previous timestamp is shown on the right. Differences are highlighted.
The full screen MLAG Session card provides tabs for all MLAG sessions
and all events.
Item
Description
Title
Network Services | MLAG
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All MLAG Sessions tab
Displays all MLAG sessions for the given session. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Backup Ip: IP address of the interface to use if the peerlink (or bond) goes down
Backup Ip Active: Indicates whether the backup IP address has been specified and is active (true) or not (false)
Bonds
Conflicted: Identifies the set of interfaces in a bond that do not match on each end of the bond
Single: Identifies a set of interfaces connecting to only one of the two switches
Dual: Identifies a set of interfaces connecting to both switches
Proto Down: Interface on the switch brought down by the clagd service. Value is blank if no interfaces are down due to clagd service.
Mlag Sysmac: Unique MAC address for each bond interface pair. Note: Must be a value between 44:38:39:ff:00:00 and 44:38:39:ff:ff:ff.
Peer:
If: Name of the peer interface
Role: Role of the peer device. Values include primary and secondary.
State: Indicates if peer device is up (true) or down (false)
Role: Role of the host device. Values include primary and secondary.
Timestamp: Date and time the MLAG session was started, deleted, updated, or marked dead (device went down)
Vxlan Anycast: Anycast IP address used for VXLAN termination
All Events tab
Displays all events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of an event. Example: Clag conflicted bond changed from swp7 swp8 to swp9 swp10
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of clag in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Session Status Summary
A summary of the MLAG session is available from the MLAG Session card workflow, showing the node and its peer and current status.
To view the summary:
Open the full screen MLAG Service card.
Select a session from the listing to view.
Close the full screen card to view the medium MLAG Session card.
In the left example, we see that the tor1 switch plays the secondary role in this session with the switch at 44:38:39:ff:01:01. In the right example, we see that the leaf03 switch plays the primary role in this session with leaf04.
View MLAG Session Peering State Changes
You can view the peering state for a given MLAG session from the medium and large MLAG Session cards. For a given time period, you can determine the stability of the MLAG session between two devices. If you experienced connectivity issues at a particular time, you can use these cards to help verify the state of the peer. If the peer was not alive more than it was alive, you can then investigate further into possible causes.
To view the state transitions for a given MLAG session:
Open the full screen MLAG Service card.
Select a session from the listing to view.
Close the full screen card to view the medium MLAG Session card.
In this example, the peer switch has been alive for the entire 24-hour period.
From this card, you can also view the node role, peer role and state, and MLAG system MAC address which identify the session in more detail.
To view the peering state transitions for a given MLAG session on the large MLAG Session card, open that card.
From this card, you can also view the alarm and info event counts, node role, peer role, state, and interface, MLAG system MAC address, active backup IP address, single, dual, conflicted, and protocol down bonds, and the VXLAN anycast address identifying the session in more detail.
View Changes to the MLAG Service Configuration File
Each time a change is made to the configuration file for the MLAG service, NetQ logs the change and enables you to compare it with the last version. This can be useful when you are troubleshooting potential causes for alarms or sessions losing their connections.
To view the configuration file changes:
Open the large MLAG Session card.
Hover over the card and click to open the Configuration File Evolution tab.
Select the time of interest on the left; when a change may have impacted the performance. Scroll down if needed.
Choose between the File view and the Diff view (selected option is dark; File by default).
The File view displays the content of the file for you to review.
The Diff view displays the changes between this version (on left) and the most recent version (on right) side by side. The changes are highlighted in red and green. In this example, we don’t have any changes after this first creation, so the same file is shown on both sides and no highlighting is present.
All MLAG Session Details
You can view all stored attributes of all of the MLAG sessions associated with the two devices on this card.
To view all session details, open the full screen MLAG Session card, and click the All MLAG Sessions tab.
Where to go next depends on what data you see, but a few options include:
Open the All Events tabs to look more closely at the alarm and info events fin the network.
Sort on other parameters:
by Single Bonds to determine which interface sets are only connected to one of the switches
by Backup IP and Backup IP Active to determine if the correct backup IP address is specified for the service
Export the data to a file by clicking
Return to your workbench by clicking in the top right corner
View All MLAG Session Events
You can view all of the alarm and info events for the two devices on this card.
To view all events, open the full screen MLAG Session card, and click the All Events tab.
Where to go next depends on what data you see, but a few options include:
Open the All MLAG Sessions tabs to look more closely at the individual sessions.
Sort on other parameters:
by Message to determine the frequency of particular events
by Severity to determine the most critical events
by Time to find events that may have occurred at a particular time to try to correlate them with other system events
Export the data to a file by clicking
Return to your workbench by clicking in the top right corner
Monitor the OSPF Service
The Cumulus NetQ UI enables operators to view the health of the OSPF service on a network-wide and a per session basis, giving greater insight into all aspects of the service. This is accomplished through two card workflows, one for the service and one for the session. They are described separately here.
Monitor the OSPF Service (All Sessions)
With NetQ, you can monitor the number of nodes running the OSPF service, view switches with the most full and unestablished OSPF sessions, and view alarms triggered by the OSPF service. For an overview and how to configure OSPF to run in your data center network, refer to Open Shortest Path First - OSPF or Open Shortest Path First v3 - OSPFv3.
OSPF Service Card Workflow
The small OSPF Service card displays:
Item
Description
Indicates data is for all sessions of a Network Service or Protocol
Title
OSPF: All OSPF Sessions, or the OSPF Service
Total number of switches and hosts with the OSPF service enabled during the designated time period
Total number of OSPF-related alarms received during the designated time period
Chart
Distribution of OSPF-related alarms received during the designated time period
The medium OSPF Service card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Network Services | All OSPF Sessions
Total number of switches and hosts with the OSPF service enabled during the designated time period
Total number of OSPF-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the OSPF service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running OSPF last week or last month might be more or less than the number of nodes running OSPF currently.
Total Sessions Not Established chart
Distribution of unestablished OSPF sessions during the designated time period, and the total number of unestablished sessions in the network currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of unestablished session last week or last month might be more of less than the number of nodes with unestablished sessions currently.
Total Sessions chart
Distribution of OSPF sessions during the designated time period, and the total number of sessions running on the network currently.
The large OSPF service card contains two tabs.
The Sessions Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for all sessions of a Network Service or Protocol
Title
Sessions Summary (visible when you hover over card)
Total number of switches and hosts with the OSPF service enabled during the designated time period
Total number of OSPF-related alarms received during the designated time period
Total Nodes Running chart
Distribution of switches and hosts with the OSPF service enabled during the designated time period, and a total number of nodes running the service currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of nodes running OSPF last week or last month might be more or less than the number of nodes running OSPF currently.
Total Sessions chart
Distribution of OSPF sessions during the designated time period, and the total number of sessions running on the network currently.
Total Sessions Not Established chart
Distribution of unestablished OSPF sessions during the designated time period, and the total number of unestablished sessions in the network currently.
Note: The node count here may be different than the count in the summary bar. For example, the number of unestablished session last week or last month might be more of less than the number of nodes with unestablished sessions currently.
Table/Filter options
When the Switches with Most Sessions filter option is selected, the table displays the switches and hosts running OSPF sessions in decreasing order of session count-devices with the largest number of sessions are listed first
When the Switches with Most Unestablished Sessions filter option is selected, the table switches and hosts running OSPF sessions in decreasing order of unestablished sessions-devices with the largest number of unestablished sessions are listed first
Show All Sessions
Link to view data for all OSPF sessions in the full screen card
The Alarms tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
(in header)
Indicates data is all alarms for all OSPF sessions
Title
Alarms (visible when you hover over card)
Total number of switches and hosts with the OSPF service enabled during the designated time period
(in summary bar)
Total number of OSPF-related alarms received during the designated time period
Total Alarms chart
Distribution of OSPF-related alarms received during the designated time period, and the total number of current OSPF-related alarms in the network.
Note: The alarm count here may be different than the count in the summary bar. For example, the number of new alarms received in this time period does not take into account alarms that have already been received and are still active. You might have no new alarms, but still have a total number of alarms present on the network of 10.
Table/Filter options
When the selected filter option is Switches with Most Alarms, the table displays switches and hosts running OSPF in decreasing order of the count of alarms-devices with the largest number of OSPF alarms are listed first
Show All Sessions
Link to view data for all OSPF sessions in the full screen card
The full screen OSPF Service card provides tabs for all switches, all sessions, and all alarms.
Item
Description
Title
Network Services | OSPF
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All Switches tab
Displays all switches and hosts running the OSPF service. By default, the device list is sorted by hostname. This tab provides the following additional data about each device:
Agent
State: Indicates communication state of the NetQ Agent on a given device. Values include Fresh (heard from recently) and Rotten (not heard from recently).
Version: Software version number of the NetQ Agent on a given device. This should match the version number of the NetQ software loaded on your server or appliance; for example, 2.1.0.
ASIC
Core BW: Maximum sustained/rated bandwidth. Example values include 2.0 T and 720 G.
Model: Chip family. Example values include Tomahawk, Trident, and Spectrum.
Model Id: Identifier of networking ASIC model. Example values include BCM56960 and BCM56854.
Ports: Indicates port configuration of the switch. Example values include 32 x 100G-QSFP28, 48 x 10G-SFP+, and 6 x 40G-QSFP+.
Vendor: Manufacturer of the chip. Example values include Broadcom and Mellanox.
CPU
Arch: Microprocessor architecture type. Values include x86_64 (Intel), ARMv7 (AMD), and PowerPC.
Max Freq: Highest rated frequency for CPU. Example values include 2.40 GHz and 1.74 GHz.
Model: Chip family. Example values include Intel Atom C2538 and Intel Atom C2338.
Nos: Number of cores. Example values include 2, 4, and 8.
Disk Total Size: Total amount of storage space in physical disks (not total available). Example values: 10 GB, 20 GB, 30 GB.
License State: Indicator of validity. Values include ok and bad.
Memory Size: Total amount of local RAM. Example values include 8192 MB and 2048 MB.
OS
Vendor: Operating System manufacturer. Values include Cumulus Networks, RedHat, Ubuntu, and CentOS.
Version: Software version number of the OS. Example values include 3.7.3, 2.5.x, 16.04, 7.1.
Version Id: Identifier of the OS version. For Cumulus, this is the same as the Version (3.7.x).
Platform
Date: Date and time the platform was manufactured. Example values include 7/12/18 and 10/29/2015.
MAC: System MAC address. Example value: 17:01:AB:EE:C3:F5.
Model: Manufacturer's model name. Examples values include AS7712-32X and S4048-ON.
Number: Manufacturer part number. Examples values include FP3ZZ7632014A, 0J09D3.
Revision: Release version of the platform
Series: Manufacturer serial number. Example values include D2060B2F044919GD000060, CN046MRJCES0085E0004.
Vendor: Manufacturer of the platform. Example values include Cumulus Express, Dell, EdgeCore, Lenovo, Mellanox.
Time: Date and time the data was collected from device.
All Sessions tab
Displays all OSPF sessions network-wide. By default, the session list is sorted by hostname. This tab provides the following additional data about each session:
Area: Routing domain for this host device. Example values include 0.0.0.1, 0.0.0.23.
Ifname: Name of the interface on host device where session resides. Example values include swp5, peerlink-1.
Is IPv6: Indicates whether the address of the host device is IPv6 (true) or IPv4 (false)
Peer
Address: IPv4 or IPv6 address of the peer device
Hostname: User-defined name for peer device
ID: Network subnet address of router with access to the peer device
State: Current state of OSPF. Values include Full, 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Timestamp: Date and time session was started, deleted, updated or marked dead (device is down)
All Alarms tab
Displays all OSPF events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a OSPF-related event. Example: swp4 area ID mismatch with peer leaf02
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of OSPF in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Service Status Summary
A summary of the OSPF service is available from the Network Services card workflow, including the number of nodes running the service, the number of OSPF-related alarms, and a distribution of those alarms.
To view the summary, open the small OSPF Service card.
For more detail, select a different size OSPF Service card.
View the Distribution of Sessions
It is useful to know the number of network nodes running the OSPF protocol over a period of time, as it gives you insight into the amount of traffic associated with and breadth of use of the protocol. It is also useful to view the health of the sessions.
To view these distributions, open the medium OSPF Service card.
You can dig a little deeper with the large OSPF Service card tabs.
View Devices with the Most OSPF Sessions
You can view the load from OSPF on your switches and hosts using the large Network Services card. This data enables you to see which switches are handling the most OSPF traffic currently, validate that is what is expected based on your network design, and compare that with data from an earlier time to look for any differences.
To view switches and hosts with the most OSPF sessions:
Open the large OSPF Service card.
Select Switches with Most Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes running the most OSPF sessions at the top. Scroll down to view those with the fewest sessions.
To compare this data with the same data at a previous time:
Open another large OSPF Service card.
Move the new card next to the original card if needed.
Change the time period for the data on the new card by hovering over the card and clicking .
Select the time period that you want to compare with the original time. We chose Past Week for this example.
You can now see whether there are significant differences between this time and the original time. If the changes are unexpected, you can investigate further by looking at another timeframe, determining if more nodes are now running OSPF than previously, looking for changes in the topology, and so forth.
View Devices with the Most Unestablished OSPF Sessions
You can identify switches and hosts that are experiencing difficulties establishing OSPF sessions; both currently and in the past.
To view switches with the most unestablished OSPF sessions:
Open the large OSPF Service card.
Select Switches with Most Unestablished Sessions from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most unestablished OSPF sessions at the top. Scroll down to view those with the fewest unestablished sessions.
Where to go next depends on what data you see, but a couple of options include:
Change the time period for the data to compare with a prior time.
If the same switches are consistently indicating the most unestablished sessions, you might want to look more carefully at those switches using the Switches card workflow to determine probable causes. Refer to Monitor Switches.
Click Show All Sessions to investigate all OSPF sessions with events in the full screen card.
View Devices with the Most OSPF-related Alarms
Switches or hosts experiencing a large number of OSPF alarms may indicate a configuration or performance issue that needs further investigation. You can view the devices sorted by the number of OSPF alarms and then use the Switches card workflow or the Alarms card workflow to gather more information about possible causes for the alarms. compare the number of nodes running OSPF with unestablished sessions with the alarms present at the same time to determine if there is any correlation between the issues and the ability to establish an OSPF session.
To view switches with the most OSPF alarms:
Open the large OSPF Service card.
Hover over the header and click .
Select Switches with Most Alarms from the filter above the table.
The table content is sorted by this characteristic, listing nodes with the most OSPF alarms at the top. Scroll down to view those with the fewest alarms.
Where to go next depends on what data you see, but a few options include:
Change the time period for the data to compare with a prior time. If the same switches are consistently indicating the most alarms, you might want to look more carefully at those switches using the Switches card workflow.
Click Show All Sessions to investigate all OSPF sessions with events in the full screen card.
View All OSPF Events
The OSPF Network Services card workflow enables you to view all of the OSPF events in the designated time period.
To view all OSPF events:
Open the full screen OSPF Service card.
Click All Alarms tab in the navigation panel. By default, events are listed in most recent to least recent order.
Where to go next depends on what data you see, but a couple of options include:
Open one of the other full screen tabs in this flow to focus on devices or sessions
Export the data for use in another analytics tool, by clicking and providing a name for the data file
View Details for All Devices Running OSPF
You can view all stored attributes of all switches and hosts running OSPF in your network in the full screen card.
To view all device details, open the full screen OSPF Service card and click the All Switches tab.
To return to your workbench, click in the top right corner.
View Details for All OSPF Sessions
You can view all stored attributes of all OSPF sessions in your network in the full-screen card.
To view all session details, open the full screen OSPF Service card and click the All Sessions tab.
To return to your workbench, click in the top right corner.
Use the icons above the table to select/deselect, filter, and export items in the list. Refer to Table Settings for more detail. To return to original display of results, click the associated tab.
Monitor a Single OSPF Session
With NetQ, you can monitor a single session of the OSPF service, view session state changes, and compare with alarms occurring at the same time, as well as monitor the running OSPF configuration and changes to the configuration file. For an overview and how to configure OSPF to run in your data center network, refer to Open Shortest Path First - OSPF or Open Shortest Path First v3 - OSPFv3.
To access the single session cards, you must open the full screen OSPF Service, click the All Sessions tab, select the desired session, then click (Open Cards).
Granularity of Data Shown Based on Time Period
On the medium and large single OSPF session cards, the status of the sessions is represented in heat maps stacked vertically; one for established sessions, and one for unestablished sessions. Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all sessions during that time period were established for the entire time block, then the top block is 100% saturated (white) and the not established block is zero percent saturated (gray). As sessions that are not established increase in saturation, the sessions that are established block is proportionally reduced in saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
OSPF Session Card Workflow Summary
The small OSPF Session card displays:
Item
Description
Indicates data is for a single session of a Network Service or Protocol
Title
OSPF Session
Hostnames of the two devices in a session. Host appears on top with peer below.
,
Current state of OSPF. Full or 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
The medium OSPF Session card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
Network Services | OSPF Session
Hostnames of the two devices in a session. Host appears on top with peer below.
,
Current state of OSPF. Full or 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Time period for chart
Time period for the chart data
Session State Changes Chart
Heat map of the state of the given session over the given time period. The status is sampled at a rate consistent with the time period. For example, for a 24 hour period, a status is collected every hour. Refer to Granularity of Data Shown Based on Time Period.
Ifname
Interface name on or hostname for host device where session resides
Peer Address
IP address of the peer device
Peer ID
IP address of router with access to the peer device
The large OSPF Session card contains two tabs.
The Session Summary tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates data is for a single session of a Network Service or Protocol
Title
Session Summary (Network Services | OSPF Session)
Summary bar
Hostnames of the two devices in a session. Arrow points in the direction of the session.
Current state of OSPF. Full or 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Session State Changes Chart
Heat map of the state of the given session over the given time period. The status is sampled at a rate consistent with the time period. For example, for a 24 hour period, a status is collected every hour. Refer to Granularity of Data Shown Based on Time Period.
Alarm Count Chart
Distribution and count of OSPF alarm events over the given time period
Info Count Chart
Distribution and count of OSPF info events over the given time period
Ifname
Name of the interface on the host device where the session resides
State
Current state of OSPF. Full or 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Is Unnumbered
Indicates if the session is part of an unnumbered OSPF configuration (true) or part of a numbered OSPF configuration (false)
Nbr Count
Number of routers in the OSPF configuration
Is Passive
Indicates if the host is in a passive state (true) or active state (false).
Peer ID
IP address of router with access to the peer device
Is IPv6
Indicates if the IP address of the host device is IPv6 (true) or IPv4 (false)
If Up
Indicates if the interface on the host is up (true) or down (false)
Nbr Adj Count
Number of adjacent routers for this host
MTU
Maximum transmission unit (MTU) on shortest path between the host and peer
Peer Address
IP address of the peer device
Area
Routing domain of the host device
Network Type
Architectural design of the network. Values include Point-to-Point and Broadcast.
Cost
Shortest path through the network between the host and peer devices
Dead Time
Countdown timer, starting at 40 seconds, that is constantly reset as messages are heard from the neighbor. If the dead time gets to zero, the neighbor is presumed dead, the adjacency is torn down, and the link removed from SPF calculations in the OSPF database.
The Configuration File Evolution tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates configuration file information for a single session of a Network Service or Protocol
Device identifiers (hostname, IP address, or MAC address) for host and peer in session. Arrow points from the host to the peer. Click to open associated device card.
,
Current state of OSPF. Full or 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Timestamps
When changes to the configuration file have occurred, the date and time are indicated. Click the time to see the changed file.
Configuration File
When File is selected, the configuration file as it was at the selected time is shown.
When Diff is selected, the configuration file at the selected time is shown on the left and the configuration file at the previous timestamp is shown on the right. Differences are highlighted.
The full screen OSPF Session card provides tabs for all OSPF sessions
and all events.
Item
Description
Title
Network Services | OSPF
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
All OSPF Sessions tab
Displays all OSPF sessions running on the host device. The session list is sorted by hostname by default. This tab provides the following additional data about each session:
Area: Routing domain for this host device. Example values include 0.0.0.1, 0.0.0.23.
Ifname: Name of the interface on host device where session resides. Example values include swp5, peerlink-1.
Is IPv6: Indicates whether the address of the host device is IPv6 (true) or IPv4 (false)
Peer
Address: IPv4 or IPv6 address of the peer device
Hostname: User-defined name for peer device
ID: Network subnet address of router with access to the peer device
State: Current state of OSPF. Values include Full, 2-way, Attempt, Down, Exchange, Exstart, Init, and Loading.
Timestamp: Date and time session was started, deleted, updated or marked dead (device is down)
All Events tab
Displays all events network-wide. By default, the event list is sorted by time, with the most recent events listed first. The tab provides the following additional data about each event:
Message: Text description of a OSPF-related event. Example: OSPF session with peer tor-1 swp7 vrf default state changed from failed to Established
Source: Hostname of network device that generated the event
Severity: Importance of the event. Values include critical, warning, info, and debug.
Type: Network protocol or service generating the event. This always has a value of OSPF in this card workflow.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Session Status Summary
A summary of the OSPF session is available from the OSPF Session card workflow, showing the node and its peer and current status.
To view the summary:
Add the Network Services | All OSPF Sessions card.
Switch to the full screen card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
Optionally, switch to the small OSPF Session card.
View OSPF Session State Changes
You can view the state of a given OSPF session from the medium and large OSPF Session Network Service cards. For a given time period, you can determine the stability of the OSPF session between two devices. If you experienced connectivity issues at a particular time, you can use these cards to help verify the state of the session. If it was not established more than it was established, you can then investigate further into possible causes.
To view the state transitions for a given OSPF session, on the medium OSPF Session card:
Add the Network Services | All OSPF Sessions card.
Switch to the full screen card.
Open the large OSPF Service card.
Click the All Sessions tab.
Double-click the session of interest. The full screen card closes automatically.
The heat map indicates the status of the session over the designated time period. In this example, the session has been established for the entire time period.
From this card, you can also view the interface name, peer address, and peer id identifying the session in more detail.
To view the state transitions for a given OSPF session on the large OSPF Session card, follow the same steps to open the medium OSPF Session card and then switch to the large card.
From this card, you can view the alarm and info event counts, interface name, peer address and peer id, state, and several other parameters identifying the session in more detail.
View Changes to the OSPF Service Configuration File
Each time a change is made to the configuration file for the OSPF service, NetQ logs the change and enables you to compare it with the last version. This can be useful when you are troubleshooting potential causes for alarms or sessions losing their connections.
To view the configuration file changes:
Open the large OSPF Session card.
Hover over the card and click to open the Configuration File Evolution tab.
Select the time of interest on the left; when a change may have impacted the performance. Scroll down if needed.
Choose between the File view and the Diff view (selected option is dark; File by default).
The File view displays the content of the file for you to review.
The Diff view displays the changes between this version (on left) and the most recent version (on right) side by side. The changes are highlighted in red and green. In this example, we don’t have a change to highlight, so it shows the same file on both sides.
View All OSPF Session Details
You can view all stored attributes of all of the OSPF sessions associated with the two devices on this card.
To view all session details, open the full screen OSPF Session card, and click the All OSPF Sessions tab.
To return to your workbench, click in the top right corner.
View All Events
You can view all of the alarm and info events for the two devices on this card.
To view all events, open the full screen OSPF Session card, and click the All Events tab.
To return to your workbench, click in the top right corner.
Monitor Network Connectivity
It is helpful to verify that communications are freely flowing between the various devices in your network. You can verify the connectivity between two devices in both an adhoc fashion and by defining connectivity checks to occur on a scheduled basis. There are three card workflows which enable you to view connectivity, the Trace Request, On-demand Trace Results, and Scheduled Trace Results.
Create a Trace Request
Two types of connectivity checks can be run-an immediate (on-demand) trace and a scheduled trace. The Trace Request card workflow is used to configure and run both of these trace types.
Trace Request Card Workflow Summary
The small Trace Request card displays:
Item
Description
Indicates a trace request
Select Trace list
Select a scheduled trace request from the list
Go
Click to start the trace now
The medium Trace Request card displays:
Item
Description
Indicates a trace request
Title
New Trace Request
New Trace Request
Create a new layer 3 trace request. Use the large Trace Request card to create a new layer 2 or 3 request.
Source
(Required) Hostname or IP address of device where to begin the trace
Destination
(Required) IP address of device where to end the trace
Run Now
Start the trace now
The large Trace Request card displays:
Item
Description
Indicates a trace request
Title
New Trace Request
Trace selection
Leave New Trace Request selected to create a new request, or choose a scheduled request from the list.
Source
(Required) Hostname or IP address of device where to begin the trace.
Destination
(Required) Ending point for the trace. For layer 2 traces, value must be a MAC address. For layer 3 traces, value must be an IP address.
VRF
Optional for layer 3 traces. Virtual Route Forwarding interface to be used as part of the trace path.
VLAN ID
Required for layer 2 traces. Virtual LAN to be used as part of the trace path.
Schedule
Sets the frequency with which to run a new trace (Run every) and when to start the trace for the first time (Starting).
Run Now
Start the trace now
Update
Update is available when a scheduled trace request is selected from the dropdown list and you make a change to its configuration. Clicking Update saves the changes to the existing scheduled trace.
Save As New
Save As New is available in two instances:
When you enter a source, destination, and schedule for a new trace. Clicking Save As New in this instance saves the new scheduled trace.
When changes are made to a selected scheduled trace request. Clicking Save As New in this instance saves the modified scheduled trace without changing the original trace on which it was based.
The full screen Trace Request card displays:
Item
Description
Title
Trace Request
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Results
Number of results found for the selected tab
Schedule Preview tab
Displays all scheduled trace requests for the given user. By default, the listing is sorted by Start Time, with the most recently started traces listed at the top. The tab provides the following additional data about each event:
Action: Indicates latest action taken on the trace job. Values include Add, Deleted, Update.
Frequency: How often the trace is scheduled to run
Active: Indicates if trace is actively running (true), or stopped from running (false)
ID: Internal system identifier for the trace job
Trace Name: User-defined name for a trace
Trace Params: Indicates source and destination, optional VLAN or VRF specified, and whether to alert on failure
Table Actions
Select, export, or filter the list. Refer to Table Settings.
Create a Layer 3 On-demand Trace Request
It is helpful to verify the connectivity between two devices when you suspect an issue is preventing proper communication between them. It you cannot find a path through a layer 3 path, you might also try checking connectivity through a layer 2 path.
To create a layer 3 trace request:
Open the medium Trace Request card.
In the Source field, enter the hostname or IP address of the device where you want to start the trace.
In the Destination field, enter the IP address of the device where you want to end the trace.
In this example, we are starting our trace at server02 and ending it at 10.1.3.103.
If you mistype an address, you must double-click it, or backspace over the error, and retype the address. You cannot select the address by dragging over it as this action attempts to move the card to another location.
Click Run Now. A corresponding Trace Results card is opened on your workbench. Refer to View Layer 3 Trace Results for details.
Create a Layer 3 Trace Through a Given VRF
If you want to guide a trace through a particular VRF interface, you can do so using the large New Trace Request card.
To create the trace request:
Open the large Trace Request card.
In the Source field, enter the hostname or IP address of the device where you want to start the trace.
In the Destination field, enter the IP address of the device where you want to end the trace.
In the VRF field, enter the identifier for the VRF interface you want to use.
In this example, we are starting our trace at leaf01 and ending it at 10.1.3.103 using VRF vrf1.
Click Run Now. A corresponding Trace Results card is opened on your workbench. Refer to View Layer 3 Trace Results for details.
Create a Layer 2 Trace
It is helpful to verify the connectivity between two devices when you suspect an issue is preventing proper communication between them. It you cannot find a path through a layer 2 path, you might also try checking connectivity through a layer 3 path.
To create a layer 2 trace request:
Open the large Trace Request card.
In the Source field, enter the hostname or IP address of the device where you want to start the trace.
In the Destination field, enter the MAC address for where you want to end the trace.
In the VLAN ID field, enter the identifier for the VLAN you want to use.
In this example, we are starting our trace at leaf01 and ending it at 00:03:00:33:33:01 using VLAN 13.
Click Run Now. A corresponding Trace Results card is opened on your workbench. Refer to View Layer 2 Trace Results for details.
Create a Trace to Run on a Regular Basis (Scheduled Trace)
There may be paths through your network that you consider critical to your everyday or particularly important operations. In that case, it might be useful to create one or more traces to periodically confirm that at least one path is available between the relevant two devices. Scheduling a trace request can be performed from the large Trace Request card.
To schedule a trace:
Open the large Trace Request card.
In the Source field, enter the hostname or IP address of the device where you want to start the trace.
In the Destination field, enter the MAC address (layer 2) or IP address (layer 3) of the device where you want to end the trace.
Optionally, enter a VLAN ID (layer 2) or VRF interface (layer 3).
Select a timeframe under Schedule to specify how often you want to run the trace.
Accept the default starting time, or click in the Starting field to specify the day you want the trace to run for the first time.
Click Next.
Click the time you want the trace to run for the first time.
Click OK.
Verify your entries are correct, then click Save As New.
Provide a name for the trace. Note: This name must be unique for a given user.
Click Save. You can now run this trace on demand by selecting it from the dropdown list, or wait for it to run on its defined schedule.
Run a Scheduled Trace on Demand
You may find that, although you have a schedule for a particular trace, you want to have visibility into the connectivity data now. You can run a scheduled trace on demand from the small, medium and large Trace Request cards.
To run a scheduled trace now:
Open the small or medium or large Trace Request card.
Select the scheduled trace from the Select Trace or New Trace Request list. Note: In the medium and large cards, the trace details are filled in on selection of the scheduled trace.
Click Go or Run Now. A corresponding Trace Results card is opened on your workbench.
View On-demand Trace Results
Once you have started an on-demand trace, the results are displayed in the medium Trace Results card by default. You may view the results in more or less detail by switching to the large or small Trace Results card, respectively.
On-demand Trace Results Card Workflow Summary
The small On-demand Trace Results card
displays:
Item
Description
Indicates an on-demand trace result
Source and destination of the trace, identified by their address or hostname. Source is listed on top with arrow pointing to destination.
,
Indicates success or failure of the trace request. A successful result implies all paths were successful without any warnings or failures. A failure result implies there was at least one path with warnings or errors.
The medium On-demand Trace Results card displays:
Item
Description
Indicates an on-demand trace result
Title
On-demand Trace Result
Source and destination of the trace, identified by their address or hostname. Source is listed on top with arrow pointing to destination.
,
Indicates success or failure of the trace request. A successful result implies all paths were successful without any warnings or failures. A failure result implies there was at least one path with warnings or errors.
Total Paths Found
Number of paths found between the two devices
MTU Overall
Average size of the maximum transmission unit for all paths
Minimum Hops
Smallest number of hops along a path between the devices
Maximum Hops
Largest number of hops along a path between the devices
The large On-demand Trace Results card contains two tabs.
The On-demand Trace Result tab displays:
Item
Description
Indicates an on-demand trace result
Title
On-demand Trace Result
,
Indicates success or failure of the trace request. A successful result implies all paths were successful without any warnings or failures. A failure result implies there was at least one path with warnings or errors.
Source and destination of the trace, identified by their address or hostname. Source is listed on top with arrow pointing to destination.
Distribution by Hops chart
Displays the distributions of various hop counts for the available paths
Distribution by MTU chart
Displays the distribution of MTUs used on the interfaces used in the available paths
Table
Provides detailed path information, sorted by the route identifier, including:
Route ID: Identifier of each path
MTU: Average speed of the interfaces used
Hops: Number of hops to get from the source to the destination device
Warnings: Number of warnings encountered during the trace on a given path
Errors: Number of errors encountered during the trace on a given path
Total Paths Found
Number of paths found between the two devices
MTU Overall
Average size of the maximum transmission unit for all paths
Minimum Hops
Smallest number of hops along a path between the devices
The On-demand Trace Settings tab displays:
Item
Description
Indicates an on-demand trace setting
Title
On-demand Trace Settings
Source
Starting point for the trace
Destination
Ending point for the trace
Schedule
Does not apply to on-demand traces
VRF
Associated virtual route forwarding interface, when used with layer 3 traces
VLAN
Associated virtual local area network, when used with layer 2 traces
Job ID
Identifier of the job; used internally
Re-run Trace
Clicking this button runs the trace again
The full screen On-demand Trace Results card displays:
Item
Description
Title
On-demand Trace Results
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Results
Number of results found for the selected tab
Trace Results tab
Provides detailed path information, sorted by the Resolution Time (date and time results completed), including:
SCR.IP: Source IP address
DST.IP: Destination IP address
Max Hop Count: Largest number of hops along a path between the devices
Min Hop Count: Smallest number of hops along a path between the devices
Total Paths: Number of paths found between the two devices
PMTU: Average size of the maximum transmission unit for all interfaces along the paths
Errors: Message provided for analysis when a trace fails
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View Layer 2 Trace Results
When you start the trace, the corresponding results card is opened on your workbench. While it is working on the trace, a notice is shown on the card indicating it is running.
Once the job is completed, the results are displayed.
In this example, we see that the trace was successful. Four paths were found between the devices, each with four hops and with an overall MTU of 1500. If there was a difference between the minimum and maximum number of hops or other failures, viewing the results on the large card would provide additional information.
In our example, we can verify that every path option had four hops since the distribution chart only shows one hop count and the table indicates each path had a value of four hops. Similarly, you can view the MTU data. If there had been any warnings, the count would have been visible in the table.
View Layer 3 Trace Results
When you start the trace, the corresponding results card is opened on your workbench. While it is working on the trace, a notice is shown on the card indicating it is running.
Once results are obtained, it displays them. Using our example from earlier, the following results are shown:
In this example, we see that the trace was successful. Six paths were found between the devices, each with five hops and with an overall MTU of 1500. If there was a difference between the minimum and maximum number of hops or other failures, viewing the results on the large card would provide additional information.
In our example, we can verify that every path option had five hops since the distribution chart only shows one hop count and the table indicates each path had a value of five hops. Similarly, you can view the MTU data. If there had been any warnings, the count would have been visible in the table.
View Detailed On-demand Trace Results
After the trace request has completed, the results are available in the corresponding medium Trace Results card.
To view the more detail:
Open the full-screen Trace Results card for the trace of interest.
Double-click on the trace of interest to open the detail view.
The tabular view enables you to walk through the trace path, host by host, viewing the interfaces, ports, tunnels, VLANs, and so forth used to traverse the network from the source to the destination.
If the trace was run on a Mellanox switch and drops were detected by the What Just Happened feature, they are identified above the path. Click the down arrow to view the list of drops and their details. Click the up arrow to close the list.
View Scheduled Trace Results
You can view the results of scheduled traces at any time. Results are displayed on the Scheduled Trace Results cards.
Scheduled Trace Results Card Workflow Summary
The small Scheduled Trace Results card displays:
Item
Description
Indicates a scheduled trace result
Source and destination of the trace, identified by their address or hostname. Source is listed on left with arrow pointing to destination.
Results
Summary of trace results: a successful result implies all paths were successful without any warnings or failures; a failure result implies there was at least one path with warnings or errors.
Number of trace runs completed in the designated time period
Number of runs with warnings
Number of runs with errors
The medium Scheduled Trace Results card displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates a scheduled trace result
Title
Scheduled Trace Result
Summary
Name of scheduled validation and summary of trace results: a successful result implies all paths were successful without any warnings or failures; a failure result implies there was at least one path with warnings or errors.
Number of trace runs completed in the designated time period
Number of runs with warnings
Number of runs with errors
Charts
Heat map: A time segmented view of the results. For each time segment, the color represents the percentage of warning and failed results. Refer to Granularity of Data Shown Based on Time Period for details on how to interpret the results.
Unique Bad Nodes: Distribution of unique nodes that generated the indicated warnings and/or failures
The large Scheduled Trace Results card contains two tabs:
The Results tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Indicates a scheduled trace result
Title
Scheduled Trace Result
Summary
Name of scheduled validation and summary of trace results: a successful result implies all paths were successful without any warnings or failures; a failure result implies there was at least one path with warnings or errors.
Number of trace runs completed in the designated time period
Number of runs with warnings
Number of runs with errors
Charts
Heat map: A time segmented view of the results. For each time segment, the color represents the percentage of warning and failed results. Refer to Granularity of Data Shown Based on Time Period for details on how to interpret the results.
Small charts: Display counts for each item during the same time period, for the purpose of correlating with the warnings and errors shown in the heat map.
Table/Filter options
When the Failures filter option is selected, the table displays the failure messages received for each run.
When the Paths filter option is selected, the table displays all of the paths tried during each run.
When the Warning filter option is selected, the table displays the warning messages received for each run.
The Configuration tab displays:
Item
Description
Time period
Range of time in which the displayed data was collected; applies to all card sizes
Address or hostname of the device where the trace was started
Destination
Address of the device where the trace was stopped
Schedule
The frequency and starting date and time to run the trace
VRF
Virtual Route Forwarding interface, when defined
VLAN
Virtual LAN identifier, when defined
Name
User-defined name of the scheduled trace
Run Now
Start the trace now
Edit
Modify the trace. Opens Trace Request card with this information pre-populated.
The full screen Scheduled Trace Results card displays:
Item
Description
Title
Scheduled Trace Results
Closes full screen card and returns to workbench
Time period
Range of time in which the displayed data was collected; applies to all card sizes; select an alternate time period by clicking
Results
Number of results found for the selected tab
Scheduled Trace Results tab
Displays the basic information about the trace, including:
Resolution Time: Time that trace was run
SRC.IP: IP address of the source device
DST.IP: Address of the destination device
Max Hop Count: Maximum number of hops across all paths between the devices
Min Hop Count: Minimum number of hops across all paths between the devices
Total Paths: Number of available paths found between the devices
PMTU: Average of the maximum transmission units for all paths
Errors: Message provided for analysis if trace fails
Click on a result to open a detailed view of the results.
Table Actions
Select, export, or filter the list. Refer to Table Settings.
Granularity of Data Shown Based on Time Period
On the medium and large Trace Result cards, the status of the runs is represented in heat maps stacked vertically; one for runs with warnings and one for runs with failures. Depending on the time period of data on the card, the number of smaller time blocks used to indicate the status varies. A vertical stack of time blocks, one from each map, includes the results from all checks during that time. The results are shown by how saturated the color is for each block. If all traces run during that time period pass, then both blocks are 100% gray. If there are only failures, the associated lower blocks are 100% saturated white and the warning blocks are 100% saturated gray. As warnings and failures increase, the blocks increase their white saturation. As warnings or failures decrease, the blocks increase their gray saturation. An example heat map for a time period of 24 hours is shown here with the most common time periods in the table showing the resulting time blocks.
Time Period
Number of Runs
Number Time Blocks
Amount of Time in Each Block
6 hours
18
6
1 hour
12 hours
36
12
1 hour
24 hours
72
24
1 hour
1 week
504
7
1 day
1 month
2,086
30
1 day
1 quarter
7,000
13
1 week
View Detailed Scheduled Trace Results
Once a scheduled trace request has completed, the results are available in the corresponding Trace Result card.
To view the results:
Open the full screen Trace Request card to view all scheduled traces that have been run.
Select the scheduled trace you want to view results for by clicking in the first column of the result and clicking the check box.
On the Edit Menu that appears at the bottom of the window, click (Open Cards). This opens the medium Scheduled Trace Results card(s) for the selected items.
Note the distribution of results. Are there many failures? Are they concentrated together in time? Has the trace begun passing again?
Hover over the heat maps to view the status numbers and what percentage of the total results that represents for a given region.
Switch to the large Scheduled Trace Result card.
If there are a large number of warnings or failures, view the associated messages by selecting Failures or Warning in the filter above the table. This might help narrow the failures down to a particular device or small set of devices that you can investigate further.
Look for a consistent number of paths, MTU, hops in the small charts under the heat map. Changes over time here might correlate with the messages and give you a clue to any specific issues. Note if the number of bad nodes changes over time. Devices that become unreachable are often the cause of trace failures.
View the available paths for each run, by selecting Paths in the filter above the table.
You can view the configuration of the request that produced the results shown on this card workflow, by hovering over the card and clicking . If you want to change the configuration, click Edit to open the large Trace Request card, pre-populated with the current configuration. Follow the instructions in Create a Scheduled Trace Request to make your changes in the same way you created a new scheduled trace.
To view a summary of all scheduled trace results, switch to the full screen card.
Look for changes and patterns in the results for additional clues to isolate root causes of trace failures. Select and view related traces using the Edit menu.
View the details of any specific trace result by clicking on the trace. A new window opens similar to the following:
Scroll to the right to view the information for a given hop. Scroll down to view additional paths. This display shows each of the hosts and detailed steps the trace takes to validate a given path between two devices. Using Path 1 as an example, each path can be interpreted as follows:
Hop 1 is from the source device, server02 in this case.
It exits this device at switch port bond0 with an MTU of 9000 and over the default VRF to get to leaf02.
The trace goes in to swp2 with an MTU of 9216 over the vrf1 interface.
It exits leaf02 through switch port 52 and so on.
Export this data by clicking Export or click to return to the results list to view another trace in detail.
Monitor Devices
The core capabilities of Cumulus NetQ enable you to monitor your network by viewing performance and configuration data about your individual network devices and the entire fabric network-wide. The topics contained in this section describe monitoring tasks that apply to particular device types. For network-wide monitoring refer to Monitor Network Performance.
Monitor Switches
With the NetQ UI, you can monitor individual switches separately from the network. You are able to view the status of services they are running, health of its various components, and connectivity performance. Being able to monitor switch component inventory aids in upgrade, compliance, and other planning tasks. Viewing individual switch health helps isolate performance issues.
Viewing detail about a particular switch is essential when troubleshooting performance issues. With NetQ you can view the overall performance and drill down to view attributes of the switch, interface performance and the events associated with a switch. This is accomplished through the Switches card.
Switch Card Workflow Summary
The small Switch card displays:
Item
Description
Indicates data is for a single switch
title
Hostname of switch
Chart
Distribution of switch alarms during the designated time period
Trend
Trend of alarm count, represented by an arrow:
Pointing upward and green: alarm count is higher than the last two time periods, an increasing trend
Pointing downward and bright pink: alarm count is lower than the last two time periods, a decreasing trend
No arrow: alarm count is unchanged over the last two time periods, trend is steady
Count
Current count of alarms on the switch
Rating
Overall performance of the switch. Determined by the count of alarms relative to the average count of alarms during the designated time period:
Low: Count of alarms is below the average count; a nominal count
Med: Count of alarms is in range of the average count; some room for improvement
High: Count of alarms is above the average count; user intervention recommended
The medium Switch card displays:
Item
Description
Indicates data is for a single switch
title
Hostname of switch
Alarms
When selected, displays distribution and count of alarms by alarm category, generated by this switch during the designated time period
Charts
When selected, displays distribution of alarms by alarm category, during the designated time period
The large Switch card contains three tabs:
The Attributes tab displays:
Item
Description
Indicates data is for a single switch
title
<Hostname> | Attributes
Hostname
User-defined name for this switch
Management IP
IPv4 or IPv6 address used for management of this switch
Management MAC
MAC address used for management of this switch
Agent State
Operational state of the NetQ Agent on this switch; Fresh or Rotten
Platform Vendor
Manufacturer of this switch box. Cumulus Networks is identified as the vendor for a switch in the Cumulus in the Cloud (CITC) environment, as seen here.
Platform Model
Manufacturer model of this switch. VX is identified as the model for a switch in CITC environment, as seen here.
ASIC Vendor
Manufacturer of the ASIC installed on the motherboard
ASIC Model
Manufacturer model of the ASIC installed on the motherboard
OS
Operating system running on the switch. CL indicates a Cumulus Linux license.
OS Version
Version of the OS running on the switch
NetQ Agent Version
Version of the NetQ Agent running on the switch
License State
Indicates whether the license is valid (ok) or invalid/missing (bad)
Total Interfaces
Total number of interfaces on this switch, and the number of those that are up and down.
The Utilization tab displays:
Item
Description
Indicates utilization data is for a single switch
Title
<Hostname> | Utilization
Performance
Displays distribution of CPU and memory usage during the designated time period
Disk Utilization
Displays distribution of disk usage during the designated time period
The Interfaces tab displays:
Item
Description
Indicates interface statistics for a single switch
Title
<Hostname> | Interface Stats
Interface List
List of interfaces present during the designated time period
Interface Filter
Sorts interface list by Name, Rx Util (receive utilization), or Tx Util (transmit utilization)
Interfaces Count
Number of interfaces present during the designated time period
Interface Statistics
Distribution and current value of various transmit and receive statistics associated with a selected interface:
Broadcast: Number of broadcast packets
Bytes: Number of bytes per second
Drop: Number of dropped packets
Errs: Number of errors
Frame: Number of frames received
Multicast: Number of multicast packets
Packets: Number of packets per second
Utilization: Bandwidth utilization as a percentage of total available bandwidth
The full screen Switch card provides multiple tabs.
Item
Description
Title
<hostname>
Closes full screen card and returns to workbench
Default Time
Displayed data is current as of this moment
Displays data refresh status. Click to pause data refresh. Click to resume data refresh. Current refresh rate is visible by hovering over icon.
Results
Number of results found for the selected tab
Alarms
Displays all known critical alarms for the switch. This tab provides the following additional data about each address:
Hostname: User-defined name of the switch
Message: Description of alarm
Message Type: Indicates the protocol or service which generated the alarm
Severity: Indicates the level of importance of the event; it is always critical for NetQ alarms
Time: Date and time the data was collected
All Interfaces
Displays all known interfaces on the switch. This tab provides the following additional data about each interface:
Details: Information about the interface, such as MTU, table number, members, protocols running, VLANs
Hostname: Hostname of the given event
IfName: Name of the interface
Last Changed: Data and time that the interface was last enabled, updated, deleted, or changed state to down
OpId: Process identifier; for internal use only
State: Indicates if the interface is up or down
Time: Date and time the data was collected
Type: Kind of interface; for example, VRF, switch port, loopback, ethernet
VRF: Name of the associated virtual route forwarding (VRF) interface if deployed
MAC Addresses
Displays all known MAC addresses for the switch. This tab provides the following additional data about each MAC address:
Egress Port: Importance of the event-critical, warning, info, or debug
Hostname: User-defined name of the switch
Last Changed: Data and time that the address was last updated or deleted
MAC Address: MAC address of switch
Origin: Indicates whether this switch owns this address (true) or if another switch owns this address (false)
Remote: Indicates whether this address is reachable via a VXLAN on another switch (true) or is reachable locally on the switch (false)
Time: Date and time the data was collected
VLAN Id: Identifier of an associated VLAN if deployed
VLANs
Displays all configured VLANs on the switch. This tab provides the following additional data about each VLAN:
Hostname: User-defined name of the switch
IfName: Name of the interface
Last Changed: Data and time that the VLAN was last updated or deleted
Ports: Ports used by the VLAN
SVI: Indicates whether is the VLAN has a switch virtual interface (yes) or not (no)
Time: Date and time the data was collected
VLANs: Name of the VLAN
IP Routes
Displays all known IP routes for the switch. This tab provides the following additional data about each route:
Hostname: User-defined name of the switch
Is IPv6: Indicates whether the route is based on an IPv6 address (true) or an IPv4 address (false)
Message Type: Service type; always route
NextHops: List of hops in the route
Origin: Indicates whether the route is owned by this switch (true) or not (false)
Prefix: Prefix for the address
Priority: Indicates the importance of the route; higher priority is used before lower priority
Route Type: Kind of route, where the type is dependent on the protocol
RT Table Id: Identifier of the routing table that contains this route
Source: Address of source switch; *None* if this switch is the source
Time: Date and time the data was collected
VRF: Name of the virtual route forwarding (VRF) interface if used by the route
IP Neighbors
Displays all known IP neighbors of the switch. This tab provides the following additional data about each neighbor:
Hostname: User-defined name of the switch
IfIndex: Index of the interface
IfName: Name of the interface
IP Address: IP address of the neighbor
Is IPv6: Indicates whether the address is an IPv6 address (true) or an IPv4 address (false)
Is Remote: Indicates whether this address is reachable via a VXLAN on another switch (true) or is reachable locally on the switch (false)
MAC Address: MAC address of neighbor
Message Type: Service type; always neighbor
OpId: Process identifier; for internal use only
Time: Date and time the data was collected
VRF: Name of the virtual route forwarding (VRF) interface if deployed
IP Addresses
Displays all known IP addresses for the switch. This tab provides the following additional data about each address:
Hostname: User-defined name of the switch
IfName: Name of the interface
Is IPv6: Indicates whether the address is an IPv6 address (true) or an IPv4 address (false)
Mask: Mask for the address
Prefix: Prefix for the address
Time: Date and time the data was collected
VRF: Name of the virtual route forwarding (VRF) interface if deployed
BTRFS Utilization
Displays disk utilization information for devices running Cumulus Linux 3.x and the b-tree file system (BTRFS):
Device Allocated: Percentage of the disk space allocated by BTRFS
Hostname: Hostname of the given device
Largest Chunk Size: Largest remaining chunk size on disk
Last Changed: Data and time that the storage allocation was last updated
Rebalance Recommended: Based on rules described in [When to Rebalance BTRFS Partitions](https://ania-stage.dao6mistqkn0c.amplifyapp.com/networking-ethernet-software/knowledge-base/Configuration-and-Usage/Storage/When-to-Rebalance-BTRFS-Partitions/), a rebalance is suggested
Unallocated Space: Amount of space remaining on the disk
Unused Data Chunks Space: Amount of available data chunk space
Installed Packages
Displays all known interfaces on the switch. This tab provides the following additional data about each package:
CL Version: Version of Cumulus Linux associated with the package
Hostname: Hostname of the given event
Last Changed: Data and time that the interface was last enabled, updated, deleted, or changed state to down
Package Name: Name of the package
Package Status: Indicates if the package is installed
Version: Version of the package
SSD Utilization
Displays overall health and utilization of a 3ME3 solid state drive (SSD). This tab provides the following data about each drive:
Hostname: Hostname of the device with the 3ME3 drive installed
Last Changed: Data and time that the SSD information was updated
SSD Model: SSD model name
Total PE Cycles Supported: PE cycle rating for the drive
Current PE Cycles Executed: Number of PE cycle run to date
% Remaining PE Cycles: Number of PE cycle available before drive needs to be replaced
Forwarding Resources
Displays usage statistics for all forwarding resources on the switch. This tab provides the following additional data about each resource:
ECMP Next Hops: Maximum number of hops seen in forwarding table, number used, and the percentage of this usage versus the maximum number
Hostname: Hostname where forwarding resources reside
IPv4 Host Entries: Maximum number of hosts in forwarding table, number of hosts used, and the percentage of usage versus the maximum.
IPv4 Route Entries: Maximum number of routes in forwarding table, number of routes used, and the percentage of usage versus the maximum.
IPv6 Host Entries: Maximum number of hosts in forwarding table, number of hosts used, and the percentage of usage versus the maximum.
IPv6 Route Entries: Maximum number of routes in forwarding table, number of routes used, and the percentage of usage versus the maximum.
MAC Entries: Maximum number of MAC addresses in forwarding table, number of MAC addresses used, and the percentage of usage versus the maximum.
MCAST Route: Maximum number of multicast routes in forwarding table, number of multicast routes used, and the percentage of usage versus the maximum.
Time: Date and time the data was collected
Total Routes: Maximum number of total routes in forwarding table, number of total routes used, and the percentage of usage versus the maximum.
ACL Resources
Displays usage statistics for all ACLs on the switch. The following is diplayed for each ACL:
maximum entries in the ACL
number entries used
percentage of this usage versus the maximum
This tab also provides the following additional data about each ACL:
Hostname: Hostname where the ACLs reside
Time: Date and time the data was collected
What Just Happened
Displays displays events based on conditions detected in the data plane on the switch. Refer to What Just Happened for descriptions of the fields in this table.
Sensors
Displays all known sensors on the switch. This tab provides a table for each type of sensor. Select the sensor type using the filter above the table.
Fan:
Hostname: Hostname where the fan sensor resides
Message Type: Type of sensor; always Fan
Description: Text identifying the sensor
Speed (RPM): Revolutions per minute of the fan
Max: Maximum speed of the fan measured by sensor
Min: Minimum speed of the fan measured by sensor
Message: Description
Sensor Name: User-defined name for the fan sensor
Previous State: Operational state of the fan sensor before last update
State: Current operational state of the fan sensor
Time: Date and time the data was collected
Temperature:
Hostname: Hostname where the temperature sensor resides
Message Type: Type of sensor; always Temp
Critical: Maximum temperature (°C) threshold for the sensor
Description: Text identifying the sensor
Lower Critical: Minimum temperature (°C) threshold for the sensor
Max: Maximum temperature measured by sensor
Min: Minimum temperature measured by sensor
Message: Description
Sensor Name: User-defined name for the temperature sensor
Previous State: State of the sensor before last update
State: Current state of the temperature sensor
Temperature: Current temperature measured at sensor
Time: Date and time the data was collected
Power Supply Unit (PSU):
Hostname: Hostname where the temperature sensor resides
Message Type: Type of sensor; always PSU
PIn: Input power (W) measured by sensor
POut: Output power (W) measured by sensor
Sensor Name: User-defined name for the power supply unit sensor
Previous State: State of the sensor before last update
State: Current state of the temperature sensor
Time: Date and time the data was collected
VIn: Input voltage (V) measured by sensor
VOut: Output voltage (V) measured by sensor
Table Actions
Select, export, or filter the list. Refer to Table Settings.
View the Overall Health of a Switch
When you want to monitor the health of a particular switch, open the small Switch card. It is unlikely that you would have this card open for every switch in your network at the same time, but it is useful for tracking selected switches that may have been problematic in the recent past or that you have recently installed. The card shows you alarm status and summary performance score and trend.
To view the summary:
Click , and select Device|Switches. A dialog box opens.
Begin typing the hostname of the device you are interested in. Select it from the suggested matches when it appears.
Select small to open the small size card.
Click Add, or Cancel to exit the process.
In this example, we see that the leaf01 switch has had very few alarms overall, but the number is trending upward, with a total count of 24 alarms currently.
View Health Performance Metrics
When you are monitoring switches that have been problematic or are newly installed, you might want to view more than a summary. Instead, seeing key performance metrics can help you determine where issues might be occurring or how new devices are functioning in the network.
To view the key metrics, open the medium Switch card. The card shows you the overall switch health score and the scores for the key metrics that comprise that score. The key metric scores are based on the number of alarms attributed to the following activities on the switch:
network services, such as BGP, EVPN, MLAG, NTP, and so forth
scheduled traces
interface performance
platform performance
Also included on the card is the total alarm count for all of these metrics. You can view the key performance metrics as numerical scores or as line charts over time, by clicking Charts or Alarms at the top of the card.
View Attributes of a Switch
For a quick look at the key attributes of a particular switch, open the large Switch card. Attributes are displayed as the default tab.
In this example, the items of interest might be the five interfaces that are down and what version of OS and NetQ Agent the switch is running.
View Current Resource Utilization for a Switch
The NetQ GUI enables you to easily view the performance of various hardware components and the network tables. This enables you to determine whether a switch is reaching its maximum load and compare its performance with other switches.
To view the resource utilization on a particular switch:
Open the large Switch card.
Hover over the card and click .
The card is divided into two sections, displaying hardware-related performance through a series of charts.
Look at the hardware performance charts. Are there any that are reaching critical usage levels?
Is usage high at a particular time of day?
Change the time period. Is the performance about the same? Better? Worse? The results can guide your decisions about upgrade options.
Open a different Switch card for a comparable switch. Is the performance similar?
View Interface Statistics for a Switch
If you suspect that a particular switch is having performance problems, you might want to view the status of its interfaces. The statistics can also provide insight into interfaces that are more heavily loaded than others.
To view interface statistics:
Click .
Begin typing the name of the switch of interest, and select when it appears in the suggestions list.
Select the Large card size.
Click Add.
Hover over the card and click to open the Interface Stats tab.
Select an interface from the list, scrolling down until you find it. By default the interfaces are sorted by Name, but you may find it easier to sort by the highest transmit or receive utilization using the filter above the list.
The charts update according to your selection. Scroll up and down to view the individual statistics.
What you view next depends on what you see, but a couple of possibilities include:
Open the full screen card to view details about all of the IP addresses, MAC addresses, and interfaces on the switch.
Open another switch card to compare performance on a similar interface.
View All Addresses for a Switch
It can be useful to view all of the configured addresses that this switch is using. You can view all IP addresses or all MAC addresses using the full screen Switch card.
To view all IP addresses:
Open the full screen Switch card. Click IP addresses.
By default All IP addresses are selected. Click IPv6 or IPv4 above the table to view only those IP addresses.
Review the addresses for any anomalies, to obtain prefix information, determine if it is an IPv4 or IPv6 address, and so forth.
To return to the workbench, click in the top right corner.
To view all MAC addresses:
Open the full screen Switch card and click MAC Addresses.
Review the addresses for any anomalies, to see the associated egress port, associated VLANs, and so forth.
To return to the workbench, click in the top right corner.
View All Interfaces on a Switch
You can view all of the configured interfaces on a switch in one place making it easier to see inconsistencies in the configuration, quickly see when changes were made, and the operational status.
To view all interfaces:
Open the full-screen Switch card and click All Interfaces.
Look for interfaces that are down, shown in the State column.
Look for recent changes to the interfaces, shown in the Last Changed column.
View details about each interface, shown in the Details column.
Verify they are of the correct kind for their intended function, shown in the Type column.
Verify the correct VRF interface is assigned to an interface, shown in the VRF column.
To return to the workbench, click in the top right corner.
View All Software Packages on a Switch
You can view all of the software installed on a given switch to quickly validate versions and total software installed.
To view all software packages:
Open the full-screen Switch card and click Installed Packages.
Look for packages of interest and their version and status. Sort by a particular parameter by clicking .
Optionally, export the list by selecting all or specific packages, then clicking .
View Disk Storage After BTRFS Allocation
Customers running Cumulus Linux 3.x which uses the BTRFS (b-tree file system) might experience issues with disk space management. This is a known problem of BTRFS because it does not perform periodic garbage collection, or rebalancing. If left unattended, these errors can make it impossible to rebalance the partitions on the disk. To avoid this issue, Cumulus Networks recommends rebalancing the BTRFS partitions in a preemptive manner, but only when absolutely needed to avoid reduction in the lifetime of the disk. By tracking the state of the disk space usage, users can determine when rebalancing should be performed. For details about when a rebalance is recommended, refer to When to Rebalance BTRFS Partitions.
To view the disk state:
Open the full-screen Switch card for a switch of interest:
Type the switch name in the Search box, then use the card size picker to open the full-screen card, or
Click (Switches) and enter the switch name and select the full-screen card size.
Click BTRFS Utilization.
Look for the Rebalance Recommended column.
If the value in that column says Yes, then you are strongly encouraged to rebalance the BTRFS partitions. If it says No, then you can review the other values in the table to determine if you are getting close to needing a rebalance, and come back to view this table at a later time.
View SSD Utilization
For NetQ servers and appliances that have 3ME3 solid state drives (SSDs) installed (primarily in on-premises deployments), you can view the utilization of the drive on-demand. An alarm is generated for drives that drop below 10% health, or have more than a two percent loss of health in 24 hours, indicating the need to rebalance the drive. Tracking SSD utiilization over time enables you to see any downward trend or instability of the drive before you receive an alarm.
To view SSD utilization:
Open the full screen Switch card and click SSD Utilization.
View the average PE Cycles value for a given drive. Is it higher than usual?
View the Health value for a given drive. Is it lower than usual? Less than 10%?
Consider adding the switch cards that are suspect to a workbench for easy tracking.
Monitor Switch Component Inventory
Knowing what components are included on all of your switches aids in upgrade, compliance, and other planning tasks. Viewing this data is accomplished through the Switch Inventory card.
Switch Inventory Card Workflow Summary
The small Switch Inventory card displays:
Item
Description
Indicates data is for switch inventory
Count
Total number of switches in the network inventory
Chart
Distribution of overall health status during the designated time period; fresh versus rotten
The medium Switch Inventory card displays:
Item
Description
Indicates data is for switch inventory
Filter
View fresh switches (those you have heard from recently) or rotten switches (those you have not heard from recently) on this card
Chart
Distribution of switch components (disk size, OS, ASIC, NetQ Agents, CPU, Cumulus Linux licenses, platform, and memory size) during the designated time period. Hover over chart segment to view versions of each component.
Note: You should only have one version of NetQ Agent running and it should match the NetQ Platform release number. If you have more than one, you likely need to upgrade the older agents.
Unique
Number of unique versions of the various switch components. For example, for OS, you might have CL 3.7.1 and CL 3.7.4 making the unique value two.
The large Switch Inventory card contains four tabs.
The Summary tab displays:
Item
Description
Indicates data is for switch inventory
Filter
View fresh switches (those you have heard from recently) or rotten switches (those you have not heard from recently) on this card
Charts
Distribution of switch components (disk size, OS, ASIC, NetQ Agents, CPU, Cumulus Linux licenses, platform, and memory size), divided into software and hardware, during the designated time period. Hover over chart segment to view versions of each component.
Note: You should only have one version of NetQ Agent running and it should match the NetQ Platform release number. If you have more than one, you likely need to upgrade the older agents.
Unique
Number of unique versions of the various switch components. For example, for OS, you might have CL 3.7.6 and CL 3.7.4 making the unique value two.
The ASIC tab displays:
Item
Description
Indicates data is for ASIC information
Filter
View fresh switches (those you have heard from recently) or rotten switches (those you have not heard from recently) on this card
Vendor chart
Distribution of ASIC vendors. Hover over chart segment to view the number of switches with each version.
Model chart
Distribution of ASIC models. Hover over chart segment to view the number of switches with each version.
Show All
Opens full screen card displaying all components for all switches
The Platform tab displays:
Item
Description
Indicates data is for platform information
Filter
View fresh switches (those you have heard from recently) or rotten switches (those you have not heard from recently) on this card
Vendor chart
Distribution of platform vendors. Hover over chart segment to view the number of switches with each vendor.
Platform chart
Distribution of platform models. Hover over chart segment to view the number of switches with each model.
License State chart
Distribution of Cumulus Linux license status. Hover over chart segments to highlight the vendor and platforms that have that license status.
Show All
Opens full screen card displaying all components for all switches
The Software tab displays:
Item
Description
Indicates data is for software information
Filter
View fresh switches (those you have heard from recently) or rotten switches (those you have not heard from recently) on this card
Operating System chart
Distribution of OS versions. Hover over chart segment to view the number of switches with each version.
Agent Version chart
Distribution of NetQ Agent versions. Hover over chart segment to view the number of switches with each version.
Note: You should only have one version of NetQ Agent running and it should match the NetQ Platform release number. If you have more than one, you likely need to upgrade the older agents.
Show All
Opens full screen card displaying all components for all switches
The full screen Switch Inventory card provides tabs for all components, ASIC, platform, CPU, memory, disk, and OS components.
There are a multitude of ways to view and analyze the available data within this workflow. A few examples are provided here.
View a Summary of Communication Status for All Switches
A communication status summary for all of your switches across the network is available from the small Switch Inventory card.
In this example, we see all 13 switches have been heard from recently (they are fresh).
View the Number of Types of Any Component Deployed
For each of the components monitored on a switch, NetQ displays the variety of those component by way of a count. For example, if you have three operating systems running on your switches, say Cumulus Linux, Ubuntu and RHEL, NetQ indicates a total unique count of three OSs. If you only use Cumulus Linux, then the count shows as one.
To view this count for all of the components on the switch:
Open the medium Switch Inventory card.
Note the number in the Unique column for each component.
In the above example, there are four different disk sizes deployed, four different OSs running, four different ASIC vendors and models deployed, and so forth.
Scroll down to see additional components.
By default, the data is shown for switches with a fresh communication status. You can choose to look at the data for switches in the rotten state instead. For example, if you wanted to see if there was any correlation to a version of OS to the switch having a rotten status, you could select Rotten Switches from the dropdown at the top of the card and see if they all use the same OS (count would be 1). It may not be the cause of the lack of communication, but you get the idea.
View the Distribution of Any Component Deployed
NetQ monitors a number of switch components. For each component you can view the distribution of versions or models or vendors deployed across your network for that component.
To view the distribution:
Open the medium or large Switch Inventory card. Each component has a chart showing the distribution.
OR
Hover over a segment of the chart to view the name, version, model or vendor and the number of switches that have been deployed. You can also see the percentage of all switches this total represents. On the large Switch Inventory card, hovering also highlights the related components for the selected component. This is shown in blue here.
Point to additional segments on that component or other components to view their detail.
Scroll down to view additional components.
View the Number of Switches with Invalid or Missing Licenses
It is important to know when you have switches that have invalid or missing Cumulus Linux licenses, as not all of the features are operational without a valid license. Simply open the medium or large Switch Inventory card, and hover over the License chart to see the count.
To view which vendors and platforms have bad or missing licenses, open the large Switch Inventory card, and click to open the Platform tab. Hover over the License State bar chart to highlight the vendor and platforms with the various states.
To view which switches have invalid or missing licenses, either:
Hover over the large Switch Inventory card and click to open the Platform tab. Above the Licenses State or the Vendor chart, click Show All.
Open the full screen Switch Inventory card. Then sort the All Switches tab data table by the License State column to locate the switches with bad or missing licenses.
View the Most Commonly Deployed ASIC
It can be useful to know the quantity and ratio of many components deployed in your network to determine the scope of upgrade tasks, balance vendor reliance, or for detailed troubleshooting. You can view the most commonly deployed components in generally the same way. Some components have additional details contained in large card tabs.
To view the most commonly deployed ASIC, for example:
Open the medium or large Switch Inventory card.
Hover over the largest segment in the ASIC chart. The tooltip that appears shows you the number of switches with the given ASIC and the percentage of your entire switch population with this ASIC.
Click on any other component in a similar fashion to see the most common type of that component.
If you opened the medium Switch Inventory card, switch to the large card.
Hover over the card, and click to open the ASIC tab. Here you can more easily view the various vendors and platforms based on the ASIC deployed.
Hover over the Vendor pie chart to highlight which platforms are supported by the vendor and vice versa; hover over the Model pie chart to see which vendor supports that platform. Moving your cursor off of the charts removes the highlight.
Click on a segment of the Vendor pie chart to drill down and see only that Vendor and its supported models. A filter tag is placed at the top of the charts.
To return to the complete view of vendors and platforms, click on the filter tag.
View the Number of Switches with a Particular NetQ Agent
It is recommended that when you upgrade NetQ that you also upgrade the NetQ Agents. You can determine if you have covered all of your agents using the medium or large Switch Inventory card. To view the NetQ Agent distribution by version:
Open the medium Switch Inventory card.
View the number in the Unique column next to Agent.
If the number is greater than one, you have multiple NetQ Agent versions deployed.
If you have multiple versions, hover over the Agent chart to view the count of switches using each version.
For more detail, switch to the large Switch Inventory card.
Hover over the card and click to open the Software tab.
Hover over the chart on the right to view the number of switches using the various versions of the NetQ Agent.
Hover over the Operating System chart to see which NetQ Agent versions are being run on each OS.
Click either chart to focus on a particular OS or agent version.
To return to the full view, click in the filter tag.
Filter the data on the card by switches that are having trouble communicating, by selecting Rotten Switches from the dropdown above the charts.
View a List of All Data for a Specific Component
When the small, medium and large Switch Inventory cards do not provide either enough information or are not organized in a fashion that provides the information you need, open the full screen Switch Inventory card. Select the component tab of interest and filter and sort as desired. Export the data to a third-party tool, by clicking .
Monitor Network Elements
In addition to network performance monitoring, the Cumulus NetQ UI provides a view into the current status and configuration of the network elements in a tabular, network-wide view. These are helpful when you want to see all data for all of a particular element in your network for troubleshooting, or you want to export a list view.
Some of these views provide data that is also available through the card workflows, but these views are not treated like cards. They only provide the current status; you cannot change the time period of the views, or graph the data within the UI.
Access these tables through the Main Menu (), under the Network heading.
Tables can be manipulated using the settings above the tables, shown here and described in Table Settings.
Pagination options are shown when there are more than 25 results.
View All NetQ Agents
The Agents view provides all available parameter data about all NetQ Agents in the system.
View All Events
The Events view provides all available parameter data about all events in the system.
View All MACs
The MACs (media access control addresses) view provides all available parameter data about all MAC addresses in the system.
View All VLANs
The VLANs (virtual local area networks) view provides all available parameter data about all VLANs in the system.
View All IP Routes
The IP Routes view provides all available parameter data about all IP routes, all IPv4 routes, and all IPv6 routes in the system.
View All IP Neighbors
The IP Neighbors view provides all available parameter data about all IP neighbors, all IPv4 neighbors, and all IPv6 neighbors in the system.
View All IP Addresses
The IP Addresses view provides all available parameter data about all IP addresses, all IPv4 addresses, and all IPv6 addresses in the system.
View All Sensors
The Sensors view provides all available parameter data provided by the power supply units (PSUs), fans, and temperature sensors in the system.
View What Just Happened
The What Just Happened (WJH) feature, available on Mellanox switches, streams detailed and contextual telemetry data for analysis. This provides real-time visibility into problems in the network, such as hardware packet drops due to buffer congestion, incorrect routing, and ACL or layer 1 problems. You must have Cumulus Linux 4.0.0 or later and NetQ 2.4.0 or later to take advantage of this feature.
If your switches are sourced from a vendor other than Mellanox, this view is blank as no data is collected.
When WJH capabilities are combined with Cumulus NetQ, you have the ability to hone in on losses, anywhere in the fabric, from a single management console. You can:
View any current or historic drop information, including the reason for the drop
Identify problematic flows or endpoints, and pin-point exactly where communication is failing in the network
By default, Cumulus Linux 4.0.0 provides the NetQ 2.3.1 Agent and CLI. If you installed Cumulus Linux 4.0.0 on your Mellanox switch, you need to upgrade the NetQ Agent and optionally the CLI to release 2.4.0 or later.
WJH is enabled by default on Mellanox switches and no configuration is required in Cumulus Linux 4.0.0; however, you must enable the NetQ Agent to collect the data in NetQ 2.4.0 or later.
To enable WJH in NetQ:
Configure the NetQ Agent on the Mellanox switch.
cumulus@switch:~$ netq config add agent wjh
Restart the NetQ Agent to start collecting the WJH data.
cumulus@switch:~$ netq config restart agent
When you are finished viewing the WJH metrics, you might want to disable the NetQ Agent to reduce network traffic. Use netq config del agent wjh followed by netq config restart agent to disable the WJH feature on the given switch.
Using wjh_dump.py on a Mellanox platform that is running Cumulus Linux 4.0 and the NetQ 2.4.0 agent causes the NetQ WJH client to stop receiving packet drop call backs. To prevent this issue, run wjh_dump.py on a different system than the one where the NetQ Agent has WJH enabled, or disable wjh_dump.py and restart the NetQ Agent (run netq config restart agent).
View What Just Happened Metrics
The What Just Happened view displays events based on conditions detected in the data plane. The most recent 1000 events from the last 24 hours are presented for each drop category.
Item
Description
Title
What Just Happened
Closes full screen card and returns to workbench
Results
Number of results found for the selected tab
L1 Drops tab
Displays the reason why a port is in the down state. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Port Down Reason: Reason why the port is down
Port admin down: Port has been purposely set down by user
Auto-negotiation failure: Negotiation of port speed with peer has failed
Logical mismatch with peer link: Logical mismatch with peer link
Link training failure: Link is not able to go operational up due to link training failure
Peer is sending remote faults: Peer node is not operating correctly
Bad signal integrity: Integrity of the signal on port is not sufficient for good communication
Cable/transceiver is not supported: The attached cable or transceiver is not supported by this port
Cable/transceiver is unplugged: A cable or transceiver is missing or not fully plugged into the port
Calibration failure: Calibration failure
Port state changes counter: Cumulative number of state changes
Symbol error counter: Cumulative number of symbol errors
CRC error counter: Cumulative number of CRC errors
Corrective Action: Provides recommend action(s) to take to resolve the port down state
First Timestamp: Date and time this port was marked as down for the first time
Ingress Port: Port accepting incoming traffic
CRC Error Count: Number of CRC errors generated by this port
Symbol Error Count: Number of Symbol errors generated by this port
State Change Count: Number of state changes that have occurred on this port
OPID: Operation identifier; used for internal purposes
Is Port Up: Indicates whether the port is in an Up (true) or Down (false) state
L2 Drops tab
Displays the reason for a link to be down. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Source Port: Port ID where the link originates
Source IP: Port IP address where the link originates
Source MAC: Port MAC address where the link originates
Destination Port: Port ID where the link terminates
Destination IP: Port IP address where the link terminates
Destination MAC: Port MAC address where the link terminates
Reason: Reason why the link is down
MLAG port isolation: Not supported for port isolation implemented with system ACL
Destination MAC is reserved (DMAC=01-80-C2-00-00-0x): The address cannot be used by this link
VLAN tagging mismatch: VLAN tags on the source and destination do not match
Ingress VLAN filtering: Frames whose port is not a member of the VLAN are discarded
Ingress spanning tree filter: Port is in Spanning Tree blocking state
Unicast MAC table action discard: Currently not supported
Multicast egress port list is empty: No ports are defined for multicast egress
Port loopback filter: Port is operating in loopback mode; packets are being sent to itself (source MAC address is the same as the destination MAC address
Source MAC is multicast: Packets have multicast source MAC address
Source MAC equals destination MAC: Source MAC address is the same as the destination MAC address
First Timestamp: Date and time this link was marked as down for the first time
Aggregate Count : Total number of dropped packets
Protocol: ID of the communication protocol running on this link
Ingress Port: Port accepting incoming traffic
OPID: Operation identifier; used for internal purposes
Router Drops tab
Displays the reason why the server is unable to route a packet. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Reason: Reason why the server is unable to route a packet
Non-routable packet: Packet has no route in routing table
Blackhole route: Packet received with action equal to discard
Unresolved next-hop: The next hop in the route is unknown
Blackhole ARP/neighbor: Packet received with blackhole adjacency
IPv6 destination in multicast scope FFx0:/16: Packet received with multicast destination address in FFx0:/16 address range
IPv6 destination in multicast scope FFx1:/16: Packet received with multicast destination address in FFx1:/16 address range
Non-IP packet: Cannot read packet header because it is not an IP packet
Unicast destination IP but non-unicast destination MAC: Cannot read packet with IP unicast address when destination MAC address is not unicast (FF:FF:FF:FF:FF:FF)
Destination IP is loopback address: Cannot read packet as destination IP address is a loopback address (dip=>127.0.0.0/8)
Source IP is multicast: Cannot read packet as source IP address is a multicast address (ipv4 SIP => 224.0.0.0/4)
Source IP is in class E: Cannot read packet as source IP address is a Class E address
Source IP is loopback address: Cannot read packet as source IP address is a loopback address ( ipv4 => 127.0.0.0/8 for ipv6 => ::1/128)
Source IP is unspecified: Cannot read packet as source IP address is unspecified (ipv4 = 0.0.0.0/32; for ipv6 = ::0)
Checksum or IP ver or IPv4 IHL too short: Cannot read packet due to header checksum error, IP version mismatch, or IPv4 header length is too short
Multicast MAC mismatch: For IPv4, destination MAC address is not equal to {0x01-00-5E-0 (25 bits), DIP[22:0]} and DIP is multicast. For IPv6, destination MAC address is not equal to {0x3333, DIP[31:0]} and DIP is multicast.
Source IP equals destination IP: Packet has a source IP address equal to the destination IP address
IPv4 source IP is limited broadcast: Packet has broadcast source IP address
IPv4 destination IP is local network (destination = 0.0.0.0/8): Packet has IPv4 destination address that is a local network (destination=0.0.0.0/8)
IPv4 destination IP is link local: Packet has IPv4 destination address that is a local link
Ingress router interface is disabled: Packet destined to a different subnet cannot be routed because ingress router interface is disabled
Egress router interface is disabled: Packet destined to a different subnet cannot be routed because egress router interface is disabled
IPv4 routing table (LPM) unicast miss: No route available in routing table for packet
IPv6 routing table (LPM) unicast miss: No route available in routing table for packet
Router interface loopback: Packet has destination IP address that is local. For example, SIP = 1.1.1.1, DIP = 1.1.1.128.
Packet size is larger than MTU: Packet has larger MTU configured than the VLAN
TTL value is too small: Packet has TTL value of 1
Tunnel Drops tab
Displays the reason for a tunnel to be down. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Reason: Reason why the tunnel is down
Overlay switch - source MAC is multicast: Overlay packet's source MAC address is multicast
Overlay switch - source MAC equals destination MAC: Overlay packet's source MAC address is the same as the destination MAC address
Decapsulation error: Decapsulation produced incorrect format of packet. For example, encapsulation of packet with many VLANs or IP options on the underlay can cause decapsulation to result in a short packet.
Buffer Drops tab
Displays the reason for the server buffer to be drop packets. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Reason: Reason why the buffer dropped packet
Tail drop: Tail drop is enabled, and buffer queue is filled to maximum capacity
WRED: Weighted Random Early Detection is enabled, and buffer queue is filled to maximum capacity or the RED engine dropped the packet as of random congestion prevention.
ACL Drops tab
Displays the reason for an ACL to drop packets. By default, the listing is sorted by Last Timestamp. The tab provides the following additional data about each drop event:
Hostname: Name of the Mellanox server
Reason: Reason why ACL dropped packets
Ingress port ACL: ACL action set to deny on the ingress port
Ingress router ACL: ACL action set to deny on the ingress router interface
Egress port ACL: ACL action set to deny on the egress port
Egress router ACL: ACL action set to deny on the egress router interface
Table Actions
Select, export, or filter the list. Refer to Table Settings.
Monitor Using Topology View
The core capabilities of Cumulus NetQ enable you to monitor your network by viewing performance and configuration data about your individual network devices and the entire fabric network-wide. The topics contained in this section describe monitoring tasks that can be performed from a topology view rather than through the NetQ UI card workflows or the NetQ CLI.
Access the Topology View
To open the topology view, click in any workbench header.
This opens the full screen view of your network topology.
This document uses the Cumulus Networks reference topology for all examples.
To close the view, click in the top right corner.
Topology Overview
The topology view provides a visual representation of your Linux network, showing the connections and device information for all monitored nodes, for an alternate monitoring and troubleshooting perspective. The topology view uses a number of icons and elements to represent the nodes and their connections as follows:
Symbol
Usage
Switch running Cumulus Linux OS
Switch running RedHat, Ubuntu, or CentOS
Host with unknown operating system
Host running Ubuntu
Red
Alarm (critical) event is present on the node
Yellow
Info event is present
Lines
Physical links or connections
Interact with the Topology
There are a number of ways in which you can interact with the topology.
Move the Topology Focus
You can move the focus on the topology closer to view a smaller number of nodes, or further out to view a larger number of nodes. As with mapping applications, the node labels appear and disappear as you move in and out on the diagram for better readability. To zoom, you can use:
the zoom controls, , in the bottom right corner of the screen; the ‘+’ zooms you in closer, the ‘-’ moves you further out, and the ‘o’ resets to the default size.
a scrolling motion on your mouse
your trackpad
You can also click anywhere on the topology, and drag it left, right, up, or down to view a different portion of the network diagram. This is especially helpful with larger topologies.
View Data About the Network
You can hover over the various elements to view data about them. Hovering over a node highlights its connections to other nodes, temporarily de-emphasizing all other connections.
Hovering over a line highlights the connection and displays the interface ports used on each end of the connection. All other connections are temporarily de-emphasized.
You can also click on the nodes and links to open the Configuration Panel with additional data about them.
From the Configuration Panel, you can view the following data about nodes and links:
Node Data
Description
ASIC
Name of the ASIC used in the switch. A value of Cumulus Networks VX indicates a virtual machine.
License State
Status of the Cumulus Linux license for the switch; OK, BAD (missing or invalid), or N/A (for hosts)
NetQ Agent Status
Operational status of the NetQ Agent on the switch; Fresh, Rotten
NetQ Agent Version
Version ID of the NetQ Agent on the switch
OS Name
Operating system running on the switch
Platform
Vendor and name of the switch hardware
Open Card/s
Opens the Event
Number of alarm events present on the switch
Number of info events present on the switch
Link Data
Description
Source
Switch where the connection originates
Source Interface
Port on the source switch used by the connection
Target
Switch where the connection ends
Target Interface
Port on the destination switch used by the connection
After reviewing the provided information, click to close the panel, or to view data for another node or link without closing the panel, simply click on that element. The panel is hidden by default.
When no devices or links are selected, you can view the unique count of items in the network by clicking on the on the upper left to open the count summary. Click to close the panel.
You can change the time period for the data as well. This enables you to view the state of the network in the past and compare it with the current state. Click in the timestamp box in the topology header to select an alternate time period.
Hide Events on Topology Diagram
You can hide the event symbols on the topology diagram. Simple move the Events toggle in the header to the left. Move the toggle to the right to show them again.
Export Your NetQ Topology Data
The topology view provides the option to export your topology information as a JSON file. Click Export in the header.
This guide is intended for network administrators who are responsible
for monitoring and troubleshooting the network in their data center
environment. NetQ 2.x offers the ability to easily monitor and manage
your data center network infrastructure and operational health. This
guide provides instructions and information about monitoring individual
components of the network, the network as a whole, and the NetQ software
itself using the NetQ command line interface (CLI). If you prefer to use
a graphical interface, refer to the Cumulus NetQ UI User Guide.
NetQ Command Line Overview
The NetQ CLI provides access to all of the network state and event information collected by the NetQ Agents. It behaves the same way most CLIs behave, with groups of commands used to display related information, the ability to use TAB completion when entering commands, and to get help for given commands and options. The commands are grouped into four categories: check, show, config, and trace.
The NetQ command line interface only runs on switches and server hosts implemented with Intel x86 or ARM-based architectures. If you are unsure what architecture your switch or server employs, check the Cumulus Hardware Compatibility List and verify the value in the Platforms tab > CPU column.
CLI Access
When NetQ is installed or upgraded, the CLI may also be installed and enabled on your NetQ server or appliance and hosts. Refer to the Install NetQ topic for details.
To access the CLI from a switch or server:
Log in to the device. This example uses the default username of cumulus and a hostname of switch.
<computer>:~<username>$ ssh cumulus@switch
Enter your password to reach the command prompt. The default password is
CumulusLinux! For example:
Enter passphrase for key '/Users/<username>/.ssh/id_rsa': <enter CumulusLinux! here>
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-112-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Last login: Tue Sep 15 09:28:12 2019 from 10.0.0.14
cumulus@switch:~$
Run commands. For example:
cumulus@switch:~$ netq show agents
cumulus@switch:~$ netq check bgp
Command Line Basics
This section describes the core structure and behavior of the NetQ CLI. It includes the following:
The Cumulus NetQ command line has a flat structure as opposed to a modal structure. This means that all commands can be run from the primary prompt instead of only in a specific mode. For example, some command lines require the administrator to switch between a configuration mode and an operation mode. Configuration commands can only be run in the configuration mode and operational commands can only be run in operation mode. This structure requires the administrator to switch between modes to run commands which can be tedious and time consuming. Cumulus NetQ command line enables the administrator to run all of its commands at the same level.
Command Syntax
NetQ CLI commands all begin with netq. Cumulus NetQ commands fall into one of four syntax categories: validation (check), monitoring (show), configuration, and trace.
netq check <network-protocol-or-service> [options]
netq show <network-protocol-or-service> [options]
netq config <action> <object> [options]
netq trace <destination> from <source> [options]
Symbols
Meaning
Parentheses ( )
Grouping of required parameters. Choose one.
Square brackets [ ]
Single or group of optional parameters. If more than one object or keyword is available, choose one.
Angle brackets < >
Required variable. Value for a keyword or option; enter according to your deployment nomenclature.
Pipe |
Separates object and keyword options, also separates value options; enter one object or keyword and zero or one value.
For example, in the netq check command:
[<hostname>] is an optional parameter with a variable value named hostname
<network-protocol-or-service> represents a number of possible key words, such as agents, bgp, evpn, and so forth
<options> represents a number of possible conditions for the given object, such as around, vrf, or json
Thus some valid commands are:
netq leaf02 check agents json
netq show bgp
netq config restart cli
netq trace 10.0.0.5 from 10.0.0.35
Command Output
The command output presents results in color for many commands. Results with errors are shown in red, and warnings are shown in yellow. Results without errors or warnings are shown in either black or green. VTEPs are shown in blue. A node in the pretty output is shown in bold, and a router interface is wrapped in angle brackets (< >). To view the output with only black text, run the netq config del color command. You can view output with colors again by running netq config add color.
All check and show commands are run with a default timeframe of now to one hour ago, unless you specify an approximate time using the around keyword. For example, running netq check bgp shows the status of BGP over the last hour. Running netq show bgp around 3h shows the status of BGP three hours ago.
Command Prompts
NetQ code examples use the following prompts:
cumulus@switch:~$ Indicates the user cumulus is logged in to a switch to run the example command
cumulus@host:~$ Indicates the user cumulus is logged in to a host to run the example command
cumulus@netq-appliance:~$ Indicates the user cumulus is logged in to either the NetQ Appliance or NetQ Cloud Appliance to run the command
The switches must be running the Cumulus Linux operating system (OS), NetQ Platform software, and the NetQ Agent. The hosts must be running CentOS, RHEL, or Ubuntu OS and the NetQ Agent. Refer to the Install NetQ topic for details.
Command Completion
As you enter commands, you can get help with the valid keywords or options using the Tab key. For example, using Tab completion with netq check displays the possible objects for the command, and returns you to the command prompt to complete the command.
cumulus@switch:~$ netq check <<press Tab>>
agents : Netq agent
bgp : BGP info
cl-version : Cumulus Linux version
clag : Cumulus Multi-chassis LAG
evpn : EVPN
interfaces : network interface port
license : License information
mtu : Link MTU
ntp : NTP
ospf : OSPF info
sensors : Temperature/Fan/PSU sensors
vlan : VLAN
vxlan : VXLAN data path
cumulus@switch:~$ netq check
Command Help
As you enter commands, you can get help with command syntax by entering help at various points within a command entry. For example, to find out what options are available for a BGP check, enter help after entering a portion of the netq check command. In this example, you can see that there are no additional required parameters and two optional parameters, vrf and around, that can be used with a BGP check.
The CLI stores commands issued within a session, which enables you to review and rerun commands that have already been run. At the command prompt, press the Up Arrow and Down Arrow keys to move back and forth through the list of commands previously entered. When you have found a given command, you can run the command by pressing Enter, just as you would if you had entered it manually. Optionally you can modify the command before you run it.
Command Categories
While the CLI has a flat structure, the commands can be conceptually grouped into four functional categories:
The netqcheck commands enable the network administrator to validate the current or historical state of the network by looking for errors and misconfigurations in the network. The commands run fabric-wide validations against various configured protocols and services to determine how well the network is operating. Validation checks can be performed for the following:
agents: NetQ Agents operation on all switches and hosts
bgp: BGP (Border Gateway Protocol) operation across the network
fabric
clag: Cumulus Multi-chassis LAG (link aggregation) operation
mlag: Cumulus Multi-chassis LAG (link aggregation) operation
mtu: Link MTU (maximum transmission unit) consistency across paths
ntp: NTP (Network Time Protocol) operation
ospf: OSPF (Open Shortest Path First) operation
sensors: Temperature/Fan/PSU sensor operation
vlan: VLAN (Virtual Local Area Network) operation
vxlan: VXLAN (Virtual Extensible LAN) data path operation
The commands take the form of netq check <network-protocol-or-service> [options], where the options vary according to the protocol or service.
This example shows the output for the netq check bgp command, followed by the same command using the json option. If there had been any failures, they would be have been listed below the summary results or in the failedNodes section, respectively.
The netq show commands enable the network administrator to view
details about the current or historical configuration and status of the
various protocols or services. The configuration and status can be shown
for the following:
agents: NetQ Agents status on switches and hosts
bgp: BGP status across the network fabric
cl-btrfs-info: BTRFS file system data for monitored Cumulus Linux switches
cl-manifest: Information about the versions of Cumulus Linux available on monitored switches
cl-pkg-info: Information about software packages installed on monitored switches
cl-resource: ACL and forwarding information
cl-ssd-util: SSD utilization information
clag: CLAG/MLAG status
ethtool-stats: Interface statistics
events: Display changes over time
evpn: EVPN status
interface-stats: Interface statistics
interface-utilization: Interface statistics plus utilization
interfaces: network interface port status
inventory: hardware component information
ip: IPv4 status
ipv6: IPv6 status
job-status: status of jobs running on the OPTA
kubernetes: Kubernetes cluster, daemon, pod, node, service and replication status
lldp: LLDP status
mac-history: Historical information for a MAC address
macs: MAC table or address information
mlag: MLAG status (an alias for CLAG)
notification: Slack or PagerDuty notification configurations
ntp: NTP status
opta-health: Display health of apps on the OPTA
opta-platform: NetQ Appliance version information and uptime
ospf: OSPF status
recommended-pkg-version: Current host information to be considered
resource-util: Display usage of memory, CPU and disk resources
sensors: Temperature/Fan/PSU sensor status
services: System services status
tca: Threshold crossing alerts
trace: Control plane trace path across fabric
unit-tests: Show list of unit tests for netq check
validation: Schedule a validation check
vlan: VLAN status
vxlan: VXLAN data path status
wjh-drop: drop information from Mellanox What Just Happened
The commands take the form of netq [<hostname>] show <network-protocol-or-service> [options], where the options vary according to the protocol or service. The commands can be restricted from showing the information for all devices to showing information for a selected device using the hostname option.
This example shows the standard and restricted output for the netq show agents command.
cumulus@switch:~$ netq leaf01 show agents
Matching agents records:
Hostname Status NTP Sync Version Sys Uptime Agent Uptime Reinitialize Time Last Changed
----------------- ---------------- -------- ------------------------------------ ------------------------- ------------------------- -------------------------- -------------------------
leaf01 Fresh yes 2.3.0-cl3u21~1569246310.30858c3 15h:57m:24s 15h:57m:15s 15h:57m:15s Mon Sep 23 22:43:55 2019
Configuration Commands
The netq config and netq notification commands enable the network administrator to manage NetQ Agent and CLI server configuration, set up container monitoring, and event notification.
The agent configuration commands enable you to add and remove agents from switches and hosts, start and stop agent operations, add and remove Kubernetes container monitoring, add or remove sensors, debug the agent, and add or remove FRR (FRRouting).
Commands apply to one agent at a time, and are run from the switch or host where the NetQ Agent resides.
This example shows how to view the NetQ Agent configuration.
cumulus@switch:~$ netq config show agent
netq-agent value default
--------------------- --------- ---------
enable-opta-discovery True True
exhibitport
agenturl
server 127.0.0.1 127.0.0.1
exhibiturl
vrf default default
agentport 8981 8981
port 31980 31980
After making configuration changes to your agents, you must restart the agent for the changes to take effect. Use the netq config restart agent command.
CLI Configuration
The CLI commands enable the network administrator to configure and
manage the CLI component. These commands enable you to add or remove CLI (essentially enabling/disabling the service), start and restart it, and view the configuration of the service.
Commands apply to one device at a time, and are run from the switch or host where the CLI is run.
The CLI configuration commands include:
netq config add cli server
netq config del cli server
netq config show cli premises [json]
netq config show (cli|all) [json]
netq config (status|restart) cli
This example shows how to restart the CLI instance.
cumulus@switch~:$ netq config restart cli
This example shows how to enable the CLI on a NetQ Platform or NetQ
Appliance.
cumulus@switch~:$ netq config add cli server 10.1.3.101
This example shows how to enable the CLI on a NetQ Cloud Appliance with a single premise.
netq config add cli server api.netq.cumulusnetworks.com access-key <user-access-key> secret-key <user-secret-key> port 443
Event Notification Commands
The notification configuration commands enable you to add, remove and show notification application integrations. These commands create the channels, filters, and rules needed to control event messaging. The commands include:
The trace commands enable the network administrator to view the available paths between two nodes on the network currently and at a time in the past. You can perform a layer 2 or layer 3 trace, and view the output in one of three formats (json, pretty, and detail). JSON output provides the output in a JSON file format for ease of importing to other applications or software. Pretty output lines up the paths in a pseudo-graphical manner to help visualize multiple paths. Detail output is useful for traces with higher hop counts where the pretty output wraps lines, making it harder to interpret the results. The detail output displays a table with a row for each path.
A number of commands have changed in this release to accommodate the addition of new options or to simplify their syntax. Additionally, new commands have been added and others have been removed. A summary of those changes is provided here.
New Commands
The following table summarizes the new commands available with this release. They include lifecycle management (LCM) and modular agent commands.
The port, rx and tx options are now required. Removed the min option. Added the extended option to show more statistics.
3.0.0
netq [<hostname>] show events [level info | level error | level warning | level critical | level debug] [type clsupport | type ntp | type mtu | type configdiff | type vlan | type trace | type vxlan | type clag | type bgp | type interfaces | type interfaces-physical | type agents | type ospf | type evpn | type macs | type services | type lldp | type license | type os | type sensors | type btrfsinfo] [between <text-time> and <text-endtime>] [json]
netq [<hostname>] show events [level info | level error | level warning | level critical | level debug] [type clsupport | type ntp | type mtu | type configdiff | type vlan | type trace | type vxlan | type clag | type bgp | type interfaces | type interfaces-physical | type agents | type ospf | type evpn | type lnv | type macs | type services | type lldp | type license | type os | type sensors | type btrfsinfo] [between <text-time> and <text-endtime>] [json]
Removed type lnv since LNV is no longer supported in Cumulus Linux.
3.0.0
netq [<hostname>] show interface-utilization [<text-port>] [tx|rx] [around <text-time>] [json]
netq [<hostname>] show interface-utils [<text-port>] [tx|rx] [around <text-time>] [json]
Changed interface-utils keyword to interface-utilization.
Added the ability to display all addresses in a subnet or supernet or the layer 3 gateway of an address.
3.0.0
Removed Commands
The following table summarizes the previously deprecated commands that have been removed from Cumulus NetQ.
Command
Summary
Version
netq [<hostname>] show lnv [around <text-time>] [json]
LNV is no longer supported in Cumulus Linux.
3.0.0
netq check lnv [around <text-time>] [json]
LNV is no longer supported in Cumulus Linux.
3.0.0
Configure Lifecycle Management
This topic for network administrators only.
As an administrator, you want to manage the deployment of Cumulus Networks product software onto your network devices (servers, appliances, and switches) in the most efficient way and with the most information about the process as possible. With this release, NetQ introduces Lifecycle Management (LCM) to the NetQ CLI, which supports Cumulus Linux image, switch, and credential management.
Switch access credentials are needed for upgrading Cumulus Linux on the switches. You can choose between basic authentication (username and password) and SSH key-based authentication. These credentials apply to all switches.
To configure basic authentication for the cumulus user with the password CumulusLinux!, run:
To configure authentication using a public SSH key, run:
netq lcm add credentials ssh-key PUBLIC_SSH_KEY
View Credentials
A switch can have just one set of credentials. To see the credentials, run netq lcm show credentials.
If an SSH key is used for the credentials, the public key is displayed in the command output:
cumulus@switch:~$ netq lcm show credentials
Type SSH Key Username Password Last Changed
---------------- -------------- ---------------- ---------------- -------------------------
SSH MY-SSH-KEY Tue Apr 28 19:08:52 2020
If a username and passord is used for the credentials, the username is displayed in the command output but the password is masked:
cumulus@leaf01:mgmt-vrf:~$ netq lcm show credentials
Type SSH Key Username Password Last Changed
---------------- -------------- ---------------- ---------------- -------------------------
BASIC cumulus ************** Tue Apr 28 19:10:27 2020
Remove Credentials
To remove the credentials, run netq lcm del credentials.
Configure Switch Roles
Four pre-defined switch roles are available. Their names are based on Clos architecture:
Superspine
Spine
Leaf
Exit
Switch roles are used to:
Identify switch dependencies and determine the order in which switches are upgraded.
Determine when to stop if an upgrade fails.
For more information about managing switch roles, see Role Management.
To configure one or more switches for a given role, run netq lcm add role command. For example, to configure leaf01 through leaf04 in the leaf role, run:
netq lcm add role leaf switches leaf01,leaf02,leaf03,leaf04
Show Switch Roles
To see the roles of the switches in the fabric, run netq lcm show switches. You can filter the list by a particular version by running netq lcm show switches version X.Y.Z.
After installing NetQ 3.0, there are no Cumulus Linux images in the LCM repository. You can upload Cumulus Linux binary images to a local LCM repository for use with installation and upgrade of your switches.
For more information about Cumulus Linux images and LCM, read Image Management.
Download the version of Cumulus Linux you plan to use to upgrade the switches from the MyMellanox downloads page.
Upload the image onto an accessible part of your network. The following example uses the Cumulus Linux 3.7.12 disk image, named cumulus-linux-3.7.12-bcm-amd64.bin.
LCM provides the ability to upgrade Cumulus Linux on switches on your network through NetQ. Once the image is uploaded and the switch credentials are configured, you can upgrade the operating system. To do you, you need:
A Cumulus Linux license file accessible over the network.
A Cumulus Linux install image accessible over the network.
The ID for the Cumulus Linux image.
The names of the switches you plan to upgrade.
To upgrade one or more switches:
Get the Cumulus Linux install image ID. Determine the image ID intended to upgrade the switches and copy it.
cumulus@switch:~$ netq lcm show images
ID Name CL Version CPU ASIC Last Changed
------------------------- --------------- -------------------- -------- --------------- -------------------------
cl_image_69ce56d15b7958de cumulus-linux-3 3.7.12 x86_64 VX Fri Apr 24 15:20:02 2020
5bb8371e9c4bf2fc9131da9a5 .7.12-vx-amd64.
7b13853e2a60ca109238b22 bin
cl_image_1187bd949568aba7 cumulus-linux-3 3.7.11 x86_64 VX Fri Apr 24 14:55:13 2020
eff1b37b1dec394cb832ceb4d .7.11-vx-amd64.
94e234d9a1f62deb279c405 bin
Perform the upgrade:
cumulus@switch:~$ netq lcm upgrade name upgrade-3712 image-id cl_image_69ce56d15b7958de5bb8371e9c4bf2fc9131da9a57b13853e2a60ca109238b22 license LICENSE hostnames spine01,spine02 order spine
You can assign an order for which switches to upgrade based on the switch roles defined above. For example, to upgrade the spines before the leafs, add the order ROLE1,ROLE2 option to the command:
cumulus@switch:~$ netq lcm upgrade name upgrade-3712 image-id cl_image_69ce56d15b7958de5bb8371e9c4bf2fc9131da9a57b13853e2a60ca109238b22 license LICENSE hostnames spine01,spine02,leaf01,leaf02 order spine,leaf
If the switches have not been assigned a role, then do not use the order option. So in this example, if switches spine01 and spine02 have not been assigned the spine role, then do not specify the order spine option.
You can also decide to run LCM before and after the upgrade by adding the run-before-after option to the command:
cumulus@switch:~$ netq lcm upgrade name upgrade-3712 image-id cl_image_69ce56d15b7958de5bb8371e9c4bf2fc9131da9a57b13853e2a60ca109238b22 license LICENSE hostnames spine01,spine02,leaf01,leaf02 order spine,leaf run-before-after
Running an Upgrade Job Again
Every upgrade job requires a unique name. If the upgrade job fails, you need to provide a new name for the job in order to run the upgrade job again. You can get the history of all previous upgrade jobs to ensure that the new upgrade job does not have a duplicate name.
To see a history of previous upgrades that have been run, run netq lcm show upgrade-jobs:
cumulus@switch:~$ netq lcm show upgrade-jobs
Job ID Name CL Version Pre-Check Status Warnings Errors Start Time
------------ --------------- -------------------- -------------------------------- ---------------- ------------ --------------------
job_upgrade_ 3.7.12 Upgrade 3.7.12 WARNING Fri Apr 24 20:27:47
fda24660-866 2020
9-11ea-bda5-
ad48ae2cfafb
job_upgrade_ DataCenter 3.7.12 WARNING Mon Apr 27 17:44:36
81749650-88a 2020
e-11ea-bda5-
ad48ae2cfafb
job_upgrade_ Upgrade to CL3. 3.7.12 COMPLETED Fri Apr 24 17:56:59
4564c160-865 7.12 2020
3-11ea-bda5-
ad48ae2cfafb
To see details a particular upgrade job, run netq lcm show status job-ID:
To back up and restore the switches themselves, use the config-backup and config-restore commands in Cumulus Linux directly on the switches. For more information, read the Cumulus Linux user guide.
Monitor Overall Network Health
NetQ provides the information you need to monitor the health of your network fabric, devices, and interfaces. You are able to easily validate the operation and view the configuration across the entire network from switches to hosts to containers. For example, you can monitor the operation of routing protocols and virtual network configurations, the status of NetQ Agents and hardware components, and the operation and efficiency of interfaces. When issues are present, NetQ makes it easy to identify and resolve them. You can also see when changes have occurred to the network, devices, and interfaces by viewing their operation, configuration, and status at an earlier point in time.
Validate Network Health
NetQ check commands validate the various elements of your network fabric, looking for inconsistencies in configuration across your fabric, connectivity faults, missing configuration, and so forth, and then and display the results for your assessment. They can be run from any node in the network.
Validate the Network Fabric
You can validate the following network fabric elements:
cumulus@switch:~$ netq check
agents : Netq agent
bgp : BGP info
cl-version : Cumulus Linux version
clag : Cumulus Multi-chassis LAG
evpn : EVPN
interfaces : network interface port
license : License information
mlag : Multi-chassis LAG (alias of clag)
mtu : Link MTU
ntp : NTP
ospf : OSPF info
sensors : Temperature/Fan/PSU sensors
vlan : VLAN
vxlan : VXLAN data path
Validation Commands
The validation commands have been changed in this release:
You can view more detail about the validation tests that are run with each command
You can filter these tests to run only those tests of interest
If you are running scripts based on the older version of the netq check commands and want to stay with the old output, edit the netq.yml file to include old-check: true in the netq-cli section of the file. For example:
Then run netq config restart cli to apply the change.
If you update your scripts to work with the new version of the commands, simply change the old-check value to false or remove it. Then restart the CLI.
Each of the check commands provides a starting point for troubleshooting configuration and connectivity issues within your network in real time.
Use netq check mlag in place of netq check clag from NetQ 2.4 onward. netq check clag remains available for automation scripts, but you should begin migrating to netq check mlag to maintain compatibility with future NetQ releases.
You can view only the summary of the validation results by running the netq check commands with summary option; for example, netq check agents summary or netq check evpn summary. This summary displays such data as the total number of nodes checked, how many failed a test, total number of sessions checked, how many of these that failed, and so forth.
You can view more information about the individual tests that are run as part of the validation, including individual tests for agents.
You can run validations for a time in the past and output the results in JSON format if desired. The around option enables users to view the network state at an earlier time. The around option value requires an integer plus a unit of measure (UOM), with no space between them. The following are valid UOMs:
UOM
Command Value
Example
day(s)
<#>d
3d
hour(s)
<#>h
6h
minute(s)
<#>m
30m
second(s)
<#>s
20s
If you want to go back in time by months or years, use the equivalent number of days.
You can include or exclude one or more of the various tests performed during the validation. Each test is assigned a number, which is used to identify which tests to run. By default, all tests are run. The value of <protocol-number-range-list> is a number list separated by commas, or a range using a dash, or a combination of these. Do not use spaces after commas. For example:
include 1,3,5
include 1-5
include 1,3-5
exclude 6,7
exclude 6-7
exclude 3,4-7,9
The output indicates whether a given test passed, failed, or was skipped.
Output from the netq check commands are color-coded; green for successful results and red for failures, warnings, and errors. Use the netq config add color command to enable the use of color.
What the NetQ Validation System Checks
Each of the netq check commands perform a set of validation tests appropriate to the protocol or element being validated.
To view the list of tests run for a given protocol or service, use either netq show unit-tests <protocol/service> or perform a tab completion on netq check <protocol/service> [include|exclude].
This section describes these tests.
NetQ Agent Validation Tests
The netq check agents command looks for an agent status of Rotten for each node in the network. A Fresh status indicates the Agent is running as expected. The Agent sends a heartbeat every 30 seconds, and if three consecutive heartbeats are missed, its status changes to Rotten. This check only runs one test:
Test Number
Test Name
Description
0
Agent Health
Checks for nodes that have failed or lost communication
BGP Validation Tests
The netq check bgp command runs the following tests to establish session sanity:
Test Number
Test Name
Description
0
Session Establishment
Checks that BGP sessions are in an established state
1
Address Families
Checks if transmit and receive address family advertisement is consistent between peers of a BGP session
2
Router ID
Checks for BGP router ID conflict in the network
CLAG Validation Tests
The netq check clag command runs the following tests:
Test Number
Test Name
Description
0
Peering
Checks if:
CLAG peerlink is up
CLAG peerlink bond slaves are down (not in full capacity and redundancy)
Peering is established between two nodes in a CLAG pair
1
Backup IP
Checks if:
CLAG backup IP configuration is missing on a CLAG node
CLAG backup IP is correctly pointing to the CLAG peer and its connectivity is available
2
Clag Sysmac
Checks if:
CLAG Sysmac is consistently configured on both nodes in a CLAG pair
there is any duplication of a CLAG sysmac within a bridge domain
3
VXLAN Anycast IP
Checks if the VXLAN anycast IP address is consistently configured on both nodes in a CLAG pair
4
Bridge Membership
Checks if the CLAG peerlink is part of bridge
5
Spanning Tree
Checks if:
STP is enabled and running on the CLAG nodes
CLAG peerlink role is correct from STP perspective
the bridge ID is consistent between two nodes of a CLAG pair
the VNI in the bridge has BPDU guard and BPDU filter enabled
6
Dual Home
Checks for:
CLAG bonds that are not in dually connected state
dually connected bonds have consistent VLAN and MTU configuration on both sides
STP has consistent view of bonds' dual connectedness
7
Single Home
Checks for:
singly connected bonds
STP has consistent view of bond’s single connectedness
8
Conflicted Bonds
Checks for bonds in CLAG conflicted state and shows the reason
9
ProtoDown Bonds
Checks for bonds in protodown state and shows the reason
10
SVI
Checks if:
an SVI is configured on both sides of a CLAG pair
SVI on both sides have consistent MTU setting
Cumulus Linux Version Tests
The netq check cl-version command runs the following tests:
Test Number
Test Name
Description
0
Cumulus Linux Image Version
Checks the following:
no version specified, checks that all switches in the network have consistent version
match-version specified, checks that a switch’s OS version is equal to the specified version
min-version specified, checks that a switch’s OS version is equal to or greater than the specified version
EVPN Validation Tests
The netq check evpn command runs the following tests to establish session sanity:
Test Number
Test Name
Description
0
EVPN BGP Session
Checks if:
BGP EVPN sessions are established
the EVPN address family advertisement is consistent
1
EVPN VNI Type Consistency
Because a VNI can be of type L2 or L3, checks that for a given VNI, its type is consistent across the network
2
EVPN Type 2
Checks for consistency of IP-MAC binding and the location of a given IP-MAC across all VTEPs
3
EVPN Type 3
Checks for consistency of replication group across all VTEPs
4
EVPN Session
For each EVPN session, checks if:
adv_all_vni is enabled
FDB learning is disabled on tunnel interface
5
Vlan Consistency
Checks for consistency of VLAN to VNI mapping across the network
6
Vrf Consistency
Checks for consistency of VRF to L3 VNI mapping across the network
Interface Validation Tests
The netq check interfaces command runs the following tests:
Test Number
Test Name
Description
0
Admin State
Checks for consistency of administrative state on two sides of a physical interface
1
Oper State
Checks for consistency of operational state on two sides of a physical interface
2
Speed
Checks for consistency of the speed setting on two sides of a physical interface
3
Autoneg
Checks for consistency of the auto-negotiation setting on two sides of a physical interface
License Validation Tests
The netq check license command runs the following test:
Test Number
Test Name
Description
0
License Validity
Checks for validity of license on all switches
Link MTU Validation Tests
The netq check mtu command runs the following tests:
Test Number
Test Name
Description
0
Link MTU Consistency
Checks for consistency of MTU setting on two sides of a physical interface
1
VLAN interface
Checks if the MTU of an SVI is no smaller than the parent interface, substracting the VLAN tag size
2
Bridge interface
Checks if the MTU on a bridge is not arbitrarily smaller than the smallest MTU among its members
MLAG Validation Tests
The netq check mlag command runs the following tests:
Test Number
Test Name
Description
0
Peering
Checks if:
MLAG peerlink is up
MLAG peerlink bond slaves are down (not in full capacity and redundancy)
Peering is established between two nodes in a MLAG pair
1
Backup IP
Checks if:
MLAG backup IP configuration is missing on a MLAG node
MLAG backup IP is correctly pointing to the MLAG peer and its connectivity is available
2
Clag Sysmac
Checks if:
MLAG Sysmac is consistently configured on both nodes in a MLAG pair
there is any duplication of a MLAG sysmac within a bridge domain
3
VXLAN Anycast IP
Checks if the VXLAN anycast IP address is consistently configured on both nodes in an MLAG pair
4
Bridge Membership
Checks if the MLAG peerlink is part of bridge
5
Spanning Tree
Checks if:
STP is enabled and running on the MLAG nodes
MLAG peerlink role is correct from STP perspective
the bridge ID is consistent between two nodes of a MLAG pair
the VNI in the bridge has BPDU guard and BPDU filter enabled
6
Dual Home
Checks for:
MLAG bonds that are not in dually connected state
dually connected bonds have consistent VLAN and MTU configuration on both sides
STP has consistent view of bonds' dual connectedness
7
Single Home
Checks for:
singly connected bonds
STP has consistent view of bond’s single connectedness
8
Conflicted Bonds
Checks for bonds in MLAG conflicted state and shows the reason
9
ProtoDown Bonds
Checks for bonds in protodown state and shows the reason
10
SVI
Checks if:
an SVI is configured on both sides of a MLAG pair
SVI on both sides have consistent MTU setting
NTP Validation Tests
The netq check ntp command runs the following test:
Test Number
Test Name
Description
0
NTP Sync
Checks if the NTP service is running and in sync state
OSPF Validation Tests
The netq check ospf command runs the following tests to establish session sanity:
Test Number
Test Name
Description
0
Router ID
Checks for OSPF router ID conflicts in the network
1
Adjacency
Checks or OSPF adjacencies in a down or unknown state
2
Timers
Checks for consistency of OSPF timer values in an OSPF adjacency
3
Network Type
Checks for consistency of network type configuration in an OSPF adjacency
4
Area ID
Checks for consistency of area ID configuration in an OSPF adjacency
5
Interface MTU
Checks for MTU consistency in an OSPF adjacency
6
Service Status
Checks for OSPF service health in an OSPF adjacency
Sensor Validation Tests
The netq check sensors command runs the following tests:
Test Number
Test Name
Description
0
PSU sensors
Checks for power supply unit sensors that are not in ok state
1
Fan sensors
Checks for fan sensors that are not in ok state
2
Temperature sensors
Checks for temperature sensors that are not in ok state
VLAN Validation Tests
The netq check vlan command runs the following tests:
Test Number
Test Name
Description
0
Link Neighbor VLAN Consistency
Checks for consistency of VLAN configuration on two sides of a port or a bond
1
CLAG Bond VLAN Consistency
Checks for consistent VLAN membership of a CLAG bond on each side of the CLAG pair
VXLAN Validation Tests
The netq check vxlan command runs the following tests:
Test Number
Test Name
Description
0
VLAN Consistency
Checks for consistent VLAN to VXLAN mapping across all VTEPs
1
BUM replication
Checks for consistent replication group membership across all VTEPs
Validation Examples
This section provides validation examples for a variety of protocols and elements.
Perform a NetQ Agent Validation
The default validation confirms that the NetQ Agent is running on all monitored nodes and provides a summary of the validation results. This example shows the results of a fully successful validation.
cumulus@switch:~$ netq check agents
agent check result summary:
Checked nodes : 13
Total nodes : 13
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Agent Health Test : passed
Perform a BGP Validation
The default validation runs a network-wide BGP connectivity and configuration check on all nodes running the BGP service:
cumulus@switch:~$ netq check bgp
bgp check result summary:
Checked nodes : 8
Total nodes : 8
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Total Sessions : 30
Failed Sessions : 0
Session Establishment Test : passed
Address Families Test : passed
Router ID Test : passed
This example indicates that all nodes running BGP and all BGP sessions are running properly. If there were issues with any of the nodes, NetQ would provide information about each node to aid in resolving the issues.
Perform a BGP Validation for a Particular VRF
Using the vrf <vrf> option of the netq check bgp command, you can validate the BGP service where communication is occurring through a particular virtual route. In this example, the VRF of interest is named vrf1.
cumulus@switch:~$ netq check bgp vrf vrf1
bgp check result summary:
Checked nodes : 2
Total nodes : 2
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Total Sessions : 2
Failed Sessions : 0
Session Establishment Test : passed
Address Families Test : passed
Router ID Test : passed
Perform a BGP Validation with Selected Tests
Using the include <bgp-number-range-list> and exclude <bgp-number-range-list> options, you can include or exclude one or more of the various checks performed during the validation. You can select from the following BGP validation tests:
The default validation runs a network-wide CLAG connectivity and configuration check on all nodes running the CLAG service. This example shows results for a fully successful validation.
cumulus@switch:~$ netq check clag
clag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Peering Test : passed,
Backup IP Test : passed,
Clag SysMac Test : passed,
VXLAN Anycast IP Test : passed,
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
This example shows representative results for one or more failures, warnings, or errors. In particular, you can see that you have duplicate system MAC addresses.
cumulus@switch:~$ netq check clag
clag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 2
Warning nodes : 0
Peering Test : passed,
Backup IP Test : passed,
Clag SysMac Test : 0 warnings, 2 errors,
VXLAN Anycast IP Test : passed,
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
Clag SysMac Test details:
Hostname Reason
----------------- ---------------------------------------------
leaf01 Duplicate sysmac with leaf02/None
leaf03 Duplicate sysmac with leaf04/None
Perform a CLAG Validation with Selected Tests
Using the include <clag-number-range-list> and exclude <clag-number-range-list> options, you can include or exclude one or more of the various checks performed during the validation. You can select from the following CLAG validation tests:
To include only the CLAG SysMAC test during a validation:
cumulus@switch:~$ netq check clag include 2
clag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 2
Warning nodes : 0
Peering Test : skipped
Backup IP Test : skipped
Clag SysMac Test : 0 warnings, 2 errors,
VXLAN Anycast IP Test : skipped
Bridge Membership Test : skipped
Spanning Tree Test : skipped
Dual Home Test : skipped
Single Home Test : skipped
Conflicted Bonds Test : skipped
ProtoDown Bonds Test : skipped
SVI Test : skipped
Clag SysMac Test details:
Hostname Reason
----------------- ---------------------------------------------
leaf01 Duplicate sysmac with leaf02/None
leaf03 Duplicate sysmac with leaf04/None
To exclude the backup IP, CLAG SysMAC, and VXLAN anycast IP tests during a validation:
cumulus@switch:~$ netq check clag exclude 1-3
clag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Peering Test : passed,
Backup IP Test : skipped
Clag SysMac Test : skipped
VXLAN Anycast IP Test : skipped
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
Perform a Cumulus Linux Version Validation
The default validation (using no options) checks that all switches in the network have a consistent version.
cumulus@switch:~$ netq check cl-version
version check result summary:
Checked nodes : 12
Total nodes : 12
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Cumulus Linux Image Version Test : passed
Perform an EVPN Validation
The default validation runs a network-wide EVPN connectivity and configuration check on all nodes running the EVPN service. This example shows results for a fully successful validation.
cumulus@switch:~$ netq check evpn
evpn check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed BGP Sessions : 0
Total Sessions : 16
Total VNIs : 3
EVPN BGP Session Test : passed,
EVPN VNI Type Consistency Test : passed,
EVPN Type 2 Test : passed,
EVPN Type 3 Test : passed,
EVPN Session Test : passed,
Vlan Consistency Test : passed,
Vrf Consistency Test : passed,
Perform an EVPN Validation for a Time in the Past
Using the around option, you can view the state of the EVPN service at a time in the past. Be sure to include the UOM.
cumulus@switch:~$ netq check evpn around 4d
evpn check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed BGP Sessions : 0
Total Sessions : 16
Total VNIs : 3
EVPN BGP Session Test : passed,
EVPN VNI Type Consistency Test : passed,
EVPN Type 2 Test : passed,
EVPN Type 3 Test : passed,
EVPN Session Test : passed,
Vlan Consistency Test : passed,
Vrf Consistency Test : passed,
Perform an EVPN Validation with Selected Tests
Using the include <evpn-number-range-list> and exclude <evpn-number-range-list> options, you can include or exclude one or more of the various checks performed during the validation. You can select from the following EVPN validation tests:
cumulus@switch:~$ netq check evpn include 2
evpn check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed BGP Sessions : 0
Total Sessions : 0
Total VNIs : 3
EVPN BGP Session Test : skipped
EVPN VNI Type Consistency Test : skipped
EVPN Type 2 Test : passed,
EVPN Type 3 Test : skipped
EVPN Session Test : skipped
Vlan Consistency Test : skipped
Vrf Consistency Test : skipped
To exclude the BGP session and VRF consistency tests:
cumulus@switch:~$ netq check evpn exclude 0,6
evpn check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed BGP Sessions : 0
Total Sessions : 0
Total VNIs : 3
EVPN BGP Session Test : skipped
EVPN VNI Type Consistency Test : passed,
EVPN Type 2 Test : passed,
EVPN Type 3 Test : passed,
EVPN Session Test : passed,
Vlan Consistency Test : passed,
Vrf Consistency Test : skipped
To run only the first five tests:
cumulus@switch:~$ netq check evpn include 0-4
evpn check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed BGP Sessions : 0
Total Sessions : 16
Total VNIs : 3
EVPN BGP Session Test : passed,
EVPN VNI Type Consistency Test : passed,
EVPN Type 2 Test : passed,
EVPN Type 3 Test : passed,
EVPN Session Test : passed,
Vlan Consistency Test : skipped
Vrf Consistency Test : skipped
Perform an Interfaces Validation
The default validation runs a network-wide connectivity and configuration check on all interfaces. This example shows results for a fully successful validation.
cumulus@switch:~$ netq check interfaces
interface check result summary:
Checked nodes : 12
Total nodes : 12
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Unverified Ports : 56
Checked Ports : 108
Failed Ports : 0
Admin State Test : passed,
Oper State Test : passed,
Speed Test : passed,
Autoneg Test : passed,
Perform an Interfaces Validation for a Time in the Past
Using the around option, you can view the state of the interfaces at a time in the past. Be sure to include the UOM.
cumulus@switch:~$ netq check interfaces around 6h
interface check result summary:
Checked nodes : 12
Total nodes : 12
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Unverified Ports : 56
Checked Ports : 108
Failed Ports : 0
Admin State Test : passed,
Oper State Test : passed,
Speed Test : passed,
Autoneg Test : passed,
Perform an Interfaces Validation with Selected Tests
Using the include <interface-number-range-list> and exclude <interface-number-range-list> options, you can include or exclude one or more of the various checks performed during the validation. You can select from the following interface validation tests:
You can also check for any nodes that have invalid licenses without going to each node. Because switches do not operate correctly without a valid license you might want to verify that your Cumulus Linux licenses on a regular basis.
This example shows that all licenses on switches are valid.
This command checks every node, meaning every switch and host in the network. Hosts do not require a Cumulus Linux license, so the number of licenses checked might be smaller than the total number of nodes checked.
Perform a Link MTU Validation
The default validate verifies that all corresponding interface links have matching MTUs. This example shows no mismatches.
cumulus@switch:~$ netq check mtu
mtu check result summary:
Checked nodes : 12
Total nodes : 12
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Warn Links : 0
Failed Links : 0
Checked Links : 196
Link MTU Consistency Test : passed,
VLAN interface Test : passed,
Bridge interface Test : passed,
Perform an MLAG Validation
The default validation runs a network-wide MLAG connectivity and configuration check on all nodes running the MLAG service. This example shows results for a fully successful validation.
cumulus@switch:~$ netq check mlag
mlag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Peering Test : passed,
Backup IP Test : passed,
Clag SysMac Test : passed,
VXLAN Anycast IP Test : passed,
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
This example shows representative results for one or more failures, warnings, or errors. In particular, you can see that you have duplicate system MAC addresses.
cumulus@switch:~$ netq check mlag
mlag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 2
Warning nodes : 0
Peering Test : passed,
Backup IP Test : passed,
Clag SysMac Test : 0 warnings, 2 errors,
VXLAN Anycast IP Test : passed,
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
Clag SysMac Test details:
Hostname Reason
----------------- ---------------------------------------------
leaf01 Duplicate sysmac with leaf02/None
leaf03 Duplicate sysmac with leaf04/None
Perform an MLAG Validation with Selected Tests
Using the include <mlag-number-range-list> and exclude <mlag-number-range-list> options, you can include or exclude one or more of the various checks performed during the validation. You can select from the following MLAG validation tests:
To include only the CLAG SysMAC test during a validation:
cumulus@switch:~$ netq check mlag include 2
mlag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 2
Warning nodes : 0
Peering Test : skipped
Backup IP Test : skipped
Clag SysMac Test : 0 warnings, 2 errors,
VXLAN Anycast IP Test : skipped
Bridge Membership Test : skipped
Spanning Tree Test : skipped
Dual Home Test : skipped
Single Home Test : skipped
Conflicted Bonds Test : skipped
ProtoDown Bonds Test : skipped
SVI Test : skipped
Clag SysMac Test details:
Hostname Reason
----------------- ---------------------------------------------
leaf01 Duplicate sysmac with leaf02/None
leaf03 Duplicate sysmac with leaf04/None
To exclude the backup IP, CLAG SysMAC, and VXLAN anycast IP tests during a validation:
cumulus@switch:~$ netq check mlag exclude 1-3
mlag check result summary:
Checked nodes : 4
Total nodes : 4
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Peering Test : passed,
Backup IP Test : skipped
Clag SysMac Test : skipped
VXLAN Anycast IP Test : skipped
Bridge Membership Test : passed,
Spanning Tree Test : passed,
Dual Home Test : passed,
Single Home Test : passed,
Conflicted Bonds Test : passed,
ProtoDown Bonds Test : passed,
SVI Test : passed,
Perform an NTP Validation
The default validation checks for synchronization of the NTP server with all nodes in the network. It is always important to have your devices in time synchronization to ensure configuration and management events can be tracked and correlations can be made between events.
The default validation runs a network-wide OSPF connectivity and configuration check on all nodes running the OSPF service. This example shows results several errors in the Timers and Interface MTU tests.
cumulus@switch:~# netq check ospf
Checked nodes: 8, Total nodes: 8, Rotten nodes: 0, Failed nodes: 4, Warning nodes: 0, Failed Adjacencies: 4, Total Adjacencies: 24
Router ID Test : passed
Adjacency Test : passed
Timers Test : 0 warnings, 4 errors
Network Type Test : passed
Area ID Test : passed
Interface Mtu Test : 0 warnings, 2 errors
Service Status Test : passed
Timers Test details:
Hostname Interface PeerID Peer IP Reason Last Changed
----------------- ------------------------- ------------------------- ------------------------- --------------------------------------------- -------------------------
spine-1 downlink-4 torc-22 uplink-1 dead time mismatch Mon Jul 1 16:18:33 2019
spine-1 downlink-4 torc-22 uplink-1 hello time mismatch Mon Jul 1 16:18:33 2019
torc-22 uplink-1 spine-1 downlink-4 dead time mismatch Mon Jul 1 16:19:21 2019
torc-22 uplink-1 spine-1 downlink-4 hello time mismatch Mon Jul 1 16:19:21 2019
Interface Mtu Test details:
Hostname Interface PeerID Peer IP Reason Last Changed
----------------- ------------------------- ------------------------- ------------------------- --------------------------------------------- -------------------------
spine-2 downlink-6 0.0.0.22 27.0.0.22 mtu mismatch Mon Jul 1 16:19:02 2019
tor-2 uplink-2 0.0.0.20 27.0.0.20 mtu mismatch Mon Jul 1 16:19:37 2019
Perform a Sensors Validation
Hardware platforms have a number sensors to provide environmental data about the switches. Knowing these are all within range is a good check point for maintenance.
For example, if you had a temporary HVAC failure and you are concerned that some of your nodes are beginning to overheat, you can run this validation to determine if any switches have already reached the maximum temperature threshold.
cumulus@switch:~$ netq check sensors
sensors check result summary:
Checked nodes : 8
Total nodes : 8
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Checked Sensors : 136
Failed Sensors : 0
PSU sensors Test : passed,
Fan sensors Test : passed,
Temperature sensors Test : passed,
Perform a VLAN Validation
Validate that VLANS are configured and operating properly:
cumulus@switch:~$ netq check vlan
vlan check result summary:
Checked nodes : 12
Total nodes : 12
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Additional summary:
Failed Link Count : 0
Total Link Count : 196
Link Neighbor VLAN Consistency Test : passed,
Clag Bond VLAN Consistency Test : passed,
Perform a VXLAN Validation
Validate that VXLANs are configured and operating properly:
cumulus@switch:~$ netq check vxlan
vxlan check result summary:
Checked nodes : 6
Total nodes : 6
Rotten nodes : 0
Failed nodes : 0
Warning nodes : 0
Vlan Consistency Test : passed,
BUM replication Test : passed,
Both asymmetric and symmetric VXLAN configurations are validated with this command.
Validation Check Result Filtering
You can create filters to suppress false alarms or uninteresting errors and warnings that can be a nuisance in CI workflows. For example, certain configurations permit a singly-connected CLAG bond and the standard error that is generated is not useful.
Filtered errors and warnings related to validation checks do NOT generate notifications and are not counted in the alarm and info event totals. They are counted as part of suppressed notifications instead.
The filters are defined in the check-filter.yml file in the /etc/netq/ directory. You can create a rule for individual check commands or you can create a global rule that applies to all tests run by the check command. Additionally, you can create a rule specific to a particular test run by the check command.
Each rule must contain at least one match criteria and an action response. The only action currently available is filter. The match can be comprised of multiple criteria, one per line, creating a logical AND. Matches can be made against any column in the validation check output. The match criteria values must match the case and spacing of the column names in the corresponding netq check output and are parsed as regular expressions.
This example shows a global rule for the BGP checks that indicates any events generated by the DataVrf virtual route forwarding interface coming from swp3 or swp7. are to be suppressed. It also shows a test-specific rule to filter all Address Families events from devices with hostnames starting with exit-1 or firewall.
You can configure filters to change validation errors to warnings that would normally occur due to the default expectations of the netq check commands. This applies to all protocols and services, except for Agents. For example, if you have provisioned BGP with configurations where a BGP peer is not expected or desired, you will get errors that a BGP peer is missing. By creating a filter, you can remove the error in favor of a warning.
To create a validation filter:
Navigate to the /etc/netq directory.
Create or open the check_filter.yml file using your text editor of choice.
This file contains the syntax to follow to create one or more rules for one or more protocols or services. Create your own rules, and/or edit and un-comment any example rules you would like to use.
# Netq check result filter rule definition file. This is for filtering
# results based on regex match on one or more columns of each test result.
# Currently, only action 'filter' is supported. Each test can have one or
# more rules, and each rule can match on one or more columns. In addition,
# rules can also be optionally defined under the 'global' section and will
# apply to all tests of a check.
#
# syntax:
#
# <check name>:
# tests:
# <test name, as shown in test list when using the include/exclude and tab>:
# - rule:
# match:
# <column name>: regex
# <more columns and regex.., result is AND>
# action:
# filter
# - <more rules..>
# global:
# - rule:
# . . .
# - rule:
# . . .
#
# <another check name>:
# . . .
#
# e.g.
#
# bgp:
# tests:
# Address Families:
# - rule:
# match:
# Hostname: (^exit*|^firewall)
# VRF: DataVrf1080
# Reason: AFI/SAFI evpn not activated on peer
# action:
# filter
# - rule:
# match:
# Hostname: exit-2
# Reason: SAFI evpn not activated on peer
# action:
# filter
# Router ID:
# - rule:
# match:
# Hostname: exit-2
# action:
# filter
#
# evpn:
# tests:
# EVPN Type 2:
# - rule:
# match:
# Hostname: exit-1
# action:
# filter
#
View Network Details
The netq show commands display a wide variety of content about the network and its various elements. You can show content for the following:
cumulus@switch:~$ netq show [TAB]
agents : Netq agent
bgp : BGP info
cl-btrfs-info : Btrfs Information
cl-manifest : Manifest Information
cl-pkg-info : Package Information
cl-resource : add help text
cl-ssd-util : SSD Utilization Information
clag : Cumulus Multi-chassis LAG
ethtool-stats : Interface statistics
events : Display changes over time
evpn : EVPN
interface-stats : Interface statistics
interface-utilization : Interface utils
interfaces : network interface port
inventory : Inventory information
ip : IPv4 related info
ipv6 : IPv6 related info
job-status : add help text
kubernetes : Kubernetes Information
lldp : LLDP based neighbor info
mac-history : Mac history info for a mac address
macs : Mac table or MAC address info
mlag : Multi-chassis LAG (alias of clag)
notification : Send notifications to Slack or PagerDuty
ntp : NTP
opta-health : Display health of apps on the OPTA
opta-platform : Appliance version info and uptime
ospf : OSPF info
recommended-pkg-version : Current host information to be considered
resource-util : add help text
sensors : Temperature/Fan/PSU sensors
services : System services
tca : Threshold Crossing Alerts
trace : Control plane trace path across fabric
unit-tests : Show list of unit tests for netq tests
validation : Schedule a validation check
vlan : VLAN
vxlan : VXLAN data path
wjh-drop : add help text
For example, to validate status of the NetQ agents running in the fabric, run netq show agents. A Fresh status indicates the Agent is running as expected. The Agent sends a heartbeat every 30 seconds, and if three consecutive heartbeats are missed, its status changes to
Rotten.
cumulus@switch:~$ netq show vlan
Matching vlan records:
Hostname VLANs SVIs Last Changed
----------------- ------------------------- ------------------------- -------------------------
exit01 4001 4001 Tue Mar 17 19:52:16 2020
exit02 4001 4001 Tue Mar 17 19:52:16 2020
leaf01 1,13,24,4001 13 24 4001 Tue Mar 17 19:52:16 2020
leaf02 1,13,24,4001 13 24 4001 Tue Mar 17 19:52:16 2020
leaf03 1,13,24,4001 13 24 4001 Tue Mar 17 19:52:16 2020
leaf04 1,13,24,4001 13 24 4001 Tue Mar 17 19:52:16 2020
View the status of the hardware sensors:
cumulus@switch:~$ netq show sensors all
Matching sensors records:
Hostname Name Description State Message Last Changed
----------------- --------------- ----------------------------------- ---------- ----------------------------------- -------------------------
exit01 fan1 fan tray 1, fan 1 ok Wed Feb 6 23:02:35 2019
exit01 fan2 fan tray 1, fan 2 ok Wed Feb 6 23:02:35 2019
exit01 fan3 fan tray 2, fan 1 ok Wed Feb 6 23:02:35 2019
exit01 fan4 fan tray 2, fan 2 ok Wed Feb 6 23:02:35 2019
exit01 fan5 fan tray 3, fan 1 ok Wed Feb 6 23:02:35 2019
exit01 fan6 fan tray 3, fan 2 ok Wed Feb 6 23:02:35 2019
exit01 psu1fan1 psu1 fan ok Wed Feb 6 23:02:35 2019
exit01 psu2fan1 psu2 fan ok Wed Feb 6 23:02:35 2019
exit02 fan1 fan tray 1, fan 1 ok Wed Feb 6 23:03:35 2019
exit02 fan2 fan tray 1, fan 2 ok Wed Feb 6 23:03:35 2019
exit02 fan3 fan tray 2, fan 1 ok Wed Feb 6 23:03:35 2019
exit02 fan4 fan tray 2, fan 2 ok Wed Feb 6 23:03:35 2019
exit02 fan5 fan tray 3, fan 1 ok Wed Feb 6 23:03:35 2019
exit02 fan6 fan tray 3, fan 2 ok Wed Feb 6 23:03:35 2019
exit02 psu1fan1 psu1 fan ok Wed Feb 6 23:03:35 2019
exit02 psu2fan1 psu2 fan ok Wed Feb 6 23:03:35 2019
leaf01 fan1 fan tray 1, fan 1 ok Wed Feb 6 23:01:12 2019
leaf01 fan2 fan tray 1, fan 2 ok Wed Feb 6 23:01:12 2019
leaf01 fan3 fan tray 2, fan 1 ok Wed Feb 6 23:01:12 2019
leaf01 fan4 fan tray 2, fan 2 ok Wed Feb 6 23:01:12 2019
leaf01 fan5 fan tray 3, fan 1 ok Wed Feb 6 23:01:12 2019
leaf01 fan6 fan tray 3, fan 2 ok Wed Feb 6 23:01:12 2019
leaf01 psu1fan1 psu1 fan ok Wed Feb 6 23:01:12 2019
leaf01 psu2fan1 psu2 fan ok Wed Feb 6 23:01:12 2019
leaf02 fan1 fan tray 1, fan 1 ok Wed Feb 6 22:59:54 2019
leaf02 fan2 fan tray 1, fan 2 ok Wed Feb 6 22:59:54 2019
leaf02 fan3 fan tray 2, fan 1 ok Wed Feb 6 22:59:54 2019
leaf02 fan4 fan tray 2, fan 2 ok Wed Feb 6 22:59:54 2019
leaf02 fan5 fan tray 3, fan 1 ok Wed Feb 6 22:59:54 2019
...
Monitor Switch Hardware
With NetQ, a network administrator can monitor the key components of switch an NetQ Appliance hardware, including the motherboard, ASIC, microprocessor,
disk, memory, fan and power supply information. You can also monitor temperature and SSD utilization information. With this data, NetQ helps you answer questions such as:
What switches do I have in the network?
What hardware is installed on my switches?
How many transmit and receive packets have been dropped?
How healthy are the fans and power supply?
NetQ uses LLDP (Link Layer Discovery Protocol) to collect port information. NetQ can also identify peer ports connected to DACs (Direct Attached Cables) and AOCs (Active Optical Cables) without using LLDP, even if the link is not UP.
The NetQ CLI provides a number of netq show commands to monitor switches. The syntax of these commands is:
netq [<hostname>] show inventory brief [opta] [json]
netq [<hostname>] show inventory asic [vendor <asic-vendor>|model <asic-model>|model-id <asic-model-id>] [opta] [json]
netq [<hostname>] show inventory board [vendor <board-vendor>|model <board-model>] [opta] [json]
netq [<hostname>] show inventory cpu [arch <cpu-arch>] [opta] [json]
netq [<hostname>] show inventory disk [name <disk-name>|transport <disk-transport>|vendor <disk-vendor>] [opta] [json]
netq [<hostname>] show inventory license [cumulus] [status ok|status missing] [around <text-time>] [opta] [json]
netq [<hostname>] show inventory memory [type <memory-type>|vendor <memory-vendor>] [opta] [json]
netq [<hostname>] show inventory os [version <os-version>|name <os-name>] [opta] [json]
netq [<hostname>] show sensors all [around <text-time>] [json]
netq [<hostname>] show sensors psu [<psu-name>] [around <text-time>] [json]
netq [<hostname>] show sensors temp [<temp-name>] [around <text-time>] [json]
netq [<hostname>] show sensors fan [<fan-name>] [around <text-time>] [json]
netq [<hostname>] show interface-stats [errors|all] [<physical-port>] [around <text-time>] [json]
netq [<hostname>] show interface-utilization [<text-port>] [tx|rx] [around <text-time>] [json]
netq [<hostname>] show resource-util [cpu | memory] [around <text-time>] [json]
netq [<hostname>] show resource-util disk [<text-diskname>] [around <text-time>] [json]
netq [<hostname>] show cl-ssd-util [around <text-time>] [json]
netq [<hostname>] show cl-btrfs-info [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] [type interfaces-physical|type sensors|type btrfsinfo] [between <text-time> and <text-endtime>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
The keyword values for the vendor, model, model-id, arch,
name, transport, type, version, psu, temp, and fan
keywords are specific to your deployment. For example, if you have
devices with CPU architectures of only one type, say Intel x86, then
that is the only option available for the cpu-arch keyword value. If
you have multiple CPU architectures, say you also have ARMv7, then that
would also be an option for you.
View a Summary of Your Network Inventory
While the detail can be very helpful, sometimes a simple overview of the
hardware inventory is better. This example shows the basic hardware
information for all devices.
You can view the vendor, model, model identifier, core bandwidth
capability, and ports of the ASIC installed on your switch motherboard.
This example shows all of these for all devices.
cumulus@switch:~$ netq show inventory asic
Matching inventory records:
Hostname Vendor Model Model ID Core BW Ports
----------------- -------------------- ------------------------------ ------------------------- -------------- -----------------------------------
dell-z9100-05 Broadcom Tomahawk BCM56960 2.0T 32 x 100G-QSFP28
mlx-2100-05 Mellanox Spectrum MT52132 N/A 16 x 100G-QSFP28
mlx-2410a1-05 Mellanox Spectrum MT52132 N/A 48 x 25G-SFP28 & 8 x 100G-QSFP28
mlx-2700-11 Mellanox Spectrum MT52132 N/A 32 x 100G-QSFP28
qct-ix1-08 Broadcom Tomahawk BCM56960 2.0T 32 x 100G-QSFP28
qct-ix7-04 Broadcom Trident3 BCM56870 N/A 32 x 100G-QSFP28
qct-ix7-04 N/A N/A N/A N/A N/A
st1-l1 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-l2 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-l3 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-s1 Broadcom Trident2 BCM56850 960G 32 x 40G-QSFP+
st1-s2 Broadcom Trident2 BCM56850 960G 32 x 40G-QSFP+
You can filter the results of the command to view devices with a
particular characteristic. This example shows all devices that use a
Broadcom ASIC.
cumulus@switch:~$ netq show inventory asic vendor Broadcom
Matching inventory records:
Hostname Vendor Model Model ID Core BW Ports
----------------- -------------------- ------------------------------ ------------------------- -------------- -----------------------------------
dell-z9100-05 Broadcom Tomahawk BCM56960 2.0T 32 x 100G-QSFP28
qct-ix1-08 Broadcom Tomahawk BCM56960 2.0T 32 x 100G-QSFP28
qct-ix7-04 Broadcom Trident3 BCM56870 N/A 32 x 100G-QSFP28
st1-l1 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-l2 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-l3 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
st1-s1 Broadcom Trident2 BCM56850 960G 32 x 40G-QSFP+
st1-s2 Broadcom Trident2 BCM56850 960G 32 x 40G-QSFP+
You can filter the results of the command view the ASIC information for
a particular switch. This example shows the ASIC information for
st1-11 switch.
cumulus@switch:~$ netq leaf02 show inventory asic
Matching inventory records:
Hostname Vendor Model Model ID Core BW Ports
----------------- -------------------- ------------------------------ ------------------------- -------------- -----------------------------------
st1-l1 Broadcom Trident2 BCM56854 720G 48 x 10G-SFP+ & 6 x 40G-QSFP+
View Information about the Motherboard in a Switch
You can view the vendor, model, base MAC address, serial number, part
number, revision, and manufacturing date for a switch motherboard on a
single device or on all devices. This example shows all of the
motherboard data for all devices.
You can filter the results of the command to capture only those devices
with a particular motherboard vendor. This example shows only the
devices with Celestica motherboards.
cumulus@switch:~$ netq show inventory board vendor celestica
Matching inventory records:
Hostname Vendor Model Base MAC Serial No Part No Rev Mfg Date
----------------- -------------------- ------------------------------ ------------------ ------------------------- ---------------- ------ ----------
st1-l1 CELESTICA Arctica 4806xp 00:E0:EC:27:71:37 D2060B2F044919GD000011 R0854-F1004-01 Redsto 09/20/2014
ne-XP
st1-l2 CELESTICA Arctica 4806xp 00:E0:EC:27:6B:3A D2060B2F044919GD000060 R0854-F1004-01 Redsto 09/20/2014
ne-XP
You can filter the results of the command to view the model for a
particular switch. This example shows the motherboard vendor for the
st1-s1 switch.
cumulus@switch:~$ netq st1-s1 show inventory board
Matching inventory records:
Hostname Vendor Model Base MAC Serial No Part No Rev Mfg Date
----------------- -------------------- ------------------------------ ------------------ ------------------------- ---------------- ------ ----------
st1-s1 Dell S6000-ON 44:38:39:00:80:00 N/A N/A N/A N/A
View Information about the CPU on a Switch
You can view the architecture, model, operating frequency, and the
number of cores for the CPU on a single device or for all devices. This
example shows these CPU characteristics for all devices.
You can filter the results of the command to view which switches employ
a particular CPU architecture using the arch keyword. This example
shows how to determine which architectures are deployed in your network,
and then shows all devices with an x86_64 architecture.
You can filter the results to view CPU information for a single switch,
as shown here for server02.
cumulus@switch:~$ netq server02 show inventory cpu
Matching inventory records:
Hostname Arch Model Freq Cores
----------------- -------- ------------------------------ ---------- -----
server02 x86_64 Intel Core i7 9xx (Nehalem Cla N/A 1
ss Core i7)
View Information about the Disk on a Switch
You can view the name or operating system, type, transport, size,
vendor, and model of the disk on a single device or all devices. This
example shows all of these disk characteristics for all devices.
cumulus@switch:~$ netq show inventory disk
Matching inventory records:
Hostname Name Type Transport Size Vendor Model
----------------- --------------- ---------------- ------------------ ---------- -------------------- ------------------------------
leaf01 vda disk N/A 6G 0x1af4 N/A
leaf02 vda disk N/A 6G 0x1af4 N/A
leaf03 vda disk N/A 6G 0x1af4 N/A
leaf04 vda disk N/A 6G 0x1af4 N/A
oob-mgmt-server vda disk N/A 256G 0x1af4 N/A
server01 vda disk N/A 301G 0x1af4 N/A
server02 vda disk N/A 301G 0x1af4 N/A
server03 vda disk N/A 301G 0x1af4 N/A
server04 vda disk N/A 301G 0x1af4 N/A
spine01 vda disk N/A 6G 0x1af4 N/A
spine02 vda disk N/A 6G 0x1af4 N/A
You can filter the results of the command to view the disk information
for a particular device. This example shows disk information for
leaf03 switch.
cumulus@switch:~$ netq leaf03 show inventory disk
Matching inventory records:
Hostname Name Type Transport Size Vendor Model
----------------- --------------- ---------------- ------------------ ---------- -------------------- ------------------------------
leaf03 vda disk N/A 6G 0x1af4 N/A
View Memory Information for a Switch
You can view the name, type, size, speed, vendor, and serial number for
the memory installed in a single device or all devices. This example
shows all of these characteristics for all devices.
You can filter the results of the command to view devices with a
particular memory type or vendor. This example shows all of the devices
with memory from QEMU .
cumulus@switch:~$ netq show inventory memory vendor QEMU
Matching inventory records:
Hostname Name Type Size Speed Vendor Serial No
----------------- --------------- ---------------- ---------- ---------- -------------------- -------------------------
leaf01 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
leaf02 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
leaf03 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
leaf04 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
oob-mgmt-server DIMM 0 RAM 4096 MB Unknown QEMU Not Specified
server01 DIMM 0 RAM 512 MB Unknown QEMU Not Specified
server02 DIMM 0 RAM 512 MB Unknown QEMU Not Specified
server03 DIMM 0 RAM 512 MB Unknown QEMU Not Specified
server04 DIMM 0 RAM 512 MB Unknown QEMU Not Specified
spine01 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
spine02 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
You can filter the results to view memory information for a single
switch, as shown here for leaf01.
cumulus@switch:~$ netq leaf01 show inventory memory
Matching inventory records:
Hostname Name Type Size Speed Vendor Serial No
----------------- --------------- ---------------- ---------- ---------- -------------------- -------------------------
leaf01 DIMM 0 RAM 1024 MB Unknown QEMU Not Specified
View a Summary of Physical Inventory for the NetQ or NetQ Cloud Appliance
Using the opta option lets you view inventory information for the NetQ or NetQ Cloud Appliance(s) rather than all network nodes. This example give you a summary of the inventory on the device.
cumulus@spine-1:mgmt-vrf:~$ netq show inventory brief opta
Matching inventory records:
Hostname Switch OS CPU ASIC Ports
----------------- -------------------- --------------- -------- --------------- -----------------------------------
10-20-14-158 VX CL x86_64 VX N/A
View Memory for the NetQ or NetQ Cloud Appliance
You can be specific about which inventory item you want to view for an appliance. This example shows the memory information for a NetQ Appliance, letting you verify you have sufficient memory.
cumulus@netq-appliance:~$ netq show inventory memory opta
Matching inventory records:
Hostname Name Type Size Speed Vendor Serial No
----------------- --------------- ---------------- ---------- ---------- -------------------- -------------------------
netq-app DIMM 0 RAM 64 GB Unknown QEMU Not Specified
View Fan Health for All Switches
Fan, power supply unit, and temperature sensors are available to provide
additional data about the NetQ Platform operation. To view the health of
fans in your switches, use the netq show sensors fan command. If you
name the fans in all of your switches consistently, you can view more
information at once.
In this example, we look at the state of all fans with the name fan1.
cumulus@switch:~$ netq show sensors fan fan1
Hostname Name Description State Speed Max Min Message Last Changed
----------------- --------------- ----------------------------------- ---------- ---------- -------- -------- ----------------------------------- -------------------------
exit01 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:17 2019
exit02 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:33 2019
leaf01 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Sun Apr 21 20:07:12 2019
leaf02 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:41 2019
leaf03 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:44 2019
leaf04 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:36 2019
spine01 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:52 2019
spine02 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Fri Apr 19 16:01:08 2019
Use tab completion to determine the names of the fans in your switches:
cumulus@switch:~$ netq show sensors fan <<press tab>>
around : Go back in time to around ...
fan1 : Fan Name
fan2 : Fan Name
fan3 : Fan Name
fan4 : Fan Name
fan5 : Fan Name
fan6 : Fan Name
json : Provide output in JSON
psu1fan1 : Fan Name
psu2fan1 : Fan Name
<ENTER>
To view the status for a particular switch, use the optional hostname
parameter.
cumulus@switch:~$ netq leaf01 show sensors fan fan1
Hostname Name Description State Speed Max Min Message Last Changed
----------------- --------------- ----------------------------------- ---------- ---------- -------- -------- ----------------------------------- -------------------------
leaf01 fan1 fan tray 1, fan 1 ok 2500 29000 2500 Sun Apr 21 20:07:12 2019
View PSU Health for All Switches
Fan, power supply unit, and temperature sensors are available to provide
additional data about the NetQ Platform operation. To view the health of
PSUs in your switches, use the netq show sensors psu command. If you
name the PSUs in all of your switches consistently, you can view more
information at once.
In this example, we look at the state of all PSUs with the name psu2.
cumulus@switch:~$ netq show sensors psu psu2
Matching sensors records:
Hostname Name State Message Last Changed
----------------- --------------- ---------- ----------------------------------- -------------------------
exit01 psu2 ok Fri Apr 19 16:01:17 2019
exit02 psu2 ok Fri Apr 19 16:01:33 2019
leaf01 psu2 ok Sun Apr 21 20:07:12 2019
leaf02 psu2 ok Fri Apr 19 16:01:41 2019
leaf03 psu2 ok Fri Apr 19 16:01:44 2019
leaf04 psu2 ok Fri Apr 19 16:01:36 2019
spine01 psu2 ok Fri Apr 19 16:01:52 2019
spine02 psu2 ok Fri Apr 19 16:01:08 2019
Use Tab completion to determine the names of the PSUs in your switches.
Use the optional hostname parameter to view the PSU state for a given
switch.
View the Temperature in All Switches
Fan, power supply unit, and temperature sensors are available to provide
additional data about the NetQ Platform operation. To view the
temperature sensor status, current temperature, and configured threshold
values, use the netq show sensors temp command. If you name the
temperature sensors in all of your switches consistently, you can view
more information at once.
In this example, we look at the state of all temperature sensors with
the name psu1temp1.
cumulus@switch:~$ netq show sensors temp psu2temp1
Matching sensors records:
Hostname Name Description State Temp Critical Max Min Message Last Changed
----------------- --------------- ----------------------------------- ---------- -------- -------- -------- -------- ----------------------------------- -------------------------
exit01 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:17 2019
exit02 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:33 2019
leaf01 psu2temp1 psu2 temp sensor ok 25 85 80 5 Sun Apr 21 20:07:12 2019
leaf02 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:41 2019
leaf03 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:44 2019
leaf04 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:36 2019
spine01 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:52 2019
spine02 psu2temp1 psu2 temp sensor ok 25 85 80 5 Fri Apr 19 16:01:08 2019
Use Tab completion to determine the names of the temperature sensors in
your switches. Use the optional hostname parameter to view the
temperature state, current temperature, and threshold values for a given
switch.
View All Sensor Data
To view all fan data, all PSU data, or
all temperature data from the sensors, you must view all of the sensor
data. The more consistently you name your sensors, the easier it will be
to view the full sensor data.
cumulus@switch:~$ netq show sensors all
Matching sensors records:
Hostname Name Description State Message Last Changed
----------------- --------------- ----------------------------------- ---------- ----------------------------------- -------------------------
border01 fan3 fan tray 2, fan 1 ok Wed Apr 22 17:07:56 2020
border01 fan1 fan tray 1, fan 1 ok Wed Apr 22 17:07:56 2020
border01 fan6 fan tray 3, fan 2 ok Wed Apr 22 17:07:56 2020
border01 fan5 fan tray 3, fan 1 ok Wed Apr 22 17:07:56 2020
border01 psu2fan1 psu2 fan ok Wed Apr 22 17:07:56 2020
border01 fan2 fan tray 1, fan 2 ok Wed Apr 22 17:07:56 2020
border01 fan4 fan tray 2, fan 2 ok Wed Apr 22 17:07:56 2020
border01 psu1fan1 psu1 fan ok Wed Apr 22 17:07:56 2020
border02 fan1 fan tray 1, fan 1 ok Wed Apr 22 17:07:54 2020
border02 fan2 fan tray 1, fan 2 ok Wed Apr 22 17:07:54 2020
border02 psu1fan1 psu1 fan ok Wed Apr 22 17:07:54 2020
border02 fan5 fan tray 3, fan 1 ok Wed Apr 22 17:07:54 2020
border02 fan3 fan tray 2, fan 1 ok Wed Apr 22 17:07:54 2020
border02 fan6 fan tray 3, fan 2 ok Wed Apr 22 17:07:54 2020
border02 fan4 fan tray 2, fan 2 ok Wed Apr 22 17:07:54 2020
border02 psu2fan1 psu2 fan ok Wed Apr 22 17:07:54 2020
fw1 psu2fan1 psu2 fan ok Wed Apr 22 17:08:45 2020
fw1 fan3 fan tray 2, fan 1 ok Wed Apr 22 17:08:45 2020
fw1 psu1fan1 psu1 fan ok Wed Apr 22 17:08:45 2020
fw1 fan1 fan tray 1, fan 1 ok Wed Apr 22 17:08:45 2020
fw1 fan6 fan tray 3, fan 2 ok Wed Apr 22 17:08:45 2020
fw1 fan5 fan tray 3, fan 1 ok Wed Apr 22 17:08:45 2020
fw1 fan4 fan tray 2, fan 2 ok Wed Apr 22 17:08:45 2020
fw1 fan2 fan tray 1, fan 2 ok Wed Apr 22 17:08:45 2020
fw2 fan3 fan tray 2, fan 1 ok Wed Apr 22 17:07:53 2020
...
View All Sensor-related Events
You can view the events that are triggered by the sensors using the
netq show events command. You can narrow the focus to only critical
events using the severity level option.
cumulus@switch:~$ netq show events type sensors
No matching events records found
cumulus@switch:~$ netq show events level critical type sensors
No matching events records found
View Interface Statistics and Utilization
NetQ Agents collect performance statistics every 30 seconds for the
physical interfaces on switches and hosts in your network. The NetQ
Agent does not collect statistics for non-physical interfaces, such as
bonds, bridges, and VXLANs. The NetQ Agent collects the following statistics:
You can quickly determine how many compute resources — CPU, disk and
memory — are being consumed by the switches on your network. Run the
netq show resource-util command to see the percentage of CPU and memory
being consumed as well as the amount and percentage of disk space being
consumed.
You can use the around option to view the information for a particular time.
cumulus@switch:~$ netq show resource-util
Matching resource_util records:
Hostname CPU Utilization Memory Utilization Disk Name Total Used Disk Utilization Last Updated
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- ------------------------
exit01 9.2 48 /dev/vda4 6170849280 1524920320 26.8 Wed Feb 12 03:54:10 2020
exit02 9.6 47.6 /dev/vda4 6170849280 1539346432 27.1 Wed Feb 12 03:54:22 2020
leaf01 9.8 50.5 /dev/vda4 6170849280 1523818496 26.8 Wed Feb 12 03:54:25 2020
leaf02 10.9 49.4 /dev/vda4 6170849280 1535246336 27 Wed Feb 12 03:54:11 2020
leaf03 11.4 49.4 /dev/vda4 6170849280 1536798720 27 Wed Feb 12 03:54:10 2020
leaf04 11.4 49.4 /dev/vda4 6170849280 1522495488 26.8 Wed Feb 12 03:54:03 2020
spine01 8.4 50.3 /dev/vda4 6170849280 1522249728 26.8 Wed Feb 12 03:54:19 2020
spine02 9.8 49 /dev/vda4 6170849280 1522003968 26.8 Wed Feb 12 03:54:25 2020
You can focus on a specific switch by including the hostname in your query:
cumulus@switch:~$ netq leaf01 show resource-util
Matching resource_util records:
Hostname CPU Utilization Memory Utilization Disk Name Total Used Disk Utilization Last Updated
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- ------------------------
leaf01 9.8 49.9 /dev/vda4 6170849280 1524314112 26.8 Wed Feb 12 04:35:05 2020
View CPU Utilization
You can quickly determine what percentage of CPU resources are being consumed
by the switches on your network. Run the netq show resource-util cpu command.
You can use the around option to view the information for a particular time.
cumulus@switch:~$ netq show resource-util cpu
Matching resource_util records:
Hostname CPU Utilization Last Updated
----------------- -------------------- ------------------------
exit01 8.9 Wed Feb 12 04:29:29 2020
exit02 8.3 Wed Feb 12 04:29:22 2020
leaf01 10.9 Wed Feb 12 04:29:24 2020
leaf02 11.6 Wed Feb 12 04:29:10 2020
leaf03 9.8 Wed Feb 12 04:29:33 2020
leaf04 11.7 Wed Feb 12 04:29:29 2020
spine01 10.4 Wed Feb 12 04:29:38 2020
spine02 9.7 Wed Feb 12 04:29:15 2020
You can focus on a specific switch by including the hostname in your query:
cumulus@switch:~$ netq leaf01 show resource-util cpu
Matching resource_util records:
Hostname CPU Utilization Last Updated
----------------- -------------------- ------------------------
leaf01 11.1 Wed Feb 12 04:16:18 2020
View Disk Utilization
You can quickly determine how much storage, in bytes and in percentage of disk
space, is being consumed by the switches on your network. Run the
netq show resource-util disk command.
You can use the around option to view the information for a particular time.
cumulus@switch:~$ netq show resource-util disk
Matching resource_util records:
Hostname Disk Name Total Used Disk Utilization Last Updated
----------------- -------------------- -------------------- -------------------- -------------------- ------------------------
exit01 /dev/vda4 6170849280 1525309440 26.8 Wed Feb 12 04:29:29 2020
exit02 /dev/vda4 6170849280 1539776512 27.1 Wed Feb 12 04:29:22 2020
leaf01 /dev/vda4 6170849280 1524203520 26.8 Wed Feb 12 04:29:24 2020
leaf02 /dev/vda4 6170849280 1535631360 27 Wed Feb 12 04:29:41 2020
leaf03 /dev/vda4 6170849280 1537191936 27.1 Wed Feb 12 04:29:33 2020
leaf04 /dev/vda4 6170849280 1522864128 26.8 Wed Feb 12 04:29:29 2020
spine01 /dev/vda4 6170849280 1522688000 26.8 Wed Feb 12 04:29:38 2020
spine02 /dev/vda4 6170849280 1522409472 26.8 Wed Feb 12 04:29:46 2020
You can focus on a specific switch and disk drive by including the hostname
and device name in your query:
cumulus@switch:~$ netq leaf01 show resource-util disk /dev/vda4
Matching resource_util records:
Hostname Disk Name Total Used Disk Utilization Last Updated
----------------- -------------------- -------------------- -------------------- -------------------- ------------------------
leaf01 /dev/vda4 6170849280 1524064256 26.8 Wed Feb 12 04:15:45 2020
View Memory Utilization
You can quickly determine what percentage of memory resources are being consumed
by the switches on your network. Run the netq show resource-util memory command.
You can use the around option to view the information for a particular time.
cumulus@switch:~$ netq show resource-util memory
Matching resource_util records:
Hostname Memory Utilization Last Updated
----------------- -------------------- ------------------------
exit01 48.8 Wed Feb 12 04:29:29 2020
exit02 49.7 Wed Feb 12 04:29:22 2020
leaf01 49.8 Wed Feb 12 04:29:24 2020
leaf02 49.5 Wed Feb 12 04:29:10 2020
leaf03 50.7 Wed Feb 12 04:29:33 2020
leaf04 49.3 Wed Feb 12 04:29:29 2020
spine01 47.5 Wed Feb 12 04:29:07 2020
spine02 49.2 Wed Feb 12 04:29:15 2020
You can focus on a specific switch by including the hostname in your query:
cumulus@switch:~$ netq leaf01 show resource-util memory
Matching resource_util records:
Hostname Memory Utilization Last Updated
----------------- -------------------- ------------------------
leaf01 49.8 Wed Feb 12 04:16:18 2020
View SSD Utilization
For NetQ servers and appliances that have 3ME3 solid state drives (SSDs) installed (primarily in on-premises deployments), you can view the utilization of the drive on-demand. An alarm is generated for drives that drop below 10% health, or have more than a two percent loss of health in 24 hours, indicating the need to rebalance the drive. Tracking SSD utilization over time enables you to see any downward trend or instability of the drive before you receive an alarm.
Use the netq show cl-ssd-util command to view the SSD information.
This example shows the utilization for spine02 which has this type of SSD.
cumulus@switch:~$ netq spine02 show cl-ssd-util
Hostname Remaining PE Cycle (%) Current PE Cycles executed Total PE Cycles supported SSD Model Last Changed
spine02 80 576 2880 M.2 (S42) 3ME3 Thu Oct 31 00:15:06 2019
This output indicates that this drive is in a good state overall with 80% of its PE cycles remaining. View this information for all devices with this type of SSD by removing the hostname option, or add the around option to view this information around a particular time.
View Disk Storage Utilization After BTRFS Allocation
Customers running Cumulus Linux 3.x which uses the BTRFS (b-tree file system) might experience issues with disk space management. This is a known problem of BTRFS because it does not perform periodic garbage collection, or rebalancing. If left unattended, these errors can make it impossible to rebalance the partitions on the disk. To avoid this issue, Cumulus Networks recommends rebalancing the BTRFS partitions in a preemptive manner, but only when absolutely needed to avoid reduction in the lifetime of the disk. By tracking the state of the disk space usage, users can determine when rebalancing should be performed. Refer to When to Rebalance BTRFS Partitions for details about the rules used to recommend a rebalance operation.
To view the disk utilization and whether a rebalance is recommended, use the netq show cl-btrfs-util command as follows:
cumulus@switch:~$ netq show cl-btrfs-info
Matching btrfs_info records:
Hostname Device Allocated Unallocated Space Largest Chunk Size Unused Data Chunks S Rebalance Recommende Last Changed
pace d
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
exit01 31.16 % 3.96 GB 588.5 MB 39.13 MB no Wed Oct 30 18:51:35 2019
exit02 31.16 % 3.96 GB 588.5 MB 38.79 MB no Wed Oct 30 19:20:41 2019
leaf01 31.16 % 3.96 GB 588.5 MB 38.75 MB no Wed Oct 30 18:52:34 2019
leaf02 31.16 % 3.96 GB 588.5 MB 38.79 MB no Wed Oct 30 18:51:22 2019
leaf03 31.16 % 3.96 GB 588.5 MB 35.44 MB no Wed Oct 30 18:52:02 2019
leaf04 31.16 % 3.96 GB 588.5 MB 33.49 MB no Wed Oct 30 19:21:15 2019
spine01 31.16 % 3.96 GB 588.5 MB 36.9 MB no Wed Oct 30 19:21:13 2019
spine02 31.16 % 3.96 GB 588.5 MB 39.12 MB no Wed Oct 30 18:52:44 2019
Look for the Rebalance Recommended column. If the value in that column says Yes, then you are strongly encouraged to rebalance the BTRFS partitions. If it says No, then you can review the other values in the output to determine if you are getting close to needing a rebalance, and come back to view this data at a later time.
Optionally, use the hostname option to view the information for a given device, or use the around option to view the information for a particular time.
Monitor Switch Software
With NetQ, a network administrator can monitor the switch software components for misconfigurations. NetQ helps answer questions such as:
What software is installed on my switches?
Are all switches licensed correctly?
What is the ACL and forwarding resources usage?
Do all switches have NetQ Agents running?
The NetQ CLI provides the netq show inventory, netq show cl-<software-item>, and netq show events commands to monitor switches.
The syntax for these commands is:
netq [<hostname>] show agents
netq [<hostname>] show inventory brief [json]
netq [<hostname>] show inventory license [cumulus] [status ok|status missing] [around <text-time>] [json]
netq [<hostname>] show inventory os [version <os-version>|name <os-name>] [json]
netq [<hostname>] show cl-manifest [json]
netq [<hostname>] show cl-pkg-info [<text-package-name>] [around <text-time>] [json]
netq [<hostname>] show recommended-pkg-version [release-id <text-release-id>] [package-name <text-package-name>] [json]
netq [<hostname>] show cl-resource acl [ingress | egress] [around <text-time>] [json]
netq [<hostname>] show cl-resource forwarding [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] [type license|type os] [between <text-time> and <text-endtime>] [json]
The values for the name option are specific to your
deployment. For example, if you have devices with only one type of OS,
say Cumulus Linux, then that is the only option available for the
os-name option value. If you have multiple OSs running, say you also
have Ubuntu, then that would also be an option for you.
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View OS Information for a Switch
You can view the name and version of the OS on a switch, and when it was
last modified. This example shows the OS information for all devices.
You can filter the results of the command to view only devices with a
particular operating system or version. This can be especially helpful
when you suspect that a particular device has not been upgraded as
expected. This example shows all devices with the Cumulus Linux version
3.7.5 installed.
This example shows changes that have been made to the OS on all devices
between 16 and 21 days ago. Remember to use measurement units on the
time values.
cumulus@switch:~$ netq show events type os between 16d and 21d
Matching inventory records:
Hostname Name Version DB State Last Changed
----------------- --------------- ------------------------------------ ---------- -------------------------
mlx-2410a1-05 Cumulus Linux 3.7.3 Add Tue Feb 12 18:30:53 2019
mlx-2700-11 Cumulus Linux 3.7.3 Add Tue Feb 12 18:30:45 2019
mlx-2100-05 Cumulus Linux 3.7.3 Add Tue Feb 12 18:30:26 2019
mlx-2100-05 Cumulus Linux 3.7.3~1533263174.bce9472 Add Wed Feb 13 11:10:47 2019
mlx-2700-11 Cumulus Linux 3.7.3~1533263174.bce9472 Add Wed Feb 13 11:10:38 2019
mlx-2100-05 Cumulus Linux 3.7.3~1533263174.bce9472 Add Wed Feb 13 11:10:42 2019
mlx-2700-11 Cumulus Linux 3.7.3~1533263174.bce9472 Add Wed Feb 13 11:10:51 2019
View License Information for a Switch
You can view the name and current state
of the license (whether it valid or not), and when it was last updated
for one or more devices. If a license is no longer valid on a switch, it
does not operate correctly. This example shows the license information
for all devices.
cumulus@switch:~$ netq show inventory license
Matching inventory records:
Hostname Name State Last Changed
----------------- --------------- ---------- -------------------------
edge01 Cumulus Linux N/A Fri Apr 19 16:01:18 2019
exit01 Cumulus Linux ok Fri Apr 19 16:01:13 2019
exit02 Cumulus Linux ok Fri Apr 19 16:01:38 2019
leaf01 Cumulus Linux ok Sun Apr 21 20:07:09 2019
leaf02 Cumulus Linux ok Fri Apr 19 16:01:46 2019
leaf03 Cumulus Linux ok Fri Apr 19 16:01:41 2019
leaf04 Cumulus Linux ok Fri Apr 19 16:01:32 2019
server01 Cumulus Linux N/A Fri Apr 19 16:01:55 2019
server02 Cumulus Linux N/A Fri Apr 19 16:01:55 2019
server03 Cumulus Linux N/A Fri Apr 19 16:01:55 2019
server04 Cumulus Linux N/A Fri Apr 19 16:01:55 2019
spine01 Cumulus Linux ok Fri Apr 19 16:01:49 2019
spine02 Cumulus Linux ok Fri Apr 19 16:01:05 2019
You can view the historical state of licenses using the around keyword.
This example shows the license state for all devices about 7 days ago.
Remember to use measurement units on the time values.
cumulus@switch:~$ netq show inventory license around 7d
Matching inventory records:
Hostname Name State Last Changed
----------------- --------------- ---------- -------------------------
edge01 Cumulus Linux N/A Tue Apr 2 14:01:18 2019
exit01 Cumulus Linux ok Tue Apr 2 14:01:13 2019
exit02 Cumulus Linux ok Tue Apr 2 14:01:38 2019
leaf01 Cumulus Linux ok Tue Apr 2 20:07:09 2019
leaf02 Cumulus Linux ok Tue Apr 2 14:01:46 2019
leaf03 Cumulus Linux ok Tue Apr 2 14:01:41 2019
leaf04 Cumulus Linux ok Tue Apr 2 14:01:32 2019
server01 Cumulus Linux N/A Tue Apr 2 14:01:55 2019
server02 Cumulus Linux N/A Tue Apr 2 14:01:55 2019
server03 Cumulus Linux N/A Tue Apr 2 14:01:55 2019
server04 Cumulus Linux N/A Tue Apr 2 14:01:55 2019
spine01 Cumulus Linux ok Tue Apr 2 14:01:49 2019
spine02 Cumulus Linux ok Tue Apr 2 14:01:05 2019
You can filter the results to show license changes during a particular
timeframe for a particular device. This example shows that there have
been no changes to the license state on spine01 between now and 24 hours
ago.
cumulus@switch:~$ netq spine01 show events type license between now and 24h
No matching events records found
View Summary of Operating System on a Switch
As with the hardware information, you can view a summary of the software
information using the brief keyword. Specify a hostname to view the
summary for a specific device.
When you are troubleshooting an issue with a switch, you might want to know what versions of the Cumulus Linux operating system are supported on that switch and on a switch that is not having the same issue.
This example shows the Cumulus Linux OS versions supported for the leaf01 switch, using the vx ASIC vendor (virtual, so simulated) and x86_64 CPU architecture.
If you are having an issue with a particular switch, you may want to verify what software is installed and whether it needs updating. Use the netq show cl-pkg-info command to view the current package information.
This example shows all installed software packages for spine01.
cumulus@switch:~$ netq spine01 show cl-pkg-info
Matching package_info records:
Hostname Package Name Version CL Version Package Status Last Changed
----------------- ------------------------ -------------------- -------------------- -------------------- -------------------------
spine01 adduser 3.113+nmu3 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 apt 1.0.9.8.2-cl3u3 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 arping 2.14-1 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 base-files 8+deb8u11 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 busybox 1:1.22.0-9+deb8u4 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 clag 1.3.0-cl3u23 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 cumulus-chassis 0.1-cl3u4 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 cumulus-platform 3.0-cl3u28 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 dh-python 1.20141111-2 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 dialog 1.2-20140911-1 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 discover 2.1.2-7 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 discover-data 2.2013.01.11 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 dmidecode 2.12-3 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 dnsutils 1:9.9.5.dfsg-9+deb8u Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
18
spine01 e2fslibs 1.42.12-2+b1 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 e2fsprogs 1.42.12-2+b1 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 eject 2.1.5+deb1+cvs200811 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
04-13.1+deb8u1
spine01 ethtool 1:4.6-1-cl3u7 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 gcc-4.9-base 4.9.2-10+deb8u2 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
spine01 gnupg 1.4.18-7+deb8u5 Cumulus Linux 3.7.8 installed Wed Oct 30 18:21:05 2019
...
Remove the hostname option to view the information for all switches. Use the text-package-name option to narrow the results to a particular package or the around option to narrow the output to a particular time range.
View Recommended Software Packages
You can determine whether any of your switches are using a software package other than the default package associated with the Cumulus Linux release that is running on the switches. Additionally, you can determine if a software package is missing. Use the netq show recommended-pkg-version command to display a list of recommended packages to install/upgrade on one or all devices.
This example shows that the leaf12 switch which is running Cumulus Linux 3.7.1 needs to update the switchd software.
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 switchd 1.0-cl3u30 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
cumulus@noc-pr:~$
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name ptmd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 ptmd 3.0-2-cl3u8 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name lldpd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 lldpd 0.9.8-0-cl3u11 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.6.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.6.2 vx x86_64 switchd 1.0-cl3u27 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
2:57
from the hardware switch (real)
2:57
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 switchd 1.0-cl3u30 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
cumulus@noc-pr:~$
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name ptmd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 ptmd 3.0-2-cl3u8 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.7.1 package-name lldpd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.7.1 vx x86_64 lldpd 0.9.8-0-cl3u11 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq show recommended-pkg-version release-id 3.6.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
noc-pr 3.6.2 vx x86_64 switchd 1.0-cl3u27 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
2:58
from the switch
2:58
cumulus@noc-pr:~$ netq act-5712-09 show recommended-pkg-version release-id 3.6.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
act-5712-09 3.6.2 bcm x86_64 switchd 1.0-cl3u27 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq act-5712-09 show recommended-pkg-version release-id 3.7.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
act-5712-09 3.7.2 bcm x86_64 switchd 1.0-cl3u31 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
cumulus@noc-pr:~$
3:02
very old one too
3:02
cumulus@noc-pr:~$ netq act-5712-09 show recommended-pkg-version release-id 3.6.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
act-5712-09 3.6.2 bcm x86_64 switchd 1.0-cl3u27 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$ netq act-5712-09 show recommended-pkg-version release-id 3.7.2 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
act-5712-09 3.7.2 bcm x86_64 switchd 1.0-cl3u31 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
cumulus@noc-pr:~$
3:02
cumulus@noc-pr:~$ netq act-5712-09 show recommended-pkg-version release-id 3.1.0 package-name switchd
Matching manifest records:
Hostname Release ID ASIC Vendor CPU Arch Package Name Version Last Changed
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------------
act-5712-09 3.1.0 bcm x86_64 switchd 1.0-cl3u4 Wed Feb 5 04:36:30 2020
cumulus@noc-pr:~$
View ACL Resources
You can monitor the incoming and outgoing access control lists (ACLs) configured on one or all devices, currently or at a time in the past. Use the netq show cl-resource acl command to view this information. Use the egress or ingress options to show only the outgoing or incoming ACLs. Use the around option to show this information for a time in the past.
This example shows the ACL resources by the leaf01 switch.
cumulus@switch:~$ netq leaf01 show cl-resource acl
Matching cl_resource records:
Hostname In IPv4 filter In IPv4 Mangle In IPv6 filter In IPv6 Mangle In 8021x filter In Mirror In PBR IPv4 filter In PBR IPv6 filter Eg IPv4 filter Eg IPv4 Mangle Eg IPv6 filter Eg IPv6 Mangle ACL Regions 18B Rules Key 32B Rules Key 54B Rules Key L4 Port range Checke Last Updated
rs
----------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- -------------------- ------------------------
leaf01 36,512(7%) 0,0(0%) 30,768(3%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 29,256(11%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 0,0(0%) 2,24(8%) Mon Jan 13 03:34:11 2020
You can also view this same information in JSON format.
You can monitor the amount of forwarding resources used by one or all devices, currently or at a time in the past. Use the netq show cl-resource forwarding command to view this information. Use the around option to show this information for a time in the past.
This example shows the forwarding resources used by the spine02 switch.
You can confirm that NetQ Agents are running on switches and hosts (if
installed) using the netq show agents command. Viewing the Status
column of the output indicates whether the agent is up and current,
labelled Fresh, or down and stale, labelled Rotten. Additional
information is provided about the agent status, including whether it is
time synchronized, how long it has been up, and the last time its state
changed.
This example shows NetQ Agent state on all devices.
View the state of the NetQ Agent on a given device using the
hostname keyword.
View only the NetQ Agents that are fresh or rotten using the fresh or rotten keyword.
View the state of NetQ Agents at an earlier time using the around
keyword.
Monitor Software Services
Cumulus Linux and NetQ run a number of services to deliver the various
features of these products. You can monitor their status using the netq show services command. The services related to system-level operation
are described here. Monitoring of other services, such as those related
to routing, are described with those topics. NetQ automatically monitors
the following services:
bgpd: BGP (Border Gateway Protocol) daemon
clagd: MLAG (Multi-chassis Link Aggregation) daemon
mstpd: MSTP (Multiple Spanning Tree Protocol) daemon
neighmgrd: Neighbor Manager daemon for BGP and OSPF
netq-agent: NetQ Agent service
netqd: NetQ application daemon
ntp: NTP service
ntpd: NTP daemon
ptmd: PTM (Prescriptive Topology Manager) daemon
pwmd: PWM (Password Manager)
daemon
rsyslog: Rocket-fast system event logging processing service
smond: System monitor daemon
ssh: Secure Shell service for switches and servers
status: License validation service
syslog: System event logging service
vrf: VRF (Virtual Route Forwarding) service
zebra: GNU Zebra routing daemon
The CLI syntax for viewing the status of services is:
netq [<hostname>] show services [<service-name>] [vrf <vrf>] [active|monitored] [around <text-time>] [json]
netq [<hostname>] show services [<service-name>] [vrf <vrf>] status (ok|warning|error|fail) [around <text-time>] [json]
netq [<hostname>] show events [level info | level error | level warning | level critical | level debug] type services [between <text-time> and <text-endtime>] [json]
View All Services on All Devices
This example shows all of the available services on each device and
whether each is enabled, active, and monitored, along with how long the
service has been running and the last time it was changed.
It is useful to have colored output for this show command. To configure
colored output, run the netq config add color command.
cumulus@switch:~$ netq show services
Hostname Service PID VRF Enabled Active Monitored Status Uptime Last Changed
----------------- -------------------- ----- --------------- ------- ------ --------- ---------------- ------------------------- -------------------------
leaf01 bgpd 2872 default yes yes yes ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 clagd n/a default yes no yes n/a 1d:6h:43m:35s Fri Feb 15 17:28:48 2019
leaf01 ledmgrd 1850 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 lldpd 2651 default yes yes yes ok 1d:6h:43m:27s Fri Feb 15 17:28:56 2019
leaf01 mstpd 1746 default yes yes yes ok 1d:6h:43m:35s Fri Feb 15 17:28:48 2019
leaf01 neighmgrd 1986 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 netq-agent 8654 mgmt yes yes yes ok 1d:6h:43m:29s Fri Feb 15 17:28:54 2019
leaf01 netqd 8848 mgmt yes yes yes ok 1d:6h:43m:29s Fri Feb 15 17:28:54 2019
leaf01 ntp 8478 mgmt yes yes yes ok 1d:6h:43m:29s Fri Feb 15 17:28:54 2019
leaf01 ptmd 2743 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 pwmd 1852 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 smond 1826 default yes yes yes ok 1d:6h:43m:27s Fri Feb 15 17:28:56 2019
leaf01 ssh 2106 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 syslog 8254 default yes yes no ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf01 zebra 2856 default yes yes yes ok 1d:6h:43m:59s Fri Feb 15 17:28:24 2019
leaf02 bgpd 2867 default yes yes yes ok 1d:6h:43m:55s Fri Feb 15 17:28:28 2019
leaf02 clagd n/a default yes no yes n/a 1d:6h:43m:31s Fri Feb 15 17:28:53 2019
leaf02 ledmgrd 1856 default yes yes no ok 1d:6h:43m:55s Fri Feb 15 17:28:28 2019
leaf02 lldpd 2646 default yes yes yes ok 1d:6h:43m:30s Fri Feb 15 17:28:53 2019
...
You can also view services information in JSON format:
If you want to view the service information for a given device, simply
use the hostname option when running the command.
View Information about a Given Service on All Devices
You can view the status of a given service at the current time, at a
prior point in time, or view the changes that have occurred for the
service during a specified timeframe.
This example shows how to view the status of the NTP service across the
network. In this case, VRF is configured so the NTP service runs on both
the default and management interface. You can perform the same command
with the other services, such as bgpd, lldpd, and clagd.
cumulus@switch:~$ netq show services ntp
Matching services records:
Hostname Service PID VRF Enabled Active Monitored Status Uptime Last Changed
----------------- -------------------- ----- --------------- ------- ------ --------- ---------------- ------------------------- -------------------------
exit01 ntp 8478 mgmt yes yes yes ok 1d:6h:52m:41s Fri Feb 15 17:28:54 2019
exit02 ntp 8497 mgmt yes yes yes ok 1d:6h:52m:36s Fri Feb 15 17:28:59 2019
firewall01 ntp n/a default yes yes yes ok 1d:6h:53m:4s Fri Feb 15 17:28:31 2019
hostd-11 ntp n/a default yes yes yes ok 1d:6h:52m:46s Fri Feb 15 17:28:49 2019
hostd-21 ntp n/a default yes yes yes ok 1d:6h:52m:37s Fri Feb 15 17:28:58 2019
hosts-11 ntp n/a default yes yes yes ok 1d:6h:52m:28s Fri Feb 15 17:29:07 2019
hosts-13 ntp n/a default yes yes yes ok 1d:6h:52m:19s Fri Feb 15 17:29:16 2019
hosts-21 ntp n/a default yes yes yes ok 1d:6h:52m:14s Fri Feb 15 17:29:21 2019
hosts-23 ntp n/a default yes yes yes ok 1d:6h:52m:4s Fri Feb 15 17:29:31 2019
noc-pr ntp 2148 default yes yes yes ok 1d:6h:53m:43s Fri Feb 15 17:27:52 2019
noc-se ntp 2148 default yes yes yes ok 1d:6h:53m:38s Fri Feb 15 17:27:57 2019
spine01 ntp 8414 mgmt yes yes yes ok 1d:6h:53m:30s Fri Feb 15 17:28:05 2019
spine02 ntp 8419 mgmt yes yes yes ok 1d:6h:53m:27s Fri Feb 15 17:28:08 2019
spine03 ntp 8443 mgmt yes yes yes ok 1d:6h:53m:22s Fri Feb 15 17:28:13 2019
leaf01 ntp 8765 mgmt yes yes yes ok 1d:6h:52m:52s Fri Feb 15 17:28:43 2019
leaf02 ntp 8737 mgmt yes yes yes ok 1d:6h:52m:46s Fri Feb 15 17:28:49 2019
leaf11 ntp 9305 mgmt yes yes yes ok 1d:6h:49m:22s Fri Feb 15 17:32:13 2019
leaf12 ntp 9339 mgmt yes yes yes ok 1d:6h:49m:9s Fri Feb 15 17:32:26 2019
leaf21 ntp 9367 mgmt yes yes yes ok 1d:6h:49m:5s Fri Feb 15 17:32:30 2019
leaf22 ntp 9403 mgmt yes yes yes ok 1d:6h:52m:57s Fri Feb 15 17:28:38 2019
This example shows the status of the BGP daemon.
cumulus@switch:~$ netq show services bgpd
Matching services records:
Hostname Service PID VRF Enabled Active Monitored Status Uptime Last Changed
----------------- -------------------- ----- --------------- ------- ------ --------- ---------------- ------------------------- -------------------------
exit01 bgpd 2872 default yes yes yes ok 1d:6h:54m:37s Fri Feb 15 17:28:24 2019
exit02 bgpd 2867 default yes yes yes ok 1d:6h:54m:33s Fri Feb 15 17:28:28 2019
firewall01 bgpd 21766 default yes yes yes ok 1d:6h:54m:54s Fri Feb 15 17:28:07 2019
spine01 bgpd 2953 default yes yes yes ok 1d:6h:55m:27s Fri Feb 15 17:27:34 2019
spine02 bgpd 2948 default yes yes yes ok 1d:6h:55m:23s Fri Feb 15 17:27:38 2019
spine03 bgpd 2953 default yes yes yes ok 1d:6h:55m:18s Fri Feb 15 17:27:43 2019
leaf01 bgpd 3221 default yes yes yes ok 1d:6h:54m:48s Fri Feb 15 17:28:13 2019
leaf02 bgpd 3177 default yes yes yes ok 1d:6h:54m:42s Fri Feb 15 17:28:19 2019
leaf11 bgpd 3521 default yes yes yes ok 1d:6h:51m:18s Fri Feb 15 17:31:43 2019
leaf12 bgpd 3527 default yes yes yes ok 1d:6h:51m:6s Fri Feb 15 17:31:55 2019
leaf21 bgpd 3512 default yes yes yes ok 1d:6h:51m:1s Fri Feb 15 17:32:00 2019
leaf22 bgpd 3536 default yes yes yes ok 1d:6h:54m:54s Fri Feb 15 17:28:07 2019
View Events Related to a Given Service
To view changes over a given time period, use the netq show events
command. For more detailed information about events, refer to Monitor Events.
In this example, we want to view changes to the bgpd service in the last
48 hours.
cumulus@switch:/$ netq show events type bgp between now and 48h
Matching events records:
Hostname Message Type Severity Message Timestamp
----------------- ------------ -------- ----------------------------------- -------------------------
leaf01 bgp info BGP session with peer spine-1 swp3. 1d:6h:55m:37s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-2 swp4. 1d:6h:55m:37s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-3 swp5. 1d:6h:55m:37s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-1 swp3. 1d:6h:55m:37s
2 vrf DataVrf1080 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-3 swp5. 1d:6h:55m:37s
2 vrf DataVrf1080 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-2 swp4. 1d:6h:55m:37s
2 vrf DataVrf1080 state changed fro
m failed to Established
leaf01 bgp info BGP session with peer spine-3 swp5. 1d:6h:55m:37s
4 vrf DataVrf1082 state changed fro
m failed to Established
Monitor Physical Layer Components
With NetQ, a network administrator can monitor OSI Layer 1 physical
components on network devices, including interfaces, ports, links, and
peers. NetQ provides the ability to:
Manage physical inventory: view the performance and status of various components of a switch or host server
Validate configurations: verify the configuration of network peers and ports
It helps answer questions such as:
Are any individual or bonded links down?
Are any links flapping?
Is there a link mismatch anywhere in my network?
Which interface ports are empty?
Which transceivers are installed?
What is the peer for a given port?
NetQ uses LLDP (Link Layer Discovery Protocol) to collect port information. NetQ can also identify peer ports connected to DACs (Direct Attached Cables) and AOCs (Active Optical Cables) without using LLDP, even if the link is not UP.
Monitor Physical Layer Inventory
Keeping track of the various physical layer components in your switches
and servers ensures you have a fully functioning network and provides
inventory management and audit capabilities. You can monitor ports,
transceivers, and cabling deployed on a per port (interface), per
vendor, per part number and so forth. NetQ enables you to view the
current status and the status an earlier point in time. From this
information, you can, among other things:
determine which ports are empty versus which ones have cables
plugged in and thereby validate expected connectivity
audit transceiver and cable components used by vendor, giving you
insights for estimated replacement costs, repair costs, overall
costs, and so forth to improve your maintenance and purchasing
processes
identify changes in your physical layer, and when they occurred
The netq show interfaces physical command is used to obtain the
information from the devices. Its syntax is:
netq [<hostname>] show interfaces physical [<physical-port>] [empty|plugged] [peer] [vendor <module-vendor>|model <module-model>|module] [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type interfaces-physical [between <text-time> and <text-endtime>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View Detailed Cable Information for All Devices
You can view what cables are connected to each interface port for all
devices, including the module type, vendor, part number and performance
characteristics. You can also view the cable information for a given
device by adding a hostname to the show command. This example shows
cable information and status for all interface ports on all devices.
cumulus@switch:~$ netq show interfaces physical
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
edge01 eth0 up 1G on RJ45 n/a n/a Fri Jun 7 00:42:52 2019
edge01 eth1 down 1G off RJ45 n/a n/a Fri Jun 7 00:42:52 2019
edge01 eth2 down 1G off RJ45 n/a n/a Fri Jun 7 00:42:52 2019
edge01 vagrant down 1G on RJ45 n/a n/a Fri Jun 7 00:42:52 2019
exit01 eth0 up 1G off RJ45 n/a n/a Fri Jun 7 00:42:52 2019
exit01 swp1 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp44 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit01 swp45 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp46 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp47 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp48 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp49 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit01 swp50 down Unknown off RJ45 n/a n/a Fri Jun 7 00:42:53 2019
exit01 swp51 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit01 swp52 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit01 vagrant down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:03 2019
exit02 eth0 up 1G off RJ45 n/a n/a Fri Jun 7 00:42:51 2019
exit02 swp1 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp44 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit02 swp45 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp46 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp47 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp48 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp49 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp50 down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
exit02 swp51 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit02 swp52 up 1G off RJ45 n/a n/a Fri Jun 7 00:51:28 2019
exit02 vagrant down Unknown off RJ45 n/a n/a Fri Jun 7 00:43:01 2019
leaf01 eth0 up 1G off RJ45 n/a n/a Fri Jun 7 00:43:02 2019
leaf01 swp1 up 1G off RJ45 n/a n/a Fri Jun 7 00:52:03 2019
leaf01 swp2 up 1G off RJ45 n/a n/a Fri Jun 7 00:52:03 2019
...
View Detailed Module Information for a Given Device
You can view detailed information about the transceiver modules on each
interface port, including serial number, transceiver type, connector and
attached cable length. You can also view the module information for a
given device by adding a hostname to the show command. This example
shows the detailed module information for the interface ports on leaf02
switch.
cumulus@switch:~$ netq leaf02 show interfaces physical module
Matching cables records are:
Hostname Interface Module Vendor Part No Serial No Transceiver Connector Length Last Changed
----------------- ------------------------- --------- -------------------- ---------------- ------------------------- ---------------- ---------------- ------ -------------------------
leaf02 swp1 RJ45 n/a n/a n/a n/a n/a n/a Thu Feb 7 22:49:37 2019
leaf02 swp2 SFP Mellanox MC2609130-003 MT1507VS05177 1000Base-CX,Copp Copper pigtail 3m Thu Feb 7 22:49:37 2019
er Passive,Twin
Axial Pair (TW)
leaf02 swp47 QSFP+ CISCO AFBR-7IER05Z-CS1 AVE1823402U n/a n/a 5m Thu Feb 7 22:49:37 2019
leaf02 swp48 QSFP28 TE Connectivity 2231368-1 15250052 100G Base-CR4 or n/a 3m Thu Feb 7 22:49:37 2019
25G Base-CR CA-L
,40G Base-CR4
leaf02 swp49 SFP OEM SFP-10GB-LR ACSLR130408 10G Base-LR LC 10km, Thu Feb 7 22:49:37 2019
10000m
leaf02 swp50 SFP JDSU PLRXPLSCS4322N CG03UF45M 10G Base-SR,Mult LC 80m, Thu Feb 7 22:49:37 2019
imode, 30m,
50um (M5),Multim 300m
ode,
62.5um (M6),Shor
twave laser w/o
OFC (SN),interme
diate distance (
I)
leaf02 swp51 SFP Mellanox MC2609130-003 MT1507VS05177 1000Base-CX,Copp Copper pigtail 3m Thu Feb 7 22:49:37 2019
er Passive,Twin
Axial Pair (TW)
leaf02 swp52 SFP FINISAR CORP. FCLF8522P2BTL PTN1VH2 1000Base-T RJ45 100m Thu Feb 7 22:49:37 2019
View Ports without Cables Connected for a Given Device
Checking for empty ports enables you to compare expected versus actual
deployment. This can be very helpful during deployment or during
upgrades. You can also view the cable information for a given device by
adding a hostname to the show command. This example shows the ports
that are empty on leaf01 switch.
cumulus@switch:~$ netq leaf01 show interfaces physical empty
Matching cables records are:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
---------------- --------- ----- ---------- ------- --------- ---------------- ---------------- ------------------------
leaf01 swp49 down Unknown on empty n/a n/a Thu Feb 7 22:49:37 2019
leaf01 swp52 down Unknown on empty n/a n/a Thu Feb 7 22:49:37 2019
View Ports with Cables Connected for a Given Device
In a similar manner as checking for empty ports, you can check for ports
that have cables connected, enabling you to compare expected versus
actual deployment. You can also view the cable information for a given
device by adding a hostname to the show command. If you add the around
keyword, you can view which interface ports had cables connected at a
previous time. This example shows the ports of leaf01 switch that have
attached cables.
cumulus@switch:~$ netq leaf01 show interfaces physical plugged
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
leaf01 eth0 up 1G on RJ45 n/a n/a Thu Feb 7 22:49:37 2019
leaf01 swp1 up 10G off SFP Amphenol 610640005 Thu Feb 7 22:49:37 2019
leaf01 swp2 up 10G off SFP Amphenol 610640005 Thu Feb 7 22:49:37 2019
leaf01 swp3 down 10G off SFP Mellanox MC3309130-001 Thu Feb 7 22:49:37 2019
leaf01 swp33 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp34 down 10G off SFP Amphenol 571540007 Thu Feb 7 22:49:37 2019
leaf01 swp35 down 10G off SFP Amphenol 571540007 Thu Feb 7 22:49:37 2019
leaf01 swp36 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp37 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp38 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp39 down 10G off SFP Amphenol 571540007 Thu Feb 7 22:49:37 2019
leaf01 swp40 down 10G off SFP Amphenol 571540007 Thu Feb 7 22:49:37 2019
leaf01 swp49 up 40G off QSFP+ Amphenol 624410001 Thu Feb 7 22:49:37 2019
leaf01 swp5 down 10G off SFP Amphenol 571540007 Thu Feb 7 22:49:37 2019
leaf01 swp50 down 40G off QSFP+ Amphenol 624410001 Thu Feb 7 22:49:37 2019
leaf01 swp51 down 40G off QSFP+ Amphenol 603020003 Thu Feb 7 22:49:37 2019
leaf01 swp52 up 40G off QSFP+ Amphenol 603020003 Thu Feb 7 22:49:37 2019
leaf01 swp54 down 40G off QSFP+ Amphenol 624410002 Thu Feb 7 22:49:37 2019
View Components from a Given Vendor
By filtering for a specific cable vendor, you can collect information
such as how many ports use components from that vendor and when they
were last updated. This information may be useful when you run a cost
analysis of your network. This example shows all the ports that are
using components by an OEM vendor.
cumulus@switch:~$ netq leaf01 show interfaces physical vendor OEM
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
leaf01 swp33 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp36 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp37 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
leaf01 swp38 down 10G off SFP OEM SFP-H10GB-CU1M Thu Feb 7 22:49:37 2019
View All Devices Using a Given Component
You can view all of the devices with ports using a particular component.
This could be helpful when you need to change out a particular component
for possible failure issues, upgrades, or cost reasons. This example
first determines which models (part numbers) exist on all of the devices
and then those devices with a part number of QSFP-H40G-CU1M installed.
cumulus@switch:~$ netq show interfaces physical model
2231368-1 : 2231368-1
624400001 : 624400001
QSFP-H40G-CU1M : QSFP-H40G-CU1M
QSFP-H40G-CU1MUS : QSFP-H40G-CU1MUS
n/a : n/a
cumulus@switch:~$ netq show interfaces physical model QSFP-H40G-CU1M
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
leaf01 swp50 up 1G off QSFP+ OEM QSFP-H40G-CU1M Thu Feb 7 18:31:20 2019
leaf02 swp52 up 1G off QSFP+ OEM QSFP-H40G-CU1M Thu Feb 7 18:31:20 2019
View Changes to Physical Components
Because components are often changed, NetQ enables you to determine
what, if any, changes have been made to the physical components on your
devices. This can be helpful during deployments or upgrades.
You can select how far back in time you want to go, or select a time
range using the between keyword. Note that time values must include
units to be valid. If no changes are found, a “No matching cable records
found” message is displayed. This example illustrates each of these
scenarios for all devices in the network.
cumulus@switch:~$ netq show events type interfaces-physical between now and 30d
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
leaf01 swp1 up 1G off SFP AVAGO AFBR-5715PZ-JU1 Thu Feb 7 18:34:20 2019
leaf01 swp2 up 10G off SFP OEM SFP-10GB-LR Thu Feb 7 18:34:20 2019
leaf01 swp47 up 10G off SFP JDSU PLRXPLSCS4322N Thu Feb 7 18:34:20 2019
leaf01 swp48 up 40G off QSFP+ Mellanox MC2210130-002 Thu Feb 7 18:34:20 2019
leaf01 swp49 down 10G off empty n/a n/a Thu Feb 7 18:34:20 2019
leaf01 swp50 up 1G off SFP FINISAR CORP. FCLF8522P2BTL Thu Feb 7 18:34:20 2019
leaf01 swp51 up 1G off SFP FINISAR CORP. FTLF1318P3BTL Thu Feb 7 18:34:20 2019
leaf01 swp52 down 1G off SFP CISCO-AGILENT QFBR-5766LP Thu Feb 7 18:34:20 2019
leaf02 swp1 up 1G on RJ45 n/a n/a Thu Feb 7 18:34:20 2019
leaf02 swp2 up 10G off SFP Mellanox MC2609130-003 Thu Feb 7 18:34:20 2019
leaf02 swp47 up 10G off QSFP+ CISCO AFBR-7IER05Z-CS1 Thu Feb 7 18:34:20 2019
leaf02 swp48 up 10G off QSFP+ Mellanox MC2609130-003 Thu Feb 7 18:34:20 2019
leaf02 swp49 up 10G off SFP FIBERSTORE SFP-10GLR-31 Thu Feb 7 18:34:20 2019
leaf02 swp50 up 1G off SFP OEM SFP-GLC-T Thu Feb 7 18:34:20 2019
leaf02 swp51 up 10G off SFP Mellanox MC2609130-003 Thu Feb 7 18:34:20 2019
leaf02 swp52 up 1G off SFP FINISAR CORP. FCLF8522P2BTL Thu Feb 7 18:34:20 2019
leaf03 swp1 up 10G off SFP Mellanox MC2609130-003 Thu Feb 7 18:34:20 2019
leaf03 swp2 up 10G off SFP Mellanox MC3309130-001 Thu Feb 7 18:34:20 2019
leaf03 swp47 up 10G off SFP CISCO-AVAGO AFBR-7IER05Z-CS1 Thu Feb 7 18:34:20 2019
leaf03 swp48 up 10G off SFP Mellanox MC3309130-001 Thu Feb 7 18:34:20 2019
leaf03 swp49 down 1G off SFP FINISAR CORP. FCLF8520P2BTL Thu Feb 7 18:34:20 2019
leaf03 swp50 up 1G off SFP FINISAR CORP. FCLF8522P2BTL Thu Feb 7 18:34:20 2019
leaf03 swp51 up 10G off QSFP+ Mellanox MC2609130-003 Thu Feb 7 18:34:20 2019
...
oob-mgmt-server swp1 up 1G off RJ45 n/a n/a Thu Feb 7 18:34:20 2019
oob-mgmt-server swp2 up 1G off RJ45 n/a n/a Thu Feb 7 18:34:20 2019
cumulus@switch:~$ netq show events interfaces-physical between 6d and 16d
Matching cables records:
Hostname Interface State Speed AutoNeg Module Vendor Part No Last Changed
----------------- ------------------------- ---------- ---------- ------- --------- -------------------- ---------------- -------------------------
leaf01 swp1 up 1G off SFP AVAGO AFBR-5715PZ-JU1 Thu Feb 7 18:34:20 2019
leaf01 swp2 up 10G off SFP OEM SFP-10GB-LR Thu Feb 7 18:34:20 2019
leaf01 swp47 up 10G off SFP JDSU PLRXPLSCS4322N Thu Feb 7 18:34:20 2019
leaf01 swp48 up 40G off QSFP+ Mellanox MC2210130-002 Thu Feb 7 18:34:20 2019
leaf01 swp49 down 10G off empty n/a n/a Thu Feb 7 18:34:20 2019
leaf01 swp50 up 1G off SFP FINISAR CORP. FCLF8522P2BTL Thu Feb 7 18:34:20 2019
leaf01 swp51 up 1G off SFP FINISAR CORP. FTLF1318P3BTL Thu Feb 7 18:34:20 2019
leaf01 swp52 down 1G off SFP CISCO-AGILENT QFBR-5766LP Thu Feb 7 18:34:20 2019
...
cumulus@switch:~$ netq show events type interfaces-physical between 0s and 5h
No matching cables records found
View Interface Statistics
The ethtool command provides a wealth of statistics about network interfaces. The netq show ethtool-stats command returns statistics about a given node and interface, including frame errors, ACL drops, buffer drops and more.
You can use the around option to view the information for a particular time. If no changes are found, a “No matching ethtool_stats records found” message is displayed. This example illustrates the statistics for switch port swp1 on a specific switch in the network.
Beyond knowing what physical components are deployed, it is valuable to
know that they are configured and operating correctly. NetQ enables you
to confirm that peer connections are present, discover any misconfigured
ports, peers, or unsupported modules, and monitor for link flaps.
NetQ checks peer connections using LLDP. For DACs and AOCs, NetQ
determines the peers using their serial numbers in the port EEPROMs,
even if the link is not UP.
Confirm Peer Connections
You can validate peer connections for all devices in your network or for
a specific device or port. This example shows the peer hosts and their
status for leaf03 switch.
cumulus@switch:~$ netq leaf03 show interfaces physical peer
Matching cables records:
Hostname Interface Peer Hostname Peer Interface State Message
----------------- ------------------------- ----------------- ------------------------- ---------- -----------------------------------
leaf03 swp1 oob-mgmt-switch swp7 up
leaf03 swp2 down Peer port unknown
leaf03 swp47 leaf04 swp47 up
leaf03 swp48 leaf04 swp48 up
leaf03 swp49 leaf04 swp49 up
leaf03 swp50 leaf04 swp50 up
leaf03 swp51 exit01 swp51 up
leaf03 swp52 down Port cage empty
This example shows the peer data for a specific interface port.
cumulus@switch:~$ netq leaf01 show interfaces physical swp47
Matching cables records:
Hostname Interface Peer Hostname Peer Interface State Message
----------------- ------------------------- ----------------- ------------------------- ---------- -----------------------------------
leaf01 swp47 leaf02 swp47 up
Discover Misconfigurations
You can verify that the following configurations are the same on both
sides of a peer interface:
Admin state
Operational state
Link speed
Auto-negotiation setting
The netq check interfaces command is used to determine if any of the
interfaces have any continuity errors. This command only checks the
physical interfaces; it does not check bridges, bonds or other software
constructs. You can check all interfaces at once. It enables you to
compare the current status of the interfaces, as well as their status at
an earlier point in time. The command syntax is:
netq check interfaces [around <text-time>] [json]
If NetQ cannot determine a peer for a given device, the port is marked
as unverified.
If you find a misconfiguration, use the netq show interfaces physical
command for clues about the cause.
Example: Find Mismatched Operational States
In this example, we check all of the interfaces for misconfigurations
and we find that one interface port has an error. We look for clues
about the cause and see that the Operational states do not match on the
connection between leaf 03 and leaf04: leaf03 is up, but leaf04 is down.
If the misconfiguration was due to a mismatch in the administrative
state, the message would have been Admin state mismatch (up, down) or
Admin state mismatch (down, up).
This example uses the and keyword to check the connections between two
peers. An error is seen, so we check the physical peer information and
discover that the incorrect peer has been specified. After fixing it, we
run the check again, and see that there are no longer any interface
errors.
This example checks for for configuration mismatches and finds a link
speed mismatch on server03. The link speed on swp49 is 40G and the
peer port swp50 is unspecified.
This example checks for configuration mismatches and finds
auto-negotation setting mismatches between the servers and leafs.
Auto-negotiation is off on the leafs, but on on the servers.
You can also determine whether a link is flapping using the netq check interfaces command. If a link is flapping, NetQ indicates this in a
message:
cumulus@switch:~$ netq check interfaces
Checked Nodes: 18, Failed Nodes: 8
Checked Ports: 741, Failed Ports: 1, Unverified Ports: 414
Matching cables records:
Hostname Interface Peer Hostname Peer Interface Message
----------------- ------------------------- ----------------- ------------------------- -----------------------------------
leaf02 - - - Link flapped 11 times in last 5
mins
Monitor Data Link Layer Devices and Protocols
With NetQ, a network administrator can monitor OSI Layer 2 devices and
protocols, including switches, bridges, link control, and physical media
access. Keeping track of the various data link layer devices in your
network ensures consistent and error-free communications between
devices. NetQ provides the ability to:
Monitor and validate device and protocol configurations
View available communication paths between devices
It helps answer questions such as:
Is a VLAN misconfigured?
Is there an MTU mismatch in my network?
Is MLAG configured correctly?
Is there an STP loop?
Can device A reach device B using MAC addresses?
Monitor LLDP Operation
LLDP is used by network devices for
advertising their identity, capabilities, and neighbors on a LAN. You
can view this information for one or more devices. You can also view the
information at an earlier point in time or view changes that have
occurred to the information during a specified timeframe. NetQ enables
you to view LLDP information for your devices using the netq show lldp
command. The syntax for this command is:
netq [<hostname>] show lldp [<remote-physical-interface>] [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type lldp [between <text-time> and <text-endtime>] [json]
View LLDP Information for All Devices
This example shows the interface and peer information that is advertised for each device.
cumulus@switch:~$ netq show lldp
Matching lldp records:
Hostname Interface Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ----------------- ------------------------- -------------------------
exit01 swp1 edge01 swp5 Thu Feb 7 18:31:53 2019
exit01 swp2 edge02 swp5 Thu Feb 7 18:31:53 2019
exit01 swp3 spine01 swp9 Thu Feb 7 18:31:53 2019
exit01 swp4 spine02 swp9 Thu Feb 7 18:31:53 2019
exit01 swp5 spine03 swp9 Thu Feb 7 18:31:53 2019
exit01 swp6 firewall01 mac:00:02:00:00:00:11 Thu Feb 7 18:31:53 2019
exit01 swp7 firewall02 swp3 Thu Feb 7 18:31:53 2019
exit02 swp1 edge01 swp6 Thu Feb 7 18:31:49 2019
exit02 swp2 edge02 swp6 Thu Feb 7 18:31:49 2019
exit02 swp3 spine01 swp10 Thu Feb 7 18:31:49 2019
exit02 swp4 spine02 swp10 Thu Feb 7 18:31:49 2019
exit02 swp5 spine03 swp10 Thu Feb 7 18:31:49 2019
exit02 swp6 firewall01 mac:00:02:00:00:00:12 Thu Feb 7 18:31:49 2019
exit02 swp7 firewall02 swp4 Thu Feb 7 18:31:49 2019
firewall01 swp1 edge01 swp14 Thu Feb 7 18:31:26 2019
firewall01 swp2 edge02 swp14 Thu Feb 7 18:31:26 2019
firewall01 swp3 exit01 swp6 Thu Feb 7 18:31:26 2019
firewall01 swp4 exit02 swp6 Thu Feb 7 18:31:26 2019
firewall02 swp1 edge01 swp15 Thu Feb 7 18:31:31 2019
firewall02 swp2 edge02 swp15 Thu Feb 7 18:31:31 2019
firewall02 swp3 exit01 swp7 Thu Feb 7 18:31:31 2019
firewall02 swp4 exit02 swp7 Thu Feb 7 18:31:31 2019
server11 swp1 leaf01 swp7 Thu Feb 7 18:31:43 2019
server11 swp2 leaf02 swp7 Thu Feb 7 18:31:43 2019
server11 swp3 edge01 swp16 Thu Feb 7 18:31:43 2019
server11 swp4 edge02 swp16 Thu Feb 7 18:31:43 2019
server12 swp1 leaf01 swp8 Thu Feb 7 18:31:47 2019
server12 swp2 leaf02 swp8 Thu Feb 7 18:31:47 2019
Monitor Interface Health
Interface (link) health can be monitored using the netq show interfaces command. You can view status of the links, whether they are
operating over a VRF interface, the MTU of the link, and so forth. Using
the hostname option enables you to view only the interfaces for a
given device. View changes to interfaces using the netq show events
command.
Viewing the status of all interfaces at once can be helpful when you are
trying to compare configuration or status of a set of links, or
generally when changes have been made.
This example shows all interfaces network-wide.
cumulus@switch:~$ netq show interfaces
Matching link records:
Hostname Interface Type State VRF Details Last Changed
----------------- ------------------------- ---------------- ---------- --------------- ----------------------------------- -------------------------
exit01 bridge bridge up default , Root bridge: exit01, Mon Apr 29 20:57:59 2019
Root port: , Members: vxlan4001,
bridge,
exit01 eth0 eth up mgmt MTU: 1500 Mon Apr 29 20:57:59 2019
exit01 lo loopback up default MTU: 65536 Mon Apr 29 20:57:58 2019
exit01 mgmt vrf up table: 1001, MTU: 65536, Mon Apr 29 20:57:58 2019
Members: mgmt, eth0,
exit01 swp1 swp down default VLANs: , PVID: 0 MTU: 1500 Mon Apr 29 20:57:59 2019
exit01 swp44 swp up vrf1 VLANs: , Mon Apr 29 20:57:58 2019
PVID: 0 MTU: 1500 LLDP: internet:sw
p1
exit01 swp45 swp down default VLANs: , PVID: 0 MTU: 1500 Mon Apr 29 20:57:59 2019
exit01 swp46 swp down default VLANs: , PVID: 0 MTU: 1500 Mon Apr 29 20:57:59 2019
exit01 swp47 swp down default VLANs: , PVID: 0 MTU: 1500 Mon Apr 29 20:57:59 2019
...
leaf01 bond01 bond up default Slave:swp1 LLDP: server01:eth1 Mon Apr 29 20:57:59 2019
leaf01 bond02 bond up default Slave:swp2 LLDP: server02:eth1 Mon Apr 29 20:57:59 2019
leaf01 bridge bridge up default , Root bridge: leaf01, Mon Apr 29 20:57:59 2019
Root port: , Members: vxlan4001,
bond02, vni24, vni13, bond01,
bridge, peerlink,
leaf01 eth0 eth up mgmt MTU: 1500 Mon Apr 29 20:58:00 2019
leaf01 lo loopback up default MTU: 65536 Mon Apr 29 20:57:59 2019
leaf01 mgmt vrf up table: 1001, MTU: 65536, Mon Apr 29 20:57:59 2019
Members: mgmt, eth0,
leaf01 peerlink bond up default Slave:swp50 LLDP: leaf02:swp49 LLDP Mon Apr 29 20:58:00 2019
: leaf02:swp50
...
View Interface Status for a Given Device
If you are interested in only a the interfaces on a specific device, you
can view only those.
This example shows all interfaces on the spine01 device.
It can be can be useful to see the status of a particular type of
interface.
This example shows all bond interfaces that are down, and then those
that are up.
cumulus@switch:~$ netq show interfaces type bond state down
No matching link records found
cumulus@switch:~$ netq show interfaces type bond state up
Matching link records:
Hostname Interface Type State VRF Details Last Changed
----------------- ------------------------- ---------------- ---------- --------------- ----------------------------------- -------------------------
leaf01 bond01 bond up default Slave:swp1 LLDP: server01:eth1 Mon Apr 29 21:19:07 2019
leaf01 bond02 bond up default Slave:swp2 LLDP: server02:eth1 Mon Apr 29 21:19:07 2019
leaf01 peerlink bond up default Slave:swp50 LLDP: leaf02:swp49 LLDP Mon Apr 29 21:19:07 2019
: leaf02:swp50
leaf02 bond01 bond up default Slave:swp1 LLDP: server01:eth2 Mon Apr 29 21:19:07 2019
leaf02 bond02 bond up default Slave:swp2 LLDP: server02:eth2 Mon Apr 29 21:19:07 2019
leaf02 peerlink bond up default Slave:swp50 LLDP: leaf01:swp49 LLDP Mon Apr 29 21:19:07 2019
: leaf01:swp50
leaf03 bond03 bond up default Slave:swp1 LLDP: server03:eth1 Mon Apr 29 21:19:07 2019
leaf03 bond04 bond up default Slave:swp2 LLDP: server04:eth1 Mon Apr 29 21:19:07 2019
leaf03 peerlink bond up default Slave:swp50 LLDP: leaf04:swp49 LLDP Mon Apr 29 21:19:07 2019
: leaf04:swp50
leaf04 bond03 bond up default Slave:swp1 LLDP: server03:eth2 Mon Apr 29 21:19:07 2019
leaf04 bond04 bond up default Slave:swp2 LLDP: server04:eth2 Mon Apr 29 21:19:07 2019
leaf04 peerlink bond up default Slave:swp50 LLDP: leaf03:swp49 LLDP Mon Apr 29 21:19:07 2019
: leaf03:swp50
server01 bond0 bond up default Slave:bond0 LLDP: leaf02:swp1 Mon Apr 29 21:19:07 2019
server02 bond0 bond up default Slave:bond0 LLDP: leaf02:swp2 Mon Apr 29 21:19:07 2019
server03 bond0 bond up default Slave:bond0 LLDP: leaf04:swp1 Mon Apr 29 21:19:07 2019
server04 bond0 bond up default Slave:bond0 LLDP: leaf04:swp2 Mon Apr 29 21:19:07 2019
View the Total Number of Interfaces
For a quick view of the amount of interfaces currently operating on a
device, use the hostname and count options together.
This example shows the count of interfaces on the leaf03 switch.
cumulus@switch:~$ netq leaf03 show interfaces count
Count of matching link records: 28
View the Total Number of a Given Interface Type
It can be useful to see how many interfaces of a particular type you
have on a device.
This example shows the count of swp interfaces are on the leaf03
switch.
cumulus@switch:~$ netq leaf03 show interfaces type swp count
Count of matching link records: 11
View Changes to Interfaces
If you suspect that an interface is not working as expected, seeing a
drop in performance or a large number of dropped messages for example,
you can view changes that have been made to interfaces network-wide.
This example shows info level events for all interfaces in your network:
cumulus@switch:~$ netq show events level info type interfaces between now and 30d
Matching events records:
Hostname Message Type Severity Message Timestamp
----------------- ------------------------ ---------------- ----------------------------------- -------------------------
server03 link info HostName server03 changed state fro 3d:12h:8m:28s
m down to up Interface:eth2
server03 link info HostName server03 changed state fro 3d:12h:8m:28s
m down to up Interface:eth1
server01 link info HostName server01 changed state fro 3d:12h:8m:30s
m down to up Interface:eth2
server01 link info HostName server01 changed state fro 3d:12h:8m:30s
m down to up Interface:eth1
server02 link info HostName server02 changed state fro 3d:12h:8m:34s
m down to up Interface:eth2
...
Check for MTU Inconsistencies
The maximum transmission unit (MTU) determines the largest size packet
or frame that can be transmitted across a given communication link. When
the MTU is not configured to the same value on both ends of the link,
communication problems can occur. With NetQ, you can verify that the MTU
is correctly specified for each link using the netq check mtu command.
This example shows that four switches have inconsistently specified link
MTUs. Now the network administrator or operator can reconfigure the
switches and eliminate the communication issues associated with this
misconfiguration.
cumulus@switch:~$ netq check mtu
Checked Nodes: 15, Checked Links: 215, Failed Nodes: 4, Failed Links: 7
MTU mismatch found on following links
Hostname Interface MTU Peer Peer Interface Peer MTU Error
----------------- ------------------------- ------ ----------------- ------------------------- -------- ---------------
spine01 swp30 9216 exit01 swp51 1500 MTU Mismatch
exit01 swp51 1500 spine01 swp30 9216 MTU Mismatch
spine01 swp29 9216 exit02 swp51 1500 MTU Mismatch
exit02 - - - - - Rotten Agent
exit01 swp52 1500 spine02 swp30 9216 MTU Mismatch
spine02 swp30 9216 exit01 swp52 1500 MTU Mismatch
spine02 swp29 9216 exit02 swp52 1500 MTU Mismatch
Monitor VLAN Configurations
A VLAN (Virtual Local Area
Network) enables devices on one or more LANs to communicate as if they
were on the same network, without being physically connected. The VLAN
enables network administrators to
partition a network for functional or security requirements without
changing physical infrastructure. With NetQ, you can view the operation
of VLANs for one or all devices. You can also view the information at an
earlier point in time or view changes that have occurred to the
information during a specified timeframe. NetQ enables you to view basic
VLAN information for your devices using the netq show vlan command.
Additional show commands enable you to view VLAN information associated
with interfaces and MAC addresses. The syntax for these commands is:
netq [<hostname>] show interfaces [type vlan] [state <remote-interface-state>] [around <text-time>] [json]
netq <hostname> show interfaces [type vlan] [state <remote-interface-state>] [around <text-time>] [count] [json]
netq [<hostname>] show events [level info | level error | level warning | level critical | level debug] type vlan [between <text-time> and <text-endtime>] [json]
netq show macs [<mac>] [vlan <1-4096>] [origin] [around <text-time>] [json]
netq <hostname> show macs [<mac>] [vlan <1-4096>] [origin | count] [around <text-time>] [json]
netq <hostname> show macs egress-port <egress-port> [<mac>] [vlan <1-4096>] [origin] [around <text-time>] [json]
netq [<hostname>] show vlan [<1-4096>] [around <text-time>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View VLAN Information for All Devices
This example shows the VLANs configured across your network.
cumulus@switch:~$ netq show vlan
Matching vlan records:
Hostname VLANs SVIs Last Changed
----------------- ------------------------- ------------------------- -------------------------
exit01 4001 4001 Thu Feb 7 18:31:38 2019
exit02 4001 4001 Thu Feb 7 18:31:38 2019
leaf01 1,13,24,4001 13 24 4001 Thu Feb 7 18:31:38 2019
leaf02 1,13,24,4001 13 24 4001 Thu Feb 7 18:31:38 2019
leaf03 1,13,24,4001 13 24 4001 Thu Feb 7 18:31:38 2019
leaf04 1,13,24,4001 13 24 4001 Thu Feb 7 18:31:38 2019
View VLAN Interface Information
You can view the current or past state of the interfaces associated with
VLANs using the netq show interfaces command. This provides the status
of the interface, its specified MTU, whether it is running over a VRF,
and the last time it was changed.
cumulus@switch:~$ netq show interfaces type vlan
Matching link records:
Hostname Interface Type State VRF Details Last Changed
----------------- ------------------------- ---------------- ---------- --------------- ----------------------------------- -------------------------
exit01 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
exit02 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf01 peerlink.4094 vlan up default MTU:9000 Fri Feb 8 00:24:28 2019
leaf01 vlan13 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf01 vlan24 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf01 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf02 peerlink.4094 vlan up default MTU:9000 Fri Feb 8 00:24:28 2019
leaf02 vlan13 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf02 vlan24 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf02 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf03 peerlink.4094 vlan up default MTU:9000 Fri Feb 8 00:24:28 2019
leaf03 vlan13 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf03 vlan24 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf03 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf04 peerlink.4094 vlan up default MTU:9000 Fri Feb 8 00:24:28 2019
leaf04 vlan13 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf04 vlan24 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
leaf04 vlan4001 vlan up vrf1 MTU:1500 Fri Feb 8 00:24:28 2019
View MAC Addresses Associated with a VLAN
You can determine the MAC addresses associated with a given VLAN using
the netq show macs vlan command. The command also provides the
hostnames of the devices, the egress port for the interface, whether the
MAC address originated from the given device, whether it learns the MAC
address from the peer (remote=yes), and the last time the configuration
was changed.
This example shows the MAC addresses associated with VLAN13.
cumulus@switch:~$ netq show macs vlan 13
Matching mac records:
Origin MAC Address VLAN Hostname Egress Port Remote Last Changed
------ ------------------ ------ ----------------- -------------------- ------ -------------------------
no 00:03:00:11:11:01 13 leaf01 bond01:server01 no Fri Feb 8 00:24:28 2019
no 00:03:00:11:11:01 13 leaf02 bond01:server01 no Fri Feb 8 00:24:28 2019
no 00:03:00:11:11:01 13 leaf03 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 00:03:00:11:11:01 13 leaf04 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 00:03:00:33:33:01 13 leaf01 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 00:03:00:33:33:01 13 leaf02 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 00:03:00:33:33:01 13 leaf03 bond03:server03 no Fri Feb 8 00:24:28 2019
no 00:03:00:33:33:01 13 leaf04 bond03:server03 no Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:01 13 leaf01 bond01:server01 no Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:01 13 leaf02 bond01:server01 no Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:01 13 leaf03 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:01 13 leaf04 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:02 13 leaf01 bond01:server01 no Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:02 13 leaf02 bond01:server01 no Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:02 13 leaf03 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 02:03:00:11:11:02 13 leaf04 vni13:leaf01 yes Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:01 13 leaf01 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:01 13 leaf02 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:01 13 leaf03 bond03:server03 no Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:01 13 leaf04 bond03:server03 no Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:02 13 leaf01 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:02 13 leaf02 vni13:10.0.0.134 yes Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:02 13 leaf03 bond03:server03 no Fri Feb 8 00:24:28 2019
no 02:03:00:33:33:02 13 leaf04 bond03:server03 no Fri Feb 8 00:24:28 2019
yes 44:38:39:00:00:03 13 leaf01 bridge no Fri Feb 8 00:24:28 2019
yes 44:38:39:00:00:15 13 leaf02 bridge no Fri Feb 8 00:24:28 2019
yes 44:38:39:00:00:23 13 leaf03 bridge no Fri Feb 8 00:24:28 2019
yes 44:38:39:00:00:5c 13 leaf04 bridge no Fri Feb 8 00:24:28 2019
yes 44:39:39:ff:00:13 13 leaf01 bridge no Fri Feb 8 00:24:28 2019
yes 44:39:39:ff:00:13 13 leaf02 bridge no Fri Feb 8 00:24:28 2019
yes 44:39:39:ff:00:13 13 leaf03 bridge no Fri Feb 8 00:24:28 2019
yes 44:39:39:ff:00:13 13 leaf04 bridge no Fri Feb 8 00:24:28 2019
View MAC Addresses Associated with an Egress Port
You can filter that information down to just the MAC addresses that are
associated with a given VLAN that use a particular egress port. This
example shows MAC addresses associated with the leaf03 switch and
VLAN 13 that use the bridge port.
cumulus@switch:~$ netq leaf03 show macs egress-port bridge vlan 13
Matching mac records:
Origin MAC Address VLAN Hostname Egress Port Remote Last Changed
------ ------------------ ------ ----------------- -------------------- ------ -------------------------
yes 44:38:39:00:00:23 13 leaf03 bridge no Fri Feb 8 00:24:28 2019
yes 44:39:39:ff:00:13 13 leaf03 bridge no Fri Feb 8 00:24:28 2019
View the MAC Addresses Associated with VRR Configurations
You can view all of the MAC addresses associated with your VRR (virtual
router reflector) interface configuration using the netq show interfaces type macvlan command. This is useful for determining if the
specified MAC address inside a VLAN is the same or different across your
VRR configuration.
cumulus@switch:~$ netq show interfaces type macvlan
Matching link records:
Hostname Interface Type State VRF Details Last Changed
----------------- ------------------------- ---------------- ---------- --------------- ----------------------------------- -------------------------
leaf01 vlan13-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:13, Fri Feb 8 00:28:09 2019
Mode: Private
leaf01 vlan24-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:24, Fri Feb 8 00:28:09 2019
Mode: Private
leaf02 vlan13-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:13, Fri Feb 8 00:28:09 2019
Mode: Private
leaf02 vlan24-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:24, Fri Feb 8 00:28:09 2019
Mode: Private
leaf03 vlan13-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:13, Fri Feb 8 00:28:09 2019
Mode: Private
leaf03 vlan24-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:24, Fri Feb 8 00:28:09 2019
Mode: Private
leaf04 vlan13-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:13, Fri Feb 8 00:28:09 2019
Mode: Private
leaf04 vlan24-v0 macvlan up vrf1 MAC: 44:39:39:ff:00:24, Fri Feb 8 00:28:09 2019
Mode: Private
View the History of a MAC Address
It is useful when debugging to be able to see when a MAC address is learned, when and where it moved in the network after that, if there was a duplicate at any time, and so forth. The netq show mac-history command makes this information available. It enables you to see:
each change that was made chronologically
changes made between two points in time, using the between option
only the difference between to points in time using the diff option
to order the output by selected output fields using the listby option
each change that was made for the MAC address on a particular VLAN, using the vlan option
And as with many NetQ commands, the default time range used is now to one hour ago. You can view the output in JSON format as well.
The syntax of the command is:
netq [<hostname>] show mac-history <mac> [vlan <1-4096>] [diff] [between <text-time> and <text-endtime>] [listby <text-list-by>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
This example shows how to view a full chronology of changes for a MAC Address. The caret (^) notation indicates no change in this value from the row above.
cumulus@switch:~$ netq show mac-history 00:03:00:11:11:77 vlan 13
Matching mac-history records:
Last Changed Hostname VLAN Origin Link Destination Remote Static
------------------------- ----------------- ------ ------ ---------------- ---------------------- ------ ------------
Mon Nov 4 20:21:13 2019 leaf01 13 no bond01 no no
Mon Nov 4 20:21:13 2019 leaf02 13 no bond01 no no
Mon Nov 4 20:21:13 2019 leaf04 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:21:13 2019 leaf03 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf03 ^ ^ bond03 no ^
Mon Nov 4 20:22:40 2019 leaf04 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf02 13 no vni13 10.0.0.134 yes no
Mon Nov 4 20:22:40 2019 leaf01 13 no vni13 10.0.0.134 yes no
This example shows how to view the history of a MAC address by hostname. The caret (^) notation indicates no change in this value from the row above.
cumulus@switch:~$ netq show mac-history 00:03:00:11:11:77 vlan 13 listby hostname
Matching mac-history records:
Last Changed Hostname VLAN Origin Link Destination Remote Static
------------------------- ----------------- ------ ------ ---------------- ---------------------- ------ ------------
Mon Nov 4 20:21:13 2019 leaf03 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf03 ^ ^ bond03 no ^
Mon Nov 4 20:21:13 2019 leaf02 13 no bond01 no no
Mon Nov 4 20:22:40 2019 leaf02 ^ ^ vni13 10.0.0.134 yes ^
Mon Nov 4 20:21:13 2019 leaf01 13 no bond01 no no
Mon Nov 4 20:22:40 2019 leaf01 ^ ^ vni13 10.0.0.134 yes ^
Mon Nov 4 20:21:13 2019 leaf04 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf04 ^ ^ bond03 no ^
This example shows show to view the history of a MAC address between now and two hours ago. The caret (^) notation indicates no change in this value from the row above.
cumulus@switch:~$ netq show mac-history 00:03:00:11:11:77 vlan 13 between now and 2h
Matching mac-history records:
Last Changed Hostname VLAN Origin Link Destination Remote Static
------------------------- ----------------- ------ ------ ---------------- ---------------------- ------ ------------
Mon Nov 4 20:21:13 2019 leaf01 13 no bond01 no no
Mon Nov 4 20:21:13 2019 leaf02 13 no bond01 no no
Mon Nov 4 20:21:13 2019 leaf04 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:21:13 2019 leaf03 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf03 ^ ^ bond03 no ^
Mon Nov 4 20:22:40 2019 leaf04 13 no vni13 10.0.0.112 yes no
Mon Nov 4 20:22:40 2019 leaf02 13 no vni13 10.0.0.134 yes no
Mon Nov 4 20:22:40 2019 leaf01 13 no vni13 10.0.0.134 yes no
Monitor MLAG Configurations
Multi-Chassis Link Aggregation (MLAG) is used to enable a server or
switch with a two-port bond (such as a link aggregation group/LAG,
EtherChannel, port group or trunk) to connect those ports to different
switches and operate as if they are connected to a single, logical
switch. This provides greater redundancy and greater system throughput.
Dual-connected devices can create LACP bonds that contain links to each
physical switch. Therefore, active-active links from the dual-connected
devices are supported even though they are connected to two different
physical switches.
MLAG or CLAG?
The Cumulus Linux implementation of MLAG is referred to by other vendors
as CLAG, MC-LAG or VPC. You will even see references to CLAG in Cumulus
Linux and Cumulus NetQ, including the management daemon, named clagd, and other options
in the code, such as clag-id, which exist for historical purposes. The
Cumulus Linux implementation is truly a multi-chassis link aggregation
protocol, so we call it MLAG.
For instructions on configuring MLAG, refer to the MLAG topic in the Cumulus Linux User Guide.
With NetQ, you can view the configuration and operation of devices using
MLAG using the netq show clag command. You can view the current
configuration and the configuration at a prior point in time, as well as
view any changes that have been made within a timeframe. The syntax for
the show command is:
netq [<hostname>] show clag [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type clag [between <text-time> and <text-endtime>] [json]
View MLAG Configuration and Status for all Devices
This example shows the configuration and status of MLAG for all devices.
In this case, three MLAG pairs are seen between leaf11 and leaf12 (which
happens to be down), edge01(P) and edge02, and leaf21(P) and leaf22.
cumulus@switch:~$ netq show clag
Matching clag records:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
leaf11 44:38:39:ff:ff:01 down n/a 0 0 Thu Feb 7 18:30:49 2019
leaf12 44:38:39:ff:ff:01 down down 8 0 Thu Feb 7 18:30:53 2019
edge01(P) edge02 00:01:01:10:00:01 up up 25 25 Thu Feb 7 18:31:02 2019
edge02 edge01(P) 00:01:01:10:00:01 up up 25 25 Thu Feb 7 18:31:15 2019
leaf21(P) leaf22 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:20 2019
leaf22 leaf21(P) 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:30 2019
You can go back in time to see when this first MLAG pair went down.
These results indicate that the pair became disconnected some time in
the last five minutes.
cumulus@switch:~$ netq show clag around 5m
Matching clag records:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
edge01(P) edge02 00:01:01:10:00:01 up up 25 25 Thu Feb 7 18:31:30 2019
edge02 edge01(P) 00:01:01:10:00:01 up up 25 25 Thu Feb 7 18:31:30 2019
leaf11(P) leaf12 44:38:39:ff:ff:01 up up 8 8 Thu Feb 7 18:31:30 2019
leaf12 leaf11(P) 44:38:39:ff:ff:01 up up 8 8 Thu Feb 7 18:31:30 2019
leaf21(P) leaf22 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:30 2019
leaf22 leaf21(P) 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:30 2019
View MLAG Configuration and Status for Given Devices
This example shows that leaf22 is up and MLAG properly configured with a
peer connection to leaf21 through 8 bonds, all of which are dual bonded.
cumulus@switch:~$ netq leaf22 show clag
Matching CLAG session records are:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
leaf22 leaf21(P) 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:30 2019
When you’re directly on the switch, you can run clagctl to get the
state:
It is important that the switches and hosts remain in time
synchronization with the NetQ Platform to ensure collected data is
properly captured and processed. You can use the netq show ntp command
to view the time synchronization status for all devices or filter for
devices that are either in synchronization or out of synchronization,
currently or at a time in the past. The syntax for the show command is:
netq [<hostname>] show ntp [out-of-sync|in-sync] [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type ntp [between <text-time> and <text-endtime>] [json]
This example shows the time synchronization status for all devices in
the network.
This example shows all devices in the network that are out of time
synchronization, and consequently might need to be investigated.
cumulus@switch:~$ netq show ntp out-of-sync
Matching ntp records:
Hostname NTP Sync Current Server Stratum NTP App
----------------- -------- ----------------- ------- ---------------------
internet no - 16 ntpq
This example shows the time synchronization status for leaf01.
cumulus@switch:~$ netq leaf01 show ntp
Matching ntp records:
Hostname NTP Sync Current Server Stratum NTP App
----------------- -------- ----------------- ------- ---------------------
leaf01 yes kilimanjaro 2 ntpq
Monitor Spanning Tree Protocol Configuration
The Spanning Tree Protocol (STP) is used
in Ethernet-based networks to prevent communication loops when you have
redundant paths on a bridge or switch. Loops cause excessive broadcast
messages greatly impacting the network performance. With NetQ, you can
view the STP topology on a bridge or switch to ensure no loops have been
created using the netq show stp topology command. You can also view
the topology information for a prior point in time to see if any changes
were made around then. The syntax for the show command is:
netq <hostname> show stp topology [around <text-time>] [json]
This example shows the STP topology as viewed from the spine1 switch.
If you have VLANs configured, you can view the available paths between two devices on the VLAN currently and at a time in the past using their MAC addresses . You can view the output in one of three formats (json, pretty, and detail). JSON output provides the output in a JSON file format for ease of importing to other applications or software. Pretty output lines up the paths in a pseudo-graphical manner to help visualize multiple paths. Detail output is useful for traces with higher hop counts where the pretty output wraps lines, making it harder to interpret the results. The detail output displays a table with a row for each path.
To view the paths:
Identify the MAC address and VLAN ID for the destination device
Identify the IP address or hostname for the source device
Use the netq trace command to see the available paths between
those devices.
The syntax requires the destination device address first, mac, and
then the source device address or hostname. Additionally, the vlan
keyword-value pair is required for layer 2 traces even though the syntax
indicates it is optional.
The tracing function only knows about addresses that have already been
learned. If you find that a path is invalid or incomplete, you may need
to ping the identified device so that its address becomes known.
View Paths between Two Switches with Pretty Output
This example shows the available paths between a top of rack switch,
tor-1, and a server, server11. The request is to go through VLAN
1001 from the VRF vrf1. The results include a summary of the trace,
including the total number of paths available, those with errors and
warnings, and the MTU of the paths. In this case, the results are
displayed in pseudo-graphical output.
View Paths between Two Switches with Drops Detected
If you have a Mellanox switch, the What Just Happened feature detects various drop statistics. These are visible in the results of trace requests. This example shows the available paths between a switch with IP address 6.0.2.66 and a switch with IP address 6.0.2.70, where drops have been detected on path 1.
cumulus@mlx-2700:~$ netq trace 6.0.2.66 from 6.0.2.70
Number of Paths: 1
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Top packet drops along the paths in the last hour:
Path: 1 at mlx-2700:swp3s1, type: L2, reason: Source MAC equals destination MAC, flow: src_ip: 6.0.2.70, dst_ip: 6.0.2.66, protocol: 0, src_port: 0, dst_port: 0
Path MTU: 9152
Id Hop Hostname InPort InTun, RtrIf OutRtrIf, Tun OutPort
--- --- ----------- --------------- --------------- --------------- ---------------
1 1 hosts-11 swp1.1008
2 mlx-2700-03 swp3s1
--- --- ----------- --------------- --------------- --------------- ---------------
Monitor Layer 2 Drops on Mellanox Switches
The What Just Happened (WJH) feature, available on Mellanox switches, streams detailed and contextual telemetry data for analysis. This provides real-time visibility into problems in the network, such as hardware packet drops due to buffer congestion, incorrect routing, and ACL or layer 1 problems. You must have Cumulus Linux 4.0.0 or later and NetQ 2.4.0 or later to take advantage of this feature.
When WJH capabilities are combined with Cumulus Linux 4.0.0 and NetQ 2.4.0, giving you the ability to hone in on losses, anywhere in the fabric, from a single management console. You can:
View any current or historic drop information, including the reason for the drop
Identify problematic flows or endpoints, and pin-point exactly where communication is failing in the network
By default, Cumulus Linux 4.0.0 provides the NetQ 2.3.1 Agent and CLI. If you installed Cumulus Linux 4.0.0 on your Mellanox switch, you need to upgrade the NetQ Agent and optionally the CLI to release 2.4.0 or later.
WJH is enabled by default on Mellanox switches and no configuration is required in Cumulus Linux 4.0.0; however, you must enable the NetQ Agent to collect the data in NetQ 2.4.0.
To enable WJH in NetQ:
Configure the NetQ Agent on the Mellanox switch.
cumulus@switch:~$ netq config add agent wjh
Restart the NetQ Agent to start collecting the WJH data.
cumulus@switch:~$ netq config restart agent
When you are finished viewing the WJH metrics, you might want to disable the NetQ Agent to reduce network traffic. Use netq config del agent wjh followed by netq config restart agent to disable the WJH feature on the given switch.
Using wjh_dump.py on a Mellanox platform that is running Cumulus Linux 4.0 and the NetQ 2.4.0 agent causes the NetQ WJH client to stop receiving packet drop call backs. To prevent this issue, run wjh_dump.py on a different system than the one where the NetQ Agent has WJH enabled, or disable wjh_dump.py and restart the NetQ Agent (run netq config restart agent).
View What Just Happened Metrics
View layer 2 drop statistics using the netq show wjh-drop NetQ CLI command. The full syntax for this command is:
This example shows the drops seen at layer 2 across the network:
cumulus@mlx-2700-03:mgmt:~$ netq show wjh-drop l2
Matching wjh records:
Hostname Ingress Port Reason Agg Count Src Ip Dst Ip Proto Src Port Dst Port Src Mac Dst Mac First Timestamp Last Timestamp
----------------- ------------------------ --------------------------------------------- ------------------ ---------------- ---------------- ------ ---------------- ---------------- ------------------ ------------------ ------------------------------ ----------------------------
mlx-2700-03 swp1s2 Port loopback filter 10 27.0.0.19 27.0.0.22 0 0 0 00:02:00:00:00:73 0c:ff:ff:ff:ff:ff Mon Dec 16 11:54:15 2019 Mon Dec 16 11:54:15 2019
mlx-2700-03 swp1s2 Source MAC equals destination MAC 10 27.0.0.19 27.0.0.22 0 0 0 00:02:00:00:00:73 00:02:00:00:00:73 Mon Dec 16 11:53:17 2019 Mon Dec 16 11:53:17 2019
mlx-2700-03 swp1s2 Source MAC equals destination MAC 10 0.0.0.0 0.0.0.0 0 0 0 00:02:00:00:00:73 00:02:00:00:00:73 Mon Dec 16 11:40:44 2019 Mon Dec 16 11:40:44 2019
Monitor Network Layer Protocols
With NetQ, a network administrator can monitor OSI Layer 3 network
protocols running on Linux-based hosts, including IP (Internet
Protocol), BGP (Border Gateway Protocol) and OSPF (Open Shortest Path
First). NetQ provides the ability to:
Validate protocol configurations.
Validate layer 3 communication paths.
It helps answer questions such as:
Who are the IP neighbors for a switch?
How many IPv4 and IPv6 addresses am I using?
When did changes occur to my IP configuration?
Is BGP working as expected?
Is OSPF working as expected?
Can device A reach device B using IP addresses?
Monitor IP Configuration
NetQ enables you to view the current status and the status an earlier
point in time. From this information, you can:
Determine IP addresses of one or more interfaces.
Determine IP neighbors for one or more devices.
Determine IP routes owned by a device.
Identify changes to the IP configuration.
The netq show ip command is used to obtain the address, neighbor, and
route information from the devices. Its syntax is:
netq <hostname> show ip addresses [<remote-interface>] [<ipv4>|<ipv4/prefixlen>] [vrf <vrf>] [around <text-time>] [count] [json]
netq [<hostname>] show ip addresses [<remote-interface>] [<ipv4>|<ipv4/prefixlen>] [vrf <vrf>] [around <text-time>] [json]
netq show ip addresses [<remote-interface>] [<ipv4>|<ipv4/prefixlen>] [vrf <vrf>] [subnet|supernet|gateway] [around <text-time>] [json]
netq <hostname> show ip neighbors [<remote-interface>] [<ipv4>|<ipv4> vrf <vrf>|vrf <vrf>] [<mac>] [around <text-time>] [json]
netq [<hostname>] show ip neighbors [<remote-interface>] [<ipv4>|<ipv4> vrf <vrf>|vrf <vrf>] [<mac>] [around <text-time>] [count] [json]
netq <hostname> show ip routes [<ipv4>|<ipv4/prefixlen>] [vrf <vrf>] [origin] [around <text-time>] [count] [json]
netq [<hostname>] show ip routes [<ipv4>|<ipv4/prefixlen>] [vrf <vrf>] [origin] [around <text-time>] [json]
netq <hostname> show ipv6 addresses [<remote-interface>] [<ipv6>|<ipv6/prefixlen>] [vrf <vrf>] [around <text-time>] [count] [json]
netq [<hostname>] show ipv6 addresses [<remote-interface>] [<ipv6>|<ipv6/prefixlen>] [vrf <vrf>] [around <text-time>] [json]
netq show ipv6 addresses [<remote-interface>] [<ipv6>|<ipv6/prefixlen>] [vrf <vrf>] [subnet|supernet|gateway] [around <text-time>] [json]
netq <hostname> show ipv6 neighbors [<remote-interface>] [<ipv6>|<ipv6> vrf <vrf>|vrf <vrf>] [<mac>] [around <text-time>] [count] [json]
netq [<hostname>] show ipv6 neighbors [<remote-interface>] [<ipv6>|<ipv6> vrf <vrf>|vrf <vrf>] [<mac>] [around <text-time>] [json]
netq <hostname> show ipv6 routes [<ipv6>|<ipv6/prefixlen>] [vrf <vrf>] [origin] [around <text-time>] [count] [json]
netq [<hostname>] show ipv6 routes [<ipv6>|<ipv6/prefixlen>] [vrf <vrf>] [origin] [around <text-time>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View IP Address Information
You can view the IPv4 and IPv6 address information for all of your
devices, including the interface and VRF for each device. Additionally,
you can:
View the information at an earlier point in time.
Filter against a particular device, interface or VRF assignment.
Obtain a count of all of the addresses.
Each of these provides information for troubleshooting potential
configuration and communication issues at the layer 3 level.
Example: View IPv4 address information for all devices
cumulus@switch:~$ netq show ip addresses
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
10.0.0.11/32 leaf01 lo default Thu Feb 7 18:30:53 2019
10.0.0.12/32 leaf02 lo default Thu Feb 7 18:30:53 2019
10.0.0.13/32 leaf03 lo default Thu Feb 7 18:30:53 2019
10.0.0.14/32 leaf04 lo default Thu Feb 7 18:30:53 2019
10.0.0.21/32 spine01 lo default Thu Feb 7 18:30:53 2019
10.0.0.22/32 spine02 lo default Thu Feb 7 18:30:53 2019
10.0.0.254/32 oob-mgmt-server eth0 default Thu Feb 7 18:30:53 2019
172.16.1.1/24 leaf01 br0 default Thu Feb 7 18:30:53 2019
172.16.1.101/24 server01 eth1 default Thu Feb 7 18:30:53 2019
172.16.2.1/24 leaf02 br0 default Thu Feb 7 18:30:53 2019
172.16.2.101/24 server02 eth2 default Thu Feb 7 18:30:53 2019
172.16.3.1/24 leaf03 br0 default Thu Feb 7 18:30:53 2019
172.16.3.101/24 server03 eth1 default Thu Feb 7 18:30:53 2019
172.16.4.1/24 leaf04 br0 default Thu Feb 7 18:30:53 2019
172.16.4.101/24 server04 eth2 default Thu Feb 7 18:30:53 2019
172.17.0.1/16 oob-mgmt-server docker0 default Thu Feb 7 18:30:53 2019
192.168.0.11/24 leaf01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.12/24 leaf02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.13/24 leaf03 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.14/24 leaf04 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.21/24 spine01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.22/24 spine02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.254/24 oob-mgmt-server eth1 default Thu Feb 7 18:30:53 2019
192.168.0.31/24 server01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.32/24 server02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.33/24 server03 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.34/24 server04 eth0 default Thu Feb 7 18:30:53 2019
Example: View IPv6 address information for all devices
cumulus@switch:~$ netq show ipv6 addresses
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
fe80::203:ff:fe11:1101/64 server01 eth1 default Thu Feb 7 18:30:53 2019
fe80::203:ff:fe22:2202/64 server02 eth2 default Thu Feb 7 18:30:53 2019
fe80::203:ff:fe33:3301/64 server03 eth1 default Thu Feb 7 18:30:53 2019
fe80::203:ff:fe44:4402/64 server04 eth2 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:18/6 leaf02 br0 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:1b/6 leaf03 swp52 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:1c/6 spine02 swp3 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:23/6 leaf03 br0 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:24/6 leaf01 swp52 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:25/6 spine02 swp1 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:28/6 leaf02 swp51 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:29/6 spine01 swp2 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:2c/6 leaf04 br0 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:3/64 leaf01 br0 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:3b/6 leaf04 swp51 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:3c/6 spine01 swp4 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:46/6 leaf04 swp52 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:47/6 spine02 swp4 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:4f/6 leaf03 swp51 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:50/6 spine01 swp3 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:53/6 leaf01 swp51 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:54/6 spine01 swp1 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:57/6 oob-mgmt-server eth1 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:5d/6 leaf02 swp52 default Thu Feb 7 18:30:53 2019
fe80::4638:39ff:fe00:5e/6 spine02 swp2 default Thu Feb 7 18:30:53 2019
fe80::5054:ff:fe77:c277/6 oob-mgmt-server eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:11/64 leaf01 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:12/64 leaf02 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:13/64 leaf03 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:14/64 leaf04 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:21/64 spine01 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:22/64 spine02 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:31/64 server01 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:32/64 server02 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:33/64 server03 eth0 default Thu Feb 7 18:30:53 2019
fe80::a200:ff:fe00:34/64 server04 eth0 default Thu Feb 7 18:30:53 2019
Example: Filter IP Address Information for a Specific Interface
This example shows the IPv4 address information for the eth0 interface
on all devices.
cumulus@switch:~$ netq show ip addresses eth0
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
10.0.0.254/32 oob-mgmt-server eth0 default Thu Feb 7 18:30:53 2019
192.168.0.11/24 leaf01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.12/24 leaf02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.13/24 leaf03 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.14/24 leaf04 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.21/24 spine01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.22/24 spine02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.31/24 server01 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.32/24 server02 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.33/24 server03 eth0 default Thu Feb 7 18:30:53 2019
192.168.0.34/24 server04 eth0 default Thu Feb 7 18:30:53 2019
Example: Filter IP Address Information for a Specific Device
This example shows the IPv6 address information for the leaf01 switch.
cumulus@switch:~$ netq leaf01 show ipv6 addresses
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
2001:c15c:d06:f00d::16/12 leaf01 lo default Fri Feb 8 00:35:07 2019
8
2001:cafe:babe:0:22::/128 leaf01 DataVrf1080 DataVrf1080 Fri Feb 8 00:35:07 2019
2001:cafe:babe:1:22::/128 leaf01 DataVrf1081 DataVrf1081 Fri Feb 8 00:35:07 2019
2001:cafe:babe:2:22::/128 leaf01 DataVrf1082 DataVrf1082 Fri Feb 8 00:35:07 2019
2001:fee1:600d:10::1/64 leaf01 VlanA-1.102 DataVrf1082 Fri Feb 8 00:35:07 2019
2001:fee1:600d:11::1/64 leaf01 VlanA-1.103 default Fri Feb 8 00:35:07 2019
2001:fee1:600d:12::1/64 leaf01 VlanA-1.104 default Fri Feb 8 00:35:07 2019
2001:fee1:600d:13::1/64 leaf01 VlanA-1.105 default Fri Feb 8 00:35:07 2019
2001:fee1:600d:14::1/64 leaf01 VlanA-1.106 default Fri Feb 8 00:35:07 2019
2001:fee1:600d:e::1/64 leaf01 VlanA-1.100 DataVrf1080 Fri Feb 8 00:35:07 2019
2001:fee1:600d:f::1/64 leaf01 VlanA-1.101 DataVrf1081 Fri Feb 8 00:35:07 2019
2001:fee1:d00d:1::1/64 leaf01 vlan1001-v0 vrf1 Fri Feb 8 00:35:07 2019
2001:fee1:d00d:1::2/64 leaf01 vlan1001 vrf1 Fri Feb 8 00:35:07 2019
2001:fee1:d00d:2::1/64 leaf01 vlan1002-v0 vrf1 Fri Feb 8 00:35:07 2019
Example: View Changes to IP Address Information
This example shows the IPv4 address information that changed for all
devices around 1 day ago.
cumulus@switch:~$ netq show ip addresses around 1d
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
192.168.0.15/24 leaf01 eth0 mgmt Thu Feb 7 22:49:26 2019
27.0.0.22/32 leaf01 lo default Thu Feb 7 22:49:26 2019
3.0.3.129/26 leaf01 VlanA-1.100 DataVrf1080 Thu Feb 7 22:49:26 2019
3.0.3.193/26 leaf01 VlanA-1.101 DataVrf1081 Thu Feb 7 22:49:26 2019
3.0.4.1/26 leaf01 VlanA-1.102 DataVrf1082 Thu Feb 7 22:49:26 2019
3.0.4.129/26 leaf01 VlanA-1.104 default Thu Feb 7 22:49:26 2019
3.0.4.193/26 leaf01 VlanA-1.105 default Thu Feb 7 22:49:26 2019
3.0.4.65/26 leaf01 VlanA-1.103 default Thu Feb 7 22:49:26 2019
3.0.5.1/26 leaf01 VlanA-1.106 default Thu Feb 7 22:49:26 2019
30.0.0.22/32 leaf01 DataVrf1080 DataVrf1080 Thu Feb 7 22:49:26 2019
30.0.1.22/32 leaf01 DataVrf1081 DataVrf1081 Thu Feb 7 22:49:26 2019
30.0.2.22/32 leaf01 DataVrf1082 DataVrf1082 Thu Feb 7 22:49:26 2019
45.0.0.13/26 leaf01 NetQBond-1 mgmt Thu Feb 7 22:49:26 2019
6.0.0.1/26 leaf01 vlan1000-v0 vrf1 Thu Feb 7 22:49:26 2019
6.0.0.129/26 leaf01 vlan1002-v0 vrf1 Thu Feb 7 22:49:26 2019
Example: Obtain a Count of IP Addresses Used on a Node
This example shows the number of IPv4 and IPv6 addresses on the node
leaf01. Note that you must specify a hostname to use the count option.
cumulus@switch:~$ netq leaf01 show ip addresses count
Count of matching address records: 33
cumulus@switch:~$ netq leaf01 show ipv6 addresses count
Count of matching address records: 42
View IP Neighbor Information
You can view the IPv4 and IPv6 neighbor information for all of your
devices, including the interface port, MAC address, VRF assignment, and
whether it learns the MAC address from the peer (remote=yes).
Additionally, you can:
View the information at an earlier point in time.
Filter against a particular device, interface, address or VRF assignment.
Obtain a count of all of the addresses.
Each of these provides information for troubleshooting potential
configuration and communication issues at the layer 3 level.
Example: View IPv4 Neighbor Information for All Devices
cumulus@switch:~$ netq show ip neighbors
Matching neighbor records:
IP Address Hostname Interface MAC Address VRF Remote Last Changed
------------------------- ----------------- ------------------------- ------------------ --------------- ------ -------------------------
10.255.5.1 oob-mgmt-server eth0 52:54:00:0f:79:30 default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf01 swp51 44:38:39:00:00:54 default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf01 swp52 44:38:39:00:00:25 default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf02 swp51 44:38:39:00:00:29 default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf02 swp52 44:38:39:00:00:5e default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf03 swp51 44:38:39:00:00:50 default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf03 swp52 44:38:39:00:00:1c default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf04 swp51 44:38:39:00:00:3c default no Thu Feb 7 22:49:26 2019
169.254.0.1 leaf04 swp52 44:38:39:00:00:47 default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine01 swp1 44:38:39:00:00:53 default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine01 swp2 44:38:39:00:00:28 default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine01 swp3 44:38:39:00:00:4f default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine01 swp4 44:38:39:00:00:3b default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine02 swp1 44:38:39:00:00:24 default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine02 swp2 44:38:39:00:00:5d default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine02 swp3 44:38:39:00:00:1b default no Thu Feb 7 22:49:26 2019
169.254.0.1 spine02 swp4 44:38:39:00:00:46 default no Thu Feb 7 22:49:26 2019
192.168.0.11 oob-mgmt-server eth1 a0:00:00:00:00:11 default no Thu Feb 7 22:49:26 2019
192.168.0.12 oob-mgmt-server eth1 a0:00:00:00:00:12 default no Thu Feb 7 22:49:26 2019
192.168.0.13 oob-mgmt-server eth1 a0:00:00:00:00:13 default no Thu Feb 7 22:49:26 2019
192.168.0.14 oob-mgmt-server eth1 a0:00:00:00:00:14 default no Thu Feb 7 22:49:26 2019
192.168.0.21 oob-mgmt-server eth1 a0:00:00:00:00:21 default no Thu Feb 7 22:49:26 2019
192.168.0.22 oob-mgmt-server eth1 a0:00:00:00:00:22 default no Thu Feb 7 22:49:26 2019
192.168.0.253 oob-mgmt-server eth1 a0:00:00:00:00:50 default no Thu Feb 7 22:49:26 2019
192.168.0.254 leaf01 eth0 44:38:39:00:00:57 default no Thu Feb 7 22:49:26 2019
192.168.0.254 leaf02 eth0 44:38:39:00:00:57 default no Thu Feb 7 22:49:26 2019
...
Example: View IPv6 Neighbor Information for a Given Device
This example shows the IPv6 neighbors for leaf02 switch.
cumulus@switch$ netq leaf02 show ipv6 neighbors
Matching neighbor records:
IP Address Hostname Interface MAC Address VRF Remote Last Changed
------------------------- ----------------- ------------------------- ------------------ --------------- ------ -------------------------
fe80::203:ff:fe22:2202 leaf02 br0 00:03:00:22:22:02 default no Thu Feb 7 22:49:26 2019
fe80::4638:39ff:fe00:29 leaf02 swp51 44:38:39:00:00:29 default no Thu Feb 7 22:49:26 2019
fe80::4638:39ff:fe00:4 leaf02 eth0 44:38:39:00:00:04 default no Thu Feb 7 22:49:26 2019
fe80::4638:39ff:fe00:5e leaf02 swp52 44:38:39:00:00:5e default no Thu Feb 7 22:49:26 2019
fe80::a200:ff:fe00:31 leaf02 eth0 a0:00:00:00:00:31 default no Thu Feb 7 22:49:26 2019
fe80::a200:ff:fe00:32 leaf02 eth0 a0:00:00:00:00:32 default no Thu Feb 7 22:49:26 2019
fe80::a200:ff:fe00:33 leaf02 eth0 a0:00:00:00:00:33 default no Thu Feb 7 22:49:26 2019
fe80::a200:ff:fe00:34 leaf02 eth0 a0:00:00:00:00:34 default no Thu Feb 7 22:49:26 2019
View IP Routes Information
You can view the IPv4 and IPv6 routes for all of your devices, including
the IP address (with or without mask), the destination (by hostname) of
the route, next hops available, VRF assignment, and whether a host is
the owner of the route or MAC address. Additionally, you can:
View the information at an earlier point in time.
Filter against a particular address or VRF assignment.
Obtain a count of all of the routes.
Each of these provides information for troubleshooting potential
configuration and communication issues at the layer 3 level.
Example: View IP Routes for All Devices
This example shows the IPv4 and IPv6 routes for all devices in the
network.
cumulus@switch:~$ netq show ipv6 routes
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
yes default ::/0 server04 lo Thu Feb 7 22:49:26 2019
yes default ::/0 server03 lo Thu Feb 7 22:49:26 2019
yes default ::/0 server01 lo Thu Feb 7 22:49:26 2019
yes default ::/0 server02 lo Thu Feb 7 22:49:26 2019
cumulus@switch:~$ netq show ip routes
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
yes DataVrf1080 3.0.3.128/26 leaf01 VlanA-1.100 Fri Feb 8 00:46:17 2019
yes DataVrf1080 3.0.3.129/32 leaf01 VlanA-1.100 Fri Feb 8 00:46:17 2019
yes DataVrf1080 30.0.0.22/32 leaf01 DataVrf1080 Fri Feb 8 00:46:17 2019
yes DataVrf1081 3.0.3.192/26 leaf01 VlanA-1.101 Fri Feb 8 00:46:17 2019
yes DataVrf1081 3.0.3.193/32 leaf01 VlanA-1.101 Fri Feb 8 00:46:17 2019
yes DataVrf1081 30.0.1.22/32 leaf01 DataVrf1081 Fri Feb 8 00:46:17 2019
yes DataVrf1082 3.0.4.0/26 leaf01 VlanA-1.102 Fri Feb 8 00:46:17 2019
yes DataVrf1082 3.0.4.1/32 leaf01 VlanA-1.102 Fri Feb 8 00:46:17 2019
yes DataVrf1082 30.0.2.22/32 leaf01 DataVrf1082 Fri Feb 8 00:46:17 2019
yes default 27.0.0.22/32 leaf01 lo Fri Feb 8 00:46:17 2019
yes default 3.0.4.128/26 leaf01 VlanA-1.104 Fri Feb 8 00:46:17 2019
yes default 3.0.4.129/32 leaf01 VlanA-1.104 Fri Feb 8 00:46:17 2019
yes default 3.0.4.192/26 leaf01 VlanA-1.105 Fri Feb 8 00:46:17 2019
yes default 3.0.4.193/32 leaf01 VlanA-1.105 Fri Feb 8 00:46:17 2019
...
Example: View IP Routes for a Given IPAddress
This example shows the routes available for an IP address of 10.0.0.12.
cumulus@switch:~$ netq show ip routes 10.0.0.12
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
no default 10.0.0.12/32 leaf03 10.0.0.21: swp51, 10.0.0.22: swp52 Fri Feb 8 00:46:17 2019
no default 10.0.0.12/32 leaf01 10.0.0.21: swp51, 10.0.0.22: swp52 Fri Feb 8 00:46:17 2019
no default 10.0.0.12/32 leaf04 10.0.0.21: swp51, 10.0.0.22: swp52 Fri Feb 8 00:46:17 2019
no default 10.0.0.12/32 spine02 10.0.0.12: swp2 Fri Feb 8 00:46:17 2019
no default 10.0.0.12/32 spine01 10.0.0.12: swp2 Fri Feb 8 00:46:17 2019
yes default 10.0.0.12/32 leaf02 lo Fri Feb 8 00:46:17 2019
Example: View IP Routes Owned by a Given Device
This example shows the IPv4 routes that are owned by spine01 switch.
cumulus@switch:~$ netq spine01 show ip routes origin
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
yes default 10.0.0.21/32 spine01 lo Fri Feb 8 00:46:17 2019
yes default 192.168.0.0/24 spine01 eth0 Fri Feb 8 00:46:17 2019
yes default 192.168.0.21/32 spine01 eth0 Fri Feb 8 00:46:17 2019
Example: View IP Routes for a Given Device at a Prior Time
This example show the IPv4 routes for spine01 switch about 24 hours ago.
cumulus@switch:~$ netq spine01 show ip routes around 24h
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
no default 10.0.0.11/32 spine01 169.254.0.1: swp1 Fri Feb 8 00:46:17 2019
no default 10.0.0.12/32 spine01 169.254.0.1: swp2 Fri Feb 8 00:46:17 2019
no default 10.0.0.13/32 spine01 169.254.0.1: swp3 Fri Feb 8 00:46:17 2019
no default 10.0.0.14/32 spine01 169.254.0.1: swp4 Fri Feb 8 00:46:17 2019
no default 172.16.1.0/24 spine01 169.254.0.1: swp1 Fri Feb 8 00:46:17 2019
no default 172.16.2.0/24 spine01 169.254.0.1: swp2 Fri Feb 8 00:46:17 2019
no default 172.16.3.0/24 spine01 169.254.0.1: swp3 Fri Feb 8 00:46:17 2019
no default 172.16.4.0/24 spine01 169.254.0.1: swp4 Fri Feb 8 00:46:17 2019
yes default 10.0.0.21/32 spine01 lo Fri Feb 8 00:46:17 2019
yes default 192.168.0.0/24 spine01 eth0 Fri Feb 8 00:46:17 2019
yes default 192.168.0.21/32 spine01 eth0 Fri Feb 8 00:46:17 2019
Example: View the Number of IP Routes on a Node
This example shows the total number of IP routes for all devices on a
node.
cumulus@switch:~$ netq leaf01 show ip routes count
Count of matching routes records: 125
cumulus@switch:~$ netq leaf01 show ipv6 routes count
Count of matching routes records: 5
Monitor BGP Configuration
If you have BGP running on your switches and hosts, you can monitor its
operation using the NetQ CLI. For each device, you can view its
associated neighbors, ASN (autonomous system number), peer ASN, receive
IP or EVPN address prefixes, and VRF assignment. Additionally, you can:
View the information at an earlier point in time.
Filter against a particular device, ASN, or VRF assignment.
Validate it is operating correctly across the network.
The netq show bgp command is used to obtain the BGP configuration
information from the devices. The netq check bgp command is used to
validate the configuration. The syntax of these commands is:
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View BGP Configuration Information
NetQ enables you to view the BGP configuration of a single device or
across all of your devices at once. You can filter the results based on
an ASN, BGP session (IP address or interface name), or VRF assignment.
You can view the configuration in the past and view changes made to the
configuration within a given timeframe.
Example: View BGP Configuration Information Across Network
This example shows the BGP configuration across all of your switches. In
this scenario, BGP routing is configured between two spines and four
leafs. Each leaf switch has a unique ASN and the spine switches share an
ASN. The PfxRx column indicates that these devices have IPv4 address
prefixes. The second and third values in this column indicate IPv6 and
EVPN address prefixes when configured. This configuration was changed
just over one day ago.
Example: View BGP Configuration Information for a Given Device
This example shows the BGP configuration information for the spine02
switch. The switch is peered with swp1 on leaf01, swp2 on leaf02, and so
on. Spine02 has an ASN of 65020 and each of the leafs have unique ASNs.
Example: View BGP Configuration Information for a Given ASN
This example shows the BGP configuration information for ASN of
655557. This ASN is associated with spine02 and so the results show
the BGP neighbors for that switch.
This example shows that BGP configuration changes were made about five
days ago on this network.
cumulus@switch:~$ netq show events type bgp between now and 5d
Matching bgp records:
Hostname Message Type Severity Message Timestamp
----------------- ------------ -------- ----------------------------------- -------------------------
leaf01 bgp info BGP session with peer spine01 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine02 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine03 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine01 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine03 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine02 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine03 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine02 @desc 2h:10m:11s
: state changed from failed to esta
blished
leaf01 bgp info BGP session with peer spine01 @desc 2h:10m:11s
: state changed from failed to esta
blished
...
Validate BGP Operation
A single command enables you to validate that all configured route
peering is established across the network. The command checks for
duplicate router IDs and sessions that are in an unestablished state.
Either of these conditions trigger a configuration check failure. When a
failure is found, the reason is identified in the output along with the
time the issue occurred.
This example shows a check on the BGP operations that found no failed
sessions.
cumulus@switch:~$ netq check bgp
Total Nodes: 15, Failed Nodes: 0, Total Sessions: 16, Failed Sessions: 0
This example shows 24 failed BGP sessions with a variety of reasons.
cumulus@switch:~$ netq check bgp
Total Nodes: 25, Failed Nodes: 3, Total Sessions: 220 , Failed Sessions: 24,
Hostname VRF Peer Name Peer Hostname Reason Last Changed
----------------- --------------- ----------------- ----------------- --------------------------------------------- -------------------------
exit-1 DataVrf1080 swp6.2 firewall-1 BGP session with peer firewall-1 swp6.2: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-1 DataVrf1080 swp7.2 firewall-2 BGP session with peer firewall-2 (swp7.2 vrf 1d:7h:49m:31s
DataVrf1080) failed,
reason: Peer not configured
exit-1 DataVrf1081 swp6.3 firewall-1 BGP session with peer firewall-1 swp6.3: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-1 DataVrf1081 swp7.3 firewall-2 BGP session with peer firewall-2 (swp7.3 vrf 1d:7h:49m:31s
DataVrf1081) failed,
reason: Peer not configured
exit-1 DataVrf1082 swp6.4 firewall-1 BGP session with peer firewall-1 swp6.4: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-1 DataVrf1082 swp7.4 firewall-2 BGP session with peer firewall-2 (swp7.4 vrf 1d:7h:49m:31s
DataVrf1082) failed,
reason: Peer not configured
exit-1 default swp6 firewall-1 BGP session with peer firewall-1 swp6: AFI/SA 1d:7h:56m:9s
FI evpn not activated on peer
exit-1 default swp7 firewall-2 BGP session with peer firewall-2 (swp7 vrf de 1d:7h:49m:31s
fault) failed, reason: Peer not configured
exit-2 DataVrf1080 swp6.2 firewall-1 BGP session with peer firewall-1 swp6.2: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-2 DataVrf1080 swp7.2 firewall-2 BGP session with peer firewall-2 (swp7.2 vrf 1d:7h:49m:26s
DataVrf1080) failed,
reason: Peer not configured
exit-2 DataVrf1081 swp6.3 firewall-1 BGP session with peer firewall-1 swp6.3: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
...
Monitor OSPF Configuration
If you have OSPF running on your switches and hosts, you can monitor its
operation using the NetQ CLI. For each device, you can view its
associated interfaces, areas, peers, state, and type of OSPF running
(numbered or unnumbered). Additionally, you can:
View the information at an earlier point in time.
Filter against a particular device, interface, or area.
Validate it is operating correctly across the network.
The netq show ospf command is used to obtain the OSPF configuration information from the devices. The netq check ospf command is used to validate the configuration. The syntax of these commands is:
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View OSPF Configuration Information
NetQ enables you to view the OSPF configuration of a single device or
across all of your devices at once. You can filter the results based on
a device, interface, or area. You can view the configuration in the past
and view changes made to the configuration within a given timeframe.
Example: View OSPF Configuration Information Across the Network
This example shows all devices included in OSPF unnumbered routing, the
assigned areas, state, peer and interface, and the last time this
information was changed.
cumulus@switch:~$ netq show ospf
Matching ospf records:
Hostname Interface Area Type State Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ------------ ---------------- ---------- ----------------- ------------------------- -------------------------
leaf01 swp51 0.0.0.0 Unnumbered Full spine01 swp1 Thu Feb 7 14:42:16 2019
leaf01 swp52 0.0.0.0 Unnumbered Full spine02 swp1 Thu Feb 7 14:42:16 2019
leaf02 swp51 0.0.0.0 Unnumbered Full spine01 swp2 Thu Feb 7 14:42:16 2019
leaf02 swp52 0.0.0.0 Unnumbered Full spine02 swp2 Thu Feb 7 14:42:16 2019
leaf03 swp51 0.0.0.0 Unnumbered Full spine01 swp3 Thu Feb 7 14:42:16 2019
leaf03 swp52 0.0.0.0 Unnumbered Full spine02 swp3 Thu Feb 7 14:42:16 2019
leaf04 swp51 0.0.0.0 Unnumbered Full spine01 swp4 Thu Feb 7 14:42:16 2019
leaf04 swp52 0.0.0.0 Unnumbered Full spine02 swp4 Thu Feb 7 14:42:16 2019
spine01 swp1 0.0.0.0 Unnumbered Full leaf01 swp51 Thu Feb 7 14:42:16 2019
spine01 swp2 0.0.0.0 Unnumbered Full leaf02 swp51 Thu Feb 7 14:42:16 2019
spine01 swp3 0.0.0.0 Unnumbered Full leaf03 swp51 Thu Feb 7 14:42:16 2019
spine01 swp4 0.0.0.0 Unnumbered Full leaf04 swp51 Thu Feb 7 14:42:16 2019
spine02 swp1 0.0.0.0 Unnumbered Full leaf01 swp52 Thu Feb 7 14:42:16 2019
spine02 swp2 0.0.0.0 Unnumbered Full leaf02 swp52 Thu Feb 7 14:42:16 2019
spine02 swp3 0.0.0.0 Unnumbered Full leaf03 swp52 Thu Feb 7 14:42:16 2019
spine02 swp4 0.0.0.0 Unnumbered Full leaf04 swp52 Thu Feb 7 14:42:16 2019
Example: View OSPF Configuration Information for a Given Device
This example show the OSPF configuration information for leaf01.
cumulus@switch:~$ netq leaf01 show ospf
Matching ospf records:
Hostname Interface Area Type State Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ------------ ---------------- ---------- ----------------- ------------------------- -------------------------
leaf01 swp51 0.0.0.0 Unnumbered Full spine01 swp1 Thu Feb 7 14:42:16 2019
leaf01 swp52 0.0.0.0 Unnumbered Full spine02 swp1 Thu Feb 7 14:42:16 2019
Example: View OSPF Configuration Information for a Given Interface
This example shows the OSPF configuration for all devices with the swp51
interface.
cumulus@switch:~$ netq show ospf swp51
Matching ospf records:
Hostname Interface Area Type State Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ------------ ---------------- ---------- ----------------- ------------------------- -------------------------
leaf01 swp51 0.0.0.0 Unnumbered Full spine01 swp1 Thu Feb 7 14:42:16 2019
leaf02 swp51 0.0.0.0 Unnumbered Full spine01 swp2 Thu Feb 7 14:42:16 2019
leaf03 swp51 0.0.0.0 Unnumbered Full spine01 swp3 Thu Feb 7 14:42:16 2019
leaf04 swp51 0.0.0.0 Unnumbered Full spine01 swp4 Thu Feb 7 14:42:16 2019
Example: View OSPF Configuration Information at a Prior Time
This example shows the OSPF configuration for all leaf switches about
five minutes ago.
cumulus@switch:~$ netq leaf* show ospf around 5m
Matching ospf records:
Hostname Interface Area Type State Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ------------ ---------------- ---------- ----------------- ------------------------- -------------------------
leaf01 swp51 0.0.0.0 Unnumbered Full spine01 swp1 Thu Feb 7 14:42:16 2019
leaf01 swp52 0.0.0.0 Unnumbered Full spine02 swp1 Thu Feb 7 14:42:16 2019
leaf02 swp51 0.0.0.0 Unnumbered Full spine01 swp2 Thu Feb 7 14:42:16 2019
leaf02 swp52 0.0.0.0 Unnumbered Full spine02 swp2 Thu Feb 7 14:42:16 2019
leaf03 swp51 0.0.0.0 Unnumbered Full spine01 swp3 Thu Feb 7 14:42:16 2019
leaf03 swp52 0.0.0.0 Unnumbered Full spine02 swp3 Thu Feb 7 14:42:16 2019
leaf04 swp51 0.0.0.0 Unnumbered Full spine01 swp4 Thu Feb 7 14:42:16 2019
leaf04 swp52 0.0.0.0 Unnumbered Full spine02 swp4 Thu Feb 7 14:42:16 2019
Validate OSPF Operation
A single command, netq check ospf, enables you to validate that all
configured route peering is established across the network. The command
checks for:
Router ID conflicts, such as duplicate IDs.
Links that are down, or have mismatched MTUs.
Mismatched session parameters (hello timer, dead timer, area IDs and network type).
When peer information is not available, the command verifies whether
OSPF is configured on the peer and if so, whether the service is
disabled, shutdown, or not functioning.
All of these conditions trigger a configuration check failure. When a
failure is found, the reason is identified in the output along with the
time the issue occurred.
This example shows a check on the OSPF operations that found no failed sessions.
cumulus@switch:~$ netq check ospf
Total Sessions: 16, Failed Sessions: 0
This example shows a check on the OSPF operations that found two failed
sessions. The results indicate the reason for the failure is a
mismatched MTU for two links.
cumulus@switch:~$ netq check ospf
Total Nodes: 21, Failed Nodes: 2, Total Sessions: 40 , Failed Sessions: 2,
Hostname Interface PeerID Peer IP Reason Last Changed
----------------- ------------------------- ------------------------- ------------------------- --------------------------------------------- -------------------------
spine03 swp6 0.0.0.23 27.0.0.23 mtu mismatch, mtu mismatch Thu Feb 7 14:42:16 2019
leaf22 swp5 0.0.0.17 27.0.0.17 mtu mismatch, mtu mismatch Thu Feb 7 14:42:16 2019
View Paths between Devices
You can view the available paths between two devices on the network
currently and at a time in the past using their IPv4 or IPv6 addresses.
You can view the output in one of three formats (json, pretty, and
detail). JSON output provides the output in a JSON file format for
ease of importing to other applications or software. Pretty output lines
up the paths in a pseudo-graphical manner to help visualize multiple
paths. Detail output is the default when not specified, and is useful
for traces with higher hop counts where the pretty output wraps lines,
making it harder to interpret the results. The detail output displays a
table with a row per hop and a set of rows per path.
To view the paths, first identify the addresses for the source and
destination devices using the netq show ip addresses command (see
syntax above), and then use the netq trace command to see the
available paths between those devices. The trace command syntax is:
The syntax requires the destination device address first, <ip>, and
then the source device address or hostname.
The tracing function only knows about addresses that have already been
learned. If you find that a path is invalid or incomplete, you may need
to ping the identified device so that its address becomes known.
View Paths between Two Switches with Pretty Output
This example first determines the IP addresses of the leaf01 and leaf03
switches, then shows the available paths between them. The results
include a summary of the trace, including the total number of paths
available, those with errors and warnings, and the MTU of the paths. In
this case, the results are displayed in pseudo-graphical output.
cumulus@switch:~$ netq leaf01 show ip addresses
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
10.0.0.11/32 leaf01 lo default Fri Feb 8 01:35:49 2019
10.0.0.11/32 leaf01 swp51 default Fri Feb 8 01:35:49 2019
10.0.0.11/32 leaf01 swp52 default Fri Feb 8 01:35:49 2019
172.16.1.1/24 leaf01 br0 default Fri Feb 8 01:35:49 2019
192.168.0.11/24 leaf01 eth0 default Fri Feb 8 01:35:49 2019
cumulus@switch:~$ netq leaf03 show ip addresses
Matching address records:
Address Hostname Interface VRF Last Changed
------------------------- ----------------- ------------------------- --------------- -------------------------
10.0.0.13/32 leaf03 lo default Thu Feb 7 18:31:29 2019
10.0.0.13/32 leaf03 swp51 default Thu Feb 7 18:31:29 2019
10.0.0.13/32 leaf03 swp52 default Thu Feb 7 18:31:29 2019
172.16.3.1/24 leaf03 br0 default Thu Feb 7 18:31:29 2019
192.168.0.13/24 leaf03 eth0 default Thu Feb 7 18:31:29 2019
cumulus@switch:~$ netq trace 10.0.0.13 from 10.0.0.11 pretty
Number of Paths: 2
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Path MTU: 1500
leaf01 swp52 -- swp1 spine02 swp3 -- swp52 leaf03 <lo>
swp51 -- swp1 spine01 swp3 -- swp51 leaf03 <lo>
View Paths between Two Switches with Detailed Output
This example provides the same path information as the pretty output,
but displays the information in a tabular output. In this case there, no
VLAN is configured, so the related fields are left blank.
cumulus@switch:~$ netq trace 10.0.0.13 from 10.0.0.11 detail
Number of Paths: 2
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Path MTU: 1500
Id Hop Hostname InPort InVlan InTunnel InRtrIf InVRF OutRtrIf OutVRF OutTunnel OutPort OutVlan
--- --- --------------- --------------- ------ --------------------- --------------- --------------- --------------- --------------- --------------------- --------------- -------
1 1 leaf01 swp52 default swp52
2 spine02 swp1 swp1 default swp3 default swp3
3 leaf03 swp52 swp52 default lo
--- --- --------------- --------------- ------ --------------------- --------------- --------------- --------------- --------------- --------------------- --------------- -------
2 1 leaf01 swp51 default swp51
2 spine01 swp1 swp1 default swp3 default swp3
3 leaf03 swp51 swp51 default lo
--- --- --------------- --------------- ------ --------------------- --------------- --------------- --------------- --------------- --------------------- --------------- -------
View Paths between Two Switches with Drops Detected
If you have a Mellanox switch, the What Just Happened feature detects various drop statistics. These are visible in the results of trace requests. This example shows the available paths between a switch with IP address 6.0.2.66 and a switch with IP address 6.0.2.70, where drops have been detected on path 1.
cumulus@mlx-2700:~$ netq trace 6.0.2.66 from 6.0.2.70
Number of Paths: 1
Number of Paths with Errors: 0
Number of Paths with Warnings: 0
Top packet drops along the paths in the last hour:
Path: 1 at mlx-2700:swp3s1, type: L2, reason: Source MAC equals destination MAC, flow: src_ip: 6.0.2.70, dst_ip: 6.0.2.66, protocol: 0, src_port: 0, dst_port: 0
Path MTU: 9152
Id Hop Hostname InPort InTun, RtrIf OutRtrIf, Tun OutPort
--- --- ----------- --------------- --------------- --------------- ---------------
1 1 hosts-11 swp1.1008
2 mlx-2700-03 swp3s1
--- --- ----------- --------------- --------------- --------------- ---------------
Monitor Virtual Network Overlays
With NetQ, a network administrator can monitor virtual network components in the data center, including VXLAN and EVPN software constructs. NetQ provides the ability to:
Manage virtual constructs: view the performance and status of VXLANs and EVPN
Validate overlay communication paths
It helps answer questions such as:
Is my overlay configured and operating correctly?
Is my control plane configured correctly?
Can device A reach device B?
Monitor Virtual Extensible LANs
Virtual Extensible LANs (VXLANs) provide a way to create a virtual
network on top of layer 2 and layer 3 technologies. It is intended for
organizations, such as data centers, that require larger scale without
additional infrastructure and more flexibility than is available with
existing infrastructure equipment. With NetQ, you can monitor the
current and historical configuration and status of your VXLANs using the
following command:
netq [<hostname>] show vxlan [vni <text-vni>] [around <text-time>] [json]
netq show interfaces type vxlan [state <remote-interface-state>] [around <text-time>] [json]
netq <hostname> show interfaces type vxlan [state <remote-interface-state>] [around <text-time>] [count] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type vxlan [between <text-time> and <text-endtime>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
View All VXLANs in Your Network
You can view a list of configured VXLANs for all devices, including the
VNI (VXLAN network identifier), protocol, address of associated VTEPs
(VXLAN tunnel endpoint), replication list, and the last time it was
changed. You can also view VXLAN information for a given device by
adding a hostname to the show command. You can filter the results by
VNI.
This example shows all configured VXLANs across the network. In this
network, there are three VNIs (13, 24, and 104001) associated with three
VLANs (13, 24, 4001), EVPN is the virtual protocol deployed, and the
configuration was last changed around 23 hours ago.
cumulus@switch:~$ netq show vxlan
Matching vxlan records:
Hostname VNI Protoc VTEP IP VLAN Replication List Last Changed
ol
----------------- ---------- ------ ---------------- ------ ----------------------------------- -------------------------
exit01 104001 EVPN 10.0.0.41 4001 Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Fri Feb 8 01:35:49 2019
leaf01 13 EVPN 10.0.0.112 13 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf01 24 EVPN 10.0.0.112 24 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf01 104001 EVPN 10.0.0.112 4001 Fri Feb 8 01:35:49 2019
leaf02 13 EVPN 10.0.0.112 13 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf02 24 EVPN 10.0.0.112 24 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf02 104001 EVPN 10.0.0.112 4001 Fri Feb 8 01:35:49 2019
leaf03 13 EVPN 10.0.0.134 13 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
leaf03 24 EVPN 10.0.0.134 24 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
leaf03 104001 EVPN 10.0.0.134 4001 Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
leaf04 24 EVPN 10.0.0.134 24 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Fri Feb 8 01:35:49 2019
This example shows the events and configuration changes that have
occurred on the VXLANs in your network in the last 24 hours. In this
case, the EVPN configuration was added to each of the devices in the
last 24 hours.
cumulus@switch:~$ netq show events type vxlan between now and 24h
Matching vxlan records:
Hostname VNI Protoc VTEP IP VLAN Replication List DB State Last Changed
ol
----------------- ---------- ------ ---------------- ------ ----------------------------------- ---------- -------------------------
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit02 104001 EVPN 10.0.0.42 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
exit01 104001 EVPN 10.0.0.41 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 104001 EVPN 10.0.0.134 4001 Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
leaf04 13 EVPN 10.0.0.134 13 10.0.0.112() Add Fri Feb 8 01:35:49 2019
...
Consequently, if you looked for the VXLAN configuration and status for
last week, you would find either another configuration or no
configuration. This example shows that no VXLAN configuration was
present.
cumulus@switch:~$ netq show vxlan around 7d
No matching vxlan records found
You can filter the list of VXLANs to view only those associated with a
particular VNI. The VNI option lets you specify single VNI (100), a range of VNIs (10-100), or provide a comma-separated list (10,11,12). This example shows the configured VXLANs for VNI 24.
cumulus@switch:~$ netq show vxlan vni 24
Matching vxlan records:
Hostname VNI Protoc VTEP IP VLAN Replication List Last Changed
ol
----------------- ---------- ------ ---------------- ------ ----------------------------------- -------------------------
leaf01 24 EVPN 10.0.0.112 24 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf02 24 EVPN 10.0.0.112 24 10.0.0.134(leaf04, leaf03) Fri Feb 8 01:35:49 2019
leaf03 24 EVPN 10.0.0.134 24 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
leaf04 24 EVPN 10.0.0.134 24 10.0.0.112(leaf02, leaf01) Fri Feb 8 01:35:49 2019
View the Interfaces Associated with VXLANs
You can view detailed information about the VXLAN interfaces using the
netq show interface command. You can also view this information for a
given device by adding a hostname to the show command. This example
shows the detailed VXLAN interface information for the leaf02 switch.
cumulus@switch:~$ netq leaf02 show interfaces type vxlan
Matching link records:
Hostname Interface Type State VRF Details Last Changed
----------------- ------------------------- ---------------- ---------- --------------- ----------------------------------- -------------------------
leaf02 vni13 vxlan up default VNI: 13, PVID: 13, Master: bridge, Fri Feb 8 01:35:49 2019
VTEP: 10.0.0.112, MTU: 9000
leaf02 vni24 vxlan up default VNI: 24, PVID: 24, Master: bridge, Fri Feb 8 01:35:49 2019
VTEP: 10.0.0.112, MTU: 9000
leaf02 vxlan4001 vxlan up default VNI: 104001, PVID: 4001, Fri Feb 8 01:35:49 2019
Master: bridge, VTEP: 10.0.0.112,
MTU: 1500
Monitor EVPN
EVPN (Ethernet Virtual Private Network) enables network administrators
in the data center to deploy a virtual layer 2 bridge overlay on top of
layer 3 IP networks creating access, or tunnel, between two locations.
This connects devices in different layer 2 domains or sites running
VXLANs and their associated underlays. With NetQ, you can monitor the
configuration and status of the EVPN setup using the netq show evpn
command. You can filter the EVPN information by a VNI (VXLAN network
identifier), and view the current information or for a time in the past.
The command also enables visibility into changes that have occurred in
the configuration during a specific timeframe. The syntax for the
command is:
netq [<hostname>] show evpn [vni <text-vni>] [mac-consistency] [around <text-time>] [json]
netq [<hostname>] show events [level info|level error|level warning|level critical|level debug] type evpn [between <text-time> and <text-endtime>] [json]
When entering a time value, you must include a numeric value and the unit of measure:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
For the between option, the start (<text-time>) and end time (text-endtime>) values can be entered as most recent first and least recent second, or vice versa. The values do not have to have the same unit of measure.
For more information about and configuration of EVPN in your data center, refer to the Cumulus Linux EVPN topic.
View the Status of EVPN
You can view the configuration and status of your EVPN overlay across
your network or for a particular device. This example shows the
configuration and status for all devices, including the associated VNI,
VTEP address, the import and export route (showing the BGP ASN and VNI
path), and the last time a change was made for each device running EVPN.
Use the hostname option to view the configuration and status for a
single device.
You can filter the full device view to focus on a single VNI. This
example only shows the EVPN configuration and status for VNI 42.
cumulus@switch:~$ netq show evpn vni 42
Matching evpn records:
Hostname VNI VTEP IP In Kernel Export RT Import RT Last Changed
----------------- ---------- ---------------- --------- ---------------- ---------------- -------------------------
leaf01 42 27.0.0.22 yes 197:42 197:42 Thu Feb 14 00:48:24 2019
leaf02 42 27.0.0.23 yes 198:42 198:42 Wed Feb 13 18:14:49 2019
leaf11 42 36.0.0.24 yes 199:42 199:42 Wed Feb 13 18:14:22 2019
leaf12 42 36.0.0.24 yes 200:42 200:42 Wed Feb 13 18:14:27 2019
leaf21 42 36.0.0.26 yes 201:42 201:42 Wed Feb 13 18:14:33 2019
leaf22 42 36.0.0.26 yes 202:42 202:42 Wed Feb 13 18:14:37 2019
View EVPN Events
You can view status and configuration change events for the EVPN
protocol service using the netq show events command. This example
shows the events that have occurred in the last 48 hours.
cumulus@switch:/$ netq show events type evpn between now and 48h
Matching events records:
Hostname Message Type Severity Message Timestamp
----------------- ------------ -------- ----------------------------------- -------------------------
torc-21 evpn info VNI 33 state changed from down to u 1d:8h:16m:29s
p
torc-12 evpn info VNI 41 state changed from down to u 1d:8h:16m:35s
p
torc-11 evpn info VNI 39 state changed from down to u 1d:8h:16m:41s
p
tor-1 evpn info VNI 37 state changed from down to u 1d:8h:16m:47s
p
tor-2 evpn info VNI 42 state changed from down to u 1d:8h:16m:51s
p
torc-22 evpn info VNI 39 state changed from down to u 1d:8h:17m:40s
p
...
Monitor Linux Hosts
Running NetQ on Linux hosts provides unprecedented network visibility,
giving the network operator a complete view of the entire
infrastructure’s network connectivity instead of just from the network
devices.
The NetQ Agent is supported on the following Linux hosts:
Using NetQ on a Linux host is the same as using it on a Cumulus Linux
switch. For example, if you want to check LLDP neighbor information
about a given host, run:
cumulus@switch:~$ netq server01 show lldp
Matching lldp records:
Hostname Interface Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ----------------- ------------------------- -------------------------
server01 eth0 oob-mgmt-switch swp2 Fri Feb 8 01:50:59 2019
server01 eth1 leaf01 swp1 Fri Feb 8 01:50:59 2019
server01 eth2 leaf02 swp1 Fri Feb 8 01:50:59 2019
Then, to see LLDP from the switch’s perspective:
cumulus@switch:~$ netq leaf01 show lldp
Matching lldp records:
Hostname Interface Peer Hostname Peer Interface Last Changed
----------------- ------------------------- ----------------- ------------------------- -------------------------
leaf01 eth0 oob-mgmt-switch swp6 Thu Feb 7 18:31:26 2019
leaf01 swp1 server01 eth1 Thu Feb 7 18:31:26 2019
leaf01 swp2 server02 eth1 Thu Feb 7 18:31:26 2019
leaf01 swp49 leaf02 swp49 Thu Feb 7 18:31:26 2019
leaf01 swp50 leaf02 swp50 Thu Feb 7 18:31:26 2019
leaf01 swp51 spine01 swp1 Thu Feb 7 18:31:26 2019
leaf01 swp52 spine02 swp1 Thu Feb 7 18:31:26 2019
To get the routing table for a server:
cumulus@server01:~$ netq server01 show ip route
Matching routes records:
Origin VRF Prefix Hostname Nexthops Last Changed
------ --------------- ------------------------------ ----------------- ----------------------------------- -------------------------
no default 10.2.4.0/24 server01 10.1.3.1: uplink Fri Feb 8 01:50:49 2019
no default 172.16.1.0/24 server01 10.1.3.1: uplink Fri Feb 8 01:50:49 2019
yes default 10.1.3.0/24 server01 uplink Fri Feb 8 01:50:49 2019
yes default 10.1.3.101/32 server01 uplink Fri Feb 8 01:50:49 2019
yes default 192.168.0.0/24 server01 eth0 Fri Feb 8 01:50:49 2019
yes default 192.168.0.31/32 server01 eth0 Fri Feb 8 01:50:49 2019
Monitor Container Environments Using Kubernetes API Server
The NetQ Agent monitors many aspects of containers on your network by integrating with the Kubernetes API server. In particular, the NetQ Agent tracks:
Identity: Every container’s IP and MAC address, name, image, and more. NetQ can locate containers across the fabric based on a container’s name, image, IP or MAC address, and protocol and port pair.
Port mapping on a network: Protocol and ports exposed by a container. NetQ can identify containers exposing a specific protocol and port pair on a network.
Connectivity: Information about network connectivity for a container, including adjacency, and can identify containers that can be affected by a top of rack switch.
This topic assumes a reasonable familiarity with Kubernetes terminology and architecture.
Use NetQ with Kubernetes Clusters
The NetQ Agent interfaces with the Kubernetes API server and listens to Kubernetes events. The NetQ Agent monitors network identity and physical network connectivity of Kubernetes resources like Pods, Daemon sets, Service, and so forth. NetQ works with any container network interface (CNI), such as Calico or Flannel.
The NetQ Kubernetes integration enables network administrators to:
Identify and locate pods, deployment, replica-set and services deployed within the network using IP, name, label, and so forth.
Track network connectivity of all pods of a service, deployment and replica set.
Locate what pods have been deployed adjacent to a top of rack (ToR) switch.
Check what pod, services, replica set or deployment can be impacted by a specific ToR switch.
NetQ also helps network administrators identify changes within a Kubernetes cluster and determine if such changes had an adverse effect on the network performance (caused by a noisy neighbor for example). Additionally, NetQ helps the infrastructure administrator determine how Kubernetes workloads are distributed within a network.
Requirements
The NetQ Agent supports Kubernetes version 1.9.2 or later.
Command Summary
There is a large set of commands available to monitor Kubernetes configurations, including the ability to monitor clusters, nodes, daemon-set, deployment, pods, replication, and services. Run netq show kubernetes help to see all the possible commands.
After waiting for a minute, run the show command to view the cluster.
cumulus@host:~$netq show kubernetes cluster
Next, you must enable the NetQ Agent on all of the worker nodes for complete insight into your container network. Repeat steps 2 and 3 on each worker node.
View Status of Kubernetes Clusters
Run the netq show kubernetes cluster command to view the status of all Kubernetes clusters in the fabric. In this example, we see there are two clusters; one with server11 as the master server and the other with server12 as the master server. Both are healthy and their associated worker nodes are listed.
cumulus@host:~$ netq show kubernetes cluster
Matching kube_cluster records:
Master Cluster Name Controller Status Scheduler Status Nodes
------------------------ ---------------- -------------------- ---------------- --------------------
server11:3.0.0.68 default Healthy Healthy server11 server13 se
rver22 server11 serv
er12 server23 server
24
server12:3.0.0.69 default Healthy Healthy server12 server21 se
rver23 server13 serv
er14 server21 server
22
For deployments with multiple clusters, you can use the hostname option to filter the output. This example shows filtering of the list by server11:
cumulus@host:~$ netq server11 show kubernetes cluster
Matching kube_cluster records:
Master Cluster Name Controller Status Scheduler Status Nodes
------------------------ ---------------- -------------------- ---------------- --------------------
server11:3.0.0.68 default Healthy Healthy server11 server13 se
rver22 server11 serv
er12 server23 server
24
Optionally, use the json option to present the results in JSON format.
If data collection from the NetQ Agents is not occurring as it once was, you can verify that no changes have been made to the Kubernetes cluster configuration using the around option. Be sure to include the unit of measure with the around value. Valid units include:
w: week(s)
d: day(s)
h: hour(s)
m: minute(s)
s: second(s)
now
This example shows changes that have been made to the cluster in the last hour. In this example we see the addition of the two master nodes and the various worker nodes for each cluster.
cumulus@host:~$ netq show kubernetes cluster around 1h
Matching kube_cluster records:
Master Cluster Name Controller Status Scheduler Status Nodes DBState Last changed
------------------------ ---------------- -------------------- ---------------- ---------------------------------------- -------- -------------------------
server11:3.0.0.68 default Healthy Healthy server11 server13 server22 server11 serv Add Fri Feb 8 01:50:50 2019
er12 server23 server24
server12:3.0.0.69 default Healthy Healthy server12 server21 server23 server13 serv Add Fri Feb 8 01:50:50 2019
er14 server21 server22
server12:3.0.0.69 default Healthy Healthy server12 server21 server23 server13 Add Fri Feb 8 01:50:50 2019
server11:3.0.0.68 default Healthy Healthy server11 Add Fri Feb 8 01:50:50 2019
server12:3.0.0.69 default Healthy Healthy server12 Add Fri Feb 8 01:50:50 2019
View Kubernetes Pod Information
You can show configuration and status of the pods in a cluster, including the names, labels, addresses, associated cluster and containers, and whether the pod is running. This example shows pods for FRR, Nginx, Calico, and various Kubernetes components sorted by master node.
You can view detailed information about a node, including their role in the cluster, pod CIDR and kubelet status. This example shows all of the nodes in the cluster with server11 as the master. Note that server11 acts as a worker node along with the other nodes in the cluster, server12, server13, server22, server23, and server24.
To display the kubelet or Docker version, use the components option with the show command. This example lists the kublet version, a proxy address if used, and the status of the container for server11 master and worker nodes.
To view only the details for a selected node, the name option with the hostname of that node following the components option:
cumulus@host:~$ netq server11 show kubernetes node components name server13
Matching kube_cluster records:
Master Cluster Name Node Name Kubelet KubeProxy Container Runt
ime
------------------------ ---------------- -------------------- ------------ ------------ ----------------- --------------
server11:3.0.0.68 default server13 v1.9.2 v1.9.2 docker://17.3.2 KubeletReady
View Kubernetes Replica Set on a Node
You can view information about the replica set, including the name, labels, and number of replicas present for each application. This example shows the number of replicas for each application in the server11 cluster:
You can view information about the daemon set running on the node. This example shows that six copies of the cumulus-frr daemon are running on the server11 node:
cumulus@host:~$ netq server11 show kubernetes daemon-set namespace default
Matching kube_daemonset records:
Master Cluster Name Namespace Daemon Set Name Labels Desired Count Ready Count Last Changed
------------------------ ------------ ---------------- ------------------------------ -------------------- ------------- ----------- ----------------
server11:3.0.0.68 default default cumulus-frr k8s-app:cumulus-frr 6 6 14h:25m:37s
View Pods on a Node
You can view information about the pods on the node. The first example shows all pods running nginx in the default namespace for the server11 cluster. The second example shows all pods running any application in the default namespace for the server11 cluster.
cumulus@host:~$ netq server11 show kubernetes pod namespace default label nginx
Matching kube_pod records:
Master Namespace Name IP Node Labels Status Containers Last Changed
------------------------ ------------ -------------------- ---------------- ------------ -------------------- -------- ------------------------ ----------------
server11:3.0.0.68 default nginx-8586cf59-26pj5 10.244.9.193 server24 run:nginx Running nginx:6e2b65070c86 14h:25m:24s
server11:3.0.0.68 default nginx-8586cf59-c82ns 10.244.40.128 server12 run:nginx Running nginx:01b017c26725 14h:25m:24s
server11:3.0.0.68 default nginx-8586cf59-wjwgp 10.244.49.64 server22 run:nginx Running nginx:ed2b4254e328 14h:25m:24s
cumulus@host:~$ netq server11 show kubernetes pod namespace default label app
Matching kube_pod records:
Master Namespace Name IP Node Labels Status Containers Last Changed
------------------------ ------------ -------------------- ---------------- ------------ -------------------- -------- ------------------------ ----------------
server11:3.0.0.68 default httpd-5456469bfd-bq9 10.244.49.65 server22 app:httpd Running httpd:79b7f532be2d 14h:20m:34s
zm
server11:3.0.0.68 default influxdb-6cdb566dd-8 10.244.162.128 server13 app:influx Running influxdb:15dce703cdec 14h:20m:34s
9lwn
View Status of the Replication Controller on a Node
When replicas have been created, you are then able to view information about the replication controller:
cumulus@host:~$ netq server11 show kubernetes replication-controller
No matching kube_replica records found
View Kubernetes Deployment Information
For each depolyment, you can view the number of replicas associated with an application. this example shows information for a deployment of the nginx application:
cumulus@host:~$ netq server11 show kubernetes deployment name nginx
Matching kube_deployment records:
Master Namespace Name Replicas Ready Replicas Labels Last Changed
------------------------ --------------- -------------------- ---------------------------------- -------------- ------------------------------ ----------------
server11:3.0.0.68 default nginx 3 3 run:nginx 14h:27m:20s
Search Using Labels
You can search for information about your Kubernetes clusters using labels. A label search is similar to a “contains” regular expression search. In the following example, we are looking for all nodes that contain kube in the replication set name or label:
You can view the connectivity graph of a Kubernetes pod, seeing its replica set, deployment or service level. The connectivity graph starts with the server where the pod is deployed, and shows the peer for each server interface. This data is displayed in a similar manner as the netq trace command, showing the interface name, the outbound port on that interface, and the inbound port on the peer.
In this example shows connectivity at the deployment level, where the nginx-8586cf59-wjwgp replica is in a pod on the server22 node. It has four possible commumication paths, through interfaces swp1-4 out varying ports to peer interfaces swp7 and swp20 on torc-21, torc-22, edge01 and edge02 nodes. Similarly, the connections are shown for two additional nginx replicas.
You can show details about the Kubernetes services in a cluster, including service name, labels associated with the service, type of service, associated IP address, an external address if a public service, and ports used. This example show the services available in the Kubernetes cluster:
You can filter the list to view details about a particular Kubernetes service using the name option, as shown here:
cumulus@host:~$ netq show kubernetes service name calico-etcd
Matching kube_service records:
Master Namespace Service Name Labels Type Cluster IP External IP Ports Last Changed
------------------------ ---------------- -------------------- ------------ ---------- ---------------- ---------------- ----------------------------------- ----------------
server11:3.0.0.68 kube-system calico-etcd k8s-app:cali ClusterIP 10.96.232.136 TCP:6666 2d:13h:48m:10s
co-etcd
server12:3.0.0.69 kube-system calico-etcd k8s-app:cali ClusterIP 10.96.232.136 TCP:6666 2d:13h:49m:3s
co-etcd
View Kubernetes Service Connectivity
To see the connectivity of a given Kubernetes service, include the connectivity option. This example shows the connectivity of the calico-etcd service:
View the Impact of Connectivity Loss for a Service
You can preview the impact on the service availabilty based on the loss of particular node using the impact option. The output is color coded (not shown in the example below) so you can clearly see the impact: green shows no impact, yellow shows partial impact, and red shows full impact.
cumulus@host:~$ netq server11 show impact kubernetes service name calico-etcd
calico-etcd -- calico-etcd-pfg9r -- server11:swp1:torbond1 -- swp6:hostbond2:torc-11
-- server11:swp2:torbond1 -- swp6:hostbond2:torc-12
-- server11:swp3:NetQBond-2 -- swp16:NetQBond-16:edge01
-- server11:swp4:NetQBond-2 -- swp16:NetQBond-16:edge02
View Kubernetes Cluster Configuration in the Past
You can use the "time machine" features of NetQ on a Kubernetes cluster, using the around option to go back in time to check the network status and identify any changes that occurred on the network.
This example shows the current state of the network. Notice there is a node named server23. server23 is there because the node server22 went down and Kubernetes spun up a third replica on a different host to satisfy the deployment requirement.
View the Impact of Connectivity Loss for a Deployment
You can determine the impact on the Kubernetes deployment in the event a host or switch goes down. The output is color coded (not shown in the example below) so you can clearly see the impact: green shows no impact, yellow shows partial impact, and red shows full impact.
At various points in time, you might want to change which network nodes are being monitored by NetQ or look more closely at a network node for troubleshooting purposes. Adding the NetQ Agent to a switch or host is described in Install NetQ. Viewing the status of an Agent, disabling an Agent, and managing NetQ Agent logging are presented.
View NetQ Agent Status
To view the health of your NetQ Agents, use the netq show agents command:
netq [<hostname>] show agents [fresh | dead | rotten | opta] [around <text-time>] [json]
You can view the status for a given switch, host or NetQ server. You can also filter by the status as well as view the status at a time in the past.
This example shows how to prevent the agent from consuming no more than 40% of
CPU resources on a Cumulus Linux switch. This setting requires Cumulus Linux
versions 3.7.12 or later and 4.1.0 or later to be running on the switch.
netq config add agent cpu-limit 40
After making configuration changes to your agents, you must restart the
agent for the changes to take effect. Use the netq config restart agent
command.
Disable the NetQ Agent on a Node
You can temporarily disable NetQ Agent on a node. Disabling the agent
maintains the activity history in the NetQ database.
To disable NetQ Agent on a node, run the following command from the
node:
cumulus@switch:~$ netq config stop agent
Remove the NetQ Agent from a Node
You can decommission a NetQ Agent on a given node. You might need to do
this when you:
RMA the switch or host being monitored
Change the hostname of the switch or host being monitored
Move the switch or host being monitored from one data center to
another
Decommissioning the node removes the agent server settings from the
local configuration file.
To decommission a node from the NetQ database:
On the given node, stop and disable the NetQ Agent service.
The logging level used for a NetQ Agent determines what types of events
are logged about the NetQ Agent on the switch or host.
First, you need to decide what level of
logging you want to configure. You can configure the logging level to be
the same for every NetQ Agent, or selectively increase or decrease the
logging level for a NetQ Agent on a problematic node.
Logging Level
Description
debug
Sends notifications for all debugging-related, informational, warning, and error messages.
info
Sends notifications for informational, warning, and error messages (default).
warning
Sends notifications for warning and error messages.
error
Sends notifications for errors messages.
You can view the NetQ Agent log directly. Messages have the following
structure:
If you have set the logging level to
debug for troubleshooting, it is recommended that you either change
the logging level to a less heavy mode or completely disable agent
logging altogether when you are finished troubleshooting.
To change the logging level, run the
following command and restart the agent service:
The NetQ Agent contains a pre-configured set of modular commands that run periodically and send event and resource data to the NetQ appliance or VM. You can fine tune which events the agent can poll and vary frequency of polling.
For example, if your network is not running OSPF, you can disable the command that polls for OSPF events. Or you can decrease the polling interval for LLDP from the default of 60 seconds to 120 seconds. This way you can reduce agent CPU usage due to less frequent polling.
In addition, depending on the switch platform, some supported protocol commands may not be executed by the agent. For example, if a switch has no VXLAN capability, then all VXLAN-related commands get skipped by agent.
You cannot create new commands in this release.
Supported Commands
To see the list of supported modular commands, run:
The NetQ predefined commands are described as follows:
agent_stats: Collects the NetQ agent’s statistics every 5 minutes.
agent_util_stats: Collects the NetQ agent’s CPU and memory utilization every 30 seconds.
cl-support-json: Polls the switch every 3 minutes to determine if a cl-support file was generated.
config-mon-json: Polls the /etc/network/interfaces, /etc/frr/frr.conf, /etc/lldpd.d/README.conf and /etc/ptm.d/topology.dot files every 2 minutes looking to see if the contents of any of these files changes. If a change occurs, the contents of the file and its modification time are transmitted to the NetQ appliance or VM.
ports: Polls for optics plugged into the switch every hour.
proc-net-dev: Polls for network statistics on the switch every 30 seconds.
running-config-mon-json: Polls the clagctl parameters every 30 seconds and sends a diff of any changes to the NetQ appliance or VM.
Modify the Polling Frequency
You can change the polling frequency of a modular command. The frequency is specified in seconds. For example, to change the polling frequency of the lldp-json command to 60 seconds, run:
You can disable any of these commands if they are not needed on your network. This can help reduce the compute resources the agent consumes. For example, if your network does not run OSPF, you can disable the two OSPF commands:
Monitoring of systems inevitably leads to the need to troubleshoot and
resolve the issues found. In fact network management follows a common
pattern as shown in this diagram.
This topic describes some of the tools and commands you can use to
troubleshoot issues with the network and NetQ itself. Some example scenarios are included here:
Try looking at the specific protocol or service, or particular devices as well. If none of these produce a resolution, you can capture a log to use in discussion with the Cumulus Networks support team.
Browse Configuration and Log Files
To aid in troubleshooting issues with NetQ, there are the following
configuration and log files that can provide insight into the root cause
of the issue:
File
Description
/etc/netq/netq.yml
The NetQ configuration file. This file appears only if you installed either the netq-apps package or the NetQ Agent on the system.
/var/log/netqd.log
The NetQ daemon log file for the NetQ CLI. This log file appears only if you installed the netq-apps package on the system.
/var/log/netq-agent.log
The NetQ Agent log file. This log file appears only if you installed the NetQ Agent on the system.
Check NetQ Agent Health
Checking the health of the NetQ Agents is a good way to start
troubleshooting NetQ on your network. If any agents are rotten, meaning
three heartbeats in a row were not sent, then you can investigate the
rotten node. In the example below, the NetQ Agent on server01 is rotten,
so you know where to start looking for problems:
cumulus@switch:$ netq check agents
Checked nodes: 12,
Rotten nodes: 1
netq@446c0319c06a:/$ netq show agents
Node Status Sys Uptime Agent Uptime
-------- -------- ------------ --------------
exit01
Fresh
8h ago 4h ago
exit02
Fresh
8h ago 4h ago
leaf01
Fresh
8h ago 4h ago
leaf02
Fresh
8h ago 4h ago
leaf03
Fresh
8h ago 4h ago
leaf04
Fresh
8h ago 4h ago
server01
Rotten
4h ago 4h ago
server02
Fresh
4h ago 4h ago
server03
Fresh
4h ago 4h ago
server04
Fresh
4h ago 4h ago
spine01
Fresh
8h ago 4h ago
spine02
Fresh
8h ago 4h ago
Diagnose an Event after It Occurs
NetQ provides users with the ability to go back in time to replay the
network state, see fabric-wide event change logs and root cause state
deviations. The NetQ Telemetry Server maintains data collected by NetQ
agents in a time-series database, making fabric-wide events available
for analysis. This enables you to replay and analyze network-wide events
for better visibility and to correlate patterns. This allows for
root-cause analysis and optimization of network configs for the future.
NetQ provides a number of commands for diagnosing past events.
NetQ records network events and stores them in its database. You can
view the events through a third-party notification application like
PagerDuty or Slack or use netq show events to look for any changes
made to the runtime configuration that may have triggered the alert,
then use netq trace to track the connection between the nodes.
The netq trace command traces the route of an IP or MAC address from
one endpoint to another. It works across bridged, routed and VXLAN
connections, computing the path using available data instead of sending
real traffic - this way, it can be run from anywhere. It performs MTU
and VLAN consistency checks for every link along the path.
For example, say you get an alert about a BGP session failure. You can
quickly run netq check bgp to determine what sessions failed:
cumulus@switch:~$ netq check bgp
Total Nodes: 25, Failed Nodes: 3, Total Sessions: 220 , Failed Sessions: 24,
Hostname VRF Peer Name Peer Hostname Reason Last Changed
----------------- --------------- ----------------- ----------------- --------------------------------------------- -------------------------
exit-1 DataVrf1080 swp6.2 firewall-1 BGP session with peer firewall-1 swp6.2: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-1 DataVrf1080 swp7.2 firewall-2 BGP session with peer firewall-2 (swp7.2 vrf 1d:7h:49m:31s
DataVrf1080) failed,
reason: Peer not configured
exit-1 DataVrf1081 swp6.3 firewall-1 BGP session with peer firewall-1 swp6.3: AFI/ 1d:7h:56m:9s
SAFI evpn not activated on peer
exit-1 DataVrf1081 swp7.3 firewall-2 BGP session with peer firewall-2 (swp7.3 vrf 1d:7h:49m:31s
DataVrf1081) failed,
reason: Peer not configured
You can run a trace from spine01 to leaf02, which has the IP address
10.1.20.252:
cumulus@switch:~$ netq trace 10.1.20.252 from spine01 around 5m
spine01 -- spine01:swp1 -- leaf01:vlan20
-- spine01:swp2 -- leaf02:vlan20
Then you can check what’s changed on the network to help you identify
the problem.
cumulus@switch:~$ netq show events type bgp
Matching events records:
Hostname Message Type Severity Message Timestamp
----------------- ------------ -------- ----------------------------------- -------------------------
leaf21 bgp info BGP session with peer spine-1 swp3. 1d:8h:35m:19s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf21 bgp info BGP session with peer spine-2 swp4. 1d:8h:35m:19s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf21 bgp info BGP session with peer spine-3 swp5. 1d:8h:35m:19s
3 vrf DataVrf1081 state changed fro
m failed to Established
leaf21 bgp info BGP session with peer spine-1 swp3. 1d:8h:35m:19s
2 vrf DataVrf1080 state changed fro
m failed to Established
leaf21 bgp info BGP session with peer spine-3 swp5. 1d:8h:35m:19s
2 vrf DataVrf1080 state changed fro
m failed to Established
...
Use NetQ as a Time Machine
With NetQ, you can travel back to a specific point in time or a range of
times to help you isolate errors and issues.
For example, if you think you had an issue with your sensors last night,
you can check the sensors on all your nodes around the time you think
the issue occurred:
cumulus@leaf01:~$ netq check sensors around 12h
Total Nodes: 25, Failed Nodes: 0, Checked Sensors: 221, Failed Sensors: 0
Or you can specify a range of times using the between option. The
units of time you can specify are second (s), minutes (m), hours
(h) and days (d). Always specify the most recent time first, then
the more distant time. For example, to see the changes made to the
network between the past minute and 5 minutes ago, you’d run:
cumulus@switch:/$ netq show events between now and 48h
Matching events records:
Hostname Message Type Severity Message Timestamp
----------------- ------------ -------- ----------------------------------- -------------------------
leaf21 configdiff info leaf21 config file ptm was modified 1d:8h:38m:6s
leaf21 configdiff info leaf21 config file lldpd was modifi 1d:8h:38m:6s
ed
leaf21 configdiff info leaf21 config file interfaces was m 1d:8h:38m:6s
odified
leaf21 configdiff info leaf21 config file frr was modified 1d:8h:38m:6s
leaf12 configdiff info leaf12 config file ptm was modified 1d:8h:38m:11s
leaf12 configdiff info leaf12 config file lldpd was modifi 1d:8h:38m:11s
ed
leaf12 configdiff info leaf12 config file interfaces was m 1d:8h:38m:11s
odified
leaf12 configdiff info leaf12 config file frr was modified 1d:8h:38m:11s
leaf11 configdiff info leaf11 config file ptm was modified 1d:8h:38m:22s
...
You can travel back in time 5 minutes and run a trace from spine02 to
exit01, which has the IP address 27.0.0.1:
cumulus@leaf01:~$ netq trace 27.0.0.1 from spine02 around 5m
Detected Routing Loop. Node exit01 (now via Local Node exit01 and Ports swp6 <==> Remote Node/s spine01 and Ports swp3) visited twice.
Detected Routing Loop. Node spine02 (now via mac:00:02:00:00:00:15) visited twice.
spine02 -- spine02:swp3 -- exit01:swp6.4 -- exit01:swp3 -- exit01
-- spine02:swp7 -- spine02
Trace Paths in a VRF
The netq trace command works with VRFs as well:
cumulus@leaf01:~$ netq trace 10.1.20.252 from spine01 vrf default around 5m
spine01 -- spine01:swp1 -- leaf01:vlan20
-- spine01:swp2 -- leaf02:vlan20
Generate a Support File
The opta-support command generates an archive of useful information
for troubleshooting issues with NetQ. It is an extension of the
cl-support command in Cumulus Linux. It provides information about the
NetQ Platform configuration and runtime statistics as well as output
from the docker ps command. The Cumulus Networks support team may
request the output of this command when assisting with any issues that
you could not solve with your own troubleshooting. Run the following
command:
cumulus@switch:~$ opta-support
Resolve MLAG Issues
This topic outlines a few scenarios that illustrate how you use NetQ to troubleshoot MLAG on Cumulus Linux switches. Each starts with a log message that indicates the current MLAG state.
NetQ can monitor many aspects of an MLAG configuration, including:
Verifying the current state of all nodes
Verifying the dual connectivity state
Checking that the peer link is part of the bridge
Verifying whether MLAG bonds are not bridge members
Verifying whether the VXLAN interface is not a bridge member
Checking for remote-side service failures caused by systemctl
Checking for VLAN-VNI mapping mismatches
Checking for layer 3 MTU mismatches on peerlink subinterfaces
Checking for VXLAN active-active address inconsistencies
Verifying that STP priorities are the same across both peers
Scenario: All Nodes Are Up
When the MLAG configuration is running smoothly, NetQ sends out a
message that all nodes are up:
2017-05-22T23:13:09.683429+00:00 noc-pr netq-notifier[5501]: INFO: CLAG: All nodes are up
Running netq show mlag confirms this:
cumulus@switch:~$ netq show mlag
Matching clag records:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
spine01(P) spine02 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:49 2019
spine02 spine01(P) 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:53 2019
leaf01(P) leaf02 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:15 2019
leaf02 leaf01(P) 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:20 2019
leaf03(P) leaf04 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:26 2019
leaf04 leaf03(P) 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:30 2019
You can also verify a specific node is up:
cumulus@switch:~$ netq spine01 show mlag
Matching mlag records:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
spine01(P) spine02 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:49 2019
Similarly, checking the MLAG state with NetQ also confirms this:
The clag keyword has been deprecated and replaced by the mlag keyword. The
clag keyword continues to work for now, but you should start using the mlag
keyword instead. Keep in mind you should also update any scripts that use the clag
keyword.
When you are logged directly into a switch, you can run clagctl to get
the state:
After you fix the issue, you can show the MLAG state to see if all the
nodes are up. The notifications from NetQ indicate all nodes are UP, and
the netq check flag also indicates there are no failures.
cumulus@switch:~$ netq show mlag
Matching clag records:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
spine01(P) spine02 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:49 2019
spine02 spine01(P) 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:53 2019
leaf01(P) leaf02 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:15 2019
leaf02 leaf01(P) 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:20 2019
leaf03(P) leaf04 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:26 2019
leaf04 leaf03(P) 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:30 2019
When you are logged directly into a switch, you can run clagctl to get
the state:
After you fix the issue, you can show the MLAG state to see if all the
nodes are up:
cumulus@switch:~$ netq show mlag
Matching clag session records are:
Hostname Peer SysMac State Backup #Bond #Dual Last Changed
s
----------------- ----------------- ------------------ ---------- ------ ----- ----- -------------------------
spine01(P) spine02 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:49 2019
spine02 spine01(P) 00:01:01:10:00:01 up up 24 24 Thu Feb 7 18:30:53 2019
leaf01(P) leaf02 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:15 2019
leaf02 leaf01(P) 44:38:39:ff:ff:01 up up 12 12 Thu Feb 7 18:31:20 2019
leaf03(P) leaf04 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:26 2019
leaf04 leaf03(P) 44:38:39:ff:ff:02 up up 12 12 Thu Feb 7 18:31:30 2019
When you are logged directly into a switch, you can run clagctl to get
the state:
Showing the MLAG state reveals which nodes are down:
cumulus@switch:~$ netq show mlag
Matching CLAG session records are:
Node Peer SysMac State Backup #Bonds #Dual Last Changed
---------------- ---------------- ----------------- ----- ------ ------ ----- -------------------------
spine01(P) spine02 00:01:01:10:00:01 up up 9 9 Thu Feb 7 18:30:53 2019
spine02 spine01(P) 00:01:01:10:00:01 up up 9 9 Thu Feb 7 18:31:04 2019
leaf01 44:38:39:ff:ff:01 down n/a 0 0 Thu Feb 7 18:31:13 2019
leaf03(P) leaf04 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:19 2019
leaf04 leaf03(P) 44:38:39:ff:ff:02 up up 8 8 Thu Feb 7 18:31:25 2019
Checking the MLAG status provides the reason for the failure:
As an administrator, you must secure, configure, and manage your network hardware and software. Tasks associated with managing your physical hardware (switches) and virtual machines (VMs), Cumulus Linux and Cumulus NetQ software are described in this document. These responsibilities are grouped into two categories:
Application Management: manage access to and various application-wide settings for the Cumulus NetQ UI from a single location
Lifecycle Management: manage deployment and perform operational tasks for Cumulus Linux and Cumulus NetQ products from the NetQ UI or CLI
Application Management
As an administrator, you can manage access to and various application-wide settings for the Cumulus NetQ UI from a single location.
Individual users have the ability to set preferences specific to their
workspaces. This information is covered separately. Refer to
Set User Preferences.
NetQ Management Workbench
The NetQ Management workbench is accessed from the main menu. For the user(s) responsible for maintaining the application, this is a good place to start each day.
To open the workbench, click , and select Management under the Admin column.
From the NetQ Management workbench, you can view the number of users with accounts in the system. As an administrator, you can also add, modify, and delete user accounts using the User Accounts card.
Add New User Account
For each user that monitors at least one aspect of your data center
network, a user account is needed. Adding a local user is described here. Refer to Integrate NetQ with Your LDAP server for instructions for adding LDAP users.
To add a new user account:
Click Manage on the User Accounts card to open the User Accounts tab.
Click Add User.
Enter the user’s email address, along with their first and last name.
Be especially careful entering the email address as you cannot change it once you save the account. If you save a mistyped email address, you must delete the account and create a new one.
Select the user type: Admin or User.
Enter your password in the Admin Password field (only users with administrative permissions can add users).
Create a password for the user.
Enter a password for the user.
Re-enter the user password. If you do not enter a matching password, it will be underlined in red.
Click Save to create the user account, or Cancel to discard the user account.
By default the User Accounts table is sorted by Role.
Repeat these steps to add all of your users.
Edit a User Name
If a user’s first or last name was incorrectly entered, you can fix them easily.
To change a user name:
Click Manage on the User Accounts card to open the User Accounts tab.
Click the checkbox next to the account you want to edit.
Click above the account list.
Modify the first and/or last name as needed.
Enter your admin password.
Click Save to commit the changes or Cancel to discard them.
Change a User’s Password
Should a user forget his password or for security reasons, you can change a password for a particular user account.
To change a password:
Click Manage on the User Accounts card to open the User Accounts tab.
Click the checkbox next to the account you want to edit.
Click above the account list.
Click Reset Password.
Enter your admin password.
Enter a new password for the user.
Re-enter the user password. Tip: If the password you enter does not match, Save is gray (not activated).
Click Save to commit the change, or Cancel to discard the change.
Change a User’s Access Permissions
If a particular user has only standard user permissions and they need administrator permissions to perform their job (or the opposite, they have administrator permissions, but only need user permissions), you can modify their access rights.
To change access permissions:
Click Manage on the User Accounts card to open the User Accounts tab.
Click the checkbox next to the account you want to edit.
Click above the account list.
Select the appropriate user type from the dropdown list.
Enter your admin password.
Click Save to commit the change, or Cancel to discard the change.
Correct a Mistyped User ID (Email Address)
You cannot edit a user’s email address, because this is the identifier the system uses for authentication. If you need to change an email address, you must create a new one for this user. Refer to Add New User Account. You should delete the incorrect user account. Select the user account, and click .
Export a List of User Accounts
You can export user account information at any time using the User Accounts tab.
To export information for one or more user accounts:
Click Manage on the User Accounts card to open the User Accounts tab.
Select one or more accounts that you want to export by clicking the checkbox next to them. Alternately select all accounts by clicking .
Click to export the selected user accounts.
Delete a User Account
NetQ application administrators should remove user accounts associated with users that are no longer using the application.
To delete one or more user accounts:
Click Manage on the User Accounts card to open the User Accounts tab.
Select one or more accounts that you want to remove by clicking the checkbox next to them.
Click to remove the accounts.
Manage Scheduled Traces
From the NetQ Management workbench, you can view the number of traces scheduled to run in the system. A set of default traces are provided with the NetQ GUI. As an administrator, you can run one or more scheduled traces, add new scheduled traces, and edit or delete existing traces.
Add a Scheduled Trace
You can create a scheduled trace to provide regular status about a particularly important connection between a pair of devices in your network or for temporary troubleshooting.
To add a trace:
Click Manage on the Scheduled Traces card to open the Scheduled Traces tab.
Click Add Trace to open the large New Trace Request card.
Enter source and destination addresses.
For layer 2 traces, the source must be a hostname and the destination must be a MAC address. For layer 3 traces, the source can be a hostname or IP address, and the destination must be an IP address.
Specify a VLAN for a layer 2 trace or (optionally) a VRF for a layer 3 trace.
Set the schedule for the trace, by selecting how often to run the trace and when to start it the first time.
Click Save As New to add the trace. You are prompted to enter a name for the trace in the Name field.
If you want to run the new trace right away for a baseline, select the trace you just added from the dropdown list, and click Run Now.
Delete a Scheduled Trace
If you do not want to run a given scheduled trace any longer, you can remove it.
To delete a scheduled trace:
Click Manage on the Scheduled Trace card to open the Scheduled Traces tab.
Select at least one trace by clicking on the checkbox next to the trace.
Click .
Export a Scheduled Trace
You can export a scheduled trace configuration at any time using the Scheduled Traces tab.
To export one or more scheduled trace configurations:
Click Manage on the Scheduled Trace card to open the Scheduled Traces tab.
Select one or more traces by clicking on the checkbox next to the trace. Alternately, click to select all traces.
Click to export the selected traces.
Manage Scheduled Validations
From the NetQ Management workbench, you can view the total number of validations scheduled to run in the system. A set of default scheduled validations are provided and pre-configured with the NetQ UI. These are not included in the total count. As an administrator, you can view and export the configurations for all scheduled validations, or add a new validation.
View Scheduled Validation Configurations
You can view the configuration of a scheduled validation at any time. This can be useful when you are trying to determine if the validation request needs to be modified to produce a slightly different set of results (editing or cloning) or if it would be best to create a new one.
To view the configurations:
Click Manage on the Scheduled Validations card to open the Scheduled Validations tab.
Click in the top right to return to your NetQ Management cards.
Add a Scheduled Validation
You can add a scheduled validation at any time using the Scheduled Validations tab.
To add a scheduled validation:
Click Manage on the Scheduled Validations card to open the Scheduled Validations tab.
Click Add Validation to open the large Validation Request card.
You can remove a scheduled validation that you created (one of the 15 allowed) at any time. You cannot remove the default scheduled validations included with NetQ.
To remove a scheduled validation:
Click Manage on the Scheduled Validations card to open the Scheduled Validations tab.
Select one or more validations that you want to delete.
Click above the validations list.
Export Scheduled Validation Configurations
You can export one or more scheduled validation configurations at any time using the Scheduled Validations tab.
To export a scheduled validation:
Click Manage on the Scheduled Validations card to open the Scheduled Validations tab.
Select one or more validations by clicking the checkbox next to the validation. Alternately, click to select all validations.
Click to export selected validations.
Manage Threshold Crossing Rules
NetQ supports a set of events that are triggered by crossing a user-defined threshold. These events allow detection and prevention of network failures for selected interface, utilization, sensor, forwarding, and ACL events.
A notification configuration must contain one rule. Each rule must contain a scope and a threshold.
Supported Events
The following events are supported:
Category
Event ID
Description
Interface Statistics
TCA_RXBROADCAST_UPPER
rx_broadcast bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_RXBYTES_UPPER
rx_bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_RXMULTICAST_UPPER
rx_multicast per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXBROADCAST_UPPER
tx_broadcast bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXBYTES_UPPER
tx_bytes per second on a given switch or host is greater than maximum threshold
Interface Statistics
TCA_TXMULTICAST_UPPER
tx_multicast bytes per second on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_CPU_UTILIZATION_UPPER
CPU utilization (%) on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_DISK_UTILIZATION_UPPER
Disk utilization (%) on a given switch or host is greater than maximum threshold
Resource Utilization
TCA_MEMORY_UTILIZATION_UPPER
Memory utilization (%) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_FAN_UPPER
Switch sensor reported fan speed on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_POWER_UPPER
Switch sensor reported power (Watts) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_TEMPERATURE_UPPER
Switch sensor reported temperature (°C) on a given switch or host is greater than maximum threshold
Sensors
TCA_SENSOR_VOLTAGE_UPPER
Switch sensor reported voltage (Volts) on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_TOTAL_ROUTE_ENTRIES_UPPER
Number of routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_TOTAL_MCAST_ROUTES_UPPER
Number of multicast routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_MAC_ENTRIES_UPPER
Number of MAC addresses on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV4_ROUTE_UPPER
Number of IPv4 routes on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV4_HOST_UPPER
Number of IPv4 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV6_ROUTE_UPPER
Number of IPv6 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_IPV6_HOST_UPPER
Number of IPv6 hosts on a given switch or host is greater than maximum threshold
Forwarding Resources
TCA_TCAM_ECMP_NEXTHOPS_UPPER
Number of equal cost multi-path (ECMP) next hop entries on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V4_FILTER_UPPER
Number of ingress ACL filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V4_FILTER_UPPER
Number of egress ACL filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V4_MANGLE_UPPER
Number of ingress ACL mangles for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V4_MANGLE_UPPER
Number of egress ACL mangles for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V6_FILTER_UPPER
Number of ingress ACL filters for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V6_FILTER_UPPER
Number of egress ACL filters for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_V6_MANGLE_UPPER
Number of ingress ACL mangles for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_EG_ACL_V6_MANGLE_UPPER
Number of egress ACL mangles for IPv6 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_8021x_FILTER_UPPER
Number of ingress ACL 802.1 filters on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_L4_PORT_CHECKERS_UPPER
Number of ACL port range checkers on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_REGIONS_UPPER
Number of ACL regions on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_ACL_MIRROR_UPPER
Number of ingress ACL mirrors on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_18B_RULES_UPPER
Number of ACL 18B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_32B_RULES_UPPER
Number of ACL 32B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_ACL_54B_RULES_UPPER
Number of ACL 54B rules on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_PBR_V4_FILTER_UPPER
Number of ingress policy-based routing (PBR) filters for IPv4 addresses on a given switch or host is greater than maximum threshold
ACL Resources
TCA_TCAM_IN_PBR_V6_FILTER_UPPER
Number of ingress policy-based routing (PBR) filters for IPv6 addresses on a given switch or host is greater than maximum threshold
Define a Scope
A scope is used to filter the events generated by a given rule. Scope values are set on a per TCA rule basis. All rules can be filtered on Hostname. Some rules can also be filtered by other parameters, as shown in this table:
Category
Event ID
Scope Parameters
Interface Statistics
TCA_RXBROADCAST_UPPER
Hostname, Interface
Interface Statistics
TCA_RXBYTES_UPPER
Hostname, Interface
Interface Statistics
TCA_RXMULTICAST_UPPER
Hostname, Interface
Interface Statistics
TCA_TXBROADCAST_UPPER
Hostname, Interface
Interface Statistics
TCA_TXBYTES_UPPER
Hostname, Interface
Interface Statistics
TCA_TXMULTICAST_UPPER
Hostname, Interface
Resource Utilization
TCA_CPU_UTILIZATION_UPPER
Hostname
Resource Utilization
TCA_DISK_UTILIZATION_UPPER
Hostname
Resource Utilization
TCA_MEMORY_UTILIZATION_UPPER
Hostname
Sensors
TCA_SENSOR_FAN_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_POWER_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_TEMPERATURE_UPPER
Hostname, Sensor Name
Sensors
TCA_SENSOR_VOLTAGE_UPPER
Hostname, Sensor Name
Forwarding Resources
TCA_TCAM_TOTAL_ROUTE_ENTRIES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_TOTAL_MCAST_ROUTES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_MAC_ENTRIES_UPPER
Hostname
Forwarding Resources
TCA_TCAM_ECMP_NEXTHOPS_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV4_ROUTE_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV4_HOST_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV6_ROUTE_UPPER
Hostname
Forwarding Resources
TCA_TCAM_IPV6_HOST_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V4_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V4_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V6_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V6_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_V6_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_EG_ACL_V6_MANGLE_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_8021x_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_L4_PORT_CHECKERS_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_REGIONS_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_ACL_MIRROR_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_18B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_32B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_ACL_54B_RULES_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_PBR_V4_FILTER_UPPER
Hostname
ACL Resources
TCA_TCAM_IN_PBR_V6_FILTER_UPPER
Hostname
Scopes are displayed as regular expressions in the rule card.
Scope
Display in Card
Result
All devices
hostname = *
Show events for all devices
All interfaces
ifname = *
Show events for all devices and all interfaces
All sensors
s_name = *
Show events for all devices and all sensors
Particular device
hostname = leaf01
Show events for leaf01 switch
Particular interfaces
ifname = swp14
Show events for swp14 interface
Particular sensors
s_name = fan2
Show events for the fan2 fan
Set of devices
hostname ^ leaf
Show events for switches having names starting with leaf
Set of interfaces
ifname ^ swp
Show events for interfaces having names starting with swp
Set of sensors
s_name ^ fan
Show events for sensors having names starting with fan
When a rule is filtered by more than one parameter, each is displayed on the card. Leaving a value blank for a parameter defaults to all; all hostnames, interfaces, sensors, forwarding and ACL resources.
Specify Notification Channels
The notification channel specified by a TCA rule tells NetQ where to send the notification message.
To specify a notification channel:
Click , and then click Channels in the Notifications column.
This opens the Channels view.
Determine the type of channel you want to add (Slack, PagerDuty, or Syslog). Follow the instructions for the selected type.
Specify Slack Channels
To specify Slack channels:
Create one or more channels using Slack.
In NetQ, click Slack in the Channels view.
When no channels have been specified, click on the note. When at least one channel has been specified, click above the table.
Provide a unique name for the channel. Note that spaces are not allowed. Use dashes or camelCase instead.
Copy and paste the incoming webhook URL for a channel you created in Step 1 (or earlier).
Click Add.
Repeat to add additional Slack channels as needed.
Specify PagerDuty Channels
To specify PagerDuty channels:
Create one or more channels using PagerDuty.
In NetQ, click PagerDuty in the Channels view.
When no channels have been specified, click on the note. When at least one channel has been specified, click above the table.
Provide a unique name for the channel. Note that spaces are not allowed. Use dashes or camelCase instead.
Copy and paste the integration key for a PagerDuty channel you created in Step 1 (or earlier).
Click Add.
Repeat to add additional PagerDuty channels as needed.
Specify a Syslog Channel
To specify a Syslog channel:
Click Syslog in the Channels view.
When no channels have been specified, click on the note. When at least one channel has been specified, click above the table.
Provide a unique name for the channel. Note that spaces are not allowed. Use dashes or camelCase instead.
Enter the IP address and port of the Syslog server.
Click Add.
Repeat to add additional Syslog channels as needed.
Remove Notification Channels
You can view your notification channels at any time. If you create new channels or retire selected channels, you might need to add or remove them from NetQ as well. To add channels refer to Specify Notification Channels.
To remove channels:
Click , and then click Channels in the Notifications column.
This opens the Channels view.
Click the tab for the type of channel you want to remove (Slack, PagerDuty, or Syslog).
Select one or more channels.
Click .
Create a TCA Rule
Now that you know which events are supported and how to set the scope, you can create a basic rule to deliver one of the TCA events to a notification channel.
To create a TCA rule:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Click to add a rule.
The Create TCA Rule dialog opens. Four steps create the rule.
You can move forward and backward until you are satisfied with your rule definition.
On the Enter Details step, enter a name for your rule, choose your TCA event type, and assign a severity.
The rule name has a maximum of 20 characters (including spaces).
Click Next.
On the Choose Event step, select the attribute to measure against.
The attributes presented depend on the event type chosen in the Enter Details step. This example shows the attributes available when Resource Utilization was selected.
Click Next.
On the Set Threshold step, enter a threshold value.
Define the scope of the rule.
If you want to restrict the rule to a particular device, and enter values for one or more of the available parameters.
If you want the rule to apply to all devices, click the scope toggle.
Click Next.
Optionally, select a notification channel where you want the events to be sent. If no channel is select, the notifications are only available from the database. You can add a channel at a later time. Refer to Modify TCA Rules.
Click Finish.
This example shows two rules. The rule on the left triggers an informational event when switch leaf01 exceeds the maximum CPU utilization of 87%. The rule on the right triggers a critical event when any device exceeds the maximum CPU utilization of 93%. Note that the cards indicate both rules are currently Active.
View All TCA Rules
You can view all of the threshold-crossing event rules you have created by clicking and then selecting Threshold Crossing Rules under Notifications.
Modify TCA Rules
You can modify the threshold value and scope of any existing rules.
To edit a rule:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Locate the rule you want to modify and hover over the card.
Click .
Modify the rule, changing the threshold, scope or associated channel.
If you want to modify the rule name or severity after creating the rule, you must delete the rule and recreate it.
Click Update Rule.
Manage TCA Rules
Once you have created a bunch of rules, you might have the need to manage them; suppress a rule, disable a rule, or delete a rule.
Rule States
The TCA rules have three possible states:
Active: Rule is operating, delivering events. This would be the normal operating state.
Suppressed: Rule is disabled until a designated date and time. When that time occurs, the rule is automatically reenabled. This state is useful during troubleshooting or maintenance of a switch when you do not want erroneous events being generated.
Disabled: Rule is disabled until a user manually reenables it. This state is useful when you are unclear when you want the rule to be reenabled. This is not the same as deleting the rule.
Suppress a Rule
To suppress a rule for a designated amount of time, you must change the state of the rule.
To suppress a rule:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Locate the rule you want to suppress.
Click Disable.
Click in the Date/Time field to set when you want the rule to be automatically reenabled.
Click Disable.
Note the changes in the card:
The state is now marked as Inactive, but remains green
The date and time that the rule will be enabled is noted in the Suppressed field
The Disable option has changed to Disable Forever. Refer to Disable a Rule for information about this change.
Disable a Rule
To disable a rule until you want to manually reenable it, you must change the state of the rule.
To disable a rule that is currently active:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Locate the rule you want to disable.
Click Disable.
Leave the Date/Time field blank.
Click Disable.
Note the changes in the card:
The state is now marked as Inactive and is red
The rule definition is grayed out
The Disable option has changed to Enable to reactivate the rule when you are ready
To disable a rule that is currently suppressed:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Locate the rule you want to disable.
Click Disable Forever.
Note the changes in the card:
The state is now marked as Inactive and is red
The rule definition is grayed out
The Disable option has changed to Enable to reactivate the rule when you are ready
Delete a Rule
You might find that you no longer want to received event notifications for a particular TCA event. In that case, you can either disable the event if you think you may want to receive them again or delete the rule altogether. Refer to Disable a Rule in the first case. Follow the instructions here to remove the rule. The rule can be in any of the three states.
To delete a rule:
Click to open the Main Menu.
Click Threshold Crossing Rules under Notifications.
Locate the rule you want to remove and hover over the card.
Click .
Resolve Scope Conflicts
There may be occasions where the scope defined by multiple rules for a given TCA event may overlap each other. In such cases, the TCA rule with the most specific scope that is still true is used to generate the event.
To clarify this, consider this example. Three events have occurred:
First event on switch leaf01, interface swp1
Second event on switch leaf01, interface swp3
Third event on switch spine01, interface swp1
NetQ attempts to match the TCA event against hostname and interface name with three TCA rules with different scopes:
Scope 1 send events for the swp1 interface on switch leaf01 (very specific)
Scope 2 send events for all interfaces on switches that start with leaf (moderately specific)
Scope 3 send events for all switches and interfaces (very broad)
The result is:
For the first event, NetQ applies the scope from rule 1 because it matches scope 1 exactly
For the second event, NetQ applies the scope from rule 2 because it does not match scope 1, but does match scope 2
For the third event, NetQ applies the scope from rule 3 because it does not match either scope 1 or scope 2
In summary:
Input Event
Scope Parameters
Rule 1, Scope 1
Rule 2, Scope 2
Rule 3, Scope 3
Scope Applied
leaf01, swp1
Hostname, Interface
hostname=leaf01, ifname=swp1
hostname ^ leaf, ifname=*
hostname=*, ifname=*
Scope 1
leaf01, swp3
Hostname, Interface
hostname=leaf01, ifname=swp1
hostname ^ leaf, ifname=*
hostname=*, ifname=*
Scope 2
spine01, swp1
Hostname, Interface
hostname=leaf01, ifname=swp1
hostname ^ leaf, ifname=*
hostname=*, ifname=*
Scope 3
Manage Monitoring of Multiple Premises
The NetQ Management dashboard provides the ability to configure a single NetQ UI and CLI for monitoring data from multiple external premises in addition to your local premises.
A complete NetQ deployment is required at each premises. The NetQ appliance or VM of one of the deployments acts as the primary (similar to a proxy) for the premises in the other deployments. A list of these external premises is stored with the primary deployment. After the multiple premises are configured, you can view this list of external premises, change the name of premises on the list, and delete premises from the list.
To configure monitoring of external premises:
Sign in to primary NetQ Appliance or VM.
In the NetQ UI, click .
Select Management from the Admin column.
Locate the External Premises card.
Click Manage.
Click to open the Add Premises dialog.
Specify an external premises.
Enter an IP address for the API gateway on the external NetQ Appliance or VM in the Hostname field (required)
Enter the access credentials
Click Next.
Select from the available premises associated with this deployment by clicking on their names.
Click Finish.
Add more external premises by repeating Steps 6-10.
System Server Information
You can easily view the configuration of the physical server of VM from the NetQ Management dashboard.
To view the server information:
Click .
Select Management from the Admin column.
Locate the System Server Info card.
Integrate with Your LDAP Server
For on-premises deployments you can integrate your LDAP server with NetQ to provide access to NetQ using LDAP user accounts instead of ,or in addition to, the NetQ user accounts. Refer to Integrate NetQ with Your LDAP Server for more detail.
What's New
Cumulus NetQ 3.0 adds significant functionality improvements that streamline network operations and eliminate barriers to adoption of open networking for your customers. Included in the updated software are lifecycle Management (LCM) capabilities that enable NetQ to deliver upgrade and configuration management with push button simplicity.
You can upgrade from NetQ 2.4.x to NetQ 3.0.0. Upgrades from NetQ 2.3.x and earlier require a fresh installation.
Cumulus NetQ 3.0.0 includes the following new features and improvements:
Lifecycle Management support for Cumulus Linux upgrade on monitored switches (NetQ UI or CLI)
Simple NetQ UI workflow to prepare, run upgrade jobs, and evaluate results
Option to automatically generate before and after network snapshots for comparison
Option to roll back to previous CL version in the event of upgrade failure
Embedded NetQ UI application help, with step-by-step instructions and link to user documentation
Password change required on first login to NetQ UI
Display all addresses in a subnet, supernet or layer 3 gateway of an address using netq show ip addresses and netq show ipv6 addresses commands
Tune NetQ Agent polling for events and resources, and specify polling frequency using netq config agent command command set
Specify a list of hostnames when running netq check commands
View additional statistics from netq <hostname> show ethtool-status command
Ported Python 2 codebase to Python 3
LNV support has been removed as of this release.
For information regarding bug fixes and known issues present in this release, refer to the release notes.
Lifecycle Management
As an administrator, you want to manage the deployment of Cumulus Networks product software onto your network devices (servers, appliances, and switches) in the most efficient way and with the most information about the process as possible. With this release, NetQ expands its initial lifecycle management (LCM) feature of network Snapshot and Compare to support Cumulus Linux image, switch, and credential management, and a UI workflow for the Cumulus Linux image installation and upgrade, including backup and restoration of the switch configuration files. Each of these features can be managed separately, but the greatest benefits are seen when they are used together in the workflow.
This feature is only available for on-premises deployments.
Access Lifecycle Management Features
To manage the various lifecycle management features, click (Main Menu) and select Upgrade Switches.
The Manage Switch Assets view provides a summary card for switch inventory, uploaded images, and switch access settings.
If you have a workbench open, you can also access this view by clicking (Upgrade) in the workbench header.
Image Management
Cumulus Linux binary images can be uploaded to a local LCM repository for use with installation and upgrade of your switches. You can upload images from an external drive. When NetQ discovers Cumulus Linux switches running NetQ 2.4 or later in your network, it extracts the meta data needed to select the appropriate image for a given switch; including the software version (x.y.z), the CPU architecture (ARM, x86), platform (based on ASIC vendor, Broadcom or Mellanox) and SHA Checksum.
The Cumulus Linux Images card provides a summary of image status in NetQ. It shows the total number of images in the repository, a count of missing images (refer to Missing Images), and the starting points for adding and managing your images.
Default Cumulus Linux Version Assignment
You can assign a specific Cumulus Linux version as the default version to use during installation or upgrade of switches. Choosing the version that is desired for the largest number of your switches is recommended. The default selection can be overridden during upgrade job creation if an alternate version is needed for a set of switches.
Missing Images
You should upload images for each variant of Cumulus Linux currently installed on your switch inventory if you want to support rolling back to a known good version should an installation or upgrade fail. NetQ prompts you to upload any missing images to the repository. For example, if you have both Cumulus Linux 3.7.3 and 3.7.11 versions, some running on ARM and some on x86 architectures, then NetQ would verify the presence of each of these images. If only the 3.7.3 x86, 3.7.3 ARM, and 3.7.11 x86 images are in the repository, NetQ would list the 3.7.11 ARM image as missing.
If you have specified a default Cumulus Linux version, NetQ also verifies that the necessary images are available based on the known switch inventory, and if not, lists those that are missing.
Upload Images
On installation of NetQ 3.0, no images have yet been uploaded to the LCM repository. Begin by adding images that match your current inventory. Then add the image you want to use for upgrading. And finally specify a default image for upgrades, if desired.
Upload Missing Images
To upload missing images:
On the Cumulus Linux Images card, click the View missing CL images link to see what images you need. This opens the list of missing images.
Select one of the missing images and make note of the version, ASIC Vendor, and CPU architecture.
Click (Add Image) above the table.
Provide the .bin file from an external drive that matches the criteria for the selected image, either by dragging and dropping it onto the dialog or by selecting it from a directory.
Click Import.
On successful completion, you receive confirmation of the upload.
If the upload was not successful, an Image Import Failed message is shown. Close the Import Image dialog and try uploading the file again.
Click Done.
Click Uploaded tab to verify the image is in the repository.
Repeat Steps 1-7 until all of the missing images are uploaded to the repository. When all of the missing images have been uploaded, the Missing list will be empty.
Click to return to the LCM dashboard.
The Cumulus Linux Images card now shows the number of images you uploaded.
Upload Upgrade Images
To upload the Cumulus Linux images that you want to use for upgrade:
Click Add Image on the Cumulus Linux Images card.
Provide an image from an external drive, either by dragging and dropping it onto the dialog or by selecting it from a directory.
Click Import.
Click Done.
Repeat Steps 1-4 to upload additional images as needed.
For example, if you are upgrading switches with different ASIC vendors or CPU architectures, you will need more than one image.
Specify a Default Image for Upgrade
Lifecycle management does not have a default Cumulus Linux image specified automatically. You must specify the image that is appropriate for your network.
To specify a default Cumulus Linux image:
Click the Click here to set the default CL version link in the middle of the Cumulus Linux Images card.
Select the image you want to use as the default image for switch upgrades.
Click Save. The default version is now displayed on the Cumulus Linux Images card.
After you have specified a default image, you have the option to change it.
To change the default Cumulus Linux image:
Click change next to the currently identified default image on the Cumulus Linux Images card.
Select the image you want to use as the default image for switch upgrades.
Click Save.
Export Images
Once you have images uploaded to the NetQ LCM repository, you are able to export those images.
To export images:
Open the LCM dashboard.
Click Manage on the Cumulus Linux Images card.
Select the images you want to export from the Uploaded tab. Use the filter option above the table to narrow down a large listing of images.
Click above the table.
Choose the export file type and click Export.
Remove Images from Local Repository
Once you have upgraded all of your switches beyond a particular release of Cumulus Linux, you may want to remove any associated images from the NetQ LCM repository to save space on the server.
To remove images:
Open the LCM dashboard.
Click Manage on the Cumulus Linux Images card.
On the Uploaded tab, select the images you want to remove. Use the filter option above the table to narrow down a large listing of images.
Click .
Credential Management
Switch access credentials are needed for performing upgrades. You can choose between basic authentication (SSH password) and SSH (Public/Private key) authentication. These credentials apply to all switches.
Specify Switch Credentials
Switch access credentials are not specified by default. You must add these.
To specify access credentials:
Open the LCM dashboard.
Click the Click here to add switch access link on the Access card.
Select the authentication method you want to use; SSH or Basic Authentication. Basic authentication is selected by default.
Enter a username.
Enter a password.
Click Save.
The Access card now indicates your credential configuration.
You must have sudoer permission to properly configure switches when using the SSH Key method.
Create a pair of SSH private and public keys.
ssh-keygen -t rsa -C "<USER>"
Copy the SSH public key to each switch that you want to upgrade using one of the following methods:
Manually copy SSH public key to the /home/<USER>/.ssh/authorized_keys file on each switches, or
Run ssh-copy-id USER@<switch_ip> on the server where the SSH key pair was generated for each switch
Copy the SSH private key into the text box in the Create Switch Access card.
For security, your private key is stored in an encrypted format, and only provided to internal processes while encrypted.
The Access card now indicates your credential configuration.
Modify Switch Credentials
You can modify your switch access credentials at any time. You can change between authentication methods or change values for either method.
To change your access credentials:
Open the LCM dashboard.
On the Access card, click the Click here to change access mode link in the center of the card.
Select the authentication method you want to use; SSH or Basic Authentication. Basic authentication is selected by default.
This lifecycle management feature provides an inventory of switches that have been automatically discovered by NetQ 3.0.0 and are available for software installation or upgrade through NetQ. This includes all switches running Cumulus NetQ Agent 2.4 or later in your network. You assign network roles to switches and select switches for software installation and upgrade from this inventory listing.
A count of the switches NetQ was able to discover and the Cumulus Linux versions that are running on those switches is available from the LCM dashboard.
To view a list of all switches known to lifecycle management, click Manage on the Switches card.
Review the list, filtering as needed (click ) to determine if the switches you want to upgrade are included.
If you have more than one Cumulus Linux version running on your switches, you can click a version segment on the Switches card graph to open a list of switches pre-filtered by that version.
If the switches you are looking to upgrade are not present in the final list, verify the switches have NetQ 2.4 or later Agents on them.
To verify the NetQ Agent version, click , then click Agents in the Network section. Search for the switches of interest and confirm the applied version in the Version column. Upgrade any NetQ Agents if needed. Refer to Upgrade NetQ Agents for instructions.
After all of the switches you want to upgrade are contained in the list, you can assign roles to them.
Role Management
Four pre-defined switch roles are available based on the CLOS architecture:
Superspine
Spine
Leaf
Exit
With this release, you cannot create your own roles.
Switch roles are used to:
Identify switch dependencies and determine the order in which switches are upgraded
Determine when to stop the process if a failure is encountered
When roles are assigned, the upgrade process begins with switches having the superspine role, then continues with the spine switches, leaf switches, exit switches, and finally switches with no role assigned. All switches with a given role must be successfully upgraded before the switches with the closest dependent role can be upgraded.
For example, a group of seven switches are selected for upgrade. Three are spine switches and four are leaf switches. After all of the spine switches are successfully upgraded, then the leaf switches are upgraded. If one of the spine switches were to fail the upgrade, the other two spine switches are upgraded, but the upgrade process stops after that, leaving the leaf switches untouched, and the upgrade job fails.
When only some of the selected switches have roles assigned in an upgrade job, the switches with roles are upgraded first and then all the switches with no roles assigned are upgraded.
While role assignment is optional, using roles can prevent switches from becoming unreachable due to dependencies between switches or single attachments. And when MLAG pairs are deployed, switch roles avoid upgrade conflicts. For these reasons, Cumulus Networks highly recommends assigning roles to all of your switches.
Assign Switch Roles
Open the LCM dashboard.
On the Switches card, click Manage.
Select one switch or multiple switches that should be assigned to the same role.
Click .
Select the role that applies to the selected switch(es).
Click Assign.
Note that the Role column is updated with the role assigned to the selected switch(es).
Continue selecting switches and assigning roles until most or all switches have roles assigned.
A bonus of assigning roles to switches is that you can then filter the list of switches by their roles by clicking the appropriate tab.
Change the Role of a Switch
If you accidentally assign an incorrect role to a switch, it can easily be changed to the correct role.
To change a switch role:
Open the LCM dashboard.
On the Switches card, click Manage.
Select the switch with the incorrect role from the list.
Click .
Select the correct role.
Click Assign.
Export List of Switches
Using the Switch Management feature you can export a listing of all or a selected set of switches.
To export the switch listing:
Open the LCM dashboard.
On the Switches card, click Manage.
Select one or more switches, filtering as needed, or select all switches (click ).
Click .
Choose the export file type and click Export.
Network Snapshot and Compare
Creating and comparing network snapshots can be used at various times; typically when you are upgrading or changing the configuration of your switches in some way. The instructions here describe how to create and compare network snapshots at any time. Refer to Image Installation and Upgrade to see how snapshots are automatically created in that workflow to validate that the network state has not changed after an upgrade.
Create a Network Snapshot
It is simple to capture the state of your network currently or for a time in the past using the snapshot feature.
To create a snapshot:
From any workbench, click in the workbench header.
Click Create Snapshot.
Enter a name for the snapshot.
Accept the time provided or enter a previous date and time.
Optionally, add a descriptive note for the snapshot.
Click Finish.
A medium Snapshot card appears on your desktop. Spinning arrows are visible while it works. When it finishes you can see the number of items that have been captured, and if any failed. This example shows a successful result.
If you have already created other snapshots, Compare is active. Otherwise it is inactive (grayed-out).
Compare Network Snapshots
You can compare the state of your network before and after an upgrade or other configuration change to validate the changes.
To compare network snapshots:
Create a snapshot (as described in previous section) before you make any changes.
Make your changes.
Create a second snapshot.
Compare the results of the two snapshots. Depending on what, if any, cards are open on your workbench:
If you have the two desired snapshot cards open:
Simply put them next to each other to view a high-level comparison.
Scroll down to see all of the items.
To view a more detailed comparison, click Compare on one of the cards. Select the other snapshot from the list.
If you have only one of the cards open:
Click Compare on the open card.
Select the other snapshot to compare.
If no snapshot cards are open (you may have created them some time before):
Click .
Click Compare Snapshots.
Click on the two snapshots you want to compare.
Click Finish. Note that two snapshots must be selected before Finish is active.
In the latter two cases, the large Snapshot card opens. The only difference is in the card title. If you opened the comparison card from a snapshot on your workbench, the title includes the name of that card. If you open the comparison card through the Snapshot menu, the title is generic, indicating a comparison only. Functionally, you have reached the same point.
Scroll down to view all element comparisons.
Interpreting the Comparison Data
For each network element that is compared, count values and changes are shown:
In this example, a change was made to the VLAN. The snapshot taken before the change (17Apr2020) had a total count of 765 neighbors. The snapshot taken after the change (20Apr2020) had a total count of 771 neighbors. Between the two totals you can see the number of neighbors added and removed from one time to the next, resulting in six new neighbors after the change.
The red and green coloring indicates only that items were removed (red) or added (green). The coloring does not indicate whether the removal or addition of these items is bad or good.
From this card, you can also change which snapshots to compare. Select an alternate snapshot from one of the two snapshot dropdowns and then click Compare.
View Change Details
You can view additional details about the changes that have occurred between the two snapshots by clicking View Details. This opens the full screen Detailed Snapshot Comparison card.
From this card you can:
View changes for each of the elements that had added and/or removed items, and various information about each; only elements with changes are presented
Filter the added and removed items by clicking
Export all differences in JSON file format by clicking
The following table describes the information provided for each element type when changes are present:
Element
Data Descriptions
BGP
Hostname: Name of the host running the BGP session
VRF: Virtual route forwarding interface if used
BGP Session: Session that was removed or added
ASN: Autonomous system number
CLAG
Hostname: Name of the host running the CLAG session
CLAG Sysmac: MAC address for a bond interface pair that was removed or added
Interface
Hostname: Name of the host where the interface resides
IF Name: Name of the interface that was removed or added
IP Address
Hostname: Name of the host where address was removed or added
Prefix: IP address prefix
Mask: IP address mask
IF Name: Name of the interface that owns the address
Links
Hostname: Name of the host where the link was removed or added
Hostname: Name of the discovered host that was removed or added
IF Name: Name of the interface
MAC Address
Hostname: Name of the host where MAC address resides
MAC address: MAC address that was removed or added
VLAN: VLAN associated with the MAC address
Neighbor
Hostname: Name of the neighbor peer that was removed or added
VRF: Virtual route forwarding interface if used
IF Name: Name of the neighbor interface
IP address: Neighbor IP address
Node
Hostname: Name of the network node that was removed or added
OSPF
Hostname: Name of the host running the OSPF session
IF Name: Name of the associated interface that was removed or added
Area: Routing domain for this host device
Peer ID: Network subnet address of router with access to the peer device
Route
Hostname: Name of the host running the route that was removed or added
VRF: Virtual route forwarding interface associated with route
Prefix: IP address prefix
Sensors
Hostname: Name of the host where sensor resides
Kind: Power supply unit, fan, or temperature
Name: Name of the sensor that was removed or added
Services
Hostname: Name of the host where service is running
Name: Name of the service that was removed or added
VRF: Virtual route forwarding interface associated with service
Manage Network Snapshots
You can create as many snapshots as you like and view them at any time. When a snapshot becomes old and no longer useful, you can remove it.
To view an existing snapshot:
From any workbench, click in the workbench header.
Click View/Delete Snapshots.
Click View.
Click one or more snapshots you want to view, then click Finish.
Click Back or Choose Action to cancel viewing of your selected snapshot(s).
To remove an existing snapshot:
From any workbench, click in the workbench header.
Click View/Delete Snapshots.
Click Delete.
Click one or more snapshots you want to remove, then click Finish.
Click Back or Choose Action to cancel the deletion of your selected snapshot(s).
Cumulus Linux Upgrade
The workflow for installation and upgrade of Cumulus Linux using LCM is to: select switches, choose options, run pre-checks, view job preview, begin job, monitor job, review snapshot comparison and analyze as needed. Up to five jobs can be run simultaneously; however, a given switch can only be contained in one of those jobs.
Upgrades can be performed between Cumulus Linux 3.x releases, and between Cumulus Linux 4.x releases. Lifecycle management does not support upgrades from Cumulus Linux 3.x to 4.x releases.
Prepare
In preparation for switch installation or upgrade, first perform the following steps:
Verify the switches you want to manage are running NetQ Agent 2.4 or later. Refer to Switch Management.
Assign each switch a role (optional, but recommended). Refer to Role Management.
Your LCM dashboard should look similar to this after you have completed these steps:
Perform Install or Upgrade
To install or upgrade switches:
Click (Main Menu) and select Upgrade Switches, or click (Upgrade) in a workbench header.
Click Manage on the Switches card.
Select the switches you want to upgrade. If needed, use the filter to the narrow the listing and find these switches.
Click (Upgrade Switches) above the table.
From this point forward, the software walks you through the upgrade process, beginning with a review of the switches that you selected for upgrade.
Give the upgrade job a name. This is required.
For best presentation, Cumulus Networks recommends keeping the name to a maximum of 22 characters when possible. The name can contain spaces and special characters. If you choose to use longer names, use the distinguishing part of the name at the beginning.
Verify that the switches you selected are included, and that they have the correct IP address and roles assigned.
If you accidentally included a switch that you do NOT want to upgrade, hover over the switch information card and click to remove it from the upgrade job.
If the role is incorrect or missing, click to select a role for that switch, then click . Click to discard a role change.
In this example, some of the selected switches do not have roles assigned.
When you are satisfied that the list of switches is accurate for the job, click Next.
Verify that you want to use the default Cumulus Linux version for this upgrade job. If not, click Custom and select an alternate image from the list.
Default CL Version Selected
Custom CL Version Selected
Note that the switch access authentication method, Using global access credentials, indicates you have chosen either basic authentication with a username and password or SSH key-based authentication for all of your switches. Authentication on a per switch basis is not currently available.
Click Next.
Verify the upgrade job options.
By default, NetQ takes a network snapshot before the upgrade and then one after the upgrade is complete. It also performs a roll back to the original Cumulus Linux version on any server which fails to upgrade.
While these options provide a smoother upgrade process and are highly recommended, you have the option to disable these options by clicking No next to one or both options.
Click Next.
After the pre-checks have completed successfully, click Preview.
If one or more of the pre-checks fail, resolve the related issue and start the upgrade again. Expand the following dropdown to view common failures, their causes and corrective actions.
▼
Pre-check Failure Messages
Pre-check
Message
Type
Description
Corrective Action
(1) Switch Order
<hostname1> switch cannot be upgraded without isolating <hostname2>, <hostname3> which are connected neighbors. Unable to upgrade
Warning
Hostname2 and hostname3 switches will be isolated during upgrade, making them unreachable. These switches are skipped if you continue with the upgrade.
Reconfigure hostname2 and hostname 3 switches to have redundant connections, or continue with upgrade knowing that you will lose connectivity with these switches during the upgrade process.
(2) Version Compatibility
Unable to upgrade <hostname> with CL version <3.y.z> to <4.y.z>
Error
LCM only supports CL 3.x to 3.x and CL 4.x to 4.x upgrades
Perform a fresh install of CL 4.x
Image not uploaded for the combination: CL Version - <x.y.z>, Asic Vendor - <Mellanox | Broadcom>, CPU Arch - <x86 | ARM >
Error
The specified Cumulus Linux image is not available in the LCM repository
Restoration image not uploaded for the combination: CL Version - <x.y.z>, Asic Vendor - <Mellanox | Broadcom>, CPU Arch - <x86 | ARM >
Error
The specified Cumulus Linux image needed to restore the switch back to its original version if the upgrade fails is not available in the LCM repository. This applies only when the "Roll back on upgrade failure" job option is selected.
LCM cannot upgrade a switch that is not in its inventory.
Verify you have the correct hostname or IP address for the switch.
Verify the switch has NetQ Agent 2.4.0 or later installed: click , then click Agents in the Network section, view Version column. Upgrade NetQ Agents if needed. Refer to Upgrade NetQ Agents.
Switch <hostname> is rotten. Cannot select for upgrade.
Error
LCM must be able to communicate with the switch to upgrade it.
Troubleshoot the connectivity issue and retry upgrade when the switch is fresh.
Total number of jobs <running jobs count> exceeded Max jobs supported 50
Error
LCM can support a total of 50 upgrade jobs running simultaneously.
Wait for the total number of simultaneous upgrade jobs to drop below 50.
Switch <hostname> is already being upgraded. Cannot initiate another upgrade.
Error
Switch is already a part of another running upgrade job.
Remove switch from current job or wait until the competing job has completed.
Backup failed in previous upgrade attempt for switch <hostname>.
Warning
LCM was unable to back up switch during a previously failed upgrade attempt.
You may want to back up switch manually prior to upgrade if you want to restore the switch after upgrade. Refer to [add link here].
Restore failed in previous upgrade attempt for switch <hostname>.
Warning
LCM was unable to restore switch after a previously failed upgrade attempt.
You may need to restore switch manually after upgrade. Refer to [add link here].
Upgrade failed in previous attempt for switch <hostname>.
Warning
LCM was unable to upgrade switch during last attempt.
(4) MLAG Configuration
hostname:<hostname>,reason:<MLAG error message>
Error
An error in an MLAG configuration has been detected. For example: Backup IP 10.10.10.1 does not belong to peer.
Review the MLAG configuration on the identified switch. Refer to the MLAG documentation for more information. Make any needed changes.
MLAG configuration checks timed out
Error
One or more switches stopped responding to the MLAG checks.
MLAG configuration checks failed
Error
One or more switches failed the MLAG checks.
For switch <hostname>, the MLAG switch with Role: secondary and ClagSysmac: <MAC address> does not exist.
Error
Identified switch is the primary in an MLAG pair, but the defined secondary switch is not in NetQ inventory.
Verify the switch has NetQ Agent 2.4.0 or later installed: click , then click Agents in the Network section, view Version column. Upgrade NetQ Agent if needed. Refer to Upgrade NetQ Agents. Add the missing peer switch to NetQ inventory.
Review the job preview.
When all of your switches have roles assigned, this view displays the chosen job options (top center), the pre-checks status (top right and left in Pre-Upgrade Tasks), the order in which the switches are planned for upgrade (center; upgrade starts from the left), and the post-upgrade tasks status (right).
Roles assigned
When none of your switches have roles assigned, this view displays the chosen job options (top center), the pre-checks status (top right and left in Pre-Upgrade Tasks), a list of switches planned for upgrade (center), and the post-upgrade tasks status (right).
No roles assigned
When some of your switches have roles assigned, any switches without roles are upgraded last and are grouped under the label Stage1.
Some roles assigned
When you are happy with the job specifications, click Start Upgrade.
Analyze Results
After starting the upgrade you can monitor the progress from the preview page or the Upgrade History page.
From the preview page, a green circle with rotating arrows is shown above each step as it is working. Alternately, you can close the detail of the job and see a summary of all current and past upgrade jobs on the Upgrade History page. The job started most recently is shown at the bottom, and the data is refreshed every minute.
If you are disconnected while the job is in progress, it may appear as if nothing is happening. Try closing (click ) and reopening your view (click ), or refreshing the page.
Monitoring the Upgrade
Several viewing options are available for monitoring the upgrade job.
Monitor the job with full details open:
Monitor the job with summary information only in the Upgrade History page. Open this view by clicking in the full details view:
This view is refreshed automatically. Click to view what stage the job is in.
Click to view the detailed view.
After either a successful or failed upgrade attempt has been performed, a new Upgrade History card appears on your LCM dashboard.
Click View to return to the Upgrade History page as needed.
Sample Successful Upgrade
On successful completion, you can:
Compare the network snapshots taken before and after the upgrade.
Download details about the upgrade in the form of a JSON-formatted file, by clicking Download Report.
View the changes on the Switches card of the LCM dashboard.
Click , then Upgrade Switches.
In our example, all switches have been upgraded to Cumulus Linux 3.7.12.
Upgrades can be considered successful and still have post-check warnings. For example, the OS has been updated, but not all services are fully up and running after the upgrade. If one or more of the post-checks fail, warning messages are provided in the Post-Upgrade Tasks section of the preview. Click on the warning category to view the detailed messages.
Sample Failed Upgrade
If an upgrade job fails for any reason, you can view the associated error(s):
From the Upgrade History dashboard, find the job of interest.
Click .
Click .
Note in this example, all of the pre-upgrade tasks were successful, but backup failed on the spine switches.
Double-click on an error to view a more detailed error message.
This example, shows that the upgrade failure was due to bad switch access credentials. You would need to fix those and then create a new upgrade job.
Reasons for Upgrade Failure
Upgrades can fail at any of the stages of the process, including when backing up data, upgrading the Cumulus Linux software, and restoring the data. Failures can occur when attempting to connect to a switch or perform a particular task on the switch.
Some of the common reasons for upgrade failures and the errors they present:
Reason
Error Message
Switch is not reachable via SSH
Data could not be sent to remote host “192.168.0.15”. Make sure this host can be reached over ssh: ssh: connect to host 192.168.0.15 port 22: No route to host
Switch is reachable, but user-provided credentials are invalid
Invalid/incorrect username/password. Skipping remaining 2 retries to prevent account lockout: Warning: Permanently added ‘<hostname-ipaddr>’ to the list of known hosts. Permission denied, please try again.
Switch is reachable, but a valid Cumulus Linux license is not installed
1587866683.880463 2020-04-26 02:04:43 license.c:336 CRIT No license file. No license installed!
Upgrade task could not be run
Failure message depends on the why the task could not be run. For example: /etc/network/interfaces: No such file or directory
Upgrade task failed
Failed at- <task that failed>. For example: Failed at- MLAG check for the peerLink interface status
Retry failed after five attempts
FAILED In all retries to process the LCM Job
More Documents
The following documents summarize new features in the release, bug fixes, document formatting conventions, and general terminology. A PDF of the NetQ user documentation is also included here.
Document Format Conventions
The Cumulus NetQ documentation uses the following typographical and note conventions.
Typographical Conventions
Throughout the guide, text formatting is used to convey contextual information about the content.
Text Format
Meaning
Green text
Link to additional content within the topic or to another topic
Text in Monospace font
Filename, directory and path names, and command usage
[Text within square brackets]
Optional command parameters; may be presented in mixed case or all caps text
<Text within angle brackets>
Required command parameter values-variables that are to be replaced with a relevant value; may be presented in mixed case or all caps text
Note Conventions
Several note types are used throughout the document. The formatting of the note indicates its intent and
urgency.
Offers information to improve your experience with the tool, such as time-saving or shortcut options, or indicates the common or recommended method for performing a particular task or process
Provides additional information or a reminder about a task or process that may impact your next step or selection
Advises that failure to take or avoid specific action can result in possible data loss
Advises that failure to take or avoid specific action can result in possible physical harm to yourself, hardware equipment, or facility
Glossary
Common Cumulus Linux and NetQ Terminology
The following table covers some basic terms used throughout the NetQ
user documentation.
Term
Definition
Agent
NetQ software that resides on a host server that provides metrics about the host to the NetQ Telemetry Server for network health analysis.
Alarm
In UI, event with critical severity.
Bridge
Device that connects two communication networks or network segments. Occurs at OSI Model Layer 2, Data Link Layer.
Clos
Multistage circuit switching network used by the telecommunications industry, first formalized by Charles Clos in 1952.
Device
UI term referring to a switch, host, or chassis or combination of these. Typically used when describing hardware and components versus a software or network topology. See also Node.
Event
Change or occurrence in network or component; may or may not trigger a notification. In the NetQ UI, there are two types of events: Alarms which indicate a critical severity event, and Info which indicate warning, informational, and debugging severity events.
Fabric
Network topology where a set of network nodes is interconnected through one or more network switches.
Fresh
Node that has been heard from in the last 90 seconds.
High Availability
Software used to provide a high percentage of uptime (running and available) for network devices.
Host
Device that is connected to a TCP/IP network. May run one or more Virtual Machines.
Hypervisor
Software which creates and runs Virtual Machines. Also called a Virtual Machine Monitor.
Info
In UI, event with warning, informational, or debugging severity.
IP Address
An Internet Protocol address is comprised of a series of numbers assigned to a network device to uniquely identify it on a given network. Version 4 addresses are 32 bits and written in dotted decimal notation with 8-bit binary numbers separated by decimal points. Example: 10.10.10.255. Version 6 addresses are 128 bits and written in 16-bit hexadecimal numbers separated by colons. Example: 2018:3468:1B5F::6482:D673.
Leaf
An access layer switch in a Spine-Leaf or Clos topology. An Exit-Leaf is switch that connects to services outside of the Data Center such as firewalls, load balancers, and Internet routers. See also Spine, CLOS, Top of Rack and Access Switch.
Linux
Set of free and open-source software operating systems built around the Linux kernel. Cumulus Linux is one available distribution packages.
Node
UI term referring to a switch, host or chassis in a topology.
Notification
Item that informs a user of an event. In UI there are two types of notifications: Alert which is a notification sent by system to inform a user about an event; specifically received through a third-party application, and Message which is a notification sent by a user to share content with another user.
Peerlink
Link, or bonded links, used to connect two switches in an MLAG pair.
Rotten
Node that has not been heard from in 90 seconds or more.
Router
Device that forwards data packets (directs traffic) from nodes on one communication network to nodes on another network. Occurs at the OSI Model Layer 3, Network Layer.
Spine
Used to describe the role of a switch in a Spine-Leaf or CLOS topology. See also Aggregation switch, End of Row switch, and distribution switch.
Switch
High-speed device that connects that receives data packets from one device or node and redirects them to other devices or nodes on a network.
Telemetry server
NetQ server which receives metrics and other data from NetQ agents on leaf and spine switches and hosts.
Top of Rack
Switch that connects to the network (versus internally)
Virtual Machine
Emulation of a computer system that provides all of the functions of a particular architecture.
Web-scale
A network architecture designed to deliver capabilities of large cloud service providers within an enterprise IT environment.
Whitebox
Generic, off-the-shelf, switch or router hardware used in Software Defined Networks (SDN).
Common Cumulus Linux and NetQ Acronyms
The following table covers some common acronyms used throughout the NetQ
user documentation.